
Cómo Analizar PDFs en Java (Tutorial para Desarrolladores)
En este artículo se creará un analizador de PDF en Java utilizando la biblioteca IronPDF de forma eficiente.
IronPDF - Biblioteca PDF for Java
IronPDF for Java es una biblioteca Java para PDF que permite crear, leer y manipular documentos PDF con facilidad y precisión. Se basa en el éxito de IronPDF for .NET y ofrece una funcionalidad eficiente en diferentes plataformas. IronPDF for Java utiliza el IronPdfEngine, que es rápido y está optimizado para el rendimiento.
Con IronPDF, puede extraer texto e imágenes de archivos PDF y también permite crear archivos PDF a partir de diversas fuentes, incluyendo cadenas HTML, archivos, URL e imágenes. Además, puede añadir fácilmente contenido nuevo, insertar firmas con IronPDF e incrustar metadatos en documentos PDF. IronPDF está diseñado específicamente for Java 8+, Scala y Kotlin, y es compatible con Windows, Linux y plataformas en la nube.
Cómo analizar un archivo PDF en Java
- Descargar la biblioteca Java para analizar un archivo PDF
- Cargar un documento PDF existente utilizando el
fromFilemétodo - Extraiga todo el texto del PDF analizado utilizando el
extractAllTextmétodo - Utilice el
renderUrlAsPdfmétodo para generar un PDF a partir de una URL - Extrae imágenes del PDF analizado utilizando el
extractAllImagesmétodo
Crear un analizador de archivos PDF utilizando IronPDF en un programa Java
Requisitos previos
Para crear un proyecto de análisis de PDF en Java, necesitarás las siguientes herramientas:
- IDE de Java: Puedes utilizar cualquier IDE compatible con Java. Existen múltiples IDE de Java disponibles para el desarrollo. En este tutorial se utilizará el IDE IntelliJ. Puedes utilizar NetBeans, Eclipse, etc.
- Proyecto Maven: Maven es un gestor de dependencias que permite controlar el proyecto Java. Maven for Java se puede descargar desde el sitio web oficial de Maven. El IDE Java de IntelliJ tiene compatibilidad integrada con Maven.
-
IronPDF: puede descargar e instalar IronPDF for Java de varias formas.
-
Añadir la dependencia de IronPDF en el archivo
pom.xmlde un proyecto Maven.<dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>[LATEST_VERSION]</version> </dependency><dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>[LATEST_VERSION]</version> </dependency>XML - Visita el sitio web del repositorio Maven para obtener el último paquete de IronPDF for Java.
- Descarga directa desde la página oficial de descargas de Iron Software.
