
Wie man PDF zu Bild in Python konvertiert
PDF (Portable Document Format) ist das beliebteste Dateiformat für die Übertragung von Daten über das Internet, da es das Inhaltsformat beibehält und hilft, die Daten mit Sicherheitsberechtigungen zu schützen. Es gibt Szenarien, in denen wir PDF-Dateien in JPG-Bilder oder andere Bildformate wie PNG, BMP, TIFF oder GIF konvertieren müssen. Es gibt viele Online-Ressourcen für die JPG-Konvertierung, aber wie cool wäre es, unser eigenes Tool zur Umwandlung von PDF in Bild in Python zu erstellen?
Was ist Python?
Python ist eine Hochsprache zur Programmierung, die zum Erstellen von Softwareanwendungen, Websites, zur Automatisierung von Aufgaben, zur Durchführung von Datenanalysen und für Aufgaben der Künstlichen Intelligenz und des Maschinellen Lernens verwendet wird. Es ist auch eine Skriptsprache, da es interpretiert wird, was es in Bezug auf schnelle Entwicklung und Tests leistungsfähiger macht.
Um einen PDF-zu-Bild-Konverter zu erstellen, müssen wir Python 3+ auf dem Computer installiert haben. Laden Sie die neueste Version von der offiziellen Website herunter und installieren Sie sie.
In diesem Artikel werden wir unsere eigene App zur Bildkonvertierung unter Verwendung von Python PDF zu Bild-Bibliotheken erstellen. Zu diesem Zweck werden wir zwei der beliebtesten Python-Bibliotheken verwenden: PDF2Image und PyMuPDF.
Wie man PDF-Dateien in Bilddateien in Python umwandelt
- Installieren Sie die Python-Bibliothek, um PDF in Bild zu konvertieren.
- Laden Sie eine vorhandene PDF-Datei von einem beliebigen Speicherort.
- Nutzen Sie Konvertierungsmethoden.
- Durchlaufen Sie die Seiten der Datei.
- Speichern Sie jede Seite als JPG- oder PNG-Bild mit der Speichermethode.
Erstelle eine neue Python-Datei
- Öffnen Sie die Python IDLE-Anwendung und drücken Sie die Tasten Strg + N. Der Texteditor wird geöffnet. Sie können dafür Ihren bevorzugten Texteditor verwenden.
- Speichern Sie die Datei als pdf2image.py, am selben Ort wie die PDF-Datei, die Sie in Bilder umwandeln möchten.
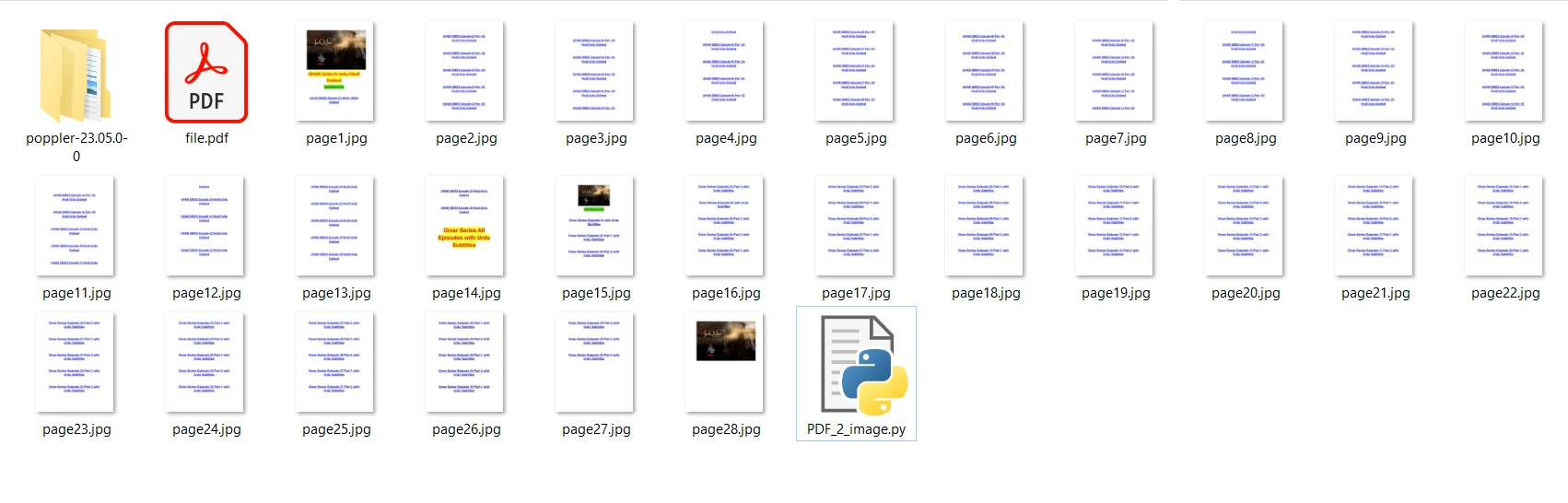
Die Eingabe-PDF-Datei, die wir verwenden werden, enthält 28 Seiten und ist wie folgt:

PDF-Dateien in Bilddateien mit der PDF2Image-Bibliothek umwandeln
1. Installieren Sie die PDF2Image Python-Bibliothek
PDF2Image ist ein Modul, das pdftocairo und pdftoppm umschließt. Es funktioniert auf Python 3.7+, um PDF in ein PIL-Bildobjekt zu konvertieren. Aus der bisherigen Versionsgeschichte geht hervor, dass es lediglich pdftoppm umschließt, um PDFs in Bilder zu konvertieren, und nur unter Python 3+ funktionierte.
