
使用Python的分佈式計算
分散式 Python
在瞬息萬變的技術領域,對可擴展、高效的運算解決方案的需求比以往任何時候都更加迫切。 對於涉及大量分散式資料處理、並髮使用者請求和運算密集型任務的工作而言,分散式運算正變得越來越必要。 為了讓開發人員能夠充分利用分散式 Python,我們將在本文中探討其應用、原理和工具。
動態產生和修改 PDF 文件是 Web 開發領域的常見需求。 透過程式設計方式建立 PDF 的功能對於快速建立發票、報告和憑證非常方便。
Python 豐富的生態系統和多功能性使其能夠處理多種 PDF 庫。 IronPDF 是一個強大的解決方案,它透過簡化 PDF 的建立流程,並啟用任務並行和分散式運算,幫助開發人員充分利用其基礎設施。
理解分散式 Python
從根本上講,分散式 Python 是將計算工作分成更小的區塊,然後將它們分配給多個節點或處理單元的過程。 這些節點可以是連接到網路的單一機器、系統內的單一 CPU 核心、遠端物件、遠端函數、遠端或函數呼叫執行,甚至是單一進程內的單一執行緒。 目標是透過並行化工作負載來提高效能、可擴展性和容錯能力。
Python 易於使用、適應性強,並且具有強大的庫生態系統,因此是分散式運算工作負載的絕佳選擇。 Python 為各種規模和用例的分散式計算提供了豐富的工具,從強大的框架(如 Dask 和 Apache Spark)到內建模組(如 multiprocessing@@@--CODE-578--內建模組(如 multiprocessing@@@--CODE-578--.--CODE@P.)。
在深入探討細節之前,讓我們先來了解一下分散式 Python 所基於的基本理念和原則:
並行與並發
並行性是指同時執行多個任務,而並發性是指處理多個可能同時進行但不一定同時執行的任務。 分散式 Python 既支援並行性也支援並發性,取決於手邊的任務和系統設計。
任務分配
平行和分散式運算的關鍵組成部分是將工作分配到多個節點或處理單元上。 有效的工作分配對於優化整體效能、效率和資源利用至關重要,無論是計算程式中的函數執行在多個核心上並行化,還是資料處理管道被分成更小的階段。
溝通與協調
在分散式系統中,節點間有效的溝通與協調至關重要,它有助於協調遠端功能執行、複雜的工作流程、資料交換和計算同步。
分散式 Python 程式受益於訊息佇列、分散式資料結構和遠端過程呼叫 (RPC) 等技術,這些技術能夠實現遠端和實際函數執行之間的順暢協調和通訊。
可靠性和錯誤預防
系統透過在不同機器上添加節點或處理單元來適應不斷增長的工作負載的能力稱為可擴展性。 相反,容錯性是指系統設計能夠承受諸如機器故障、網路分區和節點崩潰等故障,並且仍然能夠可靠地運作。
為了確保分散式應用程式在多台機器上的穩定性和彈性,分散式 Python 框架通常包含容錯和自動擴展功能。
分散式 Python 的應用
資料處理與分析:可以使用分散式 Python 框架(如 Apache Spark 和 Dask)並行處理大型資料集,這使得分散式 Python 應用程式能夠大規模地執行批次、即時串流處理和機器學習等活動。
使用微服務進行 Web 開發:可擴展的 Web 應用程式和微服務架構可以透過 Python Web 框架(如 Flask 和 Django)以及分散式任務佇列(如 Celery)來建立。 Web 應用程式可以輕鬆整合分散式快取、非同步請求處理和後台作業處理等功能。
科學運算與模擬: Python 強大的科學函式庫和分散式運算框架生態系統使得在機器叢集上進行高效能運算 (HPC) 和平行模擬成為可能。 應用領域包括金融風險分析、氣候建模、機器學習應用以及物理和計算生物學模擬。
邊緣運算與物聯網 (IoT):隨著物聯網設備和邊緣運算設計的普及,分散式 Python 對於處理感測器資料、協調邊緣運算流程、建立分散式應用程式以及將分散式機器學習模型應用於現代邊緣應用程式變得越來越重要。
建立和使用分散式 Python
使用 Dask-ML 進行分散式機器學習
一個名為 Dask-ML 的強大函式庫擴展了平行計算框架 Dask,用於涉及機器學習的工作。 將任務拆分到機器叢集中的多個核心或處理器上,使得 Python 開發人員能夠以有效的分散式方式在龐大的資料集上訓練和應用機器學習模型。
import dask.dataframe as dd
from dask_ml.model_selection import train_test_split
from dask_ml.xgboost import XGBoostClassifier
from sklearn.metrics import accuracy_score
# Load and prepare data (replace with your data loading logic)
df = dd.read_csv("training_data.csv")
X = df.drop("target_column", axis=1) # Features
y = df["target_column"] # Target variable
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Define and train the XGBoost model in a distributed fashion
model = XGBoostClassifier(n_estimators=100) # Adjust hyperparameters as needed
model.fit(X_train, y_train)
# Make predictions on test data (can be further distributed)
y_pred = model.predict(X_test)
# Evaluate model performance (replace with your desired evaluation metric)
accuracy = accuracy_score(y_test, y_pred)
print(f"Model Accuracy: {accuracy}")import dask.dataframe as dd
from dask_ml.model_selection import train_test_split