- Instala IronPDF manualmente utilizando el archivo JAR en tu sencilla aplicación Java.
-
-
slf4j-Simple: Esta dependencia también es necesaria para insertar contenido en un documento existente. Se puede añadir mediante el gestor de dependencias de Maven en IntelliJ, o se puede descargar directamente desde el sitio web de Maven. Añade la siguiente dependencia al archivo
pom.xml:<dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-simple</artifactId> <version>2.0.5</version> </dependency><dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-simple</artifactId> <version>2.0.5</version> </dependency>XML
Añadir las importaciones necesarias
Una vez instalados todos los requisitos previos, el primer paso es importar los paquetes necesarios de IronPDF para trabajar con un documento PDF. Añade el siguiente código al principio del archivo Main.java:
import com.ironsoftware.ironpdf.*;
import java.io.IO/Exception;
import java.nio.file.Paths;import com.ironsoftware.ironpdf.*;
import java.io.IO/Exception;
import java.nio.file.Paths;Clave de licencia
Algunos métodos disponibles en IronPDF requieren una licencia para su uso. Puedes adquirir una licencia o probar IronPDF de forma gratuita con una versión de prueba. Puede establecer la clave de la siguiente manera:
License.setLicenseKey("YOUR-KEY");License.setLicenseKey("YOUR-KEY");Paso 1: Analizar un documento PDF existente
Para analizar un documento existente con el fin de extraer contenido, se utiliza la clase PdfDocument. Su método estático [fromFile](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#fromFile(java.nio.file.Path) se utiliza para analizar un archivo PDF desde una ruta específica con un nombre de archivo concreto en un programa Java. El código es el siguiente:
PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("sample.pdf"));PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("sample.pdf"));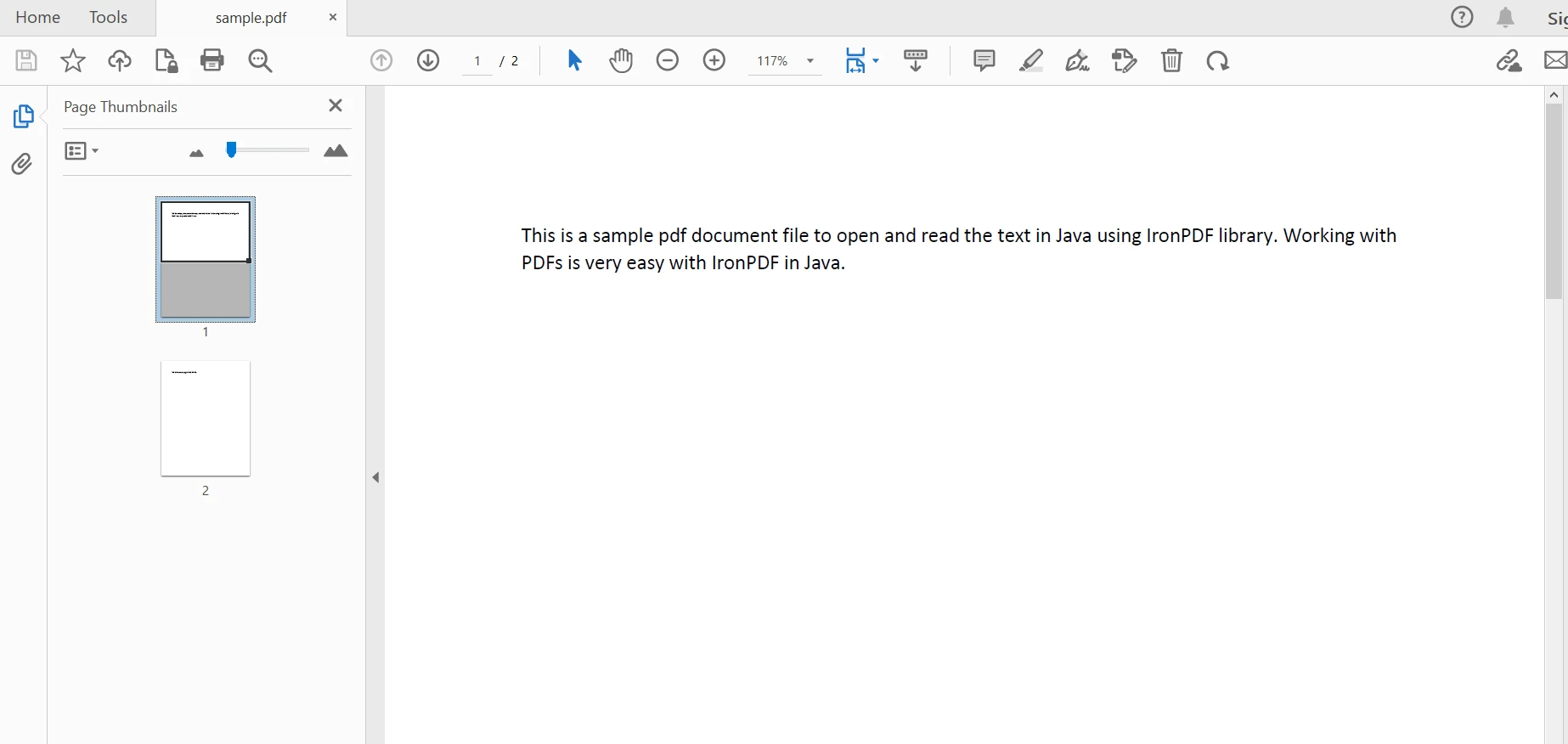 Documento analizado
Documento analizado
Paso 2: Extraer datos de texto de un archivo PDF analizado
IronPDF for Java ofrece un método sencillo para extraer texto de documentos PDF. A continuación se muestra un fragmento de código para extraer datos de texto de un archivo PDF:
String extractedText = parsedDocument.extractAllText();String extractedText = parsedDocument.extractAllText();El código anterior produce el resultado que se muestra a continuación:
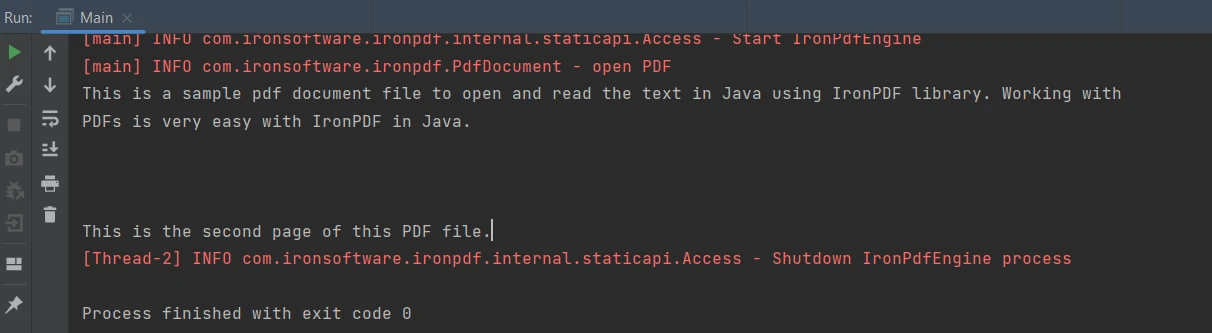 Resultado
Resultado
Paso 3: Extraer datos de texto de URL o cadenas HTML
