
Best PDF Reader for Python (Free & Paid Tools)
This article delves into the best Python libraries for working with PDFs, highlighting their features and how they cater to the specific needs of data scientists, developers, and anyone needing to handle unstructured data sources.
IronPDF - The Leading Python PDF Library
 IronPDF for Python
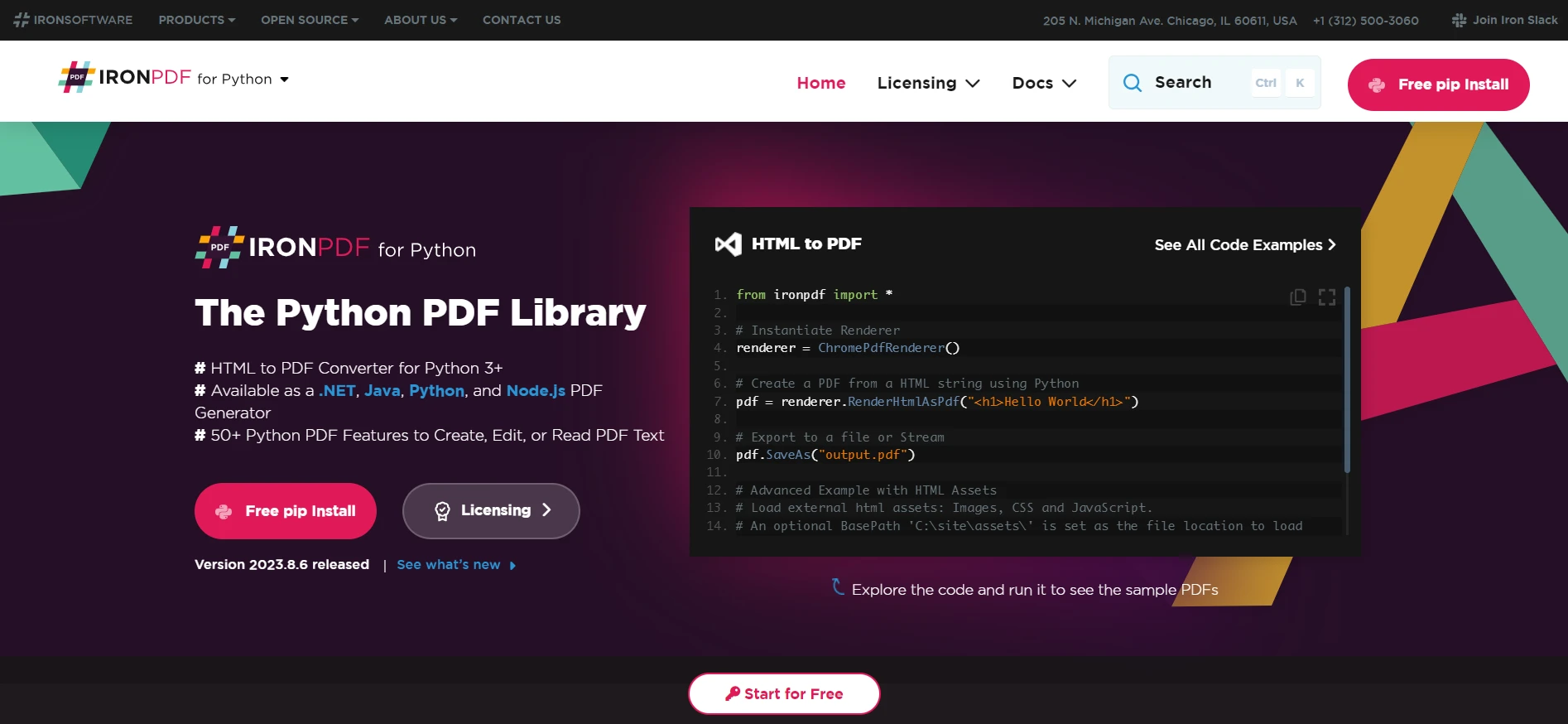
IronPDF for Python
When it comes to manipulating PDF files with Python, IronPDF stands out as a premium choice. It is not a pure Python PDF library, but its capabilities in PDF processing are extensive. It offers an explicit interface to convert PDF documents to other formats. Developers can transform PDF files into images or HTML, allowing a versatile output file to be displayed on web pages or edited in image editors.
