
Cómo Leer Documentos PDF en C# usando iTextSharp:
Full Comparison
Looking for a detailed feature-by-feature breakdown? See how IronPDF stacks up against Itext on pricing, HTML support, and licensing.
Manejar PDFs es una tarea común en el desarrollo de C#, desde extraer texto hasta modificar documentos. iText 7 ha sido durante mucho tiempo una biblioteca de referencia para esto, pero su sintaxis compleja y curva de aprendizaje pronunciada pueden ralentizar el desarrollo.
IronPDF ofrece una alternativa más simple y eficiente. Con una API intuitiva, conversión integrada de HTML a PDF y extracción de texto más fácil, IronPDF simplifica el manejo de PDFs con menos código. En este artículo, compararemos iText 7 e IronPDF, demostrando por qué IronPDF es la elección más inteligente para los desarrolladores de C#.
Entender iText 7: una visión general
iText 7 (originalmente iTextSharp) es una poderosa biblioteca de código abierto para trabajar con PDFs en .NET. Proporciona amplias funciones para crear, modificar, cifrar y extraer contenido de documentos PDF. Muchos desarrolladores confían en ella para automatizar flujos de trabajo de documentos, generar informes y manejar tareas de procesamiento de PDF a gran escala.
Una de las mayores fortalezas de iText 7 es su control detallado sobre las estructuras de PDF. Admite anotaciones, campos de formulario, marcas de agua y firmas digitales, haciéndolo una herramienta robusta para la manipulación avanzada de documentos. Además, está bien documentado y es ampliamente utilizado, con un sólido respaldo comunitario y numerosos recursos de terceros disponibles.
Instalación de iText 7
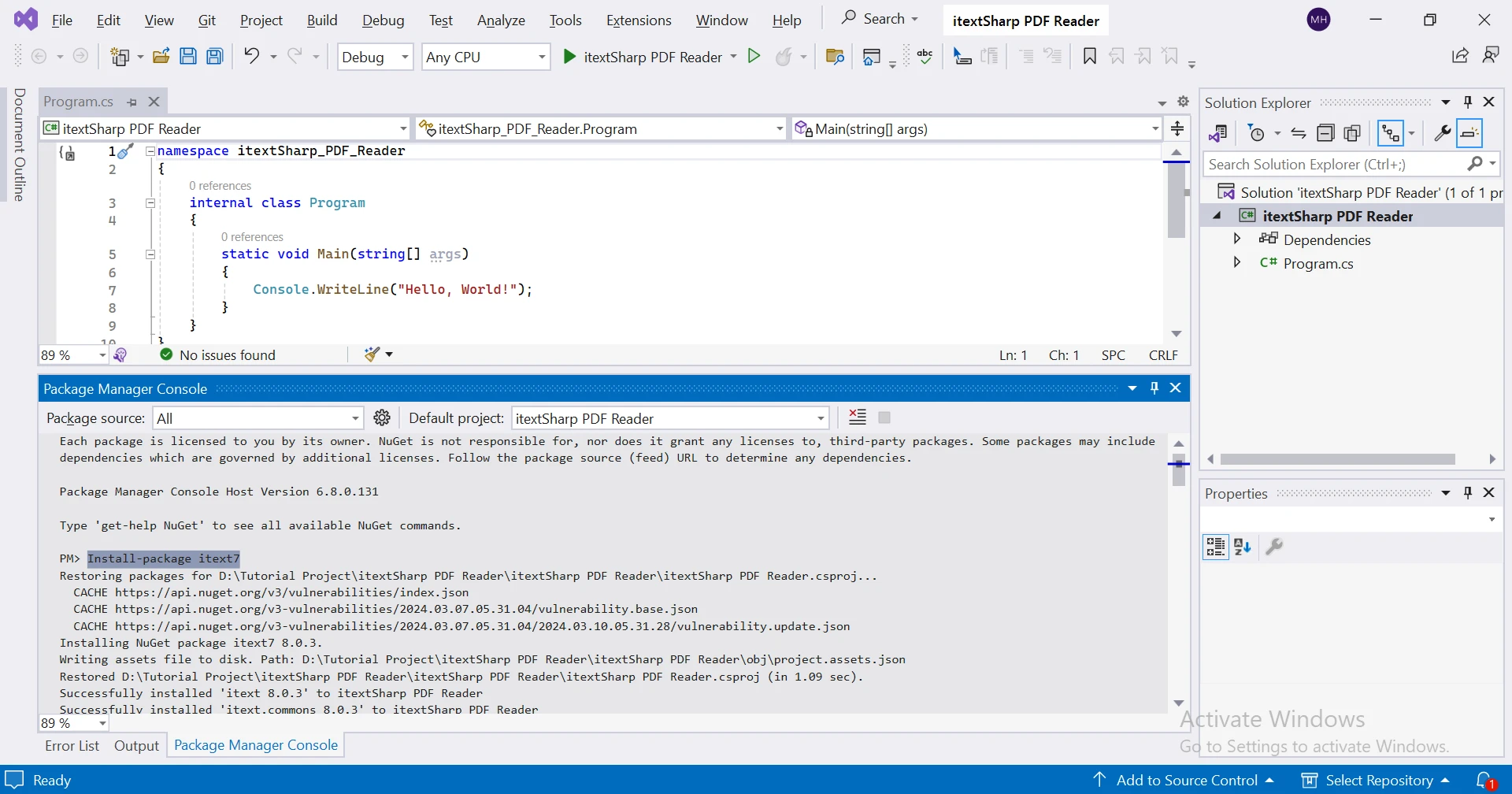
Para instalar iText 7 en un proyecto .NET, puede usar el Administrador de paquetes NuGet en Visual Studio:
Usando la Consola del Administrador de Paquetes NuGet:
Install-Package itext7
Sin embargo, iText 7 conlleva desafíos. Su compleja API requiere más código para tareas comunes como la extracción de texto o la fusión de PDFs y carece de soporte integrado para la conversión de HTML a PDF, lo que dificulta los flujos de trabajo de web a documento. Además, su licencia AGPL requiere que las empresas compren una licencia comercial para evitar los requerimientos de distribución de código abierto.
Para los desarrolladores que buscan una API más fluida y de alto nivel con características modernas, IronPDF presenta una alternativa convincente.
