IronPDF For Python 和 PyPDF 的比較
PDF(便攜式文檔格式)是在不同平台上保持文檔資訊佈局和格式的廣泛使用的文件格式。 由於其能夠在不同設備或操作系統開啟時保持一致外觀,因此在各行各業中極受歡迎。 PDF通常用於共享報告、發票、表單、電子書、自定義數據及其他重要文件。
在Python中處理PDF文件已成為許多項目的關鍵部分。 Python提供了幾個程式庫,簡化了對PDF文件的操作,使得更容易提取資訊、創建新文件、合併或拆分現有文件,以及執行其他與PDF相關的任務。
在本文中,我們將對設計用於操作PDF的兩個著名Python程式庫進行全面比較:PyPDF和IronPDF。 通過對這兩個程式庫的功能和能力進行評估,我們旨在為開發者提供有價值的見解,以幫助他們做出符合其特定軟體應用需求的明智選擇。
這些程式庫提供了穩健的工具來簡化PDF的工作,使得開發者能夠在其Python應用中高效處理PDF文檔。 因此,讓我們深入比較,探索每個程式庫的優勢,以促進您的PDF相關任務。
PyPDF - 純Python PDF程式庫
PyPDF是一個純Python PDF程式庫,提供讀取、寫入、解密PDF文件和操作PDF文檔的基本功能。 它允許開發者從PDF中提取文本和圖像,合併多個PDF文件,將大型PDF拆分為較小的文件等。 PyPDF以其簡單易用而聞名,使其成為處理簡單PDF任務的理想選擇。
它提供了一套全面的功能,適用於處理PDF文件,使其成為執行各種PDF相關任務的絕佳選擇。
功能
PyPDF是一個Python PDF程式庫,具備以下功能:
- 讀取PDF文件:從現有PDF文件中提取文本、圖像和元數據。
- 寫入PDF文件:從頭創建新的PDF,或使用文本和圖像修改現有的。
- 合併PDF文件:將多個PDF文件合併為單個文檔。
- 拆分PDF文件:將PDF分割為單獨的文件,每個文件包含一頁或多頁。
- 旋轉和疊加頁面:旋轉頁面並在PDF上添加水印或疊加。
- 加密和解密PDF文件:通過加密和解密為PDF增強安全性。
- 提取文本:從PDF中獲取純文本或特定區域內的文本。
- 提取圖像:檢索嵌入於PDF中的圖像。
- 操作PDF文件:在PDF文件中複製、刪除或重新安排頁面。
- 表單域填充:以編程方式填充PDF中的表單域。
IronPDF - Python PDF程式庫
IronPDF是一個全面的Python PDF操作程式庫,構建在IronPDF的.NET程式庫之上。 它提供了一個強大的API,具備進階功能,如將HTML轉換為PDF、處理PDF註釋和表單字段,並高效執行複雜的PDF操作。 IronPDF在需要穩健的PDF處理、性能和廣泛功能支持的項目中受到青睞。
