
Grakn Python(開發者指南)
在當今的程式設計世界中,資料庫也在不斷發展,以滿足新應用程式的需求。 雖然傳統的關聯式資料庫仍在使用,但我們現在有了物件關聯映射(ORM)等進步,它允許開發人員使用更高層級的程式設計抽象與資料庫交互,而不是僅僅依賴 SQL。 這種方法簡化了資料管理,並促進了更清晰的程式碼組織。 此外,NoSQL 資料庫已成為處理非結構化資料的有用工具,尤其是在大數據應用和即時分析中。
雲端原生資料庫也產生了重大影響,它們提供可擴展、可靠且可管理的資料庫服務,從而減輕了維護底層基礎設施的負擔。 此外,NewSQL 和圖資料庫結合了 SQL 和 NoSQL 的優勢,既具備關聯式資料庫的可靠性,也具備 NoSQL 的靈活性。 這種混合配方使它們適用於許多現代應用。 透過將這些不同的資料庫類型與創新的程式設計範式結合,我們可以創建可擴展和適應性強的解決方案,以滿足當今以資料為中心的需求。 Grakn(現更名為 TypeDB)正是這一趨勢的典型代表,它支援知識圖譜的管理和查詢。本文將探討 Grakn (TypeDB) 及其與IronPDF的整合。 IronPDF 是一款以程式設計方式產生和操作 PDF 檔案的關鍵工具。
Grakn是什麼?
Grakn(現更名為 TypeDB )由 Grakn Labs 創建,是一個知識圖譜資料庫,旨在管理和分析複雜的資料網路。 它擅長對現有資料集中的複雜關係進行建模,並能為儲存的資料提供強大的推理能力。 Grakn 的查詢語言 Graql 可以進行精確的資料操作和查詢,從而能夠開發智慧系統,從複雜的資料集中提取有價值的見解。 透過利用 Grakn 的核心功能,組織可以以強大而智慧的知識表示來管理資料結構。
Graql 是 Grakn 的查詢語言,專門設計用於與 Grakn 知識圖譜模型進行有效交互,從而實現詳細而細緻的資料轉換。 由於其橫向可擴展性和處理大型資料集的能力,TypeDB 非常適合金融、醫療保健、藥物發現和網路安全等領域,在這些領域中,理解和管理複雜的圖結構至關重要。
在 Python 中安裝和設定 Grakn
安裝 Grakn
對於有興趣使用 Grakn(TypeDB)的 Python 開發人員來說,安裝 typedb-driver 函式庫是不可或缺的。 此官方用戶端方便與 TypeDB 互動。 使用以下pip指令安裝此程式庫:
pip install typedb-driverpip install typedb-driver設定 TypeDB 伺服器
在編寫程式碼之前,請確保您的 TypeDB 伺服器已啟動並正在執行。 請依照 TypeDB 網站上針對您的作業系統提供的安裝和設定說明進行操作。 安裝完成後,您可以使用下列命令啟動 TypeDB 伺服器:
./typedb server./typedb server在 Python 中使用 Grakn
使用 Python 程式碼與 TypeDB 交互
本節示範如何建立與 TypeDB 伺服器的連線、設定資料庫模式以及執行資料插入和檢索等基本操作。
建立資料庫模式
在以下程式碼區塊中,我們透過建立一個名為 person 的類型來定義資料庫結構,該類型有兩個屬性:name 和 age。 我們以 SCHEMA 模式開啟會話,從而可以進行結構修改。 以下是模式的定義和提交方式:
from typedb.driver import TypeDB, SessionType, TransactionType
# Connect to TypeDB server
client = TypeDB.core_driver("localhost:1729")
# Create a database (if not already created)
database_name = "example_db"
if not client.databases().contains(database_name):
client.databases().create(database_name)
with client.session(database_name, SessionType.SCHEMA) as session:
with session.transaction(TransactionType.WRITE) as transaction:
transaction.query().define("""
define
person sub entity, owns name, owns age;
name sub attribute, value string;
age sub attribute, value long;
""")
transaction.commit()from typedb.driver import TypeDB, SessionType, TransactionType
# Connect to TypeDB server
client = TypeDB.core_driver("localhost:1729")
# Create a database (if not already created)
database_name = "example_db"
if not client.databases().contains(database_name):
client.databases().create(database_name)
with client.session(database_name, SessionType.SCHEMA) as session:
with session.transaction(TransactionType.WRITE) as transaction:
transaction.query().define("""
define
person sub entity, owns name, owns age;
name sub attribute, value string;
age sub attribute, value long;
""")
transaction.commit()插入數據
建立好資料庫模式後,腳本會將資料插入資料庫。 我們以資料模式開啟一個會話,該模式適用於資料操作,並執行插入查詢,新增一個名為"Alice"、年齡為30的新實體:
# Insert data into the database
with client.session(database_name, SessionType.DATA) as session:
with session.transaction(TransactionType.WRITE) as transaction:
# Create a person entity
transaction.query().insert("""
insert $p isa person, has name "Alice", has age 30;
""")
transaction.commit()# Insert data into the database
with client.session(database_name, SessionType.DATA) as session:
with session.transaction(TransactionType.WRITE) as transaction:
# Create a person entity
transaction.query().insert("""
insert $p isa person, has name "Alice", has age 30;
""")
transaction.commit()查詢數據
最後,我們透過查詢名為"Alice"的實體從資料庫中檢索資訊。我們在 DATA 模式下開啟新會話,並使用 TransactionType.READ 發起讀取事務。 處理結果後,提取並顯示姓名和年齡:
# Query the data from the database
with client.session(database_name, SessionType.DATA) as session:
with session.transaction(TransactionType.READ) as transaction:
# Query entities where the person has the name 'Alice'
results = transaction.query().match("""
match
$p isa person, has name "Alice";
$p has name $n, has age $a;
get;
""")
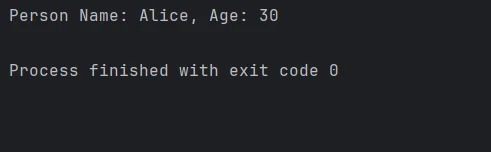
for result in results:
person_name = result.get("n").get_value()
person_age = result.get("a").get_value()
print(f"Person Name: {person_name}, Age: {person_age}")# Query the data from the database
with client.session(database_name, SessionType.DATA) as session:
with session.transaction(TransactionType.READ) as transaction:
# Query entities where the person has the name 'Alice'
results = transaction.query().match("""
match
$p isa person, has name "Alice";
$p has name $n, has age $a;
get;
""")
for result in results:
person_name = result.get("n").get_value()
person_age = result.get("a").get_value()
print(f"Person Name: {person_name}, Age: {person_age}")輸出
關閉客戶端連接
為了正確釋放資源並防止與 TypeDB 伺服器進一步交互,請使用以下命令關閉客戶端連線:client.close():
# Close the client connection
client.close()# Close the client connection
client.close()IronPDF簡介
IronPDF for Python 是一個功能強大的函式庫,可用於以程式設計方式建立和操作 PDF 檔案。 它提供了從 HTML 建立 PDF、合併 PDF 文件以及註釋現有 PDF 文件的全面功能。 IronPDF還可以將 HTML 或網頁內容轉換為高品質的 PDF,使其成為產生報告、發票和其他固定佈局文件的理想選擇。
該庫提供高級功能,例如內容提取、文件加密和頁面佈局自訂。 透過將IronPDF整合到 Python 應用程式中,開發人員可以自動化文件產生工作流程,並增強其 PDF 處理的整體功能。
安裝IronPDF庫
若要在 Python 中啟用IronPDF功能,請使用 pip 安裝程式庫:
pip install ironpdfpip install ironpdf將 Grakn TypeDB 與IronPDF集成
透過在 Python 環境中結合 TypeDB 和IronPDF ,開發人員可以基於 Grakn (TypeDB) 資料庫中複雜結構化的數據,有效地產生和管理 PDF 文件。 以下是一個整合範例:
from typedb.driver import TypeDB, SessionType, TransactionType
from ironpdf import *
import warnings
# Suppress potential warnings
warnings.filterwarnings('ignore')
# Replace with your own license key
License.LicenseKey = "YOUR LICENSE KEY GOES HERE"
# Initialize data list
data = []
# Connect to TypeDB server
client = TypeDB.core_driver("localhost:1729")