La capacidad de IronPDF for Java no se limita únicamente a los archivos PDF existentes, sino que también permite crear y analizar un nuevo archivo para extraer contenido. En este tutorial, crearemos un archivo PDF a partir de una URL y extraeremos contenido del mismo. El siguiente ejemplo muestra cómo llevar a cabo esta tarea:
public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
String extractedText = parsedDocument.extractAllText();
System.out.println("Text Extracted from URL:\n" + extractedText);
}
}public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
String extractedText = parsedDocument.extractAllText();
System.out.println("Text Extracted from URL:\n" + extractedText);
}
}El resultado es el siguiente:
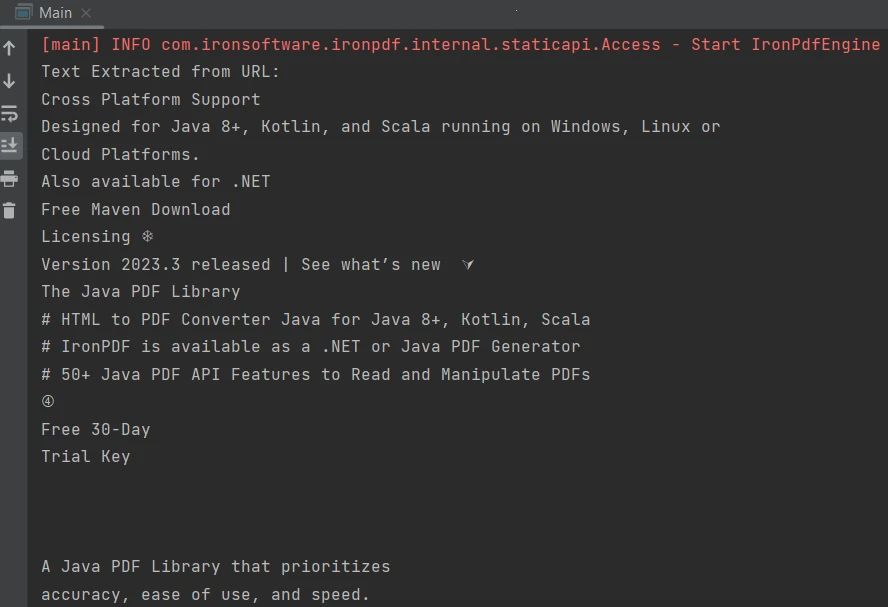 Resultado
Resultado
Paso 4: Extraer imágenes de un documento PDF analizado
IronPDF también ofrece una opción sencilla para extraer todas las imágenes de los documentos analizados. En este tutorial se utilizará el ejemplo anterior para ver lo fácil que es extraer las imágenes de los archivos PDF.
import com.ironsoftware.ironpdf.*;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.IO/Exception;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
try {
List<BufferedImage> images = parsedDocument.extractAllImages();
System.out.println("Number of images extracted from the website: " + images.size());
int i = 0;
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("assets/extracted_" + ++i + ".png")));
}
} catch (Exception exception) {
System.out.println("Failed to extract images from the website");
exception.printStackTrace();
}
}
}import com.ironsoftware.ironpdf.*;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.IO/Exception;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
try {
List<BufferedImage> images = parsedDocument.extractAllImages();
System.out.println("Number of images extracted from the website: " + images.size());
int i = 0;
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("assets/extracted_" + ++i + ".png")));
}
} catch (Exception exception) {
System.out.println("Failed to extract images from the website");
exception.printStackTrace();
}
}
}El método [extractAllImages](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllImages() devuelve una lista de BufferedImages. Cada BufferedImage se puede almacenar como imágenes PNG en una ubicación utilizando el método ImageIO.write. Hay 34 imágenes en el archivo PDF analizado y todas ellas se han extraído perfectamente.
