
msgpack python(开发人员如何使用)
MessagePack 是一种高效的二进制序列化格式,允许多种语言之间的数据交换。 它类似于JSON,但速度更快且更紧凑。 Python中的msgpack库提供了用于处理这种格式的必要工具,提供了CPython绑定和纯Python实现。
MessagePack的主要特性
1.效率: MessagePack 的设计目标是在速度和大小方面都比 JSON 更高效。它通过二进制格式(msgpack 规范)实现这一点,从而减少了与 JSON 等基于文本的格式相关的开销。 2.跨语言支持: MessagePack 支持多种编程语言,使其成为需要在不同的系统和语言之间共享数据的应用程序的理想选择。 3.兼容性: Python 中的 msgpack 库与 Python 2 和 Python 3 以及 CPython 和 PyPy 实现均兼容。 4.自定义数据类型: MessagePack 允许对自定义数据类型进行打包和解包,并提供高级解包控制,这对于复杂的应用程序非常有用。
安装
在您开始读写MessagePack数据之前,您需要安装msgpack库,可以使用pip进行安装:
pip install msgpackpip install msgpack基本用法
这里是一个如何使用MessagePack序列化和反序列化数据的简单示例:
import msgpack
# Serialize key-value pairs or file-like object
data = {'key': 'value', 'number': 42}
packed_data = msgpack.packb(data, use_bin_type=True)
# Deserialize data
unpacked_data = msgpack.unpackb(packed_data, raw=False)
print(unpacked_data)import msgpack
# Serialize key-value pairs or file-like object
data = {'key': 'value', 'number': 42}
packed_data = msgpack.packb(data, use_bin_type=True)
# Deserialize data
unpacked_data = msgpack.unpackb(packed_data, raw=False)
print(unpacked_data)高级功能
1.流式解包: MessagePack 支持流式解包,它可以从单个流中解包多个对象。 这对于处理大型数据集或连续数据流非常有用。
import msgpack
from io import BytesIO
# Create a buffer for streaming data
buf = BytesIO()
for i in range(100):
buf.write(msgpack.packb(i))
buf.seek(0)
# Unpack data from the buffer
unpacker = msgpack.Unpacker(buf)
for unpacked in unpacker:
print(unpacked)import msgpack
from io import BytesIO
# Create a buffer for streaming data
buf = BytesIO()
for i in range(100):
buf.write(msgpack.packb(i))
buf.seek(0)
# Unpack data from the buffer
unpacker = msgpack.Unpacker(buf)
for unpacked in unpacker:
print(unpacked)2.自定义数据类型:您可以为自定义数据类型定义自定义打包和解包函数。例如,要处理 datetime 自定义数据类型:
import datetime
import msgpack
def encode_datetime(obj):
"""Encode datetime objects for MessagePack serialization."""
if isinstance(obj, datetime.datetime):
return {'__datetime__': True, 'as_str': obj.strftime('%Y%m%dT%H:%M:%S.%f')}
return obj
def decode_datetime(obj):
"""Decode datetime objects after MessagePack deserialization."""
if '__datetime__' in obj:
return datetime.datetime.strptime(obj['as_str'], '%Y%m%dT%H:%M:%S.%f')
return obj
# Serialize data with custom datetime support
data = {'time': datetime.datetime.now()}
packed_data = msgpack.packb(data, default=encode_datetime)
# Deserialize data with custom datetime support
unpacked_data = msgpack.unpackb(packed_data, object_hook=decode_datetime)
print(unpacked_data)import datetime
import msgpack
def encode_datetime(obj):
"""Encode datetime objects for MessagePack serialization."""
if isinstance(obj, datetime.datetime):
return {'__datetime__': True, 'as_str': obj.strftime('%Y%m%dT%H:%M:%S.%f')}
return obj
def decode_datetime(obj):
"""Decode datetime objects after MessagePack deserialization."""