from dask_ml.xgboost import XGBoostClassifier
from sklearn.metrics import accuracy_score
# Load and prepare data (replace with your data loading logic)
df = dd.read_csv("training_data.csv")
X = df.drop("target_column", axis=1) # Features
y = df["target_column"] # Target variable
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Define and train the XGBoost model in a distributed fashion
model = XGBoostClassifier(n_estimators=100) # Adjust hyperparameters as needed
model.fit(X_train, y_train)
# Make predictions on test data (can be further distributed)
y_pred = model.predict(X_test)
# Evaluate model performance (replace with your desired evaluation metric)
accuracy = accuracy_score(y_test, y_pred)
print(f"Model Accuracy: {accuracy}")使用 Ray 進行平行函數調用
透過強大的分散式運算框架 Ray,您可以在叢集的多個核心或電腦上並發執行 Python 函數或任務。 透過使用 @ray.remote 裝飾器,Ray 允許您將函數指定為遠端函數。 之後,這些遠端任務或操作可以在叢集的 Ray 工作節點上非同步執行。
import ray
import numpy as np
# Define the Monte Carlo simulation function
@ray.remote
def simulate(seed):
np.random.seed(seed) # Set random seed for reproducibility
# Perform your simulation logic here (replace with your specific simulation)
# This example simulates a random walk and returns the final position
steps = 1000
position = 0
for _ in range(steps):
position += np.random.choice([-1, 1])
return position
# Initialize Ray cluster (comment out if using existing cluster)
ray.init()
# Number of simulations to run
num_sims = 10000
# Run simulations in parallel using Ray's map function
simulations = ray.get([simulate.remote(seed) for seed in range(num_sims)])
# Analyze simulation results (calculate statistics like average final position)
average_position = np.mean(simulations)
print(f"Average final position: {average_position}")
# Shut down Ray cluster (comment out if using existing cluster)
ray.shutdown()import ray
import numpy as np
# Define the Monte Carlo simulation function
@ray.remote
def simulate(seed):
np.random.seed(seed) # Set random seed for reproducibility
# Perform your simulation logic here (replace with your specific simulation)
# This example simulates a random walk and returns the final position
steps = 1000
position = 0
for _ in range(steps):
position += np.random.choice([-1, 1])
return position
# Initialize Ray cluster (comment out if using existing cluster)
ray.init()
# Number of simulations to run
num_sims = 10000
# Run simulations in parallel using Ray's map function
simulations = ray.get([simulate.remote(seed) for seed in range(num_sims)])
# Analyze simulation results (calculate statistics like average final position)
average_position = np.mean(simulations)
print(f"Average final position: {average_position}")
# Shut down Ray cluster (comment out if using existing cluster)
ray.shutdown()入門
IronPDF是什麼?