 Imágenes extraídas
Imágenes extraídas
Paso 5: Extraer datos de tablas en archivos PDF
Extraer contenido de los límites de las tablas en un archivo PDF es muy sencillo con solo una línea de código utilizando el [método extractAllText](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllText(). El siguiente fragmento de código muestra cómo extraer texto de una tabla en un archivo PDF:
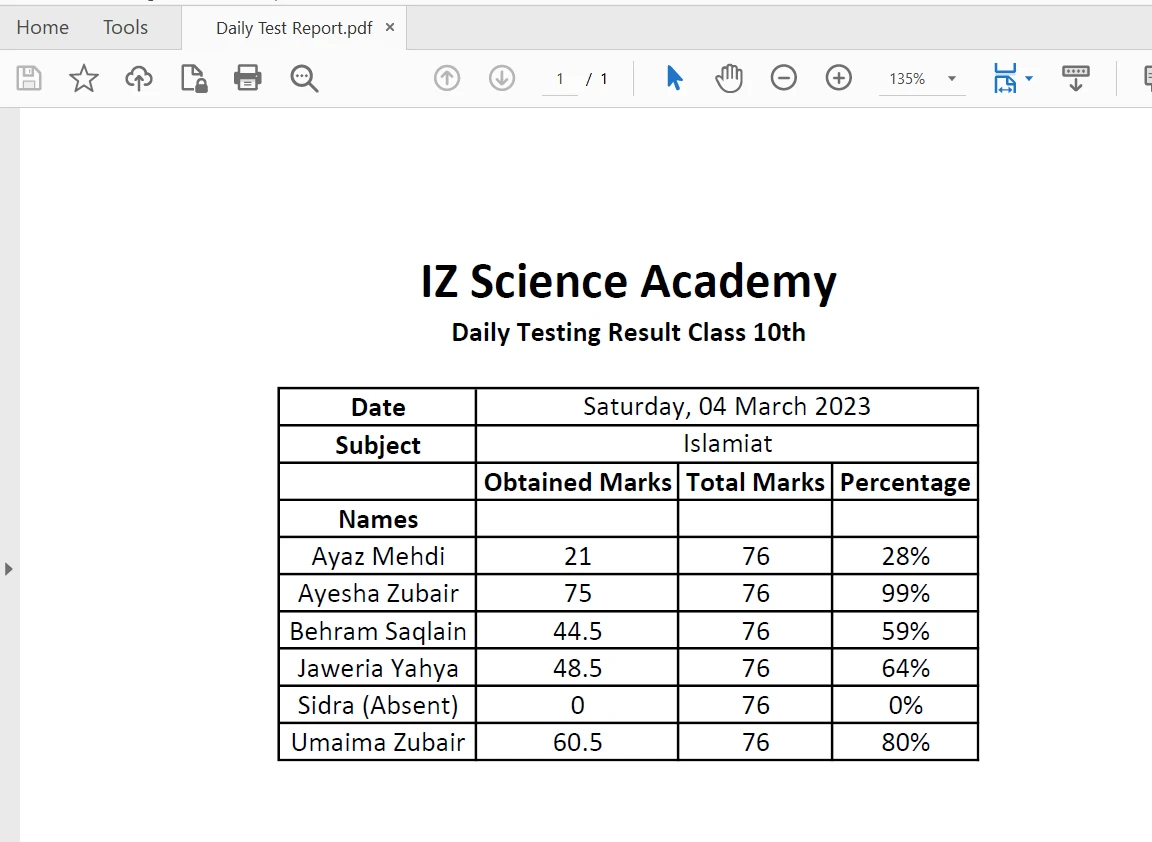 Tabla en PDF
Tabla en PDF
PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("table.pdf"));
String extractedText = parsedDocument.extractAllText();
System.out.println(extractedText);PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("table.pdf"));
String extractedText = parsedDocument.extractAllText();
System.out.println(extractedText);El resultado es el siguiente:
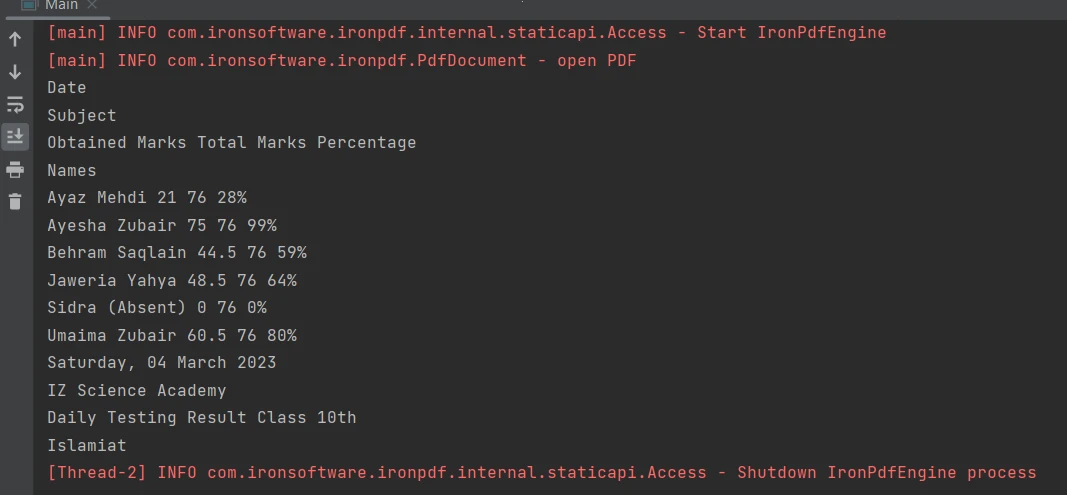 Resultado
Resultado
Conclusión
Este artículo ha mostrado cómo analizar un documento PDF existente o crear un nuevo archivo de análisis de PDF a partir de una URL para extraer datos del mismo en Java utilizando IronPDF. Tras abrir el archivo, puede extraer datos tabulares, imágenes y texto del PDF, y también puede añadir el texto extraído a un archivo de texto para su uso posterior.
Para obtener información más detallada sobre cómo trabajar con archivos PDF mediante programación en Java, consulte estos ejemplos de creación de archivos PDF.
La biblioteca IronPDF for Java es gratuita para fines de desarrollo y ofrece una versión de prueba gratuita. No obstante, para uso comercial se puede obtener una licencia a través de Iron Software, a partir de $999.
Preguntas Frecuentes
¿Cómo creo un analizador de PDF en Java?