IronPDF是一個Python PDF程式庫,能夠無縫處理PDF處理任務。 它為Python開發者提供了一個可靠且功能豐富的PDF操作解決方案。 使用IronPDF,您可以輕鬆創建、修改和從PDF的多個頁面提取內容,使其成為各種PDF相關應用的優秀選擇。
功能
以下是IronPDF的一些顯著功能:
- PDF生成:IronPDF允許開發者從頭創建PDF文件或將HTML內容轉換為PDF格式,便於生成動態且視覺上吸引人的報告和文檔。
- 進階文本與圖像操作:開發者可以輕鬆操作PDF文件中的文本和圖像。 IronPDF提供添加、編輯和格式化文本的功能,以及精確插入、調整大小和定位圖像。
- PDF合併與拆分:IronPDF允許將多個PDF文件合併為單個文檔並將PDF拆分為多個單獨文件,提供內容管理的靈活性。
- PDF表單支持:使用IronPDF,開發者可以處理PDF表單,允許他們填充表單域、提取表單數據,並創建互動PDF。
- PDF安全與加密:IronPDF提供添加密碼保護和加密PDF文檔的功能,確保數據安全和機密性。
- PDF註釋:開發者可以添加註釋,如評論、高亮和書籤,以增強PDF中的協作和可讀性。
- 頁眉和頁腳:IronPDF允許在PDF頁面中添加頁眉和頁腳,為文檔提供品牌和上下文。
- 條碼生成:IronPDF便於直接在PDF文檔中使用HTML生成各種類型的條碼和QR碼。
- 高性能:構建在IronPDF的.NET程式庫之上,IronPDF提供高性能和效率來處理大型PDF文件和複雜操作。
文章現按照以下進行:
- 創建Python項目
- PyPDF安裝
- IronPDF安裝
- 創建PDF文檔
- 合併PDF文件
- 拆分PDF文件
- 從PDF文件中提取文本
- 授權
- 結論
1. 創建Python項目
使用集成開發環境(IDE)進行Python項目可以顯著提高生產效率。 在流行的選擇中,我將使用PyCharm,因為它以智能代碼補全、強大的調試功能和與版本控制系統的無縫整合而脫穎而出。 如果您尚未安裝,您可以從JetBrains網站PyCharm下載,也可以使用其他任何IDE/文本編輯器進行Python程式設計,如VS Code。
在PyCharm中創建Python項目步驟:
啟動PyCharm並在歡迎畫面上點擊"創建新項目",或從菜單欄選擇文件 > 新項目。
- 選擇Python解釋器。 如果您尚未設置解釋器,請點擊齒輪圖標並配置一個新的。
- 選擇項目位置和模板。
提供項目名稱和設置,然後點擊創建。
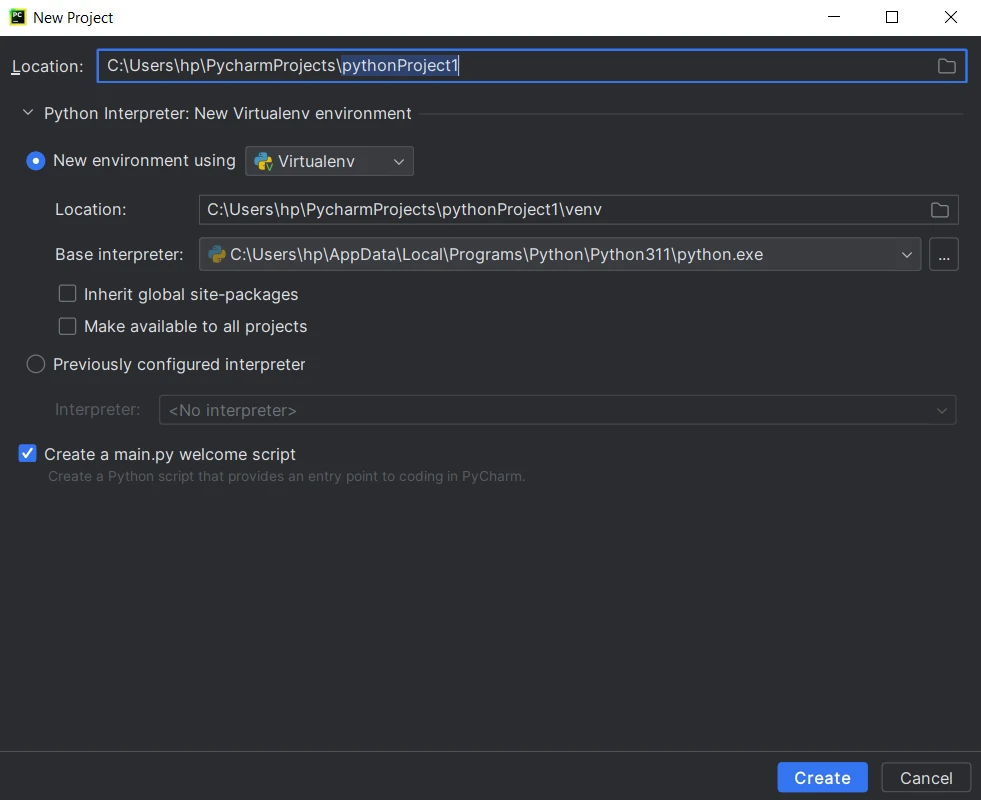
- 開始編寫代碼,運行和調試您的Python項目。
2. PyPDF安裝
PyPDF這個純Python程式庫有多種安裝方法。 我們可以使用命令提示符和PyCharm兩者進行安裝。
