xml2js npm(開發者的使用方法)
開發者可以透過將 XML2JS 與Node.js中的IronPDF結合使用,輕鬆地將 XML 資料解析和 PDF 創建功能整合到他們的應用程式中。 XML2JS 是一個廣受歡迎的Node.js包,它可以輕鬆地將 XML 資料轉換為JavaScript對象,從而方便對 XML 材料進行程式設計操作和使用。 相反, IronPDF專注於從HTML (包括動態創建的內容)產生具有可調節頁面大小、邊距和頁眉的高品質 PDF 文件。
借助 XML2JS 和IronPDF,開發人員現在可以直接從 XML 資料來源動態建立 PDF 報告、發票或其他可列印資料。 為了實現文件產生流程的自動化,並確保在Node.js應用程式中管理基於 XML 的 PDF 輸出資料的正確性和靈活性,此整合充分利用了這兩個程式庫的優勢。
什麼是xml2js?
一個名為 XML2JS 的Node.js套件可以更輕鬆地解析和建立簡單的 XML(可擴展標記語言)到JavaScript物件轉換器。 它提供了解析 XML 檔案或文字並將其轉換為結構化JavaScript物件的方法,從而簡化了 XML 文件的處理。 該程式透過提供僅管理 XML 屬性、文字內容、命名空間、合併屬性或鍵控屬性以及其他 XML 特有特徵的選項,賦予應用程式解釋和使用 XML 資料的自由度。
該程式庫能夠處理大型 XML 文件或需要非阻塞解析的情況,因為它支援同步和非同步解析操作。 此外,XML2JS 還提供了在將 XML 轉換為JavaScript物件時驗證和解決錯誤的機制,從而保證了資料處理操作的穩定性和可靠性。 綜上所述, Node.js應用程式經常使用 XML2JS 來整合基於 XML 的資料來源、配置軟體、更改資料格式以及簡化自動化測試流程。
XML2JS 是一款靈活且不可或缺的工具,用於在Node.js應用程式中處理 XML 數據,因為它具有以下特點:
XML解析
借助 XML2JS,開發人員可以透過簡化 XML 字串或檔案到JavaScript物件的處理過程,使用眾所周知的JavaScript語法更快地存取和處理 XML 資料。
JavaScript物件轉換
JavaScript應用程式能夠輕鬆地將 XML 資料轉換為結構化的JavaScript對象,簡化了 XML 資料在應用程式中的使用。
可配置選項
XML2JS 提供了多種配置選項,可讓您變更 XML 資料解析和轉換為JavaScript物件的方式。 這涵蓋了命名空間、文字內容、屬性和其他方面的管理。
雙向轉換
雙向轉換功能使得往返資料變更成為可能,該功能可以將JavaScript物件轉換回簡單的 XML 字串。
非同步解析
該庫支援非同步解析過程,可以很好地處理大型 XML 文檔,而不會幹擾應用程式的事件循環。
錯誤處理
為了處理 XML 解析和轉換過程中可能出現的驗證問題和解析錯誤,XML2JS 提供了強大的錯誤處理方法。
與 Promise 集成
它與JavaScript Promises 配合使用效果很好,使處理 XML 資料的非同步程式碼模式更清晰、更易於處理。
可自訂的解析鉤子
開發人員可以透過建立自訂解析鉤子來提高資料處理過程的靈活性,這些鉤子允許他們使用特殊選項來攔截和更改 XML 解析行為。
建立和配置 xml2js
在Node.js應用程式中使用XML2JS的初始步驟是安裝程式庫並進行配置以滿足您的需求。 這是一份關於如何設定和建立 XML2JS 的詳細操作指南。
安裝 XML2JS npm
請先確保已安裝 npm 和Node.js可以透過 npm 安裝:
npm install xml2jsnpm install xml2jsXML2JS 的基本用法
這是一個使用 XML2JS 將 XML 文字解析為JavaScript物件的簡單範例:
const xml2js = require('xml2js');
// Example XML content
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser
const parser = new xml2js.Parser();
// Parse XML content
parser.parseString(xmlContent, (err, result) => {
if (err) {
console.error('Error parsing XML:', err);
return;
}
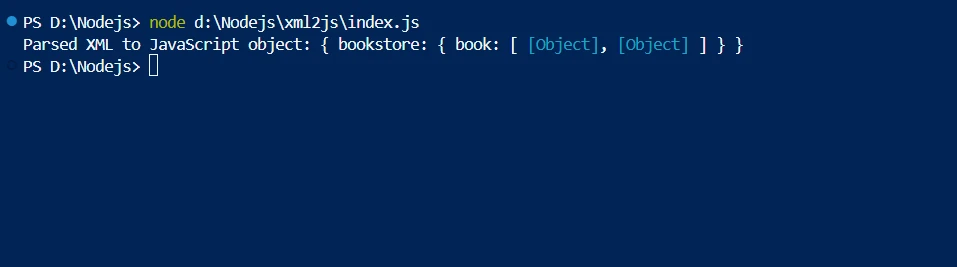
console.log('Parsed XML to JavaScript object:', result);
});const xml2js = require('xml2js');
// Example XML content
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser
const parser = new xml2js.Parser();
// Parse XML content
parser.parseString(xmlContent, (err, result) => {
if (err) {
console.error('Error parsing XML:', err);
return;
}
console.log('Parsed XML to JavaScript object:', result);
});
配置選項
XML2JS 提供了一系列配置選項和預設設置,可讓您變更解析行為。 以下舉例說明如何設定 XML2JS 的預設解析設定:
const xml2js = require('xml2js');
// Example XML content