Presentación de IronPDF: Una solución superior
IronPDF es una biblioteca .NET diseñada para hacer la extracción de PDFs, la manipulación y la generación simple y eficiente. A diferencia de iText 7, que requiere codificación extensa para muchas operaciones, IronPDF permite a los desarrolladores leer, editar y modificar PDFs con un esfuerzo mínimo.
Para la extracción de PDF, IronPDF facilita la extracción de texto, imágenes y datos estructurados de PDFs con solo unas pocas líneas de código, simplificando tus tareas de extracción de texto con facilidad. Cuando se trata de la manipulación de PDFs, IronPDF admite la fusión, la división, el marcado de agua, y la edición de PDFs sin requerir operaciones complejas de bajo nivel.
Además, IronPDF incluye la conversión de HTML a PDF nativa, lo que hace que sea simple generar PDFs desde páginas web o contenido HTML existente. También admite la representación de JavaScript, firmas digitales, y cifrado, proporcionando un conjunto de herramientas completo para aplicaciones modernas.
Con una API más limpia, mejor documentación y soporte comercial, IronPDF es una alternativa amigable para desarrolladores que simplifica el manejo de PDFs en C#. En las siguientes secciones, compararemos cómo ambas bibliotecas manejan tareas clave de PDF y por qué IronPDF ofrece una mejor experiencia para los desarrolladores de C#.
