
Cómo Extraer Datos De Un PDF en Java
Este tutorial te mostrará cómo usar IronPDF for Java para extraer datos de un archivo PDF. La configuración del entorno, la importación de la biblioteca, la lectura del archivo de entrada y la extracción de los datos necesarios se explican con ejemplos de código.
2. Biblioteca PDF Java IronPDF
IronPDF es una biblioteca de software que proporciona a los desarrolladores la capacidad de generar, editar y extraer datos de archivos PDF usando IronPDF for Java dentro de sus aplicaciones Java. Te permite crear PDFs a partir de documentos HTML, imágenes y más, así como fusionar múltiples PDFs, dividir archivos PDF, y manipular PDFs existentes. IronPDF también proporciona la capacidad de asegurar PDFs con características de protección con contraseña y añadir firmas digitales a PDFs, entre otras características.
IronPDF for Java es desarrollado y mantenido por Iron Software. Una de sus características mejor valoradas es extraer texto y datos de archivos PDF, así como de HTML y URLs.
3. Requisitos previos
Para usar IronPDF para extraer datos de archivos PDF, debes cumplir con los siguientes requisitos previos:
- Instalación de Java: Asegúrate de que Java esté instalado en tu sistema y que su ruta esté configurada en las variables de entorno. Si aún no has instalado Java, consulta esta página de descarga en el sitio de Java para obtener instrucciones.
- IDE de Java: Ten un IDE de Java como Eclipse o IntelliJ instalado. Puedes descargar Eclipse desde esta página de descarga de Eclipse e IntelliJ desde esta página de descarga de IntelliJ.
- Biblioteca IronPDF: Descarga y agrega la biblioteca IronPDF como una dependencia en tu proyecto. Visita la página de instrucciones de configuración de IronPDF para instrucciones de configuración.
- Instalación de Maven: Maven debe estar instalado e integrado con tu IDE antes de comenzar el proceso de conversión de PDF. Consulta este tutorial de instalación de Maven en JetBrains sobre instalación e integración de Maven.
4. Instalación de IronPDF for Java
Instalar IronPDF for Java es fácil y sencillo, siempre y cuando se cumplan todos los requisitos. Esta guía usará IntelliJ IDEA de JetBrains para demostrar la instalación y ejecutar código de ejemplo.
Esto es lo que debes hacer:
- Abre IntelliJ IDEA: Inicia JetBrains IntelliJ IDEA en tu sistema.
- Crea un Proyecto Maven: En IntelliJ IDEA, crea un nuevo proyecto Maven. Esto proporcionará un entorno adecuado para la instalación de IronPDF for Java.
 Nuevo Proyecto Maven en IntelliJ
Nuevo Proyecto Maven en IntelliJ
- Aparecerá una nueva ventana. Ingresa el nombre del proyecto y haz clic en Terminar.
 Nombra el Proyecto Maven y haz clic en Terminar
Nombra el Proyecto Maven y haz clic en Terminar
- Se abrirá un nuevo proyecto con un pom.xml una vez que hagas clic en Terminar. Esto se usará para añadir dependencias Maven de IronPDF for Java.
 El archivo pom.xml
El archivo pom.xml
Añade las siguientes dependencias en el archivo pom.xml o descarga el archivo JAR desde la página de la biblioteca de IronPDF en Sonatype Central.
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>1.0.0</version>
</dependency><dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>1.0.0</version>
</dependency>Una vez que hayas colocado las dependencias en el archivo pom.xml, aparecerá un pequeño icono en la esquina superior derecha del archivo.
