
PyYAML(开发人员如何使用)
PyYAML 是一个 Python 库,可用作 YAML 的解析器和发射器。 YAML(YAML 不是标记语言)是一种面向人类可读的数据序列化格式,与 Python 应用程序集成良好,具有出色的错误支持、强大的扩展 API 等功能。 YAML 通常用于配置文件和在不同数据结构的语言之间进行数据交换,旨在便于人类阅读。 在本文的后面部分,我们将了解来自 Iron Software 的 PDF 生成 Python 包 IronPDF。
PyYAML 的关键特性
1.人类可读格式: YAML 的设计宗旨是易于阅读和编写,使其成为复杂配置文件和数据序列化的理想选择。 2.完全支持 YAML 1.1: PyYAML 支持完整的 YAML 1.1 规范,包括 Unicode 支持和自定义数据类型。 3.与 Python 集成: PyYAML 提供 Python 特有的标签,允许表示任意 Python 对象,使其适用于各种应用程序。 4.错误处理: PyYAML 提供合理的错误信息,这在调试过程中非常有用。
安装
要安装 YAML 包,可以使用 pip:
pip install pyyamlpip install pyyaml基本用法
这是一个如何使用 PyYAML 将 YAML 文档加载到任意 Python 对象并从中导出的简单示例。
import yaml
# Sample YAML data
yaml_data = """
name: John Doe
age: 30
children:
- name: Jane Doe
age: 10
- name: Jim Doe
age: 8
"""
# Load YAML data into a Python dictionary
data = yaml.safe_load(yaml_data)
print(data)
# Dump Python data back to formatted YAML
yaml_output = yaml.dump(data, default_flow_style=False)
print(yaml_output)import yaml
# Sample YAML data
yaml_data = """
name: John Doe
age: 30
children:
- name: Jane Doe
age: 10
- name: Jim Doe
age: 8
"""
# Load YAML data into a Python dictionary
data = yaml.safe_load(yaml_data)
print(data)
# Dump Python data back to formatted YAML
yaml_output = yaml.dump(data, default_flow_style=False)
print(yaml_output)输出

高级功能
1.自定义数据类型: PyYAML 允许您定义自定义构造函数和表示器,以处理规范 YAML 格式的复杂数据类型。
import yaml
# Define a custom Python object
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
# Function to convert a Person object to a YAML representation
def person_representer(dumper, data):
return dumper.represent_mapping('!Person', {'name': data.name, 'age': data.age})
# Function to create a Person object from YAML representation
def person_constructor(loader, node):
values = loader.construct_mapping(node)
return Person(**values)
# Register custom representer and constructor for Person
yaml.add_representer(Person, person_representer)
yaml.add_constructor('!Person', person_constructor)
# Object Serialization
person = Person(name='John Doe', age=30)
yaml_data = yaml.dump(person)
print(yaml_data)
# Deserialize YAML to a Person object
loaded_person = yaml.load(yaml_data, Loader=yaml.FullLoader)
print(loaded_person.name, loaded_person.age)import yaml
# Define a custom Python object
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
# Function to convert a Person object to a YAML representation
def person_representer(dumper, data):
return dumper.represent_mapping('!Person', {'name': data.name, 'age': data.age})