if '__datetime__' in obj:
return datetime.datetime.strptime(obj['as_str'], '%Y%m%dT%H:%M:%S.%f')
return obj
# Serialize data with custom datetime support
data = {'time': datetime.datetime.now()}
packed_data = msgpack.packb(data, default=encode_datetime)
# Deserialize data with custom datetime support
unpacked_data = msgpack.unpackb(packed_data, object_hook=decode_datetime)
print(unpacked_data)IronPDF 简介
IronPDF 是一个强大的Python库,旨在使用HTML、CSS、图像和JavaScript创建、编辑和签署PDF。 它提供商业级性能,并具有低内存占用。 关键特性包括:
HTML 至 PDF 转换
转换HTML文件、HTML字符串和URL为PDF。 例如,使用Chrome PDF渲染器将网页呈现为PDF。
跨平台支持
兼容各种.NET平台,包括.NET Core、.NET Standard和.NET Framework。 它支持Windows、Linux和macOS。
编辑和签名
设置属性,使用密码和权限增加安全性,并应用数字签名到您的PDF。
页面模板和设置
通过页眉、页脚、页码和可调节边距自定义PDF。 支持响应式布局和自定义纸张大小。
标准合规
遵循PDF标准,如PDF/A和PDF/UA。 支持UTF-8字符编码,并处理图像、CSS和字体等资产。
使用IronPDF和msgpack生成PDF文档
import msgpack
import datetime
from ironpdf import *
# Apply your license key for IronPDF
License.LicenseKey = "key"
# Serialize data
data = {'key': 'value', 'number': 42}
packed_data = msgpack.packb(data, use_bin_type=True)
# Deserialize data
unpacked_data = msgpack.unpackb(packed_data, raw=False)
print(unpacked_data)
# Custom Data Types
def encode_datetime(obj):
"""Encode datetime objects for MessagePack serialization."""
if isinstance(obj, datetime.datetime):
return {'__datetime__': True, 'as_str': obj.strftime('%Y%m%dT%H:%M:%S.%f')}
return obj
def decode_datetime(obj):
"""Decode datetime objects after MessagePack deserialization."""
if '__datetime__' in obj:
return datetime.datetime.strptime(obj['as_str'], '%Y%m%dT%H:%M:%S.%f')
return obj
datat = {'time': datetime.datetime.now()}
packed_datat = msgpack.packb(datat, default=encode_datetime)
unpacked_datat = msgpack.unpackb(packed_datat, object_hook=decode_datetime)
print(unpacked_datat)
# Render a PDF from a HTML string using Python
renderer = ChromePdfRenderer()
content = "<h1>Awesome Iron PDF with msgpack</h1>"
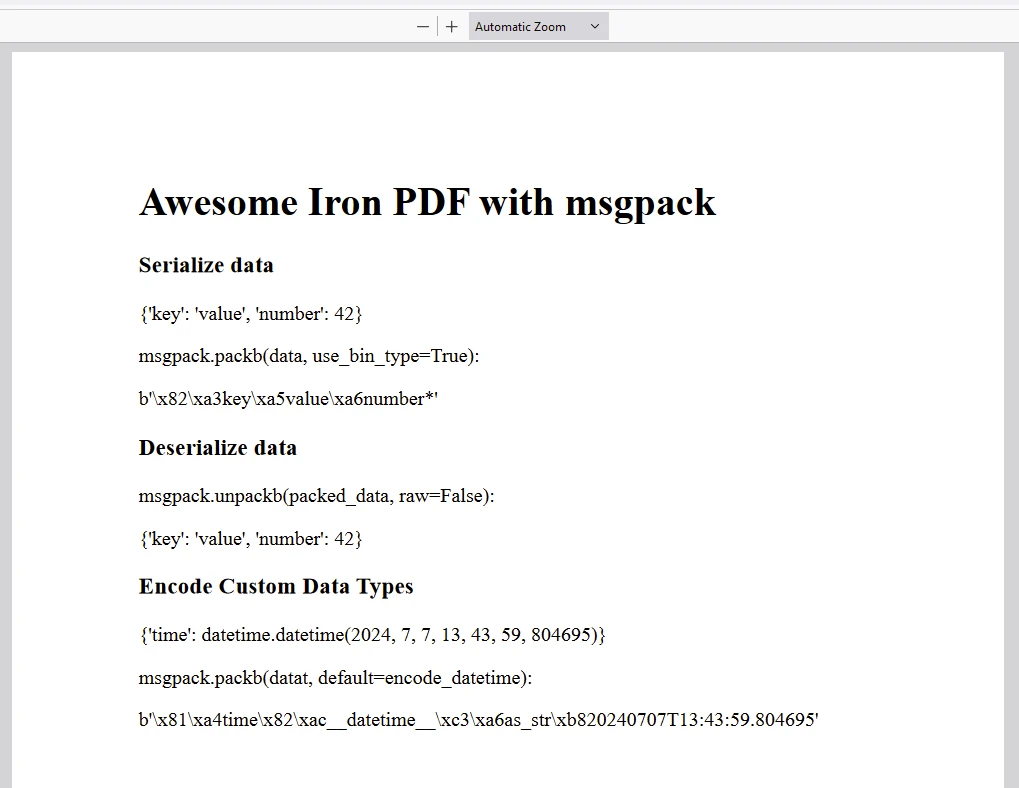
content += "<h3>Serialize data</h3>"
content += f"<p>{data}</p>"
content += f"<p> msgpack.packb(data, use_bin_type=True):</p><p>{packed_data}</p>"
content += "<h3>Deserialize data</h3>"
content += f"<p> msgpack.unpackb(packed_data, raw=False):</p><p>{unpacked_data}</p>"
content += "<h3>Encode Custom Data Types</h3>"
content += f"<p>{datat}</p>"
content += f"<p> msgpack.packb(datat, default=encode_datetime):</p><p>{packed_datat}</p>"
pdf = renderer.RenderHtmlAsPdf(content)
pdf.SaveAs("Demo-msgpack.pdf") # Export to a fileimport msgpack
import datetime
from ironpdf import *
# Apply your license key for IronPDF
License.LicenseKey = "key"
# Serialize data
data = {'key': 'value', 'number': 42}
packed_data = msgpack.packb(data, use_bin_type=True)
# Deserialize data
unpacked_data = msgpack.unpackb(packed_data, raw=False)
print(unpacked_data)
# Custom Data Types
def encode_datetime(obj):
"""Encode datetime objects for MessagePack serialization."""
