
Dask Python (How It Works For Developers)
Python is a powerful language for data analysis and machine learning, but handling large datasets can be challenging for data analytics. This is where Dask comes in. Dask is an open-source library that provides advanced parallelization for analytics, enabling efficient computation on large datasets that exceed the memory capacity of a single machine. In this article, we will look into the basic usage of the Dask library and another very interesting PDF-generation library called IronPDF from Iron Software to generate PDF documents.
Why Use Dask?
Dask is designed to scale your Python code from a single laptop to a large cluster. It integrates seamlessly with popular Python libraries like NumPy, pandas, and scikit-learn, to enable parallel execution without significant code changes.
Key Features of Dask
- Parallel Computing: Dask allows you to execute multiple tasks simultaneously, significantly speeding up computations.
- Scalability: It can handle datasets larger than memory by breaking them into smaller chunks and processing them in parallel.
- Compatibility: Works well with existing Python libraries, making it easy to integrate into your current workflow.
- Flexibility: Provides high-level collections like Dask DataFrame, task graphs, Dask Array, Dask Cluster, and Dask Bag, which mimic pandas, NumPy, and lists, respectively.
Getting Started with Dask
Installation
You can install Dask using pip:
pip install dask[complete]pip install dask[complete]Basic Usage
Here’s a simple example to demonstrate how Dask can parallelize computations:
import dask.array as da
# Create a large Dask array
x = da.random.random((10, 10), chunks=(10, 10))
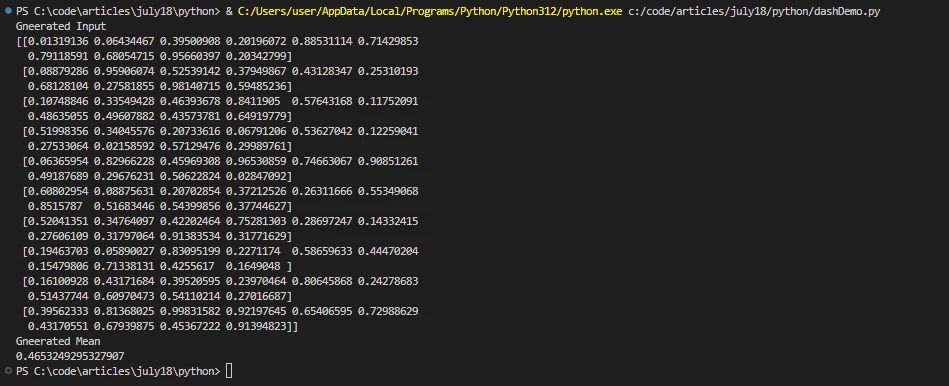
print('Generated Input')
print(x.compute())
# Perform a computation
result = x.mean().compute()
print('Generated Mean')
print(result)import dask.array as da
# Create a large Dask array
x = da.random.random((10, 10), chunks=(10, 10))
print('Generated Input')
print(x.compute())
# Perform a computation
result = x.mean().compute()
print('Generated Mean')
print(result)In this example, Dask creates a large array and divides it into smaller chunks. The compute() method triggers the parallel computation and returns the result. The task graph is used internally to achieve parallel computing in Python Dask.
Output
Dask DataFrames
Dask DataFrames are similar to pandas DataFrames but are designed to handle larger-than-memory datasets. Here’s an example:
import dask
# Generate a synthetic timeseries DataFrame
df = dask.datasets.timeseries()
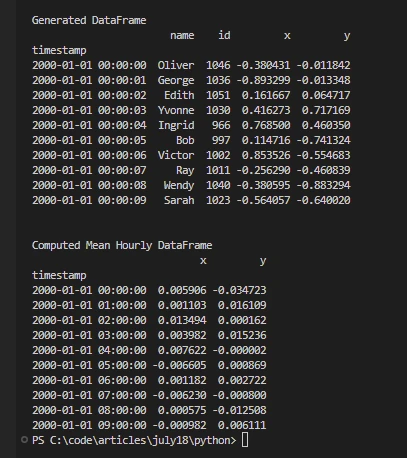
print('\nGenerated DataFrame')
print(df.head(10))
# Compute mean hourly resampled DataFrame
print('\nComputed Mean Hourly DataFrame')
print(df[["x", "y"]].resample("1h").mean().head(10))import dask
# Generate a synthetic timeseries DataFrame
df = dask.datasets.timeseries()
print('\nGenerated DataFrame')
print(df.head(10))
# Compute mean hourly resampled DataFrame
print('\nComputed Mean Hourly DataFrame')
print(df[["x", "y"]].resample("1h").mean().head(10))The code showcases Dask's ability to handle timeseries data, generate synthetic datasets, and compute aggregations like hourly means efficiently by leveraging its parallel processing capabilities using multiple Python processes, a distributed scheduler, and multiple cores computational resources.
Output
Best Practices
- Start Small: Begin with small datasets to understand how Dask works before scaling up.
- Use the Dashboard: Dask provides a dashboard to monitor the progress and performance of your computations.
- Optimize Chunk Sizes: Choose appropriate chunk sizes to balance memory usage and computation speed.
Introducing IronPDF
IronPDF is a robust Python library designed for creating, editing, and signing PDF documents using HTML, CSS, images, and JavaScript. It emphasizes performance efficiency with minimal memory usage. Key features include:
- HTML to PDF Conversion: Easily convert HTML files, strings, and URLs into PDF documents, leveraging Chrome PDF rendering capabilities.
- Cross-Platform Support: Works seamlessly across Python 3+ on Windows, Mac, Linux, and various Cloud Platforms. It's also compatible with .NET, Java, Python, and Node.js environments.