Para crear un analizador de PDF en Java, puede usar la biblioteca IronPDF. Comience descargando e instalando IronPDF, luego cargue su documento PDF usando el método fromFile. Puede extraer texto e imágenes utilizando los métodos extractAllText y extractAllImages respectivamente.
¿Puede usarse IronPDF con Java 8+?
Sí, IronPDF es compatible con Java 8 y superior, así como Scala y Kotlin. Soporta múltiples plataformas, incluidas Windows, Linux y entornos en la nube.
¿Cuáles son los pasos clave para analizar PDFs usando IronPDF en Java?
Los pasos clave incluyen configurar un proyecto Maven, agregar la dependencia de IronPDF, cargar un documento PDF con fromFile, extraer texto usando extractAllText y extraer imágenes usando extractAllImages.
¿Cómo puedo convertir una URL a PDF en Java?
Puede convertir una URL a PDF en Java usando el método renderUrlAsPdf de IronPDF. Esto le permite renderizar páginas web como documentos PDF de manera eficiente.
¿Es adecuado IronPDF para aplicaciones Java basadas en la nube?
Sí, IronPDF está diseñado para ser versátil y admite entornos basados en la nube, lo que lo hace adecuado para desarrollar aplicaciones Java que requieren funcionalidades PDF en la nube.
¿Cómo gestiono las dependencias para un proyecto de análisis de PDF en Java?
Para gestionar las dependencias en un proyecto Java, puede usar Maven. Agregue la biblioteca IronPDF al archivo pom.xml de su proyecto para incluirla como una dependencia.
¿Qué opciones de licencia están disponibles para IronPDF?
IronPDF ofrece una prueba gratuita para fines de desarrollo. Sin embargo, para uso comercial, se requiere una licencia. Esto asegura el acceso a todas las funciones y soporte prioritario.

