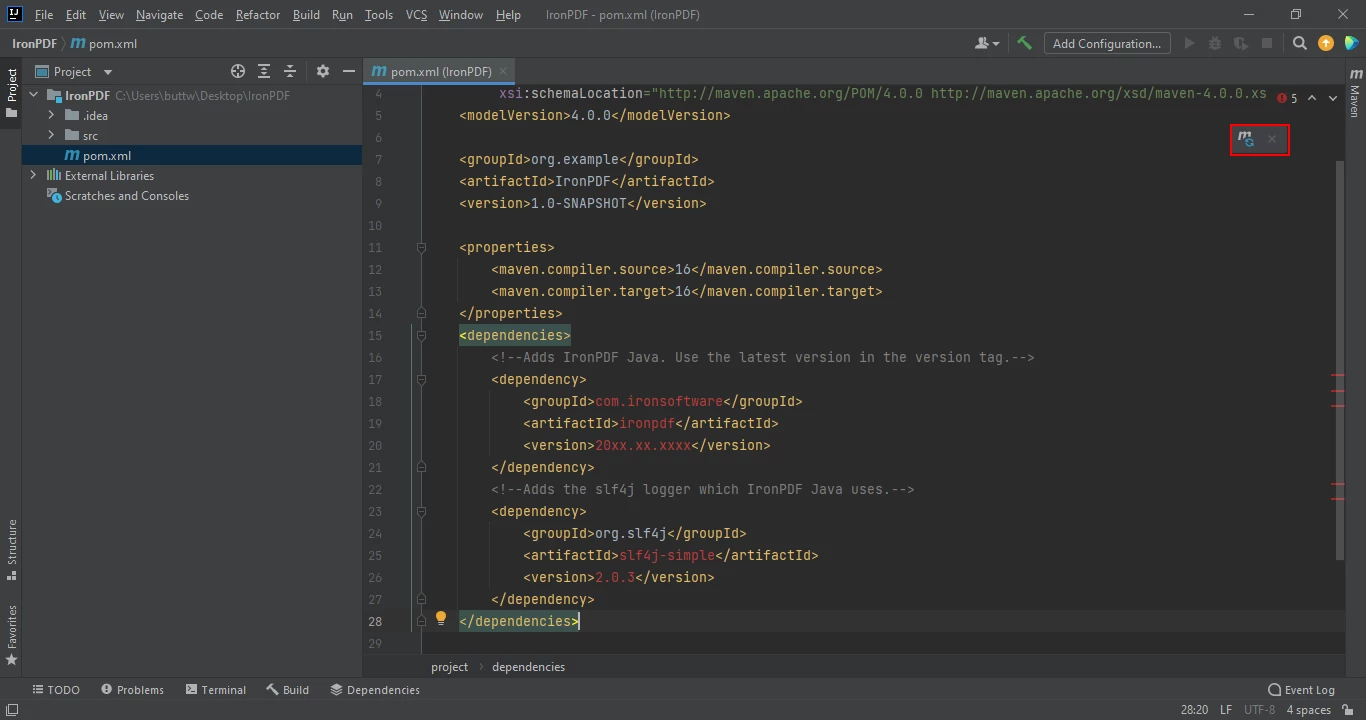 Haz clic en el icono flotante para instalar automáticamente las dependencias de Maven
Haz clic en el icono flotante para instalar automáticamente las dependencias de Maven
Instala las dependencias Maven de IronPDF for Java haciendo clic en este botón. Dependiendo de la velocidad de tu conexión a internet, esto debería tomar solo unos minutos.
5. Extraer datos
IronPDF es una biblioteca Java para crear, editar y extraer datos de documentos PDF. Proporciona una API simple para extraer texto de archivos PDF, URLs y tablas.
5.1. Extraer datos de documentos PDF
Usando IronPDF for Java, puedes fácilmente extraer datos de texto de documentos PDF. A continuación se muestra el código de ejemplo para extraer datos de un archivo PDF.
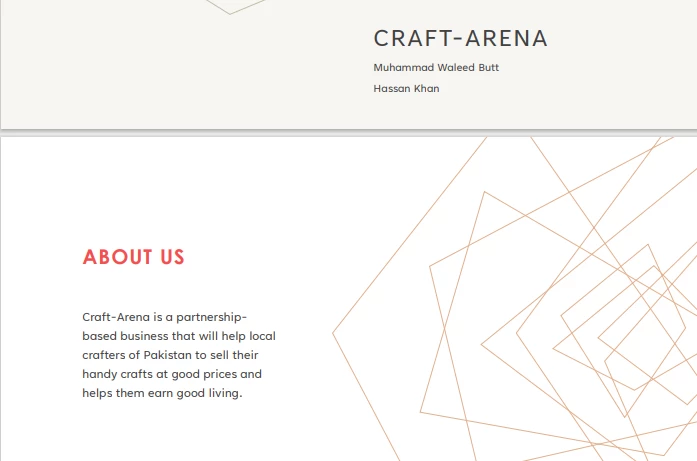 Entrada PDF
Entrada PDF
// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
import java.nio.file.Paths;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from the specified file
PdfDocument pdf = PdfDocument.fromFile(Paths.get("business plan.pdf"));
// Extract all text from the PDF document
String text = pdf.extractAllText();
// Print the extracted text to the console
System.out.println("Text extracted from the PDF: " + text);
}
}// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
import java.nio.file.Paths;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from the specified file
PdfDocument pdf = PdfDocument.fromFile(Paths.get("business plan.pdf"));
// Extract all text from the PDF document
String text = pdf.extractAllText();
// Print the extracted text to the console
System.out.println("Text extracted from the PDF: " + text);
}
}El código fuente produce la salida que se muestra a continuación:
> Text extracted from the PDF:
>
> CRAFT-ARENA
>
> Muhammad Waleed Butt
>
> Hassan Khan
>
> ABOUT US
>
> Craft-Arena is a partnership based business that will help local crafters of Pakistan to sell their handicrafts at good prices and helps them earn a good living.5.2. Extraer datos de URL
IronPDF for Java convierte la URL a PDF en tiempo de ejecución y extrae texto de ella. Este ejemplo mostrará el código fuente para extraer texto de URLs.
// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException {
// Convert a URL to a PDF and load it into a PdfDocument
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
// Extract all text from the PDF document
String text = pdf.extractAllText();
// Print the extracted text to the console
System.out.println("Text extracted from the URLs: " + text);
}
}// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException {
// Convert a URL to a PDF and load it into a PdfDocument
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
// Extract all text from the PDF document
String text = pdf.extractAllText();
// Print the extracted text to the console
System.out.println("Text extracted from the URLs: " + text);
}
}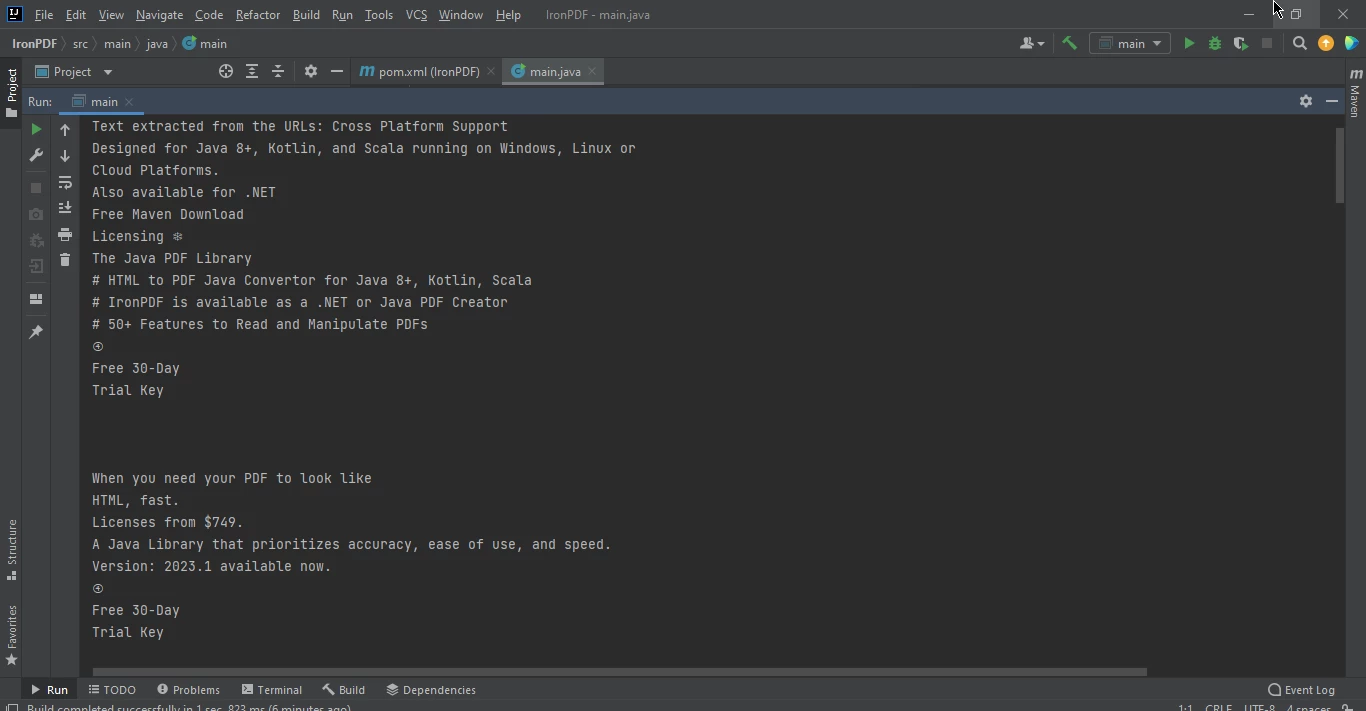 Datos de Página Web Extraídos
Datos de Página Web Extraídos
5.3. Extraer datos de datos de tabla
Para extraer datos de tabla de un PDF usando IronPDF for Java es muy simple; todo lo que necesitas es un PDF que contenga una tabla, y ejecutar el código abajo.