if isinstance(obj, datetime.datetime):
return {'__datetime__': True, 'as_str': obj.strftime('%Y%m%dT%H:%M:%S.%f')}
return obj
def decode_datetime(obj):
"""Decode datetime objects after MessagePack deserialization."""
if '__datetime__' in obj:
return datetime.datetime.strptime(obj['as_str'], '%Y%m%dT%H:%M:%S.%f')
return obj
datat = {'time': datetime.datetime.now()}
packed_datat = msgpack.packb(datat, default=encode_datetime)
unpacked_datat = msgpack.unpackb(packed_datat, object_hook=decode_datetime)
print(unpacked_datat)
# Render a PDF from a HTML string using Python
renderer = ChromePdfRenderer()
content = "<h1>Awesome Iron PDF with msgpack</h1>"
content += "<h3>Serialize data</h3>"
content += f"<p>{data}</p>"
content += f"<p> msgpack.packb(data, use_bin_type=True):</p><p>{packed_data}</p>"
content += "<h3>Deserialize data</h3>"
content += f"<p> msgpack.unpackb(packed_data, raw=False):</p><p>{unpacked_data}</p>"
content += "<h3>Encode Custom Data Types</h3>"
content += f"<p>{datat}</p>"
content += f"<p> msgpack.packb(datat, default=encode_datetime):</p><p>{packed_datat}</p>"
pdf = renderer.RenderHtmlAsPdf(content)
pdf.SaveAs("Demo-msgpack.pdf") # Export to a file代码解释
这个脚本演示了msgpack与IronPDF的集成,用于序列化和反序列化数据,以及从HTML内容创建PDF文档。
细节解析
使用msgpack序列化数据:
- 使用
packed_data)。
- 使用
使用msgpack反序列化数据:
- 使用
unpacked_data)。
- 使用
自定义数据类型处理:
- 定义自定义编码(
decode_datetime)函数,以便在使用msgpack进行序列化和反序列化时处理日期时间对象。
- 定义自定义编码(
用于PDF生成的HTML内容:
- 构建一个包含以下内容的HTML字符串(
content):- 头部和子章节详细说明序列化数据(
packed_data)。 - 反序列化数据(
unpacked_data)。 - 自定义数据类型序列化(
packed_datat)。
- 头部和子章节详细说明序列化数据(
- 构建一个包含以下内容的HTML字符串(
使用IronPDF生成PDF:
- 使用IronPDF(ChromePdfRenderer)从构建的HTML内容(
pdf)。
- 使用IronPDF(ChromePdfRenderer)从构建的HTML内容(
- 保存PDF:
- 将生成的PDF文档保存为"Demo-msgpack.pdf"。
输出

IronPDF 许可证
IronPDF 使用Python的许可证密钥运行。 IronPDF for Python提供免费试用许可证密钥,以便用户在购买前查看其广泛的功能。
在使用IronPDF包之前,将许可证密钥放在脚本的开头:
from ironpdf import *
# Apply your license key
License.LicenseKey = "key"from ironpdf import *
# Apply your license key
License.LicenseKey = "key"结论
MessagePack是Python中高效数据序列化的强大工具。 其紧凑的二进制格式、跨语言支持以及处理自定义数据类型的能力,使其成为各种应用程序的多功能选择。 无论您是在进行不同系统之间的数据交换,还是在优化数据处理任务的性能,MessagePack都提供了一个强大的解决方案。
IronPDF 是一个多用途的Python库,专为从Python应用程序中直接创建、操作和渲染PDF文档而设计。 它简化了将HTML转换为PDF、创建交互式PDF表单以及执行各种文档操作(如合并和拆分PDF文件)等任务。 通过无缝集成到现有Web技术中,IronPDF为开发者提供了一套强大的工具,用于生成动态PDF,在文档管理和呈现任务中提高生产力。
















