
Cómo Ver Archivos PDF en C++
Los archivos PDF son un formato ampliamente utilizado para el intercambio de documentos debido a su capacidad para preservar el formato en diferentes plataformas. En varias aplicaciones, la lectura programática de los contenidos de los archivos PDF se vuelve invaluable.
En este artículo, aprenderemos cómo ver texto de archivos PDF en C++ usando la herramienta de línea de comandos Xpdf. Xpdf proporciona un conjunto de utilidades de línea de comandos y bibliotecas C++ para trabajar con archivos PDF, incluida la extracción de texto. Al integrar Xpdf en nuestro programa visor de PDF de C++, podemos ver de manera eficiente el contenido de texto de los archivos PDF y procesarlo mediante programación.
Xpdf - Biblioteca de C++ y herramientas de línea de comandos
Xpdf es un conjunto de software de código abierto que ofrece una variedad de herramientas y bibliotecas para trabajar con archivos PDF. Incluye diversas utilidades de línea de comandos y bibliotecas C++ que permiten funcionalidades relacionadas con PDF, como análisis, renderizado, impresión y extracción de texto. Las herramientas de línea de comandos de Xpdf también ofrecen formas de ver archivos PDF directamente desde el terminal.
Uno de los componentes clave de Xpdf es pdftotext, que es conocido principalmente por extraer contenido de texto de archivos PDF. Sin embargo, cuando se utiliza en combinación con otras herramientas como pdftops y pdfimages, Xpdf permite a los usuarios ver el contenido PDF de diferentes maneras. La herramienta pdftotext resulta valiosa para extraer información textual de archivos PDF para su posterior procesamiento o análisis, y ofrece opciones para especificar de qué páginas extraer texto.
Requisitos previos
Antes de comenzar, asegúrate de tener los siguientes requisitos previos:
- Un compilador de C++ como GCC o Clang instalado en tu sistema. Usaremos Code::Blocks IDE para este propósito.
- Herramientas de línea de comandos de Xpdf instaladas y accesibles desde la línea de comandos. Descargar Xpdf e instalar la versión adecuada para tu entorno. Después, configura el directorio bin de Xpdf en la ruta de variables de entorno del sistema para acceder desde cualquier ubicación en el sistema de archivos.
Creación de un proyecto de visor de PDF
- Abre Code::Blocks: Inicia el IDE Code::Blocks en tu computadora.
- Crear un Nuevo Proyecto: Haz clic en "Archivo" desde el menú superior y selecciona "Nuevo" del menú desplegable. Luego, haz clic en "Proyecto" del submenú.
- Elegir Tipo de Proyecto: En la ventana "Nuevo desde plantilla", elige "Aplicación de consola" y haz clic en "Ir". Luego, selecciona el lenguaje "C/C++" y haz clic en "Siguiente".
- Ingresar Detalles del Proyecto: En el campo "Título del proyecto", dale un nombre a tu proyecto (por ejemplo, "PDFViewer"). Elige la ubicación donde deseas guardar los archivos del proyecto y haz clic en "Siguiente".
- Seleccionar Compilador: Elige el compilador que deseas usar para tu proyecto. De forma predeterminada, Code::Blocks debería haber detectado automáticamente los compiladores disponibles en tu sistema. Si no, selecciona un compilador adecuado de la lista y haz clic en "Finalizar".
Pasos para ver texto de un PDF en C++
Incluya las cabeceras necesarias
Primero, agreguemos los archivos de encabezado necesarios a nuestro archivo main.cpp:
#include <cstdlib>
#include <iostream>
#include <fstream>
#include <cstdio>
using namespace std; // Use standard namespace for convenience#include <cstdlib>
#include <iostream>
#include <fstream>
#include <cstdio>
using namespace std; // Use standard namespace for convenienceConfigurar rutas de entrada y salida
string pdfPath = "input.pdf";
string outputFilePath = "output.txt";string pdfPath = "input.pdf";
string outputFilePath = "output.txt";En la función main, declaramos dos cadenas: pdfPath y outputFilePath. pdfPath almacena la ruta al archivo PDF de entrada, y outputFilePath almacena la ruta donde se guardará el texto extraído como un archivo de texto sin formato.