2.1. 使用命令提示符
- 打開電腦上的命令提示符或終端。
使用以下pip命令來安裝PyPDF:
pip install pypdfpip install pypdfSHELL- 等待PyPDF安裝完成。 您應該會看到一個成功資訊,顯示PyPDF已安裝。
您可以使用相同的過程在PyCharm終端中安裝PyPDF。
注意:Python必須添加到系統PATH環境變數中。
2.2. 使用PyCharm
- 打開PyCharm IDE。
- 創建一個新Python項目或打開一個現有項目。
- 進入項目後,點擊頂部菜單中的文件,然後選擇設置。
- 在設置窗口中,導航至"項目:
"並點擊"Python解釋器"。 在Python解釋器窗口中,點擊"+"圖標來添加新套件。
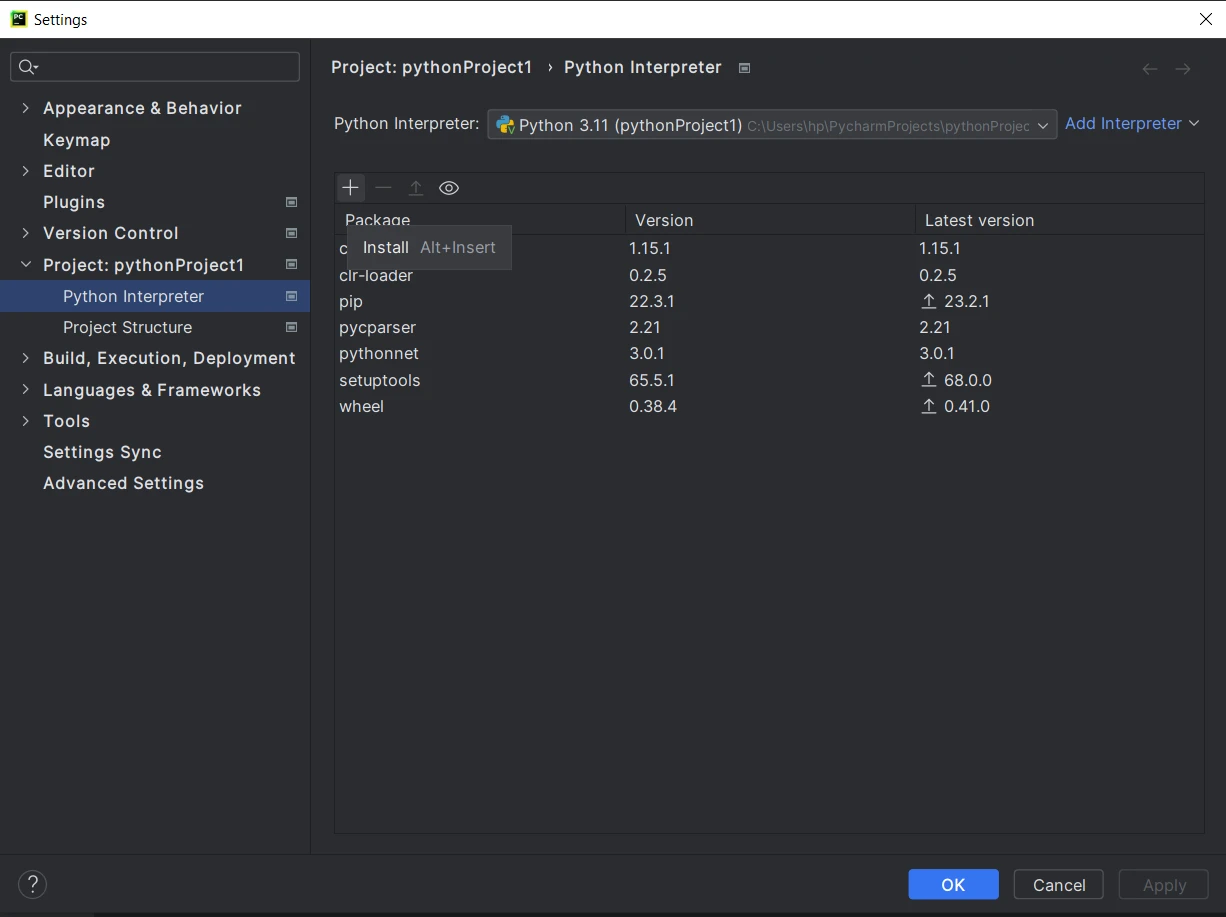
在"可用的套件"窗口中,搜尋"PyPDF"。
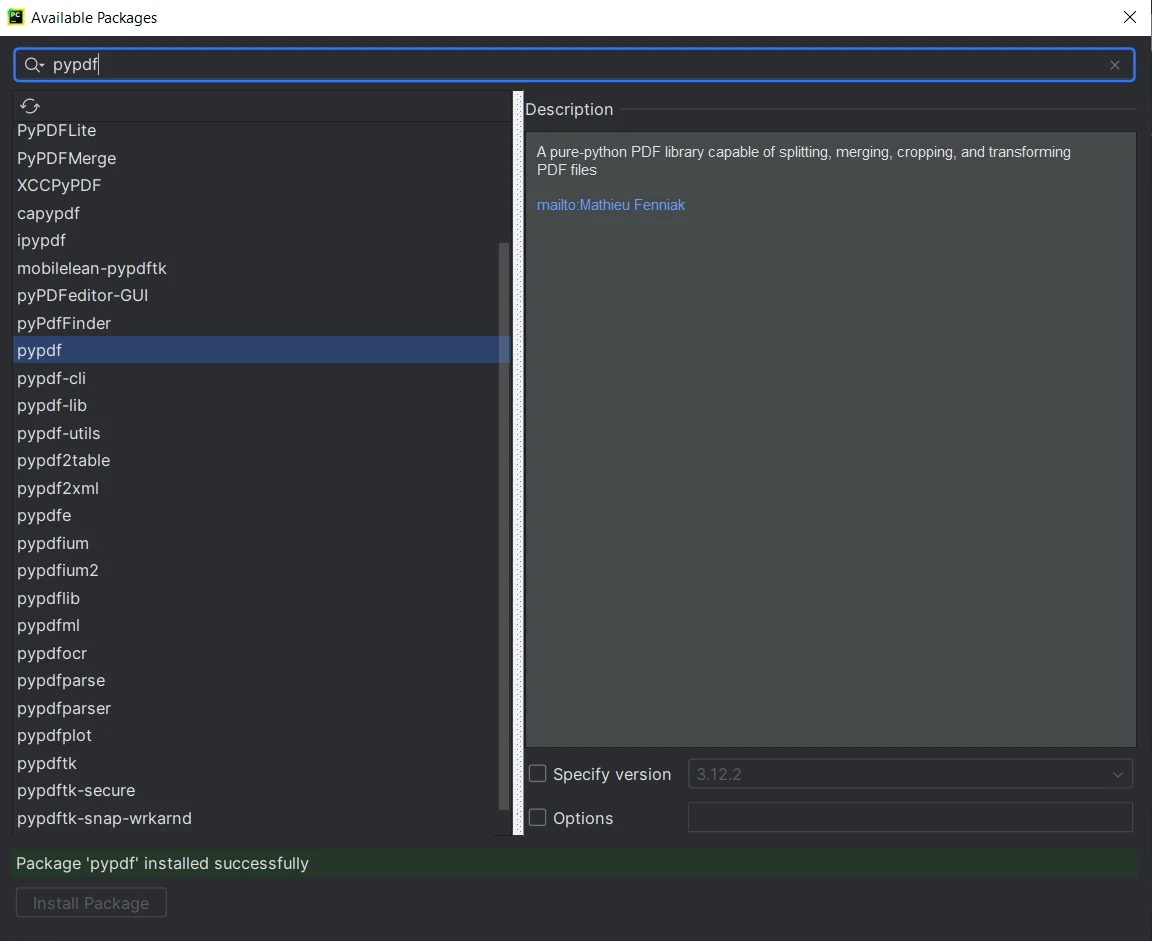
- 從列表中選擇"PyPDF"並點擊"安裝套件"按鈕。
- 等待PyCharm下載並安裝PyPDF。
3. IronPDF安裝
前提條件
IronPDF for Python使用強大的.NET 6.0技術作為基礎。 因此,要有效利用IronPDF for Python,必須在系統上安裝.NET 6.0運行時。 Linux和Mac用戶可能需要從官方Microsoft網站(https://dotnet.microsoft.com/zh-tw/download/dotnet/6.0)下載並安裝.NET,然後才能與此Python套件一起使用。 確保擁有.NET 6.0運行時將在使用IronPDF for Python進行PDF處理任務時實現無縫整合和最佳性能。
3.1. 使用命令提示符
- 打開電腦上的命令提示符或終端。
使用以下pip命令來安裝IronPDF:
pip install ironpdfpip install ironpdfSHELL- 等待安裝完成。 您應看到一個成功資訊表明IronPDF已安裝。
3.2. 使用PyCharm
- 在電腦上打開PyCharm IDE。
- 創建一個新Python項目或打開一個現有項目。
- 進入項目後,點擊"文件"在頂部菜單中並選擇"設置"。
- 在設置窗口中,導航至"項目:
"並點擊"Python解釋器"。 - 在Python解釋器窗口中,點擊"+"圖標來添加新套件。
從"可用的套件"窗口,搜尋"ironpdf"。
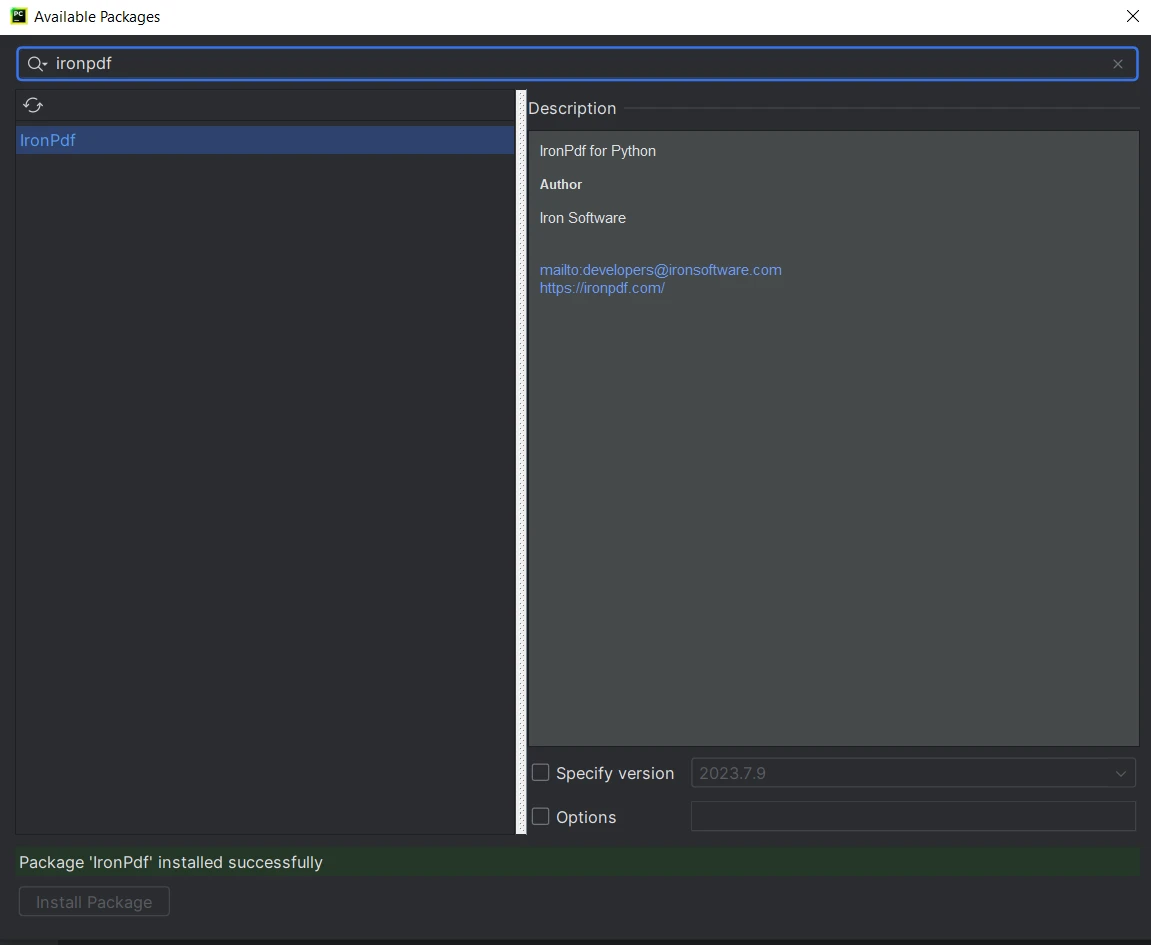
- 從列表選擇"ironpdf"並點擊"安裝套件"按鈕。
- 等待IronPDF下載並安裝。 一條成功訊息將顯示,表明IronPDF已安裝。