IronPDF supports advanced features like text analytics, providing tools for data scientists to extract text and analyze text data. Moreover, it can handle multiple pages within a PDF document, allowing for operations like rotating PDF pages, cropping pages, and even searching for text at an exact location.
The library is also an excellent choice for implementing features like PDF file print functionality into their applications. It ensures a high level of compatibility and performance, making it a go-to solution for professionals who need a reliable and powerful tool.
Pros & Cons
Pros
- Comprehensive PDF manipulation capabilities.
- Allows conversion of PDFs to other formats like images and HTML.
- Advanced features for text extraction and analytics.
- Supports multiple page handling, rotating, and cropping.
Cons
- Not a pure Python library, which might not suit all environments.
- The complex feature set might be overkill for simple tasks.
Pricing
IronPDF for Python offers a tiered licensing model, with the minimum pricing for a Lite license set at $999. This option is ideal for a single developer and permits deployment within one application.
The pricing structure scales up through more inclusive licenses, such as the Plus and Professional, catering to larger teams and multiple applications, and even extends to a Royalty-Free/SaaS/OEM Redistribution license for broad distribution without royalty fees.
Each purchase comes with a year of support and updates, with the option to extend for an additional five years at a separate cost. IronPDF also offers a free trial.
PyPDF2 - A Versatile Tool for PDF Manipulation
 PyPDF2
PyPDF2
PyPDF2 is a widely-used Python PDF library that excels in reading and writing PDF files in Python. It offers a straightforward approach to manipulating PDF documents, including merging documents, splitting PDF pages, and rotating PDF pages.
Here's a basic example code snippet demonstrating how to merge two PDF files using PyPDF2:
from PyPDF2 import PdfReader, PdfWriter
# Create a PdfWriter object for output
output = PdfWriter()
# List of PDFs to be merged
input_pdfs = ["file1.pdf", "file2.pdf"]
# Iterate over the list of PDF file paths
for pdf in input_pdfs:
# Open each PDF file
reader = PdfReader(pdf)
# Add all pages from the current PDF to the writer
for page in range(len(reader.pages)):
output.add_page(reader.pages[page])
# Finally, write the combined PDF to a new file
with open("merged.pdf", "wb") as output_stream:
output.write(output_stream)from PyPDF2 import PdfReader, PdfWriter
# Create a PdfWriter object for output
output = PdfWriter()
# List of PDFs to be merged
input_pdfs = ["file1.pdf", "file2.pdf"]
# Iterate over the list of PDF file paths
for pdf in input_pdfs:
# Open each PDF file
reader = PdfReader(pdf)
# Add all pages from the current PDF to the writer
for page in range(len(reader.pages)):
output.add_page(reader.pages[page])
# Finally, write the combined PDF to a new file
with open("merged.pdf", "wb") as output_stream:
output.write(output_stream)Explanation
- PdfReader: Used to read PDF files.
- PdfWriter: Used to write pages to a new PDF.
- The
forloop iterates over each page from the input files and adds them to the writer. - The final output is saved as
merged.pdf.
PyPDF2 allows developers to easily access page objects and extract text, making it a good choice for basic text analytics tasks.
While it does not provide as extensive a feature set as some other Python PDF libraries for transforming PDF files, its simplicity makes it a great starting point for beginners in the Python programming language or those with simpler PDF processing needs.
Pros & Cons
Pros
- Free and open-source.
- Can split, merge, crop, and transform PDF pages.
- Adds custom data, viewing options, and passwords to PDFs.
- Simple to use with a pure Python implementation.
Cons
- Less extensive feature set compared to some other libraries.
- For AES encryption or decryption, additional dependencies are required.
Pricing
PyPDF2 is free to use as an open-source library under the BSD License. There are no costs associated with using the library itself, although certain advanced features like encrypting or decrypting PDFs with AES will require extra dependencies, which may have their own costs.