我們可以使用眾所周知的 IronPDF for .NET 套件在.NET程式中建立、修改和渲染 PDF 文件。 處理 PDF 文件的方式有很多種:從 HTML 內容、照片或原始資料創建新的 PDF 文檔,到從現有文檔中提取文字和圖像,將 HTML 頁面轉換為 PDF,以及向現有文檔添加文字、圖像和形狀。
代碼 589 的簡潔性和易用性是其兩大主要優點。 由於 .NET 具有用戶友好的 API 和豐富的文檔,開發人員可以輕鬆地在其.NET應用程式中產生 PDF 文件。 IronPDF 的速度和效率是另外兩個特性,使開發人員能夠更輕鬆地快速產生高品質的 PDF 文件。
IronPDF的一些優點:
- 從原始資料、圖像和 HTML 建立 PDF。
- 從PDF文件中提取圖像和文字。
- 在 PDF 檔案中新增頁首、頁尾和浮水印。
- PDF 檔案受密碼和加密保護。
- 具備以電子方式填寫和簽署文件的能力。
使用IronPDF進行分散式 PDF 生成
分散式 Python 框架(例如 Dask 和 Ray)使得在叢集中的多個核心或電腦上分配任務成為可能。 這樣一來,就可以在叢集中並行執行複雜的任務,例如產生 PDF,並利用叢集中的多個核心,從而大大減少創建大量 PDF 所需的時間。
首先使用 pip 安裝 IronPDF 和 ray 函式庫:
pip install ironpdf
pip install celerypip install ironpdf
pip install celery以下是一些概念性的 Python 程式碼,示範了使用 IronPDF 和 Python 進行分散式 PDF 產生的兩種方法:
帶有中央工作節點的任務隊列
中央工作進程(worker.py):
from ironpdf import ChromePdfRenderer
from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://')
app.autodiscover_tasks()
@app.task(name='generate_pdf')
def generate_pdf(data):
print(data)
renderer = ChromePdfRenderer() # Instantiate renderer
pdf = renderer.RenderHtmlAsPdf(str(data))
pdf.SaveAs("output.pdf")
return f"PDF generated for data {data}"
if __name__ == '__main__':
app.worker_main(argv=['worker', '--loglevel=info', '--without-gossip', '--without-mingle', '--without-heartbeat', '-Ofair', '--pool=solo'])from ironpdf import ChromePdfRenderer
from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://')
app.autodiscover_tasks()
@app.task(name='generate_pdf')
def generate_pdf(data):
print(data)
renderer = ChromePdfRenderer() # Instantiate renderer