# Query the data from the database
with client.session(database_name, SessionType.DATA) as session:
with session.transaction(TransactionType.READ) as transaction:
# Fetch details of persons named 'Alice'
results = transaction.query().match("""
match
$p isa person, has name "Alice";
$p has name $n, has age $a;
get;
""")
for result in results:
person_name = result.get("n").get_value()
person_age = result.get("a").get_value()
data.append({"name": person_name, "age": person_age})
# Close the client connection
client.close()
# Create a PDF from HTML content
html_to_pdf = ChromePdfRenderer()
content = "<h1>Person Report</h1>"
for item in data:
content += f"<p>Name: {item['name']}, Age: {item['age']}</p>"
# Render the HTML content as a PDF
pdf_document = html_to_pdf.RenderHtmlAsPdf(content)
# Save the PDF to a file
pdf_document.SaveAs("output.pdf")from typedb.driver import TypeDB, SessionType, TransactionType
from ironpdf import *
import warnings
# Suppress potential warnings
warnings.filterwarnings('ignore')
# Replace with your own license key
License.LicenseKey = "YOUR LICENSE KEY GOES HERE"
# Initialize data list
data = []
# Connect to TypeDB server
client = TypeDB.core_driver("localhost:1729")
# Query the data from the database
with client.session(database_name, SessionType.DATA) as session:
with session.transaction(TransactionType.READ) as transaction:
# Fetch details of persons named 'Alice'
results = transaction.query().match("""
match
$p isa person, has name "Alice";
$p has name $n, has age $a;
get;
""")
for result in results:
person_name = result.get("n").get_value()
person_age = result.get("a").get_value()
data.append({"name": person_name, "age": person_age})
# Close the client connection
client.close()
# Create a PDF from HTML content
html_to_pdf = ChromePdfRenderer()
content = "<h1>Person Report</h1>"
for item in data:
content += f"<p>Name: {item['name']}, Age: {item['age']}</p>"
# Render the HTML content as a PDF
pdf_document = html_to_pdf.RenderHtmlAsPdf(content)
# Save the PDF to a file
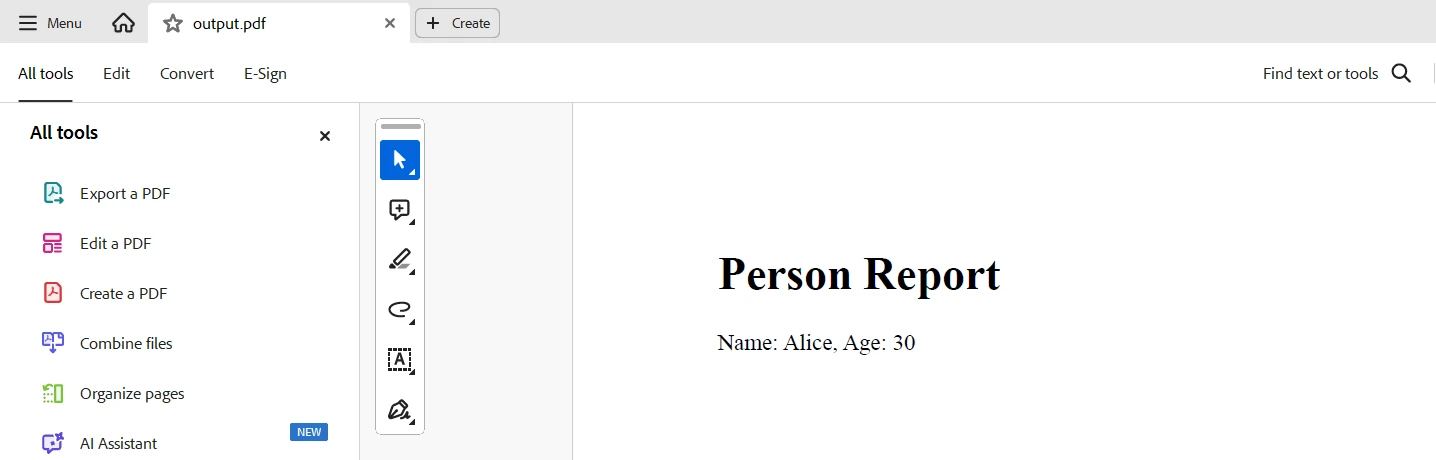
pdf_document.SaveAs("output.pdf")這段程式碼示範如何在 Python 中使用 TypeDB 和IronPDF從 TypeDB 資料庫中提取資料並產生 PDF 報告。 它連接到本機 TypeDB 伺服器,取得名為"Alice"的實體,並檢索它們的姓名和年齡。 然後使用結果建立 HTML 內容,使用 IronPDF 的 ChromePdfRenderer 將其轉換為 PDF 文檔,並儲存為"output.pdf"。
輸出
授權
需要許可證金鑰才能去除產生的 PDF 文件中的浮水印。 您可以透過此連結註冊免費試用。 請注意,註冊時無需提供信用卡資訊; 免費試用版只需要一個電子郵件地址。
結論
Grakn(現為 TypeDB)與IronPDF集成,為管理和分析 PDF 文件中的大量資料提供了一個強大的解決方案。 透過 IronPDF 的資料擷取和處理能力,以及 Grakn 在複雜關係建模和推理方面的精湛技術,您可以將非結構化文件資料轉換為結構化的、可查詢的資訊。
這種整合簡化了從 PDF 中提取有價值見解的過程,提高了查詢和分析能力,並提高了精確度。 透過將 Grakn 的高階資料管理與 IronPDF 的 PDF 處理功能結合,您可以開發更有效率的資訊處理方式,以便更好地進行決策並更深入地了解複雜的資料集。 IronSoftware也提供各種函式庫,方便跨多個作業系統和平台(包括 Windows、Android、macOS、Linux 等)進行應用程式開發。
















