
Grakn Python (How It Works: A Guide for Developers)
In today's coding world, databases are evolving to keep up with the demands of new applications. While traditional relational databases are still in use, we now have advancements like Object-Relational Mapping (ORM), which allow developers to interact with databases using higher-level programming abstractions instead of solely relying on SQL. This approach streamlines data management and promotes cleaner code organization. Additionally, NoSQL databases have emerged as useful tools for handling unstructured data, particularly in big data applications and real-time analytics.
Cloud-native databases are also making a significant impact, offering scalable, reliable, and managed services that reduce the burden of maintaining underlying infrastructure. Furthermore, NewSQL and graph databases combine the strengths of SQL and NoSQL, offering the reliability of relational databases with the flexibility of NoSQL. This blend makes them suitable for many modern applications. By integrating these various database types with innovative programming paradigms, we can create scalable and adaptive solutions that align with the data-centric demands of today. Grakn, now known as TypeDB, exemplifies this trend by supporting the management and querying of knowledge graphs. In this article, we'll explore Grakn (TypeDB) and its integration with IronPDF, a crucial tool for programmatically generating and manipulating PDFs.
What is Grakn?
Grakn (now TypeDB), created by Grakn Labs, is a knowledge graph database designed for managing and analyzing complex networks of data. It excels in modeling sophisticated relationships within existing datasets and provides powerful reasoning capabilities over stored data. Grakn's querying language, Graql, allows for precise data manipulation and querying, enabling the development of intelligent systems that can extract valuable insights from intricate datasets. By harnessing Grakn's core features, organizations can manage data structures with a robust and intelligent knowledge representation.
Graql, the query language of Grakn, is specifically crafted to interact effectively with the Grakn knowledge graph model, enabling detailed and nuanced data transformations. Due to its horizontal scalability and ability to handle large datasets, TypeDB is well-suited for domains such as finance, healthcare, drug discovery, and cybersecurity, where understanding and managing complex graph structures are crucial.
Installation and Configuring Grakn in Python
Installing Grakn
For Python developers interested in using Grakn (TypeDB), installing the typedb-driver library is essential. This official client facilitates interaction with TypeDB. Use the following pip command to install this library:
pip install typedb-driverpip install typedb-driverSet Up the TypeDB Server
Before writing code, ensure your TypeDB server is up and running. Follow the installation and setup instructions provided on the TypeDB website for your operating system. Once installed, you can use the following command to start the TypeDB server:
./typedb server./typedb serverUsing Grakn in Python
Python Code to Interact with TypeDB
This section illustrates establishing a connection with a TypeDB server, setting up a database schema, and performing basic operations like data insertion and retrieval.
Creating a Database Schema
In the following code block, we define the database structure by creating a type called person with two attributes: name and age. We open a session in SCHEMA mode, enabling structural modifications. Here’s how the schema is defined and committed:
from typedb.driver import TypeDB, SessionType, TransactionType
# Connect to TypeDB server
client = TypeDB.core_driver("localhost:1729")
# Create a database (if not already created)
database_name = "example_db"
if not client.databases().contains(database_name):
client.databases().create(database_name)
with client.session(database_name, SessionType.SCHEMA) as session:
with session.transaction(TransactionType.WRITE) as transaction:
transaction.query().define("""
define