pdf = renderer.RenderHtmlAsPdf(str(data))
pdf.SaveAs("output.pdf")
return f"PDF generated for data {data}"
if __name__ == '__main__':
app.worker_main(argv=['worker', '--loglevel=info', '--without-gossip', '--without-mingle', '--without-heartbeat', '-Ofair', '--pool=solo'])客戶端腳本(client.py):
from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://localhost')
def main():
# Send task to worker
task = app.send_task('generate_pdf', args=("<h1>This is a sample PDF</h1>",))
print(task.get()) # Wait for task completion and print result
if __name__ == '__main__':
main()from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://localhost')
def main():
# Send task to worker
task = app.send_task('generate_pdf', args=("<h1>This is a sample PDF</h1>",))
print(task.get()) # Wait for task completion and print result
if __name__ == '__main__':
main()Celery 是我們所採用的任務佇列系統。 作業會連同包含 HTML 內容的資料一起傳送到中央工作節點 (worker.py)。 函數使用 IronPDF 建立 PDF 並儲存。
客戶端腳本(client.py)向佇列發送包含範例資料的任務。 可以修改此腳本,使其能夠從不同的電腦發送其他任務。
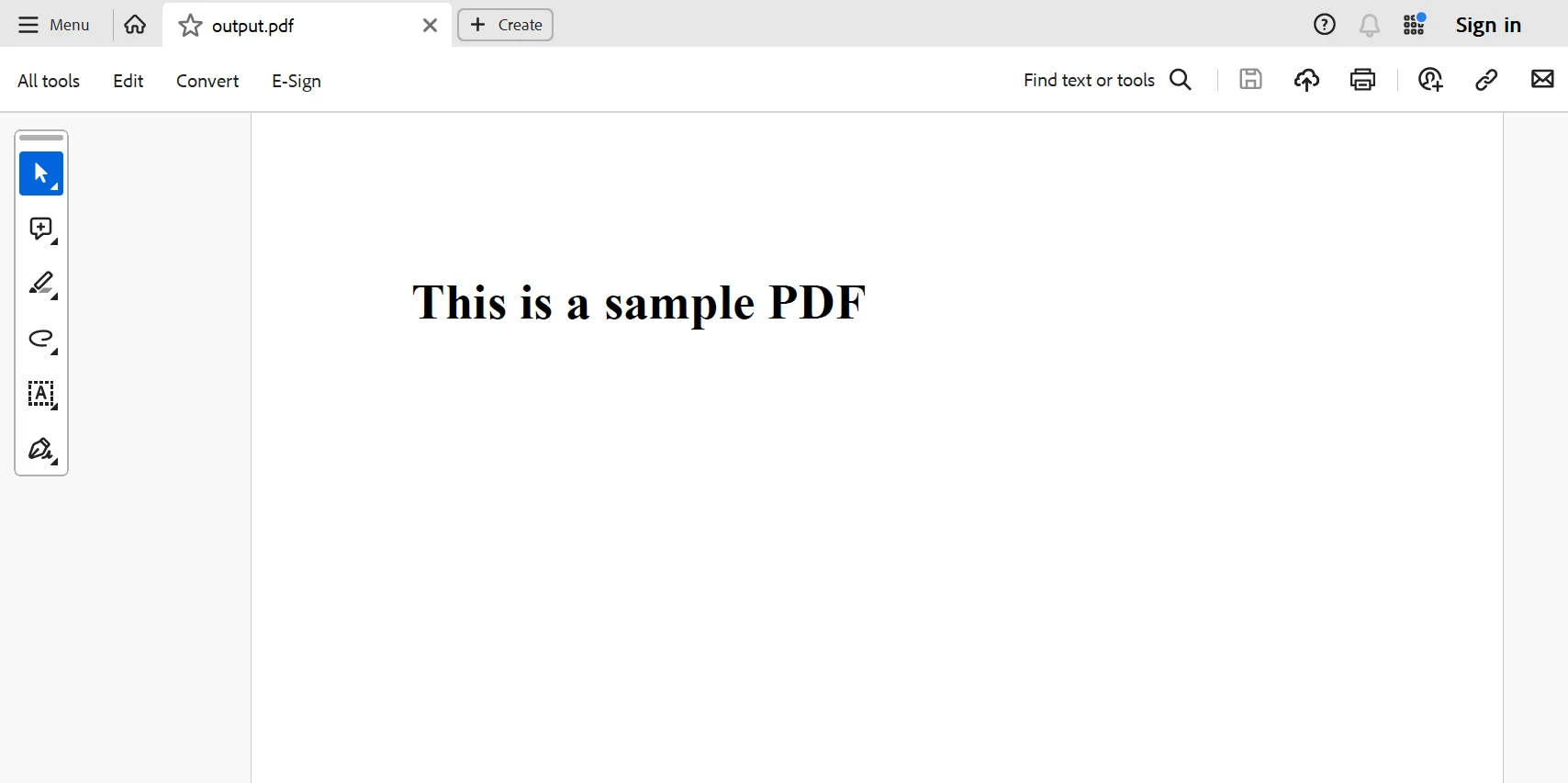
以下是根據上述程式碼產生的 PDF 檔案。
結論
使用 IronPDF 處理大規模 PDF 創建活動的用戶,可以透過利用分散式 Python 和 Ray 或 Dask 等庫來釋放巨大的潛力。 與在單一機器上執行程式碼相比,將相同的程式碼工作負載分散到多個核心上並在多台機器上使用,可顯著提高速度。
IronPDF 可以透過利用分散式 Python 程式語言,從在單一系統上建立 PDF 的強大工具增強為有效管理大型資料集的可靠解決方案。 為了在即將開展的大規模 PDF 創建專案中充分利用 IronPDF,請研究所提供的 Python 庫並嘗試這些方法!
IronPDF 以套裝形式購買價格合理,並附帶終身許可證。 軟體包物超所值,對於許多系統來說,只需 $799 即可購買。 它為許可證持有者提供全天候線上工程支援。 有關收費的更多信息,請訪問網站。若要了解Iron Software生產的產品詳情,請造訪此頁面。
