現在,兩個程式庫都已安裝並可以使用。 讓我們進入比較本身。
4. 創建PDF文檔
4.1. 使用PyPDF
PyPDF提供創建新PDF文件的基本功能。 然而,它沒有內建方法可以直接將HTML內容轉換為PDF。 要使用PyPDF創建新PDF,我們需要將內容添加至現有PDF或創建新空白PDF,再添加文本或圖像。 以下代碼有助於實現創建PDF文件的這一任務:
from pypdf import PdfWriter, PdfReader
# Create a new PDF file
pdf_output = PdfWriter()
# Add a new blank page
page = pdf_output.add_blank_page(width=610, height=842) # Width and height are in points (1 inch = 72 points)
# Read content from an existing PDF
with open('input.pdf', 'rb') as existing_pdf:
existing_pdf_reader = PdfReader(existing_pdf)
# Merge content from the first page of the existing PDF
page.merge_page(existing_pdf_reader.pages[0])
# Save the new PDF to a file
with open('output.pdf', 'wb') as output_file:
pdf_output.write(output_file)from pypdf import PdfWriter, PdfReader
# Create a new PDF file
pdf_output = PdfWriter()
# Add a new blank page
page = pdf_output.add_blank_page(width=610, height=842) # Width and height are in points (1 inch = 72 points)
# Read content from an existing PDF
with open('input.pdf', 'rb') as existing_pdf:
existing_pdf_reader = PdfReader(existing_pdf)
# Merge content from the first page of the existing PDF
page.merge_page(existing_pdf_reader.pages[0])