Archivo de entrada:

Ejecute el comando pdftotext
// Construct the command to execute pdftotext with input and output paths
string command = "pdftotext " + pdfPath + " " + outputFilePath;
// Execute the command using system function and capture the status
int status = system(command.c_str());// Construct the command to execute pdftotext with input and output paths
string command = "pdftotext " + pdfPath + " " + outputFilePath;
// Execute the command using system function and capture the status
int status = system(command.c_str());Aquí, construimos el comando pdftotext usando las variables pdfPath y outputFilePath para abrir el archivo PDF y ver su contenido. Luego se llama a la función system para ejecutar el comando, y su valor de retorno se almacena en la variable status.
Comprobar estado de extracción de texto
if (status == 0)
{
cout << "Text extraction successful." << endl;
}
else
{
cout << "Text extraction failed." << endl;
}if (status == 0)
{
cout << "Text extraction successful." << endl;
}
else
{
cout << "Text extraction failed." << endl;
}Comprobamos la variable status para ver si el comando pdftotext se ejecutó correctamente. Si status es igual a 0, significa que la extracción de texto fue exitosa e imprimimos un mensaje de éxito. Si status no es cero, indica un error e imprimimos un mensaje de error.
Leer texto extraído y mostrar
// Open the output file to read the extracted text
ifstream outputFile(outputFilePath);
if (outputFile.is_open())
{
string textContent;
string line;
while (getline(outputFile, line))
{
textContent += line + "\n"; // Concatenate each line to the text content
}
outputFile.close();
cout << "Text content extracted from PDF:" << endl;
cout << textContent << endl;
}
else
{
cout << "Failed to open output file." << endl;
}// Open the output file to read the extracted text
ifstream outputFile(outputFilePath);
if (outputFile.is_open())
{
string textContent;
string line;
while (getline(outputFile, line))
{
textContent += line + "\n"; // Concatenate each line to the text content
}
outputFile.close();
cout << "Text content extracted from PDF:" << endl;
cout << textContent << endl;
}
else
{
cout << "Failed to open output file." << endl;
}En el código de muestra anterior, abrimos outputFile (el archivo de texto generado por pdftotext), leemos su contenido línea por línea y lo almacenamos en la cadena textContent. Finalmente, cerramos el archivo e imprimimos el contenido de texto extraído en la consola.
Eliminar archivo de salida
Si no necesitas el archivo de texto de salida editable o deseas liberar espacio en disco, al final del programa simplemente elimínalo usando el siguiente comando antes de terminar la función principal:
// Remove the output file to free up disk space and if output is not needed
remove(outputFilePath.c_str());// Remove the output file to free up disk space and if output is not needed
remove(outputFilePath.c_str());Compilación y ejecución del programa
Compila el código usando la tecla de atajo "Ctrl+F9". Tras la compilación exitosa, ejecutar el ejecutable extraerá el contenido de texto del documento PDF especificado y lo mostrará en la consola. El resultado es el siguiente:
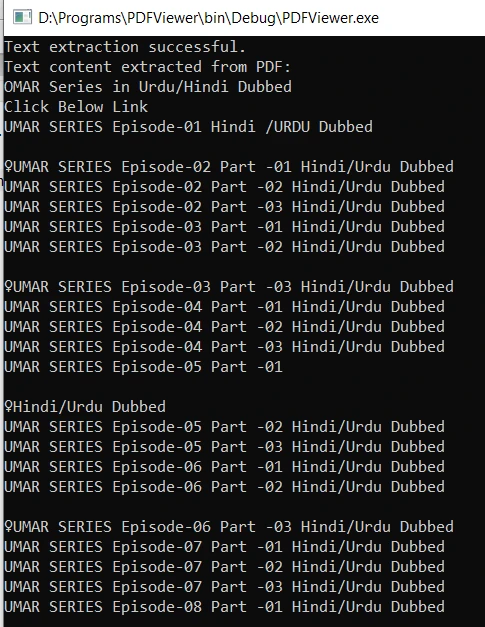
Visualización de archivos PDF en C
La Biblioteca IronPDF for .NET C# es una potente biblioteca de .NET C# que permite visualizar archivos PDF fácilmente dentro de aplicaciones C#. Aprovechando el motor del navegador web Chromium, IronPDF renderiza y muestra con precisión el contenido del PDF, incluidas imágenes, fuentes y formateo complejo. Con su interfaz intuitiva y extensas funcionalidades, los desarrolladores pueden integrar IronPDF en sus proyectos C# de forma fluida, permitiendo a los usuarios visualizar documentos PDF de manera eficiente e interactiva. Ya sea para mostrar informes, facturas u otro contenido PDF, IronPDF proporciona una solución robusta para crear visores PDF con características enriquecidas en C#.