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser with options
const parser = new xml2js.Parser({
explicitArray: false, // Converts child elements to objects instead of arrays when there is only one child
trim: true // Trims leading/trailing whitespace from text nodes
});
// Parse XML content
parser.parseString(xmlContent, (err, result) => {
if (err) {
console.error('Error parsing XML:', err);
return;
}
console.log('Parsed XML to JavaScript object with options:', result);
});const xml2js = require('xml2js');
// Example XML content
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser with options
const parser = new xml2js.Parser({
explicitArray: false, // Converts child elements to objects instead of arrays when there is only one child
trim: true // Trims leading/trailing whitespace from text nodes
});
// Parse XML content
parser.parseString(xmlContent, (err, result) => {
if (err) {
console.error('Error parsing XML:', err);
return;
}
console.log('Parsed XML to JavaScript object with options:', result);
});處理非同步解析
XML2JS 支援非同步解析,這對於在不中斷事件循環的情況下管理大型 XML 文件非常有用。以下範例展示如何在 XML2JS 中使用 async/await 語法:
const xml2js = require('xml2js');
// Example XML content (assume it's loaded asynchronously, e.g., from a file)
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser
const parser = new xml2js.Parser();
// Async function to parse XML content
async function parseXml(xmlContent) {
try {
const result = await parser.parseStringPromise(xmlContent);
console.log('Parsed XML to JavaScript object (async):', result);
} catch (err) {
console.error('Error parsing XML (async):', err);
}
}
// Call async function to parse XML content
parseXml(xmlContent);const xml2js = require('xml2js');
// Example XML content (assume it's loaded asynchronously, e.g., from a file)
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser
const parser = new xml2js.Parser();
// Async function to parse XML content
async function parseXml(xmlContent) {
try {
const result = await parser.parseStringPromise(xmlContent);
console.log('Parsed XML to JavaScript object (async):', result);
} catch (err) {
console.error('Error parsing XML (async):', err);
}
}
// Call async function to parse XML content
parseXml(xmlContent);入門
要在Node.js應用程式中使用IronPDF和XML2JS,必須先讀取XML數據,然後根據處理後的內容建立PDF文件。 這是一份詳細的操作指南,將協助您安裝和設定這些程式庫。
IronPDF是什麼?
IronPDF庫是一個功能強大的Node.js庫,用於處理 PDF 檔案。 它的目標是將 HTML 內容轉換為高品質的 PDF 文件。 它簡化了將 HTML、CSS 和其他JavaScript檔案轉換為格式正確的 PDF 的過程,而不會損害原始線上內容。 對於需要產生動態、可列印文件(例如發票、憑證和報告)的 Web 應用程式來說,這是一個非常有用的工具。