# Save the new PDF to a file
with open('output.pdf', 'wb') as output_file:
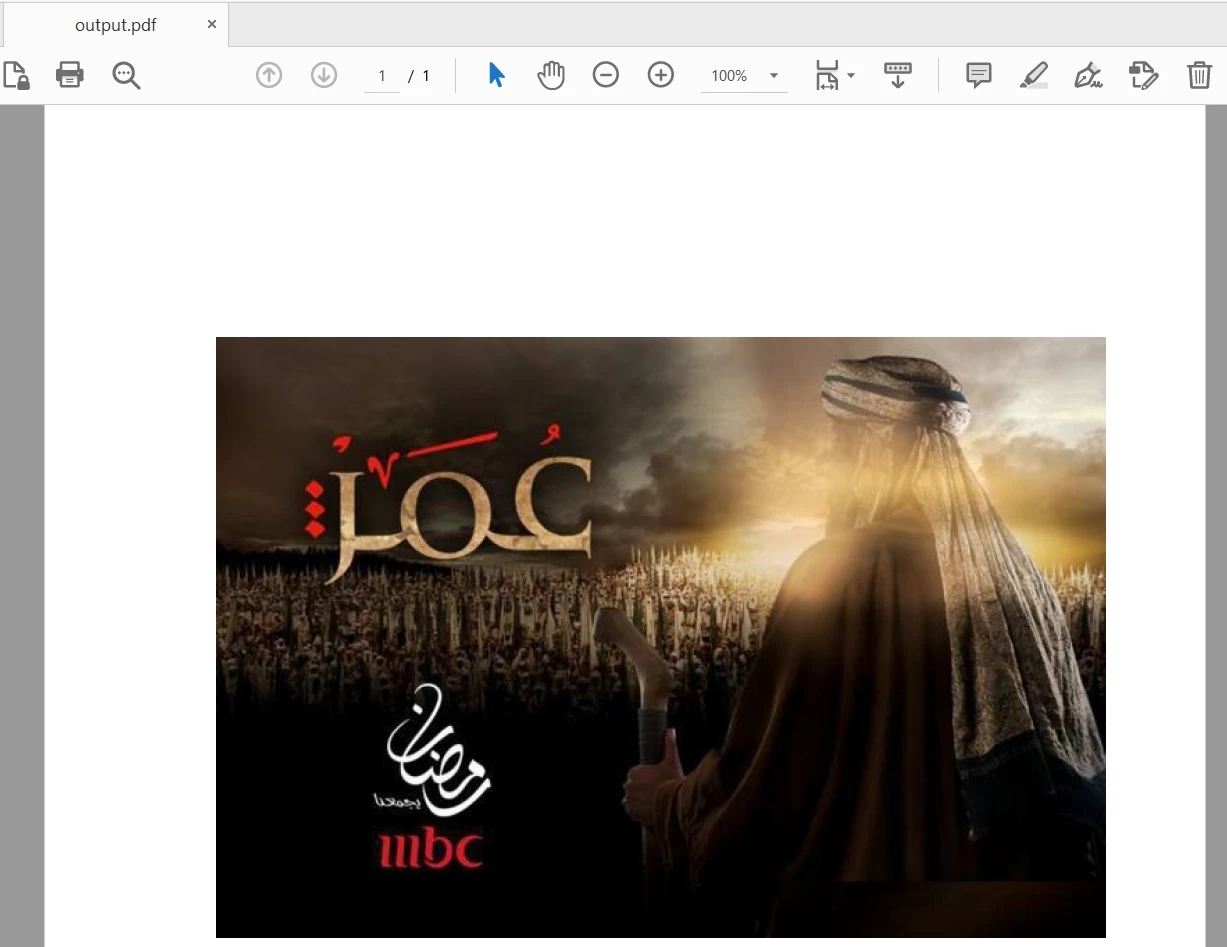
pdf_output.write(output_file)輸入文件包含28頁,僅將第一頁添加至新PDF。輸出如下:
4.2. 使用IronPDF
IronPDF提供直接從HTML內容創建新PDF文件的進階功能。 這使得在生成動態報告和文檔時無需額外步驟。 以下是範例代碼:
import ironpdf
# Set IronPDF license key to unlock full features
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
# Create a PDF from an HTML string using Python
renderer = ironpdf.ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1><p>This PDF is created using IronPDF for Python</p>")
# Export to a file or stream
pdf.SaveAs("output.pdf")
# Advanced Example with HTML Assets
# Load external html assets Images, CSS, and JavaScript.
# An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", "C:\\site\\assets")
myAdvancedPdf.SaveAs("html-with-assets.pdf")import ironpdf
# Set IronPDF license key to unlock full features
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
# Create a PDF from an HTML string using Python
renderer = ironpdf.ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1><p>This PDF is created using IronPDF for Python</p>")
# Export to a file or stream
pdf.SaveAs("output.pdf")