- Editing and Signing: Customize PDF properties, apply security measures like passwords and permissions, and seamlessly add digital signatures.
- Page Templates and Settings: Tailor PDF layouts with headers, footers, page numbers, adjustable margins, custom paper sizes, and responsive designs.
- Standards Compliance: Strict adherence to PDF standards such as PDF/A and PDF/UA, ensuring UTF-8 character encoding compatibility. Efficient management of assets like images, CSS stylesheets, and fonts is also supported.
Installation
pip install ironpdf
pip install daskpip install ironpdf
pip install daskGenerate PDF Documents using IronPDF and Dask.
Prerequisites
- Make sure Visual Studio Code is installed.
- Python version 3 is installed.
To start with, let us create a Python file to add our scripts.
Open Visual Studio Code and create a file, daskDemo.py.
Install necessary libraries:
pip install dask
pip install ironpdfpip install dask
pip install ironpdfThen add the below Python code to demonstrate the usage of IronPDF and Dask Python packages:
import dask
from ironpdf import *
# Apply your license key
License.LicenseKey = "key"
# Generate a synthetic timeseries DataFrame
df = dask.datasets.timeseries()
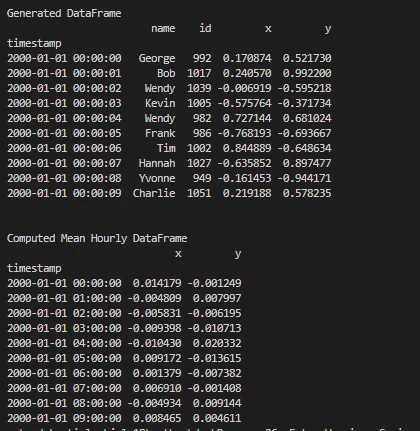
print('\nGenerated DataFrame')
print(df.head(10))
# Compute the mean hourly DataFrame
dfmean = df[["x", "y"]].resample("1h").mean().head(10)
print('\nComputed Mean Hourly DataFrame')
print(dfmean)
# Initialize the PDF renderer
renderer = ChromePdfRenderer()
# Create HTML content for the PDF
content = "<h1>Awesome Iron PDF with Dask</h1>"
# Add generated DataFrame to the content
content += "<h2>Generated DataFrame (First 10)</h2>"
rows = df.head(10)
for i in range(10):
row = rows.iloc[i]
content += f"<p>{str(row[0])}, {str(row[2])}, {str(row[3])}</p>"
# Add computed mean DataFrame to the content
content += "<h2>Computed Mean Hourly DataFrame (First 10)</h2>"
for i in range(10):
row = dfmean.iloc[i]
content += f"<p>{str(row[0])}</p>"
# Render the HTML content as PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Save the PDF to a file
pdf.SaveAs("DemoIronPDF-Dask.pdf")import dask
from ironpdf import *
# Apply your license key
License.LicenseKey = "key"
# Generate a synthetic timeseries DataFrame
df = dask.datasets.timeseries()
print('\nGenerated DataFrame')
print(df.head(10))
# Compute the mean hourly DataFrame
dfmean = df[["x", "y"]].resample("1h").mean().head(10)
print('\nComputed Mean Hourly DataFrame')
print(dfmean)
# Initialize the PDF renderer
renderer = ChromePdfRenderer()
# Create HTML content for the PDF
content = "<h1>Awesome Iron PDF with Dask</h1>"
# Add generated DataFrame to the content
content += "<h2>Generated DataFrame (First 10)</h2>"
rows = df.head(10)
for i in range(10):
row = rows.iloc[i]
content += f"<p>{str(row[0])}, {str(row[2])}, {str(row[3])}</p>"
# Add computed mean DataFrame to the content
content += "<h2>Computed Mean Hourly DataFrame (First 10)</h2>"
for i in range(10):
row = dfmean.iloc[i]
content += f"<p>{str(row[0])}</p>"
# Render the HTML content as PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Save the PDF to a file
pdf.SaveAs("DemoIronPDF-Dask.pdf")Code Explanation
This code snippet integrates Dask for data handling and IronPDF for PDF generation. It demonstrates:
- Dask Integration: Uses
dask.datasets.timeseries()to generate a synthetic timeseries DataFrame (df). Prints the first 10 rows (df.head(10)) and computes the mean hourly DataFrame (dfmean) based on columns "x" and "y". - IronPDF Usage: Sets the IronPDF license key using
License.LicenseKey. Creates an HTML string (content) containing headers and data from the generated and computed DataFrames, then renders this HTML content into a PDF (pdf) usingChromePdfRenderer(), and finally saves the PDF as "DemoIronPDF-Dask.pdf".
This code combines Dask's capabilities for large-scale data manipulation and IronPDF's functionality for converting HTML content into a PDF document.
Output

IronPDF License
IronPDF license key allows users to check out its extensive features before purchase.
Place the License Key at the start of the script before using the IronPDF package:
from ironpdf import *
# Apply your license key
License.LicenseKey = "key"from ironpdf import *
# Apply your license key
License.LicenseKey = "key"Conclusion
Dask is a versatile tool that can significantly enhance your data processing capabilities in Python. By enabling parallel and distributed computing, it allows you to work with large datasets efficiently and integrates seamlessly with your existing Python ecosystem. IronPDF is a powerful Python library for creating and manipulating PDF documents using HTML, CSS, images, and JavaScript. It offers features such as HTML-to-PDF conversion, PDF editing, digital signing, and cross-platform support, making it suitable for various document generation and management tasks in Python applications.
Together, both libraries allow data scientists to perform advanced data analytics and science operations and then store the output results in standard PDF format using IronPDF.
