Para instalar el paquete NuGet de IronPDF en Visual Studio, siga estos pasos:
- Abrir Visual Studio: Inicia Visual Studio u otro IDE de tu preferencia.
- Crear o Abrir Tu Proyecto: Crea un nuevo proyecto C# o abre uno existente donde deseas instalar el paquete IronPDF.
- Abrir el Administrador de Paquetes NuGet: En Visual Studio, ve a "Herramientas" > "Administrador de Paquetes NuGet" > "Administrar Paquetes NuGet para la Solución". Alternativamente, haz clic en el explorador de soluciones y luego selecciona "Administrar Paquetes NuGet para la Solución".
- Buscar IronPDF: En la ventana "Administrador de Paquetes NuGet", haz clic en la pestaña "Examinar" y luego busca "IronPDF" en la barra de búsqueda. Alternativamente, visita el Paquete NuGet IronPDF y descarga directamente la última versión de "IronPDF".
- Seleccionar Paquete IronPDF: Encuentra el paquete "IronPDF" y haz clic en él para seleccionarlo para tu proyecto.
- Instalar IronPDF: Haz clic en el botón "Instalar" para instalar el paquete seleccionado.
-
Sin embargo, también puedes instalar IronPDF usando la Consola de Administrador de Paquetes NuGet usando el siguiente comando:
Install-Package IronPdf
Usando IronPDF, podemos realizar operaciones como extraer texto e imágenes de documentos PDF y mostrarlos en la consola para visualización. El siguiente código ayuda a lograr esta tarea:
using IronPdf;
using IronSoftware.Drawing;
using System.Collections.Generic;
// Extracting Image and Text content from Pdf Documents
// Open a 128-bit encrypted PDF
var pdf = PdfDocument.FromFile("encrypted.pdf", "password");
// Get all text to put in a search index
string text = pdf.ExtractAllText();
// Get all Images
var allImages = pdf.ExtractAllImages();
// Or even find the precise text and images for each page in the document
for (var index = 0 ; index < pdf.PageCount ; index++)
{
int pageNumber = index + 1;
text = pdf.ExtractTextFromPage(index);
List<AnyBitmap> images = pdf.ExtractBitmapsFromPage(index);
// Further processing here...
}using IronPdf;
using IronSoftware.Drawing;
using System.Collections.Generic;
// Extracting Image and Text content from Pdf Documents
// Open a 128-bit encrypted PDF
var pdf = PdfDocument.FromFile("encrypted.pdf", "password");
// Get all text to put in a search index
string text = pdf.ExtractAllText();
// Get all Images
var allImages = pdf.ExtractAllImages();
// Or even find the precise text and images for each page in the document
for (var index = 0 ; index < pdf.PageCount ; index++)
{
int pageNumber = index + 1;
text = pdf.ExtractTextFromPage(index);
List<AnyBitmap> images = pdf.ExtractBitmapsFromPage(index);
// Further processing here...
}Imports IronPdf
Imports IronSoftware.Drawing
Imports System.Collections.Generic
' Extracting Image and Text content from Pdf Documents
' Open a 128-bit encrypted PDF
Private pdf = PdfDocument.FromFile("encrypted.pdf", "password")
' Get all text to put in a search index
Private text As String = pdf.ExtractAllText()
' Get all Images
Private allImages = pdf.ExtractAllImages()
' Or even find the precise text and images for each page in the document
For index = 0 To pdf.PageCount - 1
Dim pageNumber As Integer = index + 1
text = pdf.ExtractTextFromPage(index)
Dim images As List(Of AnyBitmap) = pdf.ExtractBitmapsFromPage(index)
' Further processing here...
Next indexPara información más detallada sobre IronPDF, por favor visita la Documentación de IronPDF.
Conclusión
En este artículo, aprendimos cómo extraer y ver el contenido de un documento PDF en C++ usando la herramienta de línea de comandos Xpdf. Este enfoque nos permite procesar y analizar el texto extraído dentro de nuestras aplicaciones C++ sin problemas.
Se encuentra disponible una licencia de prueba gratuita para evaluación con fines comerciales.