# Advanced Example with HTML Assets
# Load external html assets Images, CSS, and JavaScript.
# An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", "C:\\site\\assets")
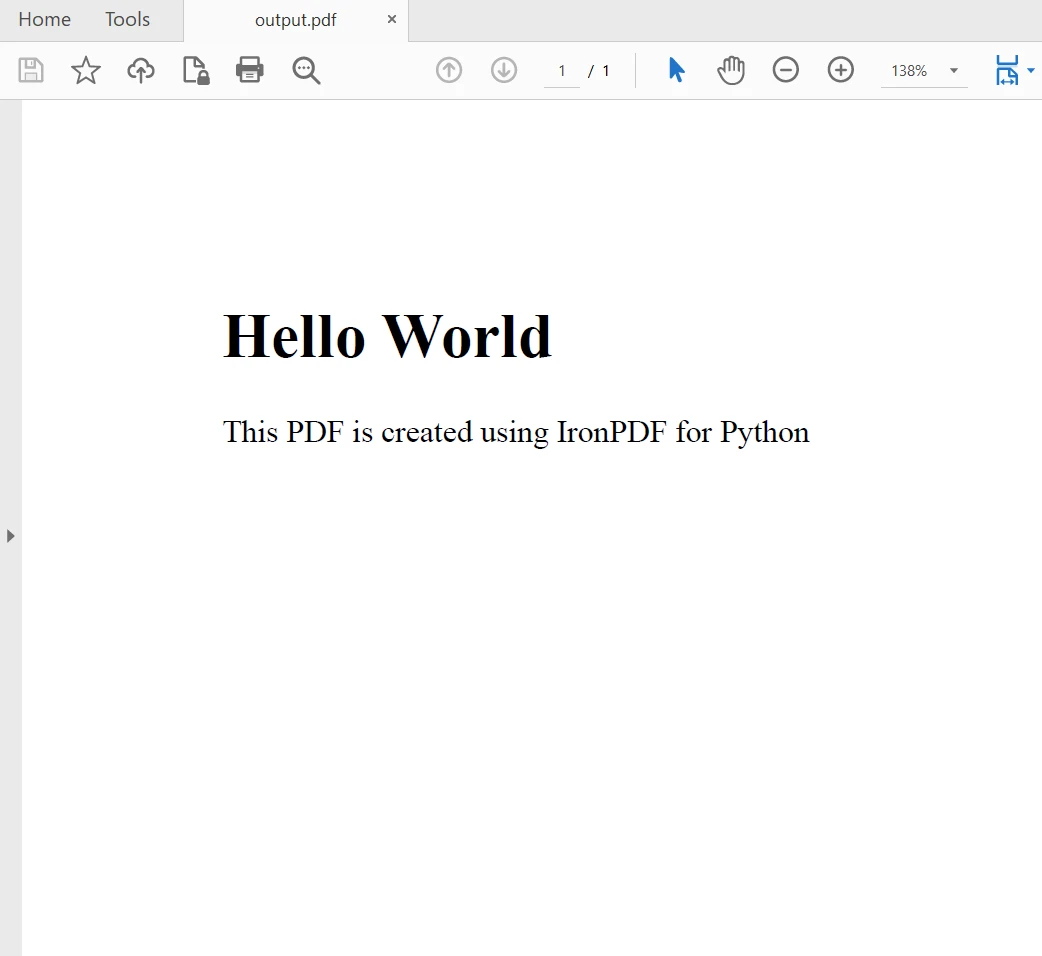
myAdvancedPdf.SaveAs("html-with-assets.pdf")在上述代碼中,我們首先應用授權金鑰以充分利用IronPDF的功能。 您也可以不使用授權金鑰,但在創建的PDF文件中會出現水印。 接著,我們創建兩個PDF文檔,首先使用HTML字符串作為內容,然後使用資源。 輸出如下:
5. 合併PDF文件
5.1. 使用PyPDF
PyPDF允許透過在一個PDF中附加頁面到另一個PDF來合併多個頁面/文檔成一個PDF。 將所有PDF文件的輸入路徑添加到列表,並使用附加方法合併生成單一文件。
from pypdf import PdfWriter
merger = PdfWriter()
for pdf in ["file1.pdf", "file2.pdf", "file3.pdf"]:
merger.append(pdf)
merger.write("merged-pdf.pdf")
merger.close()from pypdf import PdfWriter
merger = PdfWriter()
for pdf in ["file1.pdf", "file2.pdf", "file3.pdf"]:
merger.append(pdf)
merger.write("merged-pdf.pdf")
merger.close()5.2. 使用IronPDF
IronPDF還提供類似的文件合併功能,便於整合來自不同PDF來源的內容。
import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
html_a = """<p> [PDF_A] </p>
<p> [PDF_A] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_A] 2nd Page</p>"""
html_b = """<p> [PDF_B] </p>
<p> [PDF_B] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_B] 2nd Page</p>"""
renderer = ironpdf.ChromePdfRenderer()
pdfdoc_a = renderer.RenderHtmlAsPdf(html_a)
pdfdoc_b = renderer.RenderHtmlAsPdf(html_b)
merged = ironpdf.PdfDocument.Merge([pdfdoc_a, pdfdoc_b])
merged.SaveAs("Merged.pdf")import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
html_a = """<p> [PDF_A] </p>
<p> [PDF_A] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_A] 2nd Page</p>"""
html_b = """<p> [PDF_B] </p>
<p> [PDF_B] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_B] 2nd Page</p>"""
renderer = ironpdf.ChromePdfRenderer()
pdfdoc_a = renderer.RenderHtmlAsPdf(html_a)
pdfdoc_b = renderer.RenderHtmlAsPdf(html_b)
merged = ironpdf.PdfDocument.Merge([pdfdoc_a, pdfdoc_b])
merged.SaveAs("Merged.pdf")6. 拆分PDF文件
6.1. 使用PyPDF
PyPDF是一個Python程式庫,能夠將單個PDF拆分成多個獨立的PDF,每個包含一頁或多頁。
from pypdf import PdfReader, PdfWriter
# Open the PDF file
pdf_file = open('input.pdf', 'rb')
# Create a PdfFileReader object
pdf_reader = PdfReader(pdf_file)
# Split each page into separate PDFs
for page_num in range(len(pdf_reader.pages)):
pdf_writer = PdfWriter()
pdf_writer.add_page(pdf_reader.pages[page_num])
output_filename = f'page_{page_num + 1}_pypdf.pdf'
with open(output_filename, 'wb') as output_file:
pdf_writer.write(output_file)
# Close the PDF file
pdf_file.close()from pypdf import PdfReader, PdfWriter