Instalación
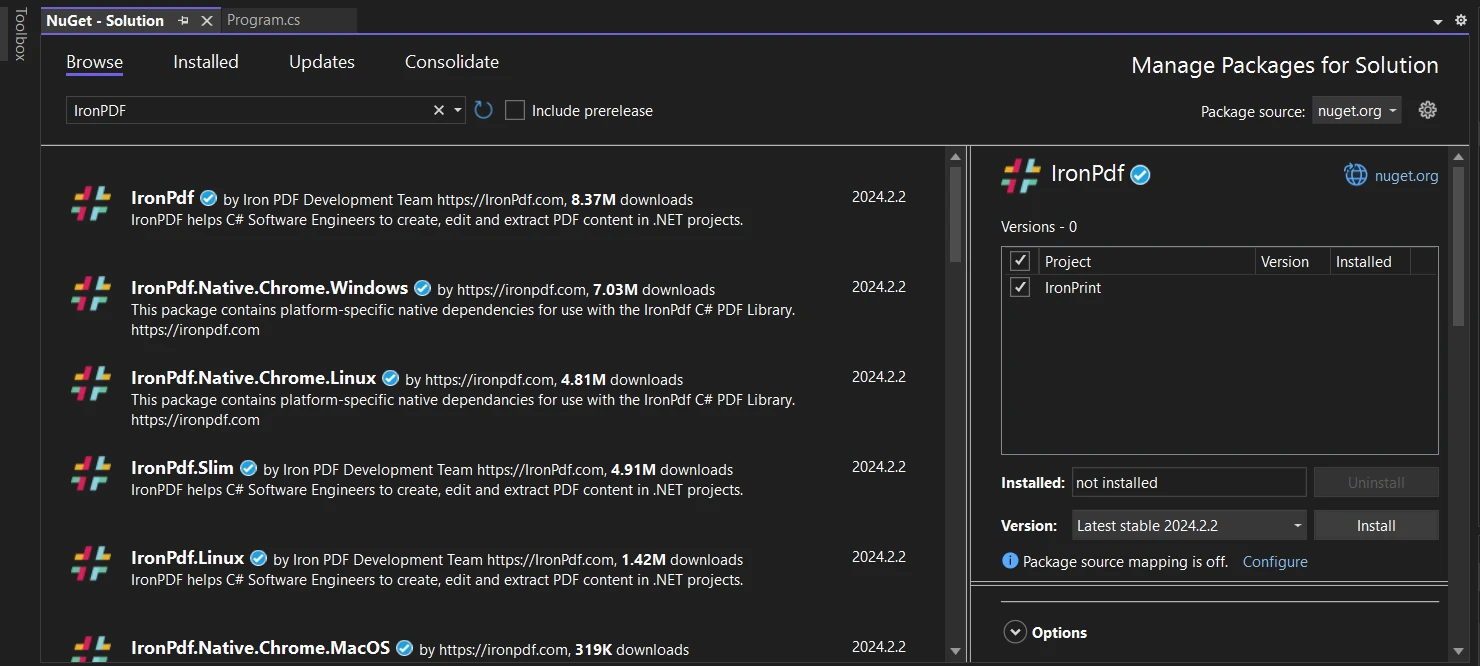
Poner en marcha IronPDF en tus proyectos de C# es tan fácil como ejecutar la siguiente línea en el Administrador de Paquetes NuGet:
Install-Package IronPdf
O, alternativamente, ve a Herramientas > Administrador de Paquetes NuGet > Administrar Paquetes NuGet para Solución, y busca IronPDF.
¡Luego simplemente haz clic en "Instalar" y IronPDF se añadirá a tu proyecto en poco tiempo!
IronPDF vs iText 7 en el procesamiento de PDF: Comparación de códigos
Uso de IronPDF para extraer texto
IronPDF simplifica la extracción de texto de PDF, la manipulación y la lectura con una API mucho más amigable para desarrolladores. A diferencia de iText 7, que requiere operaciones de bajo nivel, IronPDF permite la extracción de texto con solo unas pocas líneas de código.
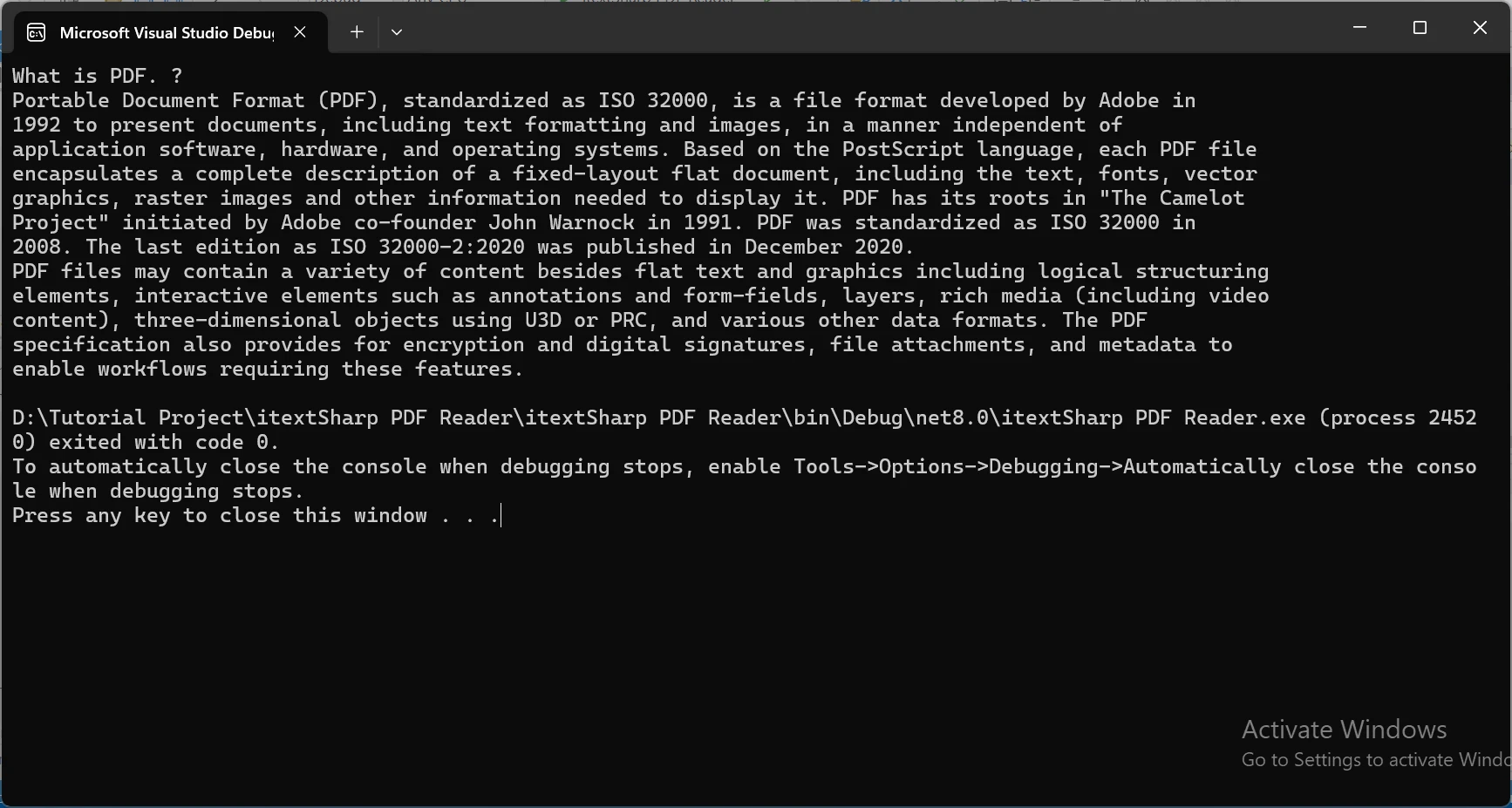
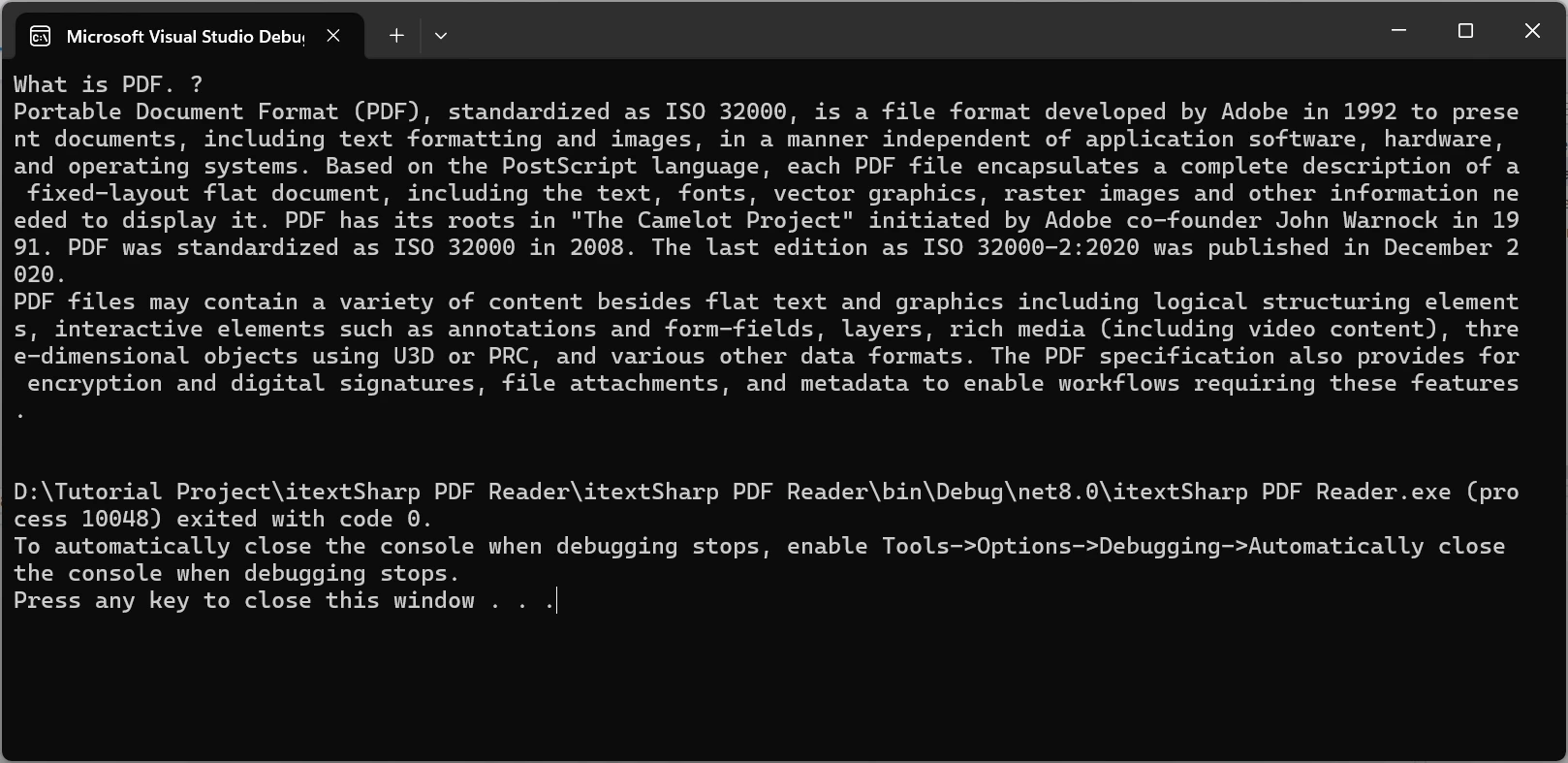
Para demostrar la poderosa herramienta de extracción de texto de IronPDF en acción, tomaré el siguiente documento PDF y extraeré el contenido de él.