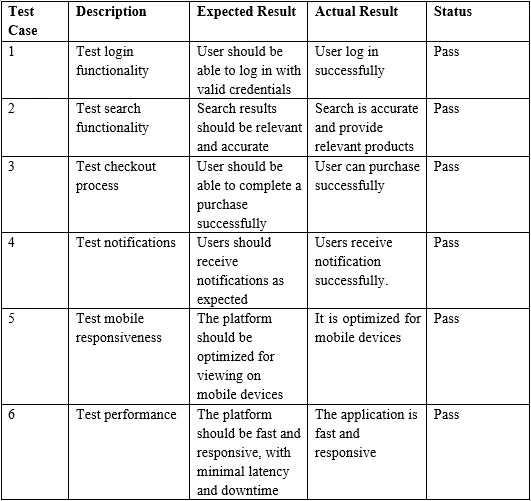 Ejemplo de Entrada de Tabla PDF
Ejemplo de Entrada de Tabla PDF
// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
import java.nio.file.Paths;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from the specified file
PdfDocument pdf = PdfDocument.fromFile(Paths.get("table.pdf"));
// Extract all text from the PDF document, including table data
String text = pdf.extractAllText();
// Print the extracted table data to the console
System.out.print("Text extracted from the Marked tables: " + text);
}
}// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
import java.nio.file.Paths;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from the specified file
PdfDocument pdf = PdfDocument.fromFile(Paths.get("table.pdf"));
// Extract all text from the PDF document, including table data
String text = pdf.extractAllText();
// Print the extracted table data to the console
System.out.print("Text extracted from the Marked tables: " + text);
}
}> Test Case Description Expected Result Actual Result Status
>
> 1 Test login functionality User should be able to log in with valid credentials
>
> User log in successfully Pass
>
> 2 Test search functionality Search results should be relevant and accurate
>
> Search is accurate and provide relevant products Pass
>
> 3 Test checkout process User should be able to complete a purchase successfully
>
> User can purchase successfully Pass6. Conclusión
En conclusión, este tutorial ha demostrado cómo extraer datos, específicamente datos tabulares, de un archivo PDF usando IronPDF for Java.
Para más información, por favor consulta el ejemplo de extracción de texto de PDF en el sitio de IronPDF.
IronPDF es una biblioteca con una licencia comercial cuyos detalles comienzan en $999. Sin embargo, puedes evaluarlo en producción con una prueba gratuita usando la licencia de prueba de IronPDF.
Preguntas Frecuentes
¿Cómo extraigo texto de un PDF en Java?
Puede usar IronPDF for Java para extraer texto de un PDF cargando el documento con la clase PdfDocument y utilizando el método extractAllText para recuperar el texto.
¿Puedo extraer datos de una URL y convertirlo en PDF en Java?
Sí, IronPDF for Java le permite convertir una URL a un PDF en tiempo de ejecución y extraer datos de él utilizando la clase PdfDocument.
¿Cuáles son los pasos para configurar IronPDF en IntelliJ IDEA?
Para configurar IronPDF en IntelliJ IDEA, cree un nuevo proyecto Maven, agregue la biblioteca IronPDF a su archivo pom.xml, e instale las dependencias de Maven haciendo clic en el ícono flotante que aparece.
¿Cuáles son los requisitos previos para usar IronPDF en Java?
Los requisitos previos incluyen tener Java instalado, un IDE de Java como Eclipse o IntelliJ, la biblioteca IronPDF, y Maven instalado e integrado con su IDE.
¿Cómo puedo extraer datos de tablas de un PDF usando Java?
Para extraer datos de tablas de un PDF usando IronPDF for Java, cargue el documento PDF con la clase PdfDocument y utilice el método extractAllText para recuperar los datos de las tablas.
¿Se requiere una licencia comercial para usar IronPDF for Java?
Sí, IronPDF for Java requiere una licencia comercial, pero hay una prueba gratuita disponible para fines de evaluación.
¿Dónde puedo encontrar tutoriales para usar IronPDF en Java?
Tutoriales y ejemplos para usar IronPDF for Java se pueden encontrar en el sitio web de IronPDF, particularmente en las secciones de ejemplos y tutoriales.
¿Qué funcionalidades ofrece IronPDF para desarrolladores Java?
IronPDF for Java proporciona funcionalidades para crear, editar, combinar, dividir y manipular archivos PDF, así como características para asegurar PDFs con protección por contraseña y agregar firmas digitales.
¿Cómo puedo solucionar problemas al extraer datos de PDFs usando Java?
Asegúrese de que se cumplan todos los requisitos previos, como tener la última versión de Java, un IDE compatible, y la biblioteca IronPDF. Verifique la correcta integración de Maven y las dependencias de la biblioteca en su archivo pom.xml.

