person sub entity, owns name, owns age;
name sub attribute, value string;
age sub attribute, value long;
""")
transaction.commit()from typedb.driver import TypeDB, SessionType, TransactionType
# Connect to TypeDB server
client = TypeDB.core_driver("localhost:1729")
# Create a database (if not already created)
database_name = "example_db"
if not client.databases().contains(database_name):
client.databases().create(database_name)
with client.session(database_name, SessionType.SCHEMA) as session:
with session.transaction(TransactionType.WRITE) as transaction:
transaction.query().define("""
define
person sub entity, owns name, owns age;
name sub attribute, value string;
age sub attribute, value long;
""")
transaction.commit()Inserting Data
After establishing the schema, the script inserts data into the database. We open a session in DATA mode, suitable for data operations, and execute an insert query to add a new person entity with the name "Alice" and age 30:
# Insert data into the database
with client.session(database_name, SessionType.DATA) as session:
with session.transaction(TransactionType.WRITE) as transaction:
# Create a person entity
transaction.query().insert("""
insert $p isa person, has name "Alice", has age 30;
""")
transaction.commit()# Insert data into the database
with client.session(database_name, SessionType.DATA) as session:
with session.transaction(TransactionType.WRITE) as transaction:
# Create a person entity
transaction.query().insert("""
insert $p isa person, has name "Alice", has age 30;
""")
transaction.commit()Querying Data
Finally, we retrieve information from the database by querying for entities with the name "Alice." We open a new session in DATA mode and initiate a read transaction using TransactionType.READ. The results are processed to extract and display the name and age:
# Query the data from the database
with client.session(database_name, SessionType.DATA) as session:
with session.transaction(TransactionType.READ) as transaction:
# Query entities where the person has the name 'Alice'
results = transaction.query().match("""
match
$p isa person, has name "Alice";
$p has name $n, has age $a;
get;
""")
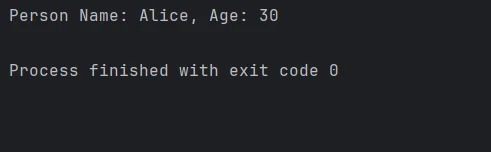
for result in results:
person_name = result.get("n").get_value()
person_age = result.get("a").get_value()
print(f"Person Name: {person_name}, Age: {person_age}")# Query the data from the database
with client.session(database_name, SessionType.DATA) as session:
with session.transaction(TransactionType.READ) as transaction:
# Query entities where the person has the name 'Alice'
results = transaction.query().match("""
match
$p isa person, has name "Alice";
$p has name $n, has age $a;
get;
""")
for result in results:
person_name = result.get("n").get_value()
person_age = result.get("a").get_value()
print(f"Person Name: {person_name}, Age: {person_age}")Output
Closing the Client Connection
To properly release resources and prevent further interactions with the TypeDB server, close the client connection using client.close():
# Close the client connection
client.close()# Close the client connection
client.close()Introducing IronPDF
IronPDF for Python is a powerful library for programmatically creating and manipulating PDF files. It provides comprehensive functionality for creating PDFs from HTML, merging PDF files, and annotating existing PDF documents. IronPDF also enables the conversion of HTML or web content into high-quality PDFs, making it an ideal choice for generating reports, invoices, and other fixed-layout documents.
The library offers advanced features such as content extraction, document encryption, and page layout customization. By integrating IronPDF into Python applications, developers can automate document generation workflows and enhance the overall capabilities of their PDF handling.
Installing the IronPDF Library
To enable IronPDF functionality in Python, install the library using pip:
pip install ironpdfpip install ironpdfIntegrating Grakn TypeDB with IronPDF
By combining TypeDB and IronPDF in a Python environment, developers can efficiently generate and manage PDF documentation based on complexly structured data in a Grakn (TypeDB) database. Here’s an integration example:
from typedb.driver import TypeDB, SessionType, TransactionType
from ironpdf import *
import warnings
# Suppress potential warnings
warnings.filterwarnings('ignore')
# Replace with your own license key
License.LicenseKey = "YOUR LICENSE KEY GOES HERE"
# Initialize data list
data = []
# Connect to TypeDB server
client = TypeDB.core_driver("localhost:1729")
# Query the data from the database
with client.session(database_name, SessionType.DATA) as session:
with session.transaction(TransactionType.READ) as transaction:
# Fetch details of persons named 'Alice'
results = transaction.query().match("""
match
$p isa person, has name "Alice";
$p has name $n, has age $a;
get;
""")
for result in results:
person_name = result.get("n").get_value()
person_age = result.get("a").get_value()
data.append({"name": person_name, "age": person_age})
# Close the client connection
client.close()
# Create a PDF from HTML content
html_to_pdf = ChromePdfRenderer()
content = "<h1>Person Report</h1>"
for item in data:
content += f"<p>Name: {item['name']}, Age: {item['age']}</p>"
# Render the HTML content as a PDF
pdf_document = html_to_pdf.RenderHtmlAsPdf(content)
# Save the PDF to a file
pdf_document.SaveAs("output.pdf")from typedb.driver import TypeDB, SessionType, TransactionType
from ironpdf import *
import warnings
# Suppress potential warnings
warnings.filterwarnings('ignore')
# Replace with your own license key
License.LicenseKey = "YOUR LICENSE KEY GOES HERE"
# Initialize data list
data = []
# Connect to TypeDB server
client = TypeDB.core_driver("localhost:1729")
# Query the data from the database
with client.session(database_name, SessionType.DATA) as session:
with session.transaction(TransactionType.READ) as transaction:
# Fetch details of persons named 'Alice'
results = transaction.query().match("""
match
$p isa person, has name "Alice";
$p has name $n, has age $a;
get;
""")
for result in results:
person_name = result.get("n").get_value()
person_age = result.get("a").get_value()
data.append({"name": person_name, "age": person_age})
# Close the client connection
client.close()
# Create a PDF from HTML content
html_to_pdf = ChromePdfRenderer()
content = "<h1>Person Report</h1>"
for item in data:
content += f"<p>Name: {item['name']}, Age: {item['age']}</p>"
# Render the HTML content as a PDF
pdf_document = html_to_pdf.RenderHtmlAsPdf(content)
# Save the PDF to a file
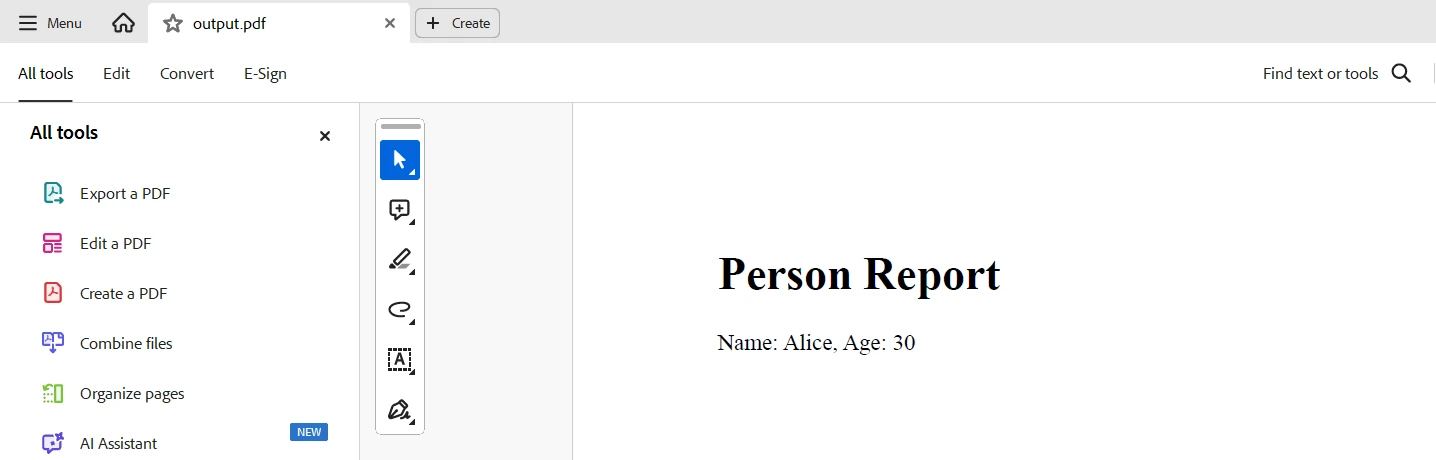
pdf_document.SaveAs("output.pdf")This code demonstrates using TypeDB and IronPDF in Python to extract data from a TypeDB database and generate a PDF report. It connects to a local TypeDB server, fetches entities named "Alice," and retrieves their names and ages. The results are then used to construct HTML content, which is converted into a PDF document using IronPDF's ChromePdfRenderer, and saved as "output.pdf".
Output
Licensing
A license key is required to remove watermarks from the generated PDFs. You can register for a free trial at this link. Note that a credit card is not needed for registration; only an email address is required for the free trial version.
Conclusion
Grakn (now TypeDB) integrated with IronPDF provides a robust solution for managing and analyzing large data volumes from PDF documents. With IronPDF's capabilities in data extraction and manipulation, and Grakn's proficiency in modeling complex relationships and reasoning, you can transform unstructured document data into structured, queryable information.
This integration simplifies the extraction of valuable insights from PDFs, enhancing their querying and analysis capabilities with improved precision. By combining Grakn's high-level data management with IronPDF’s PDF processing features, you can develop more efficient ways of handling information for better decision-making and deeper insight into complex datasets. IronSoftware also offers a variety of libraries to facilitate application development across multiple operating systems and platforms, including Windows, Android, macOS, Linux, and more.
















