How to View PDF Files in C++
PDF files are a widely used format for document exchange due to their ability to preserve formatting across different platforms. In various applications, programmatically reading the contents of PDF files becomes invaluable.
In this article, we will learn how to view text from PDF files in C++ using the Xpdf command-line tool. Xpdf provides a suite of command-line utilities and C++ libraries for working with PDF files, including text extraction. By integrating Xpdf into our C++ PDF viewer program, we can efficiently view text content from PDF files and process it programmatically.
Xpdf - C++ Library and Command-line Tools
Xpdf is an open-source software suite that offers a range of tools and libraries for working with PDF files. It includes various command-line utilities and C++ libraries that enable PDF-related functionalities, such as parsing, rendering, printing, and text extraction. Xpdf's command-line tools also offer ways to view PDF files directly from the terminal.
One of the key components of Xpdf is pdftotext, which is primarily known for extracting text content from PDF files. However, when used in combination with other tools like pdftops and pdfimages, Xpdf allows users to view the PDF content in different ways. The pdftotext tool proves valuable for extracting textual information from PDFs for further processing or analysis, and it offers options to specify which pages to extract text from.
Prerequisites
Before we begin, ensure you have the following prerequisites in place:
- A C++ compiler such as GCC or Clang installed on your system. We will be using Code::Blocks IDE for this purpose.
- Xpdf command-line tools installed and accessible from the command line. Download Xpdf and install the version suited to your environment. Afterward, set the bin directory of Xpdf in the system environment variables path to access it from any location on the file system.
Creating a PDF Viewer Project
- Open Code::Blocks: Launch the Code::Blocks IDE on your computer.
- Create a New Project: Click on "File" from the top menu and select "New" from the drop-down menu. Then, click on "Project" from the submenu.
- Choose Project Type: In the "New from template" window, choose "Console application", and click "Go". Then select the language "C/C++" and click "Next."
- Enter Project Details: In the "Project title" field, give your project a name (e.g., "PDFViewer"). Choose the location where you want to save the project files, and click "Next."
- Select Compiler: Choose the compiler you want to use for your project. By default, Code::Blocks should have automatically detected the available compilers on your system. If not, select a suitable compiler from the list, and click "Finish."
Steps to View Text from PDF in C++
Include the Necessary Headers
First, let's add the required header files to our main.cpp file:
#include <cstdlib>
#include <iostream>
#include <fstream>
#include <cstdio>
using namespace std; // Use standard namespace for convenience#include <cstdlib>
#include <iostream>
#include <fstream>
#include <cstdio>
using namespace std; // Use standard namespace for convenienceSet Input and Output Paths
string pdfPath = "input.pdf";
string outputFilePath = "output.txt";string pdfPath = "input.pdf";
string outputFilePath = "output.txt";In the main function, we declare two strings: pdfPath and outputFilePath. pdfPath stores the path to the input PDF file, and outputFilePath stores the path where the extracted text will be saved as a plain text file.
Input file is as follows:

Execute the pdftotext Command
// Construct the command to execute pdftotext with input and output paths
string command = "pdftotext " + pdfPath + " " + outputFilePath;
// Execute the command using system function and capture the status
int status = system(command.c_str());// Construct the command to execute pdftotext with input and output paths
string command = "pdftotext " + pdfPath + " " + outputFilePath;
// Execute the command using system function and capture the status
int status = system(command.c_str());Here, we construct the pdftotext command using the pdfPath and outputFilePath variables to open the PDF file for viewing its contents. The system function is then called to execute the command, and its return value is stored in the status variable.
Check Text Extraction Status
if (status == 0)
{
cout << "Text extraction successful." << endl;
}
else
{
cout << "Text extraction failed." << endl;
}if (status == 0)
{
cout << "Text extraction successful." << endl;
}
else
{
cout << "Text extraction failed." << endl;
}We check the status variable to see if the pdftotext command executed successfully. If status is equal to 0, it means the text extraction was successful, and we print a success message. If the status is non-zero, it indicates an error, and we print an error message.
Read Extracted Text and Display
// Open the output file to read the extracted text
ifstream outputFile(outputFilePath);
if (outputFile.is_open())
{
string textContent;
string line;
while (getline(outputFile, line))
{
textContent += line + "\n"; // Concatenate each line to the text content
}
outputFile.close();
cout << "Text content extracted from PDF:" << endl;
cout << textContent << endl;
}
else
{
cout << "Failed to open output file." << endl;
}// Open the output file to read the extracted text
ifstream outputFile(outputFilePath);
if (outputFile.is_open())
{
string textContent;
string line;
while (getline(outputFile, line))
{
textContent += line + "\n"; // Concatenate each line to the text content
}
outputFile.close();
cout << "Text content extracted from PDF:" << endl;
cout << textContent << endl;
}
else
{
cout << "Failed to open output file." << endl;
}In the above sample code, we open the outputFile (the text file generated by pdftotext), read its content line by line, and store it in the textContent string. Finally, we close the file and print the extracted text content on the console.