IronPDF具有多種功能,包括可自訂的頁面設定、頁首、頁腳,以及插入字體和圖像的功能。 它支援複雜的佈局和樣式,以確保所有測試輸出 PDF 都遵循指定的設計。 此外, IronPDF控制 HTML 中的JavaScript執行,因此能夠精確渲染動態和互動式內容。
IronPDF的特點
從 HTML 產生 PDF
將 HTML、CSS 和JavaScript轉換為 PDF。 支援兩種現代網路標準:媒體查詢和響應式設計。 有助於使用 HTML 和 CSS 動態裝飾 PDF 發票、報告和文件。
PDF編輯
可以將文字、圖像和其他內容新增到現有的 PDF 檔案中。 從PDF文件中提取文字和圖像。 將多個PDF文件合併成一個文件。將PDF文件拆分成多個獨立的文件。 新增頁首、頁尾、註解和浮水印。
性能和可靠性
在工業領域,高性能和高可靠性是理想的設計屬性。 輕鬆處理大型文件集。
安裝IronPDF
若要取得在Node.js專案中處理 PDF 所需的工具,請安裝IronPDF套件。
npm install @ironsoftware/ironpdfnpm install @ironsoftware/ironpdf解析 XML 並產生 PDF
為了說明這一點,我們產生一個名為 example.xml 的基本 XML 檔案:
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>建立 generatePdf.js Node.js腳本,該腳本讀取 XML 文件,使用 XML2JS 將其解析為JavaScript對象,然後使用IronPDF從解析後的資料對象建立 PDF。
// generatePdf.js
const fs = require('fs');
const xml2js = require('xml2js');
const IronPdf = require('@ironsoftware/ironpdf');
// Configure IronPDF with license if necessary
var config = IronPdf.IronPdfGlobalConfig;
config.setConfig({ licenseKey: '' });
// Function to read and parse XML
const parseXml = async (filePath) => {
const parser = new xml2js.Parser();
const xmlContent = fs.readFileSync(filePath, 'utf8');
return await parser.parseStringPromise(xmlContent);
};
// Function to generate HTML content from the parsed object
function generateHtml(parsedXml) {
let htmlContent = `
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Bookstore</title>
<style>
body { font-family: Arial, sans-serif; }
.book { margin-bottom: 20px; }
</style>
</head>
<body>
<h1>Bookstore</h1>
`;
// Iterate over each book to append to the HTML content
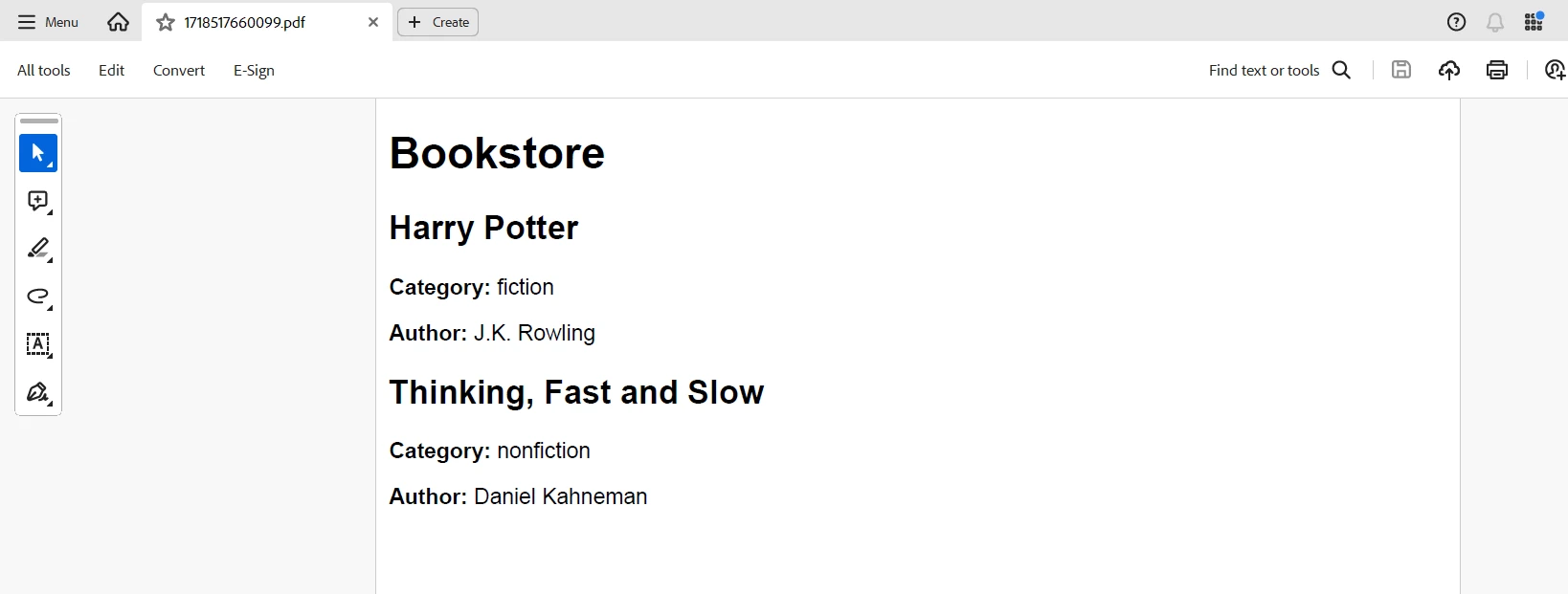
parsedXml.bookstore.book.forEach(book => {
htmlContent += `
<div class="book">
<h2>${book.title}</h2>
<p><strong>Category:</strong> ${book.$.category}</p>
<p><strong>Author:</strong> ${book.author}</p>
</div>
`;
});
htmlContent += `
</body>
</html>
`;
return htmlContent;
}
// Main function to generate PDF
const generatePdf = async () => {
try {
const parser = await parseXml('./example.xml');
const htmlContent = generateHtml(parser);
// Convert HTML to PDF
IronPdf.PdfDocument.fromHtml(htmlContent).then((pdfres) => {
const filePath = `${Date.now()}.pdf`;
pdfres.saveAs(filePath).then(() => {
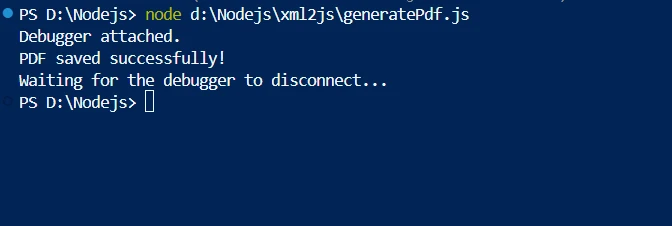
console.log('PDF saved successfully!');
}).catch((e) => {
console.log(e);
});
});
} catch (error) {
console.error('Error:', error);
}
};
// Run the main function
generatePdf();// generatePdf.js
const fs = require('fs');