Um das pdf2image-Paket zu installieren, öffnen Sie Ihren Windows-Befehlseingabeaufforderung oder Windows PowerShell und verwenden Sie den folgenden Pip-Befehl:
pip install pdf2imagepip install pdf2imagePip (Preferred Installer Program) ist der Paketmanager für Python. Es lädt herunter und installiert Softwarepakete von Drittanbietern, die Funktionen und Funktionen bieten, die nicht in der Python-Standardbibliothek enthalten sind.
Hinweis: Um diesen Befehl von überall auf der Befehlszeile auszuführen, muss Python dem PATH hinzugefügt werden. Für Python 3+ wird empfohlen, pip3 zu verwenden, da es die aktualisierte Version von pip ist.
2. Installieren Sie Poppler
Poppler ist eine freie und quelloffene Bibliothek zum Arbeiten mit PDF-Dateien. Es wird verwendet, um PDF-Dateien zu rendern, Inhalte zu lesen und Inhalte innerhalb von PDF-Dateien zu ändern. Es wird häufig von Linux-Benutzern verwendet. Für Windows müssen wir jedoch die neueste Version von Poppler herunterladen.
Für Windows
Windows-Benutzer können die neueste Version von Poppler hier herunterladen: @oschwartz10612 Version. Sie müssen dann den Ordner bin/ dem PATH-Umgebungsvariable hinzufügen.
Für Mac
Mac-Benutzer müssen auch Poppler installieren. Es kann mit Brew installiert werden:
brew install popplerbrew install popplerFür Linux
Die meisten Linux-Distributionen werden mit den Kommandozeilenprogrammen pdftoppm und pdftocairo ausgeliefert. Falls diese Hilfsprogramme nicht installiert sind, können Sie poppler-utils über den Paketmanager installieren.
Für plattformunabhängige Nutzung (unter Verwendung von conda)
-
Installieren Sie
poppler:conda install -c conda-forge popplerconda install -c conda-forge popplerSHELL -
Installieren Sie pdf2image:
pip install pdf2imagepip install pdf2imageSHELL
Jetzt ist alles fertig, lassen Sie uns mit dem Code anfangen, um PDFs in Bilder zu konvertieren.
3. Code zur Umwandlung von PDF-Dateien in Bilddateien
Der folgende Code führt die Bildkonvertierung der Eingabe-PDF-Datei durch:
from pdf2image import convert_from_path
# Notify the user that the process is starting
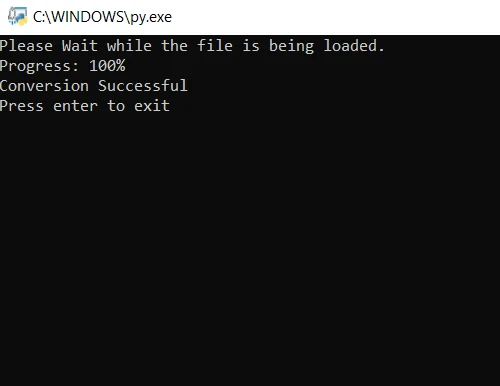
print("Please wait while the file is being loaded.")