Ejemplo de Código
using IronPdf;
class Program
{
static void Main()
{
string pdfPath = "sample.pdf";
// Load the PDF document
var pdf = new PdfDocument(pdfPath);
// Extract all text from the loaded PDF document
string extractedText = pdf.ExtractAllText();
// Output the extracted text to the console
Console.WriteLine(extractedText);
}
}using IronPdf;
class Program
{
static void Main()
{
string pdfPath = "sample.pdf";
// Load the PDF document
var pdf = new PdfDocument(pdfPath);
// Extract all text from the loaded PDF document
string extractedText = pdf.ExtractAllText();
// Output the extracted text to the console
Console.WriteLine(extractedText);
}
}Imports IronPdf
Friend Class Program
Shared Sub Main()
Dim pdfPath As String = "sample.pdf"
' Load the PDF document
Dim pdf = New PdfDocument(pdfPath)
' Extract all text from the loaded PDF document
Dim extractedText As String = pdf.ExtractAllText()
' Output the extracted text to the console
Console.WriteLine(extractedText)
End Sub
End ClassSalida
Explicación:
IronPDF simplifica la extracción de texto de PDF con su API de alto nivel, eliminando la necesidad de operaciones de bajo nivel. En solo unas pocas líneas de código, IronPDF puede extraer eficientemente todo el texto de un documento PDF, a diferencia de bibliotecas como iText 7, que a menudo requiere iteración manual de páginas y manejo complejo.
En el ejemplo, la clase PdfDocument carga el PDF y el método ExtractAllText() extrae rápidamente todo el texto, agilizando el proceso. Esto es una gran ventaja sobre iText 7, donde necesitarías manejar manualmente páginas individuales y elementos de texto.
Expansión de IronPDF para otras tareas:
Construyendo sobre el ejemplo básico de extracción de texto, la API de alto nivel de IronPDF simplifica otras tareas comunes de PDF, todo mientras mantiene la facilidad de uso y eficiencia:
Extracción de texto de páginas específicas: si necesita extraer texto de una página o rango específico, IronPDF le permite hacerlo fácilmente. Por ejemplo, para extraer texto de la primera página:
var pdf = new PdfDocument("sample.pdf");
// Access text from the first page
string pageText = pdf.Pages[0].Text;
Console.WriteLine(pageText);var pdf = new PdfDocument("sample.pdf");
// Access text from the first page
string pageText = pdf.Pages[0].Text;
Console.WriteLine(pageText);Dim pdf = New PdfDocument("sample.pdf")
' Access text from the first page
Dim pageText As String = pdf.Pages(0).Text
Console.WriteLine(pageText)Manipulación de PDF: después de extraer texto o datos de varios PDF, es posible que desee combinarlos en un solo documento. IronPDF hace que la fusión de múltiples PDFs sea simple:
var pdf1 = new PdfDocument("file1.pdf");
var pdf2 = new PdfDocument("file2.pdf");
// Merge the PDFs into a single document
var combinedPdf = PdfDocument.Merge(pdf1, pdf2);
combinedPdf.SaveAs("combined_output.pdf");var pdf1 = new PdfDocument("file1.pdf");
var pdf2 = new PdfDocument("file2.pdf");
// Merge the PDFs into a single document
var combinedPdf = PdfDocument.Merge(pdf1, pdf2);
combinedPdf.SaveAs("combined_output.pdf");Dim pdf1 = New PdfDocument("file1.pdf")
Dim pdf2 = New PdfDocument("file2.pdf")
' Merge the PDFs into a single document
Dim combinedPdf = PdfDocument.Merge(pdf1, pdf2)
combinedPdf.SaveAs("combined_output.pdf")Conversión de PDF a HTML: si necesita convertir un PDF nuevamente a HTML para una mayor extracción o manipulación, IronPDF también ofrece esta funcionalidad:
var pdf = new PdfDocument("sample.pdf");
// Convert the PDF to an HTML string
string htmlContent = pdf.ToHtmlString();var pdf = new PdfDocument("sample.pdf");
// Convert the PDF to an HTML string
string htmlContent = pdf.ToHtmlString();Dim pdf = New PdfDocument("sample.pdf")
' Convert the PDF to an HTML string
Dim htmlContent As String = pdf.ToHtmlString()Con IronPDF, la extracción de texto es solo el comienzo. La simple y poderosa API de la biblioteca se extiende a una amplia gama de tareas de manipulación de PDFs, todo en un formato que es intuitivo y fácil de integrar en tu flujo de trabajo.