const xml2js = require('xml2js');
const IronPdf = require('@ironsoftware/ironpdf');
// Configure IronPDF with license if necessary
var config = IronPdf.IronPdfGlobalConfig;
config.setConfig({ licenseKey: '' });
// Function to read and parse XML
const parseXml = async (filePath) => {
const parser = new xml2js.Parser();
const xmlContent = fs.readFileSync(filePath, 'utf8');
return await parser.parseStringPromise(xmlContent);
};
// Function to generate HTML content from the parsed object
function generateHtml(parsedXml) {
let htmlContent = `
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Bookstore</title>
<style>
body { font-family: Arial, sans-serif; }
.book { margin-bottom: 20px; }
</style>
</head>
<body>
<h1>Bookstore</h1>
`;
// Iterate over each book to append to the HTML content
parsedXml.bookstore.book.forEach(book => {
htmlContent += `
<div class="book">
<h2>${book.title}</h2>
<p><strong>Category:</strong> ${book.$.category}</p>
<p><strong>Author:</strong> ${book.author}</p>
</div>
`;
});
htmlContent += `
</body>
</html>
`;
return htmlContent;
}
// Main function to generate PDF
const generatePdf = async () => {
try {
const parser = await parseXml('./example.xml');
const htmlContent = generateHtml(parser);
// Convert HTML to PDF
IronPdf.PdfDocument.fromHtml(htmlContent).then((pdfres) => {
const filePath = `${Date.now()}.pdf`;
pdfres.saveAs(filePath).then(() => {
console.log('PDF saved successfully!');
}).catch((e) => {
console.log(e);
});
});
} catch (error) {
console.error('Error:', error);
}
};
// Run the main function
generatePdf();將 XML 資料轉換為 PDF 文件並解析多個文件的簡單方法是在Node.js應用程式中結合IronPDF和 XML2JS。 使用 XML2JS,先使用Node.js的 fs 模組讀取 XML 文件,然後將多個文件的 XML 內容解析為JavaScript物件。 隨後,利用處理後的資料動態產生構成PDF基礎的 HTML 文字。
該腳本首先從檔案中讀取 XML 文本,並使用 xml2js 將其解析為JavaScript物件。 從解析後的資料物件中,自訂函數建立 HTML 內容,並使用所需的元素對其進行結構化—例如,書店的作者和書名。 然後使用IronPDF將此 HTML 渲染成 PDF 緩衝區。 產生的PDF檔案隨後儲存到檔案系統中。
此方法利用 IronPDF 高效的 HTML 到 PDF 轉換功能和 XML2JS 強大的 XML 解析功能,為在Node.js應用程式中從 XML 資料建立 PDF 提供了一種簡化的方法。 此連接可以將動態 XML 資料轉換為可列印且格式良好的 PDF 文件。 這使其非常適合需要從 XML 來源自動產生文件的應用。
結論
總而言之,XML2JS 和IronPDF在Node.js應用程式中結合使用,提供了一種強大且靈活的方式,可以將 XML 資料轉換為高品質的 PDF 文件。 使用 XML2JS 將 XML 高效解析為JavaScript對象,可簡化資料擷取和操作。 資料解析完成後,可以動態地將其轉換為 HTML 文本,然後IronPDF可以輕鬆地將其轉換為結構正確的 PDF 文件。
對於需要從 XML 資料來源自動建立報表、發票和憑證等文件的應用程式來說,這種組合可能特別有用。 開發者可以利用這兩個函式庫的優勢,確保產生準確美觀的 PDF 輸出,簡化工作流程,並提高Node.js應用程式處理文件產生任務的能力。
IronPDF為開發人員提供更多功能以及更有效率的開發,同時充分利用 Iron Software 高度靈活的系統和套件。
當許可選項明確且針對特定專案時,開發人員更容易選擇最佳模式。 這些功能使開發人員能夠以易於使用、高效且統一的方式解決各種問題。