file = convert_from_path('file.pdf')
# Iterate over all pages in the PDF file
for i in range(len(file)):
# Update user on progress
print("Progress: " + str(round(i / len(file) * 100)) + "%")
# Save each page as a JPG image file
file[i].save('page' + str(i + 1) + '.jpg', 'JPEG')
# Notify the user that the conversion is successful
print("Conversion Successful")from pdf2image import convert_from_path
# Notify the user that the process is starting
print("Please wait while the file is being loaded.")
file = convert_from_path('file.pdf')
# Iterate over all pages in the PDF file
for i in range(len(file)):
# Update user on progress
print("Progress: " + str(round(i / len(file) * 100)) + "%")
# Save each page as a JPG image file
file[i].save('page' + str(i + 1) + '.jpg', 'JPEG')
# Notify the user that the conversion is successful
print("Conversion Successful")Im obigen Code öffnen wir zuerst die Datei mit der Methode convert_from_path. Diese Methode öffnet die Datei, die sich am angegebenen Pfad befindet. Dann durchlaufen wir jede Seite der zu konvertierenden PDF-Datei in JPG-Bilder. Abschließend wird die Methode save verwendet, um jede konvertierte Seite als JPG-Bilddatei zu speichern. Führen Sie nun das Programm aus und warten Sie, bis die Konvertierung abgeschlossen ist. Die Ausgabebilddateien werden im selben Ordner wie das Programm gespeichert.
PDF-Dateien mit der PyMuPDF-Bibliothek in Bilder umwandeln
1. Installieren Sie die PyMuPDF Python-Bibliothek
PyMuPDF ist eine erweiterte Python-Bindung zu MuPDF, einem leichten E-Book-, PDF- und XPS-Viewer, Renderer und Toolkit. Es kann verwendet werden, um PDF in andere Formate wie JPG oder PNG zu konvertieren. PyMuPDF funktioniert mit Python 3.7+ Versionen.
Um das PyMuPDF-Paket zu installieren, öffnen Sie Ihre Windows-Befehlseingabeaufforderung oder Windows PowerShell und verwenden Sie den folgenden Pip-Befehl:
pip install pymupdfpip install pymupdfBeachten Sie, dass PyMuPDF keine zusätzlichen Bibliotheken benötigt, wie es das PDF2Image-Paket tut.
2. Code zur Umwandlung von PDF-Dateien in Bilder
Der folgende Code importiert das Modul fitz aus PyMuPDF, damit wir die PDF-Datei in Bilder konvertieren können:
import fitz # PyMuPDF
# Open the PDF file
doc = fitz.open("file.pdf")
# Iterate over each page in the document
for x in range(len(doc)):
page = doc.load_page(x) # Load a specific page
pix = page.get_pixmap() # Render page to image
output = "output/pdfpage" + str(x + 1) + ".png" # Specify output path
pix.save(output) # Save the image to the output path
# Close the document
doc.close()import fitz # PyMuPDF
# Open the PDF file
doc = fitz.open("file.pdf")
# Iterate over each page in the document
for x in range(len(doc)):
page = doc.load_page(x) # Load a specific page
pix = page.get_pixmap() # Render page to image
output = "output/pdfpage" + str(x + 1) + ".png" # Specify output path
pix.save(output) # Save the image to the output path
# Close the document
doc.close()Im obigen Code wird der Dateiname als Argument an die Methode fitz.open übergeben, um die Datei zu öffnen. Anschließend durchlaufe ich das gesamte Dokument und lade jede Seite einzeln. Die Methode get_pixmap wird verwendet, um jede Dokumentseite in Bildpixel umzuwandeln, und das resultierende Bild wird mit der Methode save im Ausgabeverzeichnis gespeichert. Schließlich wird das geöffnete Dokument geschlossen, um den Speicher freizugeben.