# Open the PDF file
pdf_file = open('input.pdf', 'rb')
# Create a PdfFileReader object
pdf_reader = PdfReader(pdf_file)
# Split each page into separate PDFs
for page_num in range(len(pdf_reader.pages)):
pdf_writer = PdfWriter()
pdf_writer.add_page(pdf_reader.pages[page_num])
output_filename = f'page_{page_num + 1}_pypdf.pdf'
with open(output_filename, 'wb') as output_file:
pdf_writer.write(output_file)
# Close the PDF file
pdf_file.close()上述代碼將28頁的PDF文檔分割,將其拆分成單獨頁並保存為28新PDF文件。
6.2. 使用IronPDF
IronPDF也提供類似的拆分PDF功能,允許用戶將單個PDF拆分為多個PDF文件,每個包含單頁。 它允許我們從多頁的PDF拆分特定頁。 以下代碼有助於將文檔拆分成多個文件:
import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
html = """<p> Hello Iron </p>
<p> This is 1st Page </p>
<div style='page-break-after: always;'></div>
<p> This is 2nd Page</p>
<div style='page-break-after: always;'></div>
<p> This is 3rd Page</p>"""
renderer = ironpdf.ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(html)
# take the first page
page1doc = pdf.CopyPage(0)
page1doc.SaveAs("Split1.pdf")
# take the pages 2 & 3
page23doc = pdf.CopyPages(1, 2)
page23doc.SaveAs("Split2.pdf")import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
html = """<p> Hello Iron </p>
<p> This is 1st Page </p>
<div style='page-break-after: always;'></div>
<p> This is 2nd Page</p>
<div style='page-break-after: always;'></div>
<p> This is 3rd Page</p>"""
renderer = ironpdf.ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(html)
# take the first page
page1doc = pdf.CopyPage(0)
page1doc.SaveAs("Split1.pdf")
# take the pages 2 & 3
page23doc = pdf.CopyPages(1, 2)
page23doc.SaveAs("Split2.pdf")如需了解有關IronPDF進一步閱讀PDF文件、旋轉PDF頁面、裁剪頁面、設定擁有者/使用者密碼及其他安全選項,請訪問此IronPDF for Python程式碼範例頁面。
7. 從PDF文件中提取文本
7.1. 使用PyPDF
PyPDF提供了一個簡單的方法從PDF中提取文本。 它提供PdfReader類,允許用戶從PDF中讀取文本內容。
from pypdf import PdfReader
reader = PdfReader("input.pdf")
page = reader.pages[0]
print(page.extract_text())from pypdf import PdfReader
reader = PdfReader("input.pdf")
page = reader.pages[0]
print(page.extract_text())7.2. 使用IronPDF
IronPDF也支持使用PdfDocument類從PDF中提取文本。 它提供方法ExtractAllText從PDF中獲取文本內容。 然而,IronPDF的免費版本只能從PDF文檔中提取少量字符。 要從PDF中提取完全文本,IronPDF需要授權。 這是提取PDF文件內容的代碼範例:
import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
# Load existing PDF document
pdf = ironpdf.PdfDocument.FromFile("input.pdf")
# Extract text from PDF document
all_text = pdf.ExtractAllText()