# Function to create a Person object from YAML representation
def person_constructor(loader, node):
values = loader.construct_mapping(node)
return Person(**values)
# Register custom representer and constructor for Person
yaml.add_representer(Person, person_representer)
yaml.add_constructor('!Person', person_constructor)
# Object Serialization
person = Person(name='John Doe', age=30)
yaml_data = yaml.dump(person)
print(yaml_data)
# Deserialize YAML to a Person object
loaded_person = yaml.load(yaml_data, Loader=yaml.FullLoader)
print(loaded_person.name, loaded_person.age)输出

2.处理大型文件: PyYAML 可以通过基于流的加载和转储高效地处理多个 YAML 文档或大型 YAML 文件。
import yaml
# Load a large YAML file
with open('large_file.yaml', 'r') as file:
data = yaml.safe_load(file)
# Dump data to a large YAML file
with open('output_file.yaml', 'w') as file:
yaml.dump(data, file)import yaml
# Load a large YAML file
with open('large_file.yaml', 'r') as file:
data = yaml.safe_load(file)
# Dump data to a large YAML file
with open('output_file.yaml', 'w') as file:
yaml.dump(data, file)输出
![]()
IronPDF 简介
IronPDF 是一个强大的Python库,旨在使用HTML、CSS、图像和JavaScript创建、编辑和签署PDF。 它提供商业级性能,并具有低内存占用。 关键特性包括:
- HTML 转 PDF:将 HTML 文件、HTML 字符串和 URL 转换为 PDF。 例如,使用Chrome PDF渲染器将网页呈现为PDF。
-跨平台支持:兼容各种.NET平台,包括.NET Core、 .NET Standard和.NET Framework。 它支持Windows、Linux和macOS。
-编辑和签名:设置属性,使用密码和权限添加安全性,并将数字签名应用于您的 PDF。
-页面模板和设置:自定义 PDF,包括页眉、页脚、页码和可调整的边距。 IronPDF 支持响应式布局和自定义纸张尺寸。
-标准合规性: IronPDF遵循 PDF/A 和 PDF/UA 等 PDF 标准。 它支持UTF-8字符编码,并且可以处理像图像、CSS和字体这样的资产。
使用 IronPDF 和 PyYAML 生成 PDF 文档
import yaml
import json
from ironpdf import *
# Apply your license key
License.LicenseKey = "your license"
# Sample YAML data
yaml_data = """
name: IronPDF User1
age: 25
children:
- name: IronPDF User2
age: 23
- name: IronPDF User3
age: 24
"""
# Load YAML data into Python structures
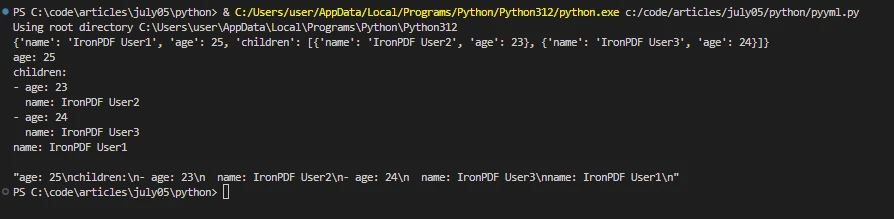
data = yaml.safe_load(yaml_data)
print(data)
# Dump Python data back to YAML
yaml_output = yaml.dump(data, default_flow_style=False)
print(yaml_output)
# Write YAML to File
with open('output_file.yaml', 'w') as file:
yaml.dump(yaml_output, file)
# Write YAML data as JSON
with open('output_file.json', 'w') as json_file:
json.dump(data, json_file)
# Read JSON and format with indentation for readability
output = json.dumps(json.load(open('output_file.json')), indent=2)
print(output)
# Create PDF renderer
renderer = ChromePdfRenderer()