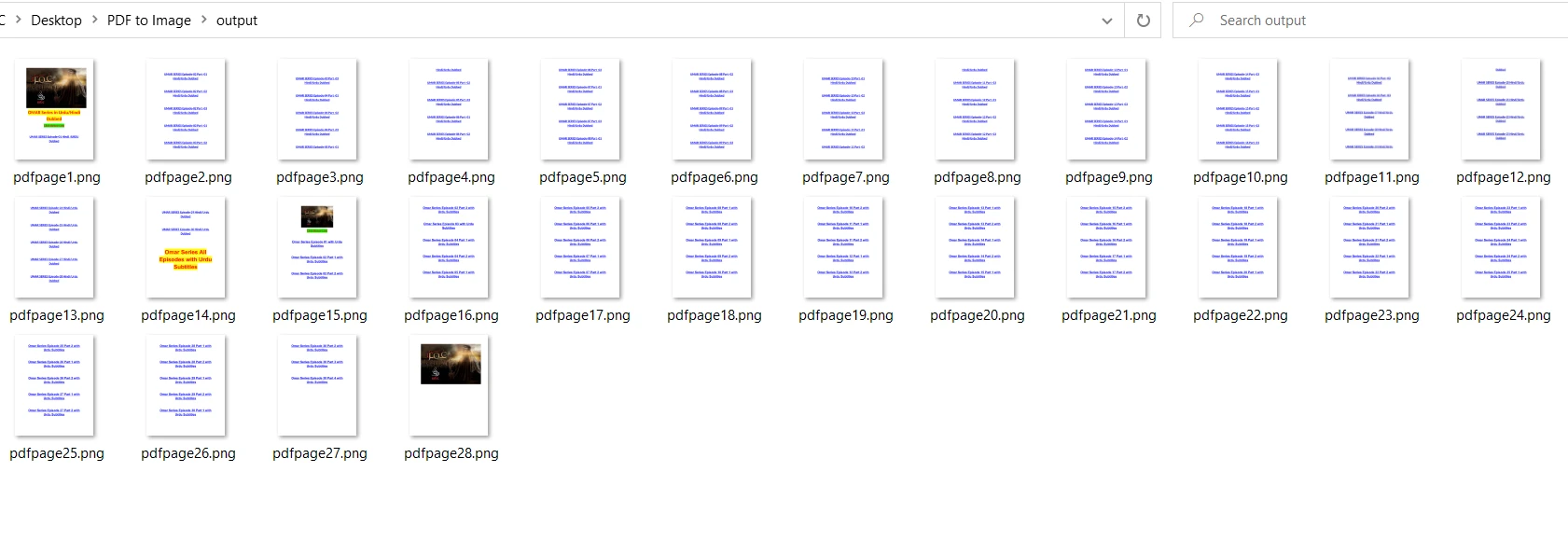
Im Vergleich zu PDF2Image ist PyMuPDF schneller bei der Umwandlung von PDF in PNG. PDF2Image kann für PNG-Format aufgrund seines Kompressionsverhältnisses langsam sein. Die Ausgabe ist die gleiche wie bei PDF2Image:
PDF in Bilder umwandeln mit C
IronPDF-Bibliothek
IronPDF ist eine Bibliothek zum Erstellen, Lesen und Bearbeiten von PDF-Dateien. Seine Besonderheit liegt im Rendern von HTML zu PDF mithilfe der Chromium Engine. Diese Funktion macht es beliebt bei Entwicklern, die HTML-Dateien oder URLs in PDF-Dokumente umwandeln müssen. Zusätzlich bietet es die Umwandlung von verschiedenen Formaten in PDF-Dateien.
Sie können auch eine PDF-Datei mit nur zwei Codezeilen in Bilder rasterisieren. Der folgende Code zeigt, wie man PDFs in verschiedene Bildformate umwandelt:
using IronPdf;
var Renderer = new IronPdf.ChromePdfRenderer();
var PDF = Renderer.RenderUrlAsPdf("https://example.com");
PDF.SaveAs("html.pdf");
// Rasterize the PDF
List<string> Images = PDF.RasterizeToImageFiles(ImageType.Png);using IronPdf;
var Renderer = new IronPdf.ChromePdfRenderer();
var PDF = Renderer.RenderUrlAsPdf("https://example.com");
PDF.SaveAs("html.pdf");
// Rasterize the PDF
List<string> Images = PDF.RasterizeToImageFiles(ImageType.Png);Imports IronPdf
Private Renderer = New IronPdf.ChromePdfRenderer()
Private PDF = Renderer.RenderUrlAsPdf("https://example.com")
PDF.SaveAs("html.pdf")
' Rasterize the PDF
Dim Images As List(Of String) = PDF.RasterizeToImageFiles(ImageType.Png)Herunterladen Sie IronPDF und probieren Sie es kostenlos aus.
