Lectura de PDF con iText 7
iText 7 requiere trabajar con lectores de PDF, flujos y procesamiento de datos a nivel de byte. La extracción de texto no es sencilla, ya que implica iterar a través de las páginas del PDF y manejar varias estructuras manualmente. Para este ejemplo de código, usaremos el mismo documento PDF que en la sección de IronPDF.
using iText.Kernel.Pdf;
using iText.Kernel.Pdf.Canvas.Parser;
class Program
{
static void Main()
{
string pdfPath = "sample.pdf";
string extractedText = ExtractTextFromPdf(pdfPath);
Console.WriteLine(extractedText);
}
// Method to extract text from a PDF
static string ExtractTextFromPdf(string pdfPath)
{
// Use PdfReader to load the PDF
using (PdfReader reader = new PdfReader(pdfPath))
// Open the PDF document for processing
using (iText.Kernel.Pdf.PdfDocument pdfDoc = new iText.Kernel.Pdf.PdfDocument(reader))
{
string text = "";
// Iterate through each page and extract text
for (int i = 1; i <= pdfDoc.GetNumberOfPages(); i++)
{
text += PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(i)) + Environment.NewLine;
}
return text;
}
}
}using iText.Kernel.Pdf;
using iText.Kernel.Pdf.Canvas.Parser;
class Program
{
static void Main()
{
string pdfPath = "sample.pdf";
string extractedText = ExtractTextFromPdf(pdfPath);
Console.WriteLine(extractedText);
}
// Method to extract text from a PDF
static string ExtractTextFromPdf(string pdfPath)
{
// Use PdfReader to load the PDF
using (PdfReader reader = new PdfReader(pdfPath))
// Open the PDF document for processing
using (iText.Kernel.Pdf.PdfDocument pdfDoc = new iText.Kernel.Pdf.PdfDocument(reader))
{
string text = "";
// Iterate through each page and extract text
for (int i = 1; i <= pdfDoc.GetNumberOfPages(); i++)
{
text += PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(i)) + Environment.NewLine;
}
return text;
}
}
}Imports iText.Kernel.Pdf
Imports iText.Kernel.Pdf.Canvas.Parser
Friend Class Program
Shared Sub Main()
Dim pdfPath As String = "sample.pdf"
Dim extractedText As String = ExtractTextFromPdf(pdfPath)
Console.WriteLine(extractedText)
End Sub
' Method to extract text from a PDF
Private Shared Function ExtractTextFromPdf(ByVal pdfPath As String) As String
' Use PdfReader to load the PDF
Using reader As New PdfReader(pdfPath)
' Open the PDF document for processing
Using pdfDoc As New iText.Kernel.Pdf.PdfDocument(reader)
Dim text As String = ""
' Iterate through each page and extract text
Dim i As Integer = 1
Do While i <= pdfDoc.GetNumberOfPages()
text &= PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(i)) & Environment.NewLine
i += 1
Loop
Return text
End Using
End Using
End Function
End ClassSalida
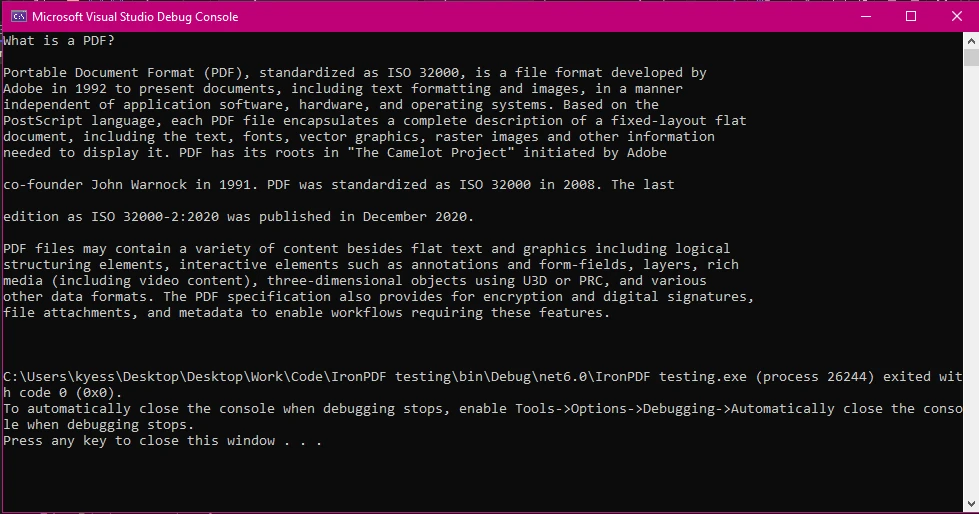
Explicación:
- El
PdfReadercarga el archivo PDF para su lectura. - El objeto
PdfDocumentpermite iterar a través de páginas. PdfTextExtractor.GetTextFromPage()recupera texto de cada página.- El texto final se almacena en una cadena y se muestra.