print(all_text)import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
# Load existing PDF document
pdf = ironpdf.PdfDocument.FromFile("input.pdf")
# Extract text from PDF document
all_text = pdf.ExtractAllText()
print(all_text)如需了解更多關於提取文本的資訊,請訪問本PDF文本至Python範例。
8. 授權
PyPDF
PyPDF使用MIT授權發行,是一個開源軟體授權,以其寬鬆的條款而聞名。 MIT授權允許用戶自由使用、修改、分發和再授權PyPDF程式庫並無任何限制。 用戶不必公開使用PyPDF的應用程式源代碼,這使得它適用於個人和商業項目。
MIT授權的完整文本通常包含在PyPDF源代碼中,用戶可以在程式庫的發行中找到"授權"文件。 此外,PyPDF GitHub存放庫(https://github.com/py-pdf/pypdf)是訪問程式庫最新版和其相關授權資訊的主要來源。
IronPDF
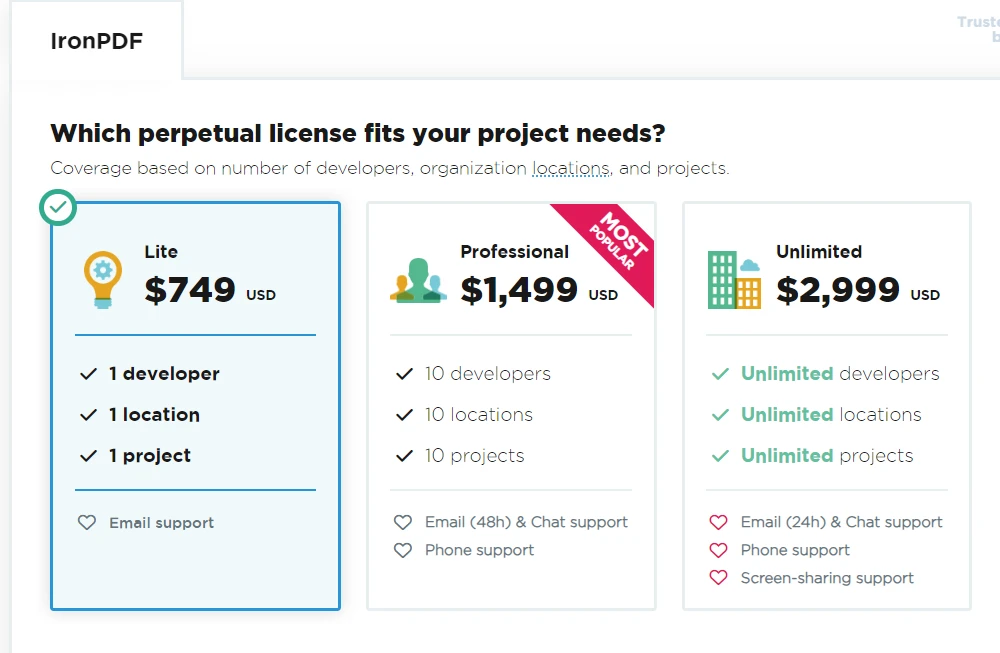
IronPDF是一種商業程式庫,並非開源。 它由Iron Software開發和分發。 使用IronPDF需要具有有效的Iron Software授權。 有不同類型的授權可用,包括評估用途的試用版和商業使用的付費授權。
由於IronPDF是商業產品,它提供了比開源替代方案更多的功能和技術支援。 要獲得IronPDF的授權,用戶可訪問官方網站,了解可用授權選項、定價和支援詳情。 其Lite套件從NVIDIA_64_LICENSE開始,並是永久授權。
9. 結論
總結
PyPDF是一個強大且易於使用的Python程式庫,主要用於處理PDF文件。 其閱讀、寫入、合併和拆分PDF的功能使其成為PDF操作任務的重要工具。 不論您是需要從PDF中提取文本,從頭創建新PDF,還是合併和拆分現有文檔,PyPDF提供了一個可靠且高效的解決方案。 通過利用PyPDF的能力,Python開發者可以簡化他們的PDF相關工作流程並提高生產力。
IronPDF是一個全面且高效的Python PDF操作程式庫,提供了廣泛的功能以讀取、創建、合併和拆分PDF文件。 不論您是需要生成動態PDF報告,從現有PDF中提取文檔資訊,還是合併多個文檔,IronPDF提供了一個可靠且易用的解決方案。 通過利用IronPDF的能力,Python開發者可以簡化其PDF相關工作流程並提高生產力。
總體比較而言,PyPDF是一個輕量級且易於使用的程式庫,適用於基本的PDF操作。 對於有簡單PDF需求的項目來說是一個好的選擇。 而另一方面,IronPDF提供了更廣泛的API和更好的性能,使其成為需要進階PDF處理能力、處理大型PDF文件和執行複雜任務的項目的理想選擇。
結論
兩個程式庫在常見的PDF任務上都有良好的編程設施。 PyPDF適合簡單的操作和快速的實施,而IronPDF則提供了更全面和多功能的API,以處理複雜的PDF相關任務。
就性能而言,IronPDF可能會優於PyPDF,特別是在處理大規模PDF文件或需要複雜PDF操作的任務時。
在選擇這兩個程式庫之間時,取決於項目的具體需求和涉及的PDF相關任務的複雜性。
IronPDF也可以進行免費試用來測試其在商業模式下的全功能。 從這裡下載針對Python的IronPDF。
常見問題解答
PyPDF 和 IronPDF 在 Python 中處理 PDF 的主要區別是什麼?
PyPDF 是一個純 Python 庫,提供基本的 PDF 操作功能,例如閱讀、寫入和合併 PDF。相比之下,IronPDF 基於 IronPDF 的 .NET 庫,提供高級功能,如 HTML 到 PDF 轉換、表單處理和高效能複雜 PDF 任務。
如何在 Python 中將 HTML 轉換為 PDF?
您可以使用 IronPDF 在 Python 中將 HTML 轉換為 PDF。它提供了像 RenderHtmlAsPdf 這樣的方法可以將 HTML 字串轉換為 PDF,還有 RenderHtmlFileAsPdf 可以將 HTML 文件轉換為 PDF。
在 Python 項目中使用 IronPDF 的安裝要求是什麼?
要在 Python 中使用 IronPDF,您需要在系統上安裝 .NET 6.0 運行時。可以使用命令 pip install ironpdf 通過 pip 安裝 IronPDF。
是否可以使用 PyPDF 提取 PDF 中的文字和圖像?
是的,PyPDF 允許從 PDF 中提取文字和圖像。它旨在用於基本的 PDF 操作任務,比如文字提取、合併和拆分 PDF。
使用 IronPDF 處理複雜 PDF 操作的優點是什麼?
IronPDF 提供強大的效能和廣泛的功能來處理複雜的 PDF 操作,包括 HTML 到 PDF 轉換、表單處理、高級文字和圖像操作,以及對大型文件的高效能操作。
我可以使用 IronPDF 合併和拆分 PDF 文件嗎?
是的,IronPDF 提供高效合併和拆分 PDF 文件的功能,為您在 Python 應用程式中管理複雜的 PDF 操作提供全面的解決方案。
在各行業中使用 PDF 的常見用途是什麼?
PDF 通常用於在各行業中共享文檔,如報告、發票、表單和電子書,因為它們在不同平台和設備上均能保持一致的外觀。
IronPDF 的許可選項有哪些?
IronPDF 是一款商業產品,需要 Iron Software 的有效許可證才能使用。有多種許可選項可供選擇,包括試用版,以滿足不同項目的需求。