PDFMiner - Specialized in Text Extraction
 PDFMiner
PDFMiner
PDFMiner shines in text extraction and analytics, making it a valuable tool for data scientists and developers looking to analyze unstructured text data. As a pure Python PDF library, it offers detailed control over text formats, allowing users to precisely extract custom data and handle unstructured data sources.
Here is an example demonstrating how to extract text from a PDF using PDFMiner:
from pdfminer.high_level import extract_text
# Specify the path of your PDF file
pdf_path = "example.pdf"
# Extract text from the PDF
text = extract_text(pdf_path)
# Display the extracted text
print(text)from pdfminer.high_level import extract_text
# Specify the path of your PDF file
pdf_path = "example.pdf"
# Extract text from the PDF
text = extract_text(pdf_path)
# Display the extracted text
print(text)Explanation
- extract_text: A high-level API function in PDFMiner that extracts all text content from a given PDF file.
- The extracted text is printed to the console. This is useful for data processing applications that need to analyze or manipulate the text data extracted.
Its ability to locate the exact location of text within a PDF page makes it particularly useful for applications that require high accuracy in text analytics, such as natural language processing or machine learning. The PDFMiner library can also handle multiple pages and convert PDF documents into other text formats.
Pros & Cons
Pros
- Specializes in text extraction with precise location and layout information.
- Pure Python and supports PDF-1.7 to a large extent.
- Can convert PDFs to other formats such as HTML/XML.
- Supports CJK languages and vertical writing scripts.
- Extensible PDF parser for various purposes.
Cons
- The focus on text extraction means it might lack some manipulation features found in other libraries.
- Only supports Python 3, which may be a limitation for environments using Python 2.
Pricing
PDFMiner is available under the MIT License, a permissive free software license. Like PyPDF2, it is open-source and free to use. There are no fees for utilizing PDFMiner in your projects, making it an economically attractive option for text extraction and analysis tasks.
Conclusion
Selecting the best Python PDF library depends mainly on the specific PDF processing needs. IronPDF is a strong candidate for comprehensive PDF file manipulation, offering many features and powerful text analytics capabilities.
For those who need pure Python PDF libraries that are easy to use, PyPDF2 and PDFMiner are excellent choices, each with their own strengths in handling and extracting text data. For creating complex PDF documents with custom layouts, ReportLab provides the necessary tools.
Whether you are a data scientist looking to extract text from PDF files, a developer aiming to convert PDF files, or you need to manipulate PDF files in any other way, there is a Python library tailored to your needs.
Python continues to support its community with robust libraries, confirming its status as a versatile interpreted language ideal for working with various unstructured data sources.
Frequently Asked Questions
What is the best way to convert HTML to PDF in Python?
You can use IronPDF to convert HTML to PDF in Python. The library provides methods like RenderHtmlAsPdf to convert HTML strings and RenderHtmlFileAsPdf for HTML files.
How can I extract text from a PDF using Python?
IronPDF allows for easy text extraction from PDFs. You can use its text extraction functions to access and manipulate the text data within PDF documents.
What are the advantages of using IronPDF for PDF manipulation in Python?
IronPDF offers advanced features like converting PDFs to images and HTML, text extraction, and managing multiple pages, making it a comprehensive solution for PDF manipulation in Python.
Is there a free trial available for IronPDF?
Yes, IronPDF offers a free trial version, allowing users to explore its features before committing to a purchase.
What are some common troubleshooting tips for using PDF libraries in Python?
Ensure you have the correct dependencies installed and verify your PDF file paths. For IronPDF, consult the documentation for specific methods and their correct usage.
Can IronPDF be used for rotating PDF pages in Python?
Yes, IronPDF provides functionality to rotate PDF pages easily, allowing you to manipulate document layouts as needed.
How does IronPDF compare with other PDF libraries like PyPDF2 and PDFMiner?
IronPDF offers more extensive features such as HTML conversion and advanced text analytics, while PyPDF2 and PDFMiner are open-source and focus on basic manipulation and text extraction, respectively.
What should I consider when choosing a PDF library for Python?
Consider your specific requirements such as the need for advanced features, ease of use, licensing costs, and whether the library is pure Python or not. IronPDF is recommended for comprehensive features, while PyPDF2 and PDFMiner are suitable for simpler needs.
