Este método funciona pero requiere iteración manual y puede ser engorroso para documentos estructurados o PDFs escaneados.
Comparación entre iText 7 e IronPDF
Mientras que iText 7 requiere codificación detallada para realizar operaciones con PDFs, IronPDF simplifica estas tareas con métodos directos. Por ejemplo, extraer texto de un PDF con iText 7 involucra múltiples pasos y código extenso, mientras que IronPDF lo logra en solo unas pocas líneas. Además, el soporte de IronPDF para la conversión de HTML a PDF es más robusto, manejando HTML complejo, CSS y JavaScript sin problemas.
Los puntos clave
- IronPDF simplifica las tareas de lectura y manipulación de PDF con una API más intuitiva y simplificada, que requiere menos código para realizar operaciones comunes.
- La extracción de texto de IronPDF es más fácil de implementar en comparación con el proceso de iteración más complejo de iTextSharp, ahorrando tiempo a los desarrolladores.
- La licencia perpetua de IronPDF es más amigable para los negocios, ofreciendo menos restricciones en comparación con la licencia AGPL de iTextSharp.
- IronPDF tiene mejor documentación que es más accesible para una solución rápida de problemas, lo que lo hace ideal para desarrolladores que quieren soluciones rápidas sin pasar por recursos excesivos.
Optimización del flujo de trabajo con IronPDF
IronPDF ofrece una gama de características poderosas que van más allá de solo la lectura de PDFs. Estas características lo convierten en una solución robusta para desarrolladores que buscan optimizar sus flujos de trabajo de PDF. Esto es cómo IronPDF puede mejorar tu proceso de desarrollo:
1. Extracción de texto de archivos PDF
IronPDF permite la fácil extracción de texto de archivos PDF, haciéndolo ideal para flujos de trabajo que involucran análisis de documentos, extracción de datos o indexación de contenido. Con IronPDF, puedes extraer rápidamente texto de PDFs y usarlo en tus aplicaciones sin lidiar con un análisis complejo.
2. Creación de PDF
IronPDF hace que sea sencillo generar PDFs desde cero, ya sea que estés creando informes, facturas u otros tipos de documentos. La herramienta también admite la conversión de HTML a PDF, permitiéndote aprovechar contenido web existente y generar PDFs bien formateados. Esto es perfecto para escenarios donde necesitas convertir páginas web o contenido HTML dinámico en archivos PDF descargables.
3. Funciones avanzadas de PDF
Más allá de la extracción básica de texto y la creación de PDF, IronPDF admite características avanzadas como el llenado de formularios PDF, la adición de anotaciones y la manipulación de contenido de documentos. Estas capacidades son útiles en industrias como la legal, la financiera o la educativa donde los formularios y comentarios son una parte regular del flujo de trabajo.
4. Procesamiento por lotes
IronPDF está bien preparado para procesar grandes cantidades de archivos PDF. Ya sea que estés extrayendo información de cientos de documentos o convirtiendo múltiples archivos HTML a PDFs, IronPDF puede automatizar estas tareas y manejarlas de manera eficiente, ahorrando tanto tiempo como esfuerzo.
5. Automatización y eficiencia
IronPDF simplifica las tareas de manipulación de PDFs que a menudo son tediosas y repetitivas. Al automatizar tareas como la extracción de texto de PDF, el llenado de formularios o la conversión por lotes, los desarrolladores pueden concentrarse en aspectos más complejos de sus proyectos mientras dejan que IronPDF haga el trabajo pesado.
Soporte técnico y recursos de la comunidad
Para asegurar que los desarrolladores puedan sacar el máximo provecho de IronPDF, la herramienta cuenta con soporte sólido y recursos comunitarios:
- Soporte Técnico: IronPDF ofrece soporte directo a través de correo electrónico y sistema de tickets, brindando asistencia para cualquier desafío de implementación o técnico.
