
How to Parse PDFs in Java (Developer Tutorial)
This article will create a PDF parser in Java using the IronPDF Library in an efficient approach.
IronPDF - Java PDF Library
IronPDF for Java is a Java PDF library that enables the creation, reading, and manipulation of PDF documents with ease and accuracy. It is built on the success of IronPDF for .NET and provides efficient functionality across different platforms. IronPDF for Java utilizes the IronPdfEngine which is fast and optimized for performance.
With IronPDF, you can extract text and images from PDF files