# Create a PDF from HTML containing YAML data
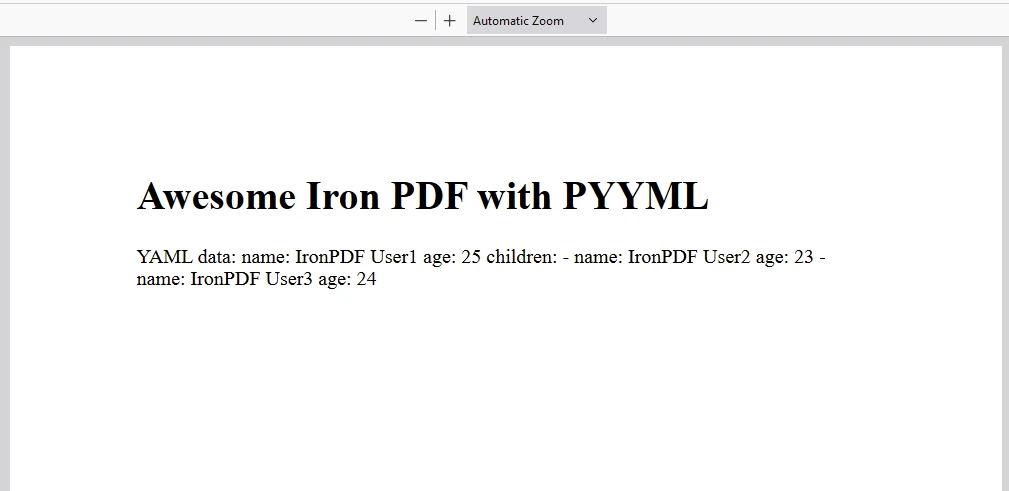
content = "<h1>Awesome Iron PDF with PyYAML</h1>"
content += "<p>YAML data: " + yaml_output + "</p>"
pdf = renderer.RenderHtmlAsPdf(content)
# Save the PDF document to a file
pdf.SaveAs("awesome.pdf")import yaml
import json
from ironpdf import *
# Apply your license key
License.LicenseKey = "your license"
# Sample YAML data
yaml_data = """
name: IronPDF User1
age: 25
children:
- name: IronPDF User2
age: 23
- name: IronPDF User3
age: 24
"""
# Load YAML data into Python structures
data = yaml.safe_load(yaml_data)
print(data)
# Dump Python data back to YAML
yaml_output = yaml.dump(data, default_flow_style=False)
print(yaml_output)
# Write YAML to File
with open('output_file.yaml', 'w') as file:
yaml.dump(yaml_output, file)
# Write YAML data as JSON
with open('output_file.json', 'w') as json_file:
json.dump(data, json_file)
# Read JSON and format with indentation for readability
output = json.dumps(json.load(open('output_file.json')), indent=2)
print(output)
# Create PDF renderer
renderer = ChromePdfRenderer()
# Create a PDF from HTML containing YAML data
content = "<h1>Awesome Iron PDF with PyYAML</h1>"
content += "<p>YAML data: " + yaml_output + "</p>"
pdf = renderer.RenderHtmlAsPdf(content)
# Save the PDF document to a file
pdf.SaveAs("awesome.pdf")代码解释
导入:
- 导入必要的库:用于YAML操作的
ironpdf。
- 导入必要的库:用于YAML操作的
设置许可证密钥:
- 设置 IronPDF 许可证密钥,以获得法律和功能访问库的权限。
示例 YAML 数据:
- 定义示例 YAML 数据,以演示 YAML 操作。
YAML 操作:
- 使用
yaml.safe_load()将YAML数据转换为可操作的Python对象。
- 使用
转储到 YAML:
- 使用
yaml.dump()将Python对象转换回YAML格式以进行输出。
- 使用
写入文件:
- 将 YAML 数据导出到 YAML 文件,以及将 JSON 数据导出到 JSON 文件以供存储或传输。
读取 JSON 和格式化:
- 从文件中读取JSON数据,并使用
json.dumps()格式化以提高可读性。
- 从文件中读取JSON数据,并使用
使用 IronPDF 生成 PDF:
- 使用 IronPDF 将 HTML 字符串渲染为 PDF 文档,包括嵌入的 YAML 数据。
保存 PDF:
- 将生成的 PDF 保存到文件系统中,展示如何进行程序化的 PDF 创建。
输出
IronPDF 许可证
IronPDF 使用Python的许可证密钥运行。 IronPDF for Python提供免费试用许可证密钥,以便用户在购买前查看其广泛的功能。
在使用IronPDF包之前,将许可证密钥放在脚本的开头:
from ironpdf import *
# Apply your license key
License.LicenseKey = "key"from ironpdf import *
# Apply your license key
License.LicenseKey = "key"结论
PyYAML 是一个功能强大且灵活的库,用于在 Python 中处理 YAML。 其人类可读的格式、完整的 YAML 1.1 支持以及与 Python 的集成,使其成为配置文件、数据序列化等的绝佳选择。 无论您处理的是简单配置还是复杂的数据结构,PyYAML 提供了您需要的工具来有效处理 YAML 数据。
IronPDF 是一个 Python 包,用于将 HTML 内容转换成 PDF 文档。 它为开发人员提供了简单的 API(ChromePdfRenderer),用于从 HTML 生成高质量的 PDF,并支持现代 Web 标准,如 CSS 和 JavaScript。 这使得它成为从 Python 应用程序中动态创建和保存 PDF 文档的有效工具。
