Remove Output File
If you do not need the editable output text file or want to free up disk space, at the end of the program simply delete it using the following command before ending the main function:
// Remove the output file to free up disk space and if output is not needed
remove(outputFilePath.c_str());// Remove the output file to free up disk space and if output is not needed
remove(outputFilePath.c_str());Compiling and Running the Program
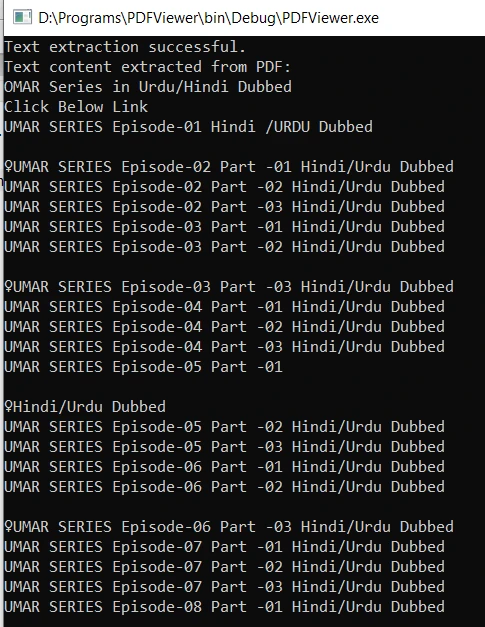
Build the code using the "Ctrl+F9" shortcut key. Upon successful compilation, running the executable will extract the text content from the specified PDF document and display it on the console. The output is as follows:
View PDF files in C#
IronPDF .NET C# Library is a powerful .NET C# PDF library that allows users to easily view PDF files within their C# applications. Leveraging the Chromium web browser engine, IronPDF accurately renders and displays PDF content, including images, fonts, and complex formatting. With its user-friendly interface and extensive functionalities, developers can seamlessly integrate IronPDF into their C# projects, enabling users to view PDF documents efficiently and interactively. Whether it's for displaying reports, invoices, or any other PDF content, IronPDF provides a robust solution for creating feature-rich PDF viewers in C#.
To install the IronPDF NuGet package in Visual Studio, follow these steps:
- Open Visual Studio: Launch Visual Studio or any other IDE of your preference.
- Create or Open Your Project: Create a new C# project or open an existing one where you want to install the IronPDF package.
- Open the NuGet Package Manager: In Visual Studio, go to "Tools" > "NuGet Package Manager" > "Manage NuGet Packages for Solution". Alternatively, click on solution explorer and then select "Manage NuGet Packages for Solution".
- Search for IronPDF: In the "NuGet Package Manager" window, click on the "Browse" tab, and then search for "IronPDF" in the search bar. Alternatively, visit the NuGet IronPDF Package and directly download the latest version of "IronPDF".
- Select IronPDF Package: Find the "IronPDF" package and click on it to select it for your project.
- Install IronPDF: Click the "Install" button to install the selected package.
-
However, you can also install IronPDF using NuGet Package Manager Console using the following command:
Install-Package IronPdf
Using IronPDF, we can perform operations such as extract text and images from PDF documents and display them in the console for viewing. The following code helps to achieve this task:
using IronPdf;
using IronSoftware.Drawing;
using System.Collections.Generic;
// Extracting Image and Text content from Pdf Documents
// Open a 128-bit encrypted PDF
var pdf = PdfDocument.FromFile("encrypted.pdf", "password");
// Get all text to put in a search index
string text = pdf.ExtractAllText();
// Get all Images
var allImages = pdf.ExtractAllImages();
// Or even find the precise text and images for each page in the document
for (var index = 0 ; index < pdf.PageCount ; index++)
{
int pageNumber = index + 1;
text = pdf.ExtractTextFromPage(index);
List<AnyBitmap> images = pdf.ExtractBitmapsFromPage(index);
// Further processing here...
}using IronPdf;
using IronSoftware.Drawing;
using System.Collections.Generic;
// Extracting Image and Text content from Pdf Documents
// Open a 128-bit encrypted PDF
var pdf = PdfDocument.FromFile("encrypted.pdf", "password");
// Get all text to put in a search index
string text = pdf.ExtractAllText();
// Get all Images
var allImages = pdf.ExtractAllImages();
// Or even find the precise text and images for each page in the document
for (var index = 0 ; index < pdf.PageCount ; index++)
{
int pageNumber = index + 1;
text = pdf.ExtractTextFromPage(index);
List<AnyBitmap> images = pdf.ExtractBitmapsFromPage(index);
// Further processing here...
}Imports IronPdf
Imports IronSoftware.Drawing
Imports System.Collections.Generic
' Extracting Image and Text content from Pdf Documents
' Open a 128-bit encrypted PDF
Private pdf = PdfDocument.FromFile("encrypted.pdf", "password")
' Get all text to put in a search index
Private text As String = pdf.ExtractAllText()
' Get all Images
Private allImages = pdf.ExtractAllImages()
' Or even find the precise text and images for each page in the document
For index = 0 To pdf.PageCount - 1
Dim pageNumber As Integer = index + 1
text = pdf.ExtractTextFromPage(index)
Dim images As List(Of AnyBitmap) = pdf.ExtractBitmapsFromPage(index)
' Further processing here...
Next indexFor more detailed information on IronPDF, please visit the IronPDF Documentation.
Conclusion
In this article, we learned how to extract and view the contents of a PDF document in C++ using the Xpdf command-line tool. This approach allows us to process and analyze the extracted text within our C++ applications seamlessly.
A Free Trial License is available to test for commercial purposes.