- Recursos Comunitarios: El sitio web de IronPDF incluye documentación extensa, tutoriales y artículos de blog. Los desarrolladores también pueden encontrar soluciones y compartir conocimientos a través de GitHub y Stack Overflow, donde la comunidad discute activamente mejores prácticas y consejos para solucionar problemas.
Conclusión
En este artículo, hemos explorado las capacidades de IronPDF como una poderosa y fácil de usar biblioteca para el manejo de PDFs para desarrolladores de .NET. La comparamos con iText 7, destacando cómo IronPDF simplifica tareas complejas como la extracción de texto y la manipulación de PDFs. La API limpia de IronPDF y características avanzadas, incluyendo edición, marcado de agua y firmas digitales, lo convierten en una solución superior para flujos de trabajo modernos de PDF.
A diferencia de iText 7, que requiere codificación intrincada para tareas comunes de PDF, IronPDF te permite realizar operaciones complejas con un código mínimo, ahorrando tiempo y esfuerzo a los desarrolladores. Ya sea que estés trabajando con documentos escaneados, generando PDFs desde HTML, o agregando marcas de agua personalizadas, IronPDF ofrece un modo intuitivo y eficiente para manejarlo todo.
Si estás buscando simplificar tus flujos de trabajo de PDF y aumentar la productividad en tus proyectos de C#, IronPDF es la elección ideal.
Te invitamos a descargar IronPDF y probarlo por ti mismo. Con una prueba gratuita disponible, puedes experimentar de primera mano lo fácil que es integrar IronPDF en tus aplicaciones y comenzar a beneficiarte de sus poderosas características hoy mismo.
Haz clic a continuación para comenzar con tu prueba gratuita:
- Comienza tu prueba gratuita con IronPDF
- Aprende más sobre las características y el precio de IronPDF ¡No esperes más, desbloquea el potencial de un manejo sin complicaciones de PDFs con IronPDF!
Preguntas Frecuentes
¿Cuáles son los beneficios de usar IronPDF sobre iText 7 para el manejo de PDF en C#?
IronPDF ofrece una API más intuitiva, admite la conversión de HTML a PDF y simplifica tareas como la extracción de texto, la fusión y la división de PDFs. Requiere menos código que iText 7 y ofrece un modelo de licencia perpetua amigable para los negocios.
¿Cómo puedo convertir una página web a PDF en C#?
Puedes usar el método RenderUrlAsPdf de IronPDF para convertir una página web directamente en un documento PDF. Esto simplifica el proceso al manejar internamente la conversión de HTML a PDF.
¿Es IronPDF adecuado para automatizar grandes tareas de procesamiento de PDF?
Sí, IronPDF es adecuado para automatización y procesamiento por lotes, lo que lo hace ideal para manejar grandes volúmenes de PDFs de manera eficiente en proyectos C#.
¿Puedo extraer texto de un rango específico de páginas en un PDF usando IronPDF?
IronPDF proporciona funcionalidad para extraer texto de páginas específicas o rangos de páginas, permitiendo un manejo preciso del contenido del PDF.
¿Qué recursos de soporte ofrece IronPDF para los desarrolladores?
IronPDF ofrece documentación completa, tutoriales y una comunidad activa. Además, hay soporte técnico directo disponible por correo electrónico y un sistema de tickets para asistir a los desarrolladores.
¿Cómo gestiona IronPDF la integración en un proyecto C#?
IronPDF puede integrarse fácilmente en un proyecto C# al instalarlo a través del Administrador de Paquetes NuGet en Visual Studio utilizando el comando 'Install-Package IronPDF'.
¿Cuáles son las opciones de licencia para IronPDF?
IronPDF ofrece un modelo de licencia perpetua, que es amigable para los negocios y evita los requisitos de distribución de código abierto asociados con la licencia AGPL de iText 7.
¿Cómo mejora IronPDF la productividad del desarrollador en proyectos C#?
IronPDF simplifica las tareas complejas de PDF a través de su API fácil de usar, reduciendo la cantidad de código necesario y acelerando los procesos de desarrollo, lo que mejora la productividad en proyectos C#.
¿IronPDF admite la conversión de PDFs a HTML?
Sí, IronPDF proporciona funcionalidad para convertir PDFs en cadenas HTML, facilitando la visualización y manipulación del contenido PDF en aplicaciones web.
¿Cuáles son las características clave de IronPDF para la manipulación de PDF?
IronPDF admite una amplia gama de funciones, incluyendo la creación de PDF, extracción de texto, conversión de HTML a PDF, fusión, división, marcas de agua y firmas digitales, todo con una API fácil de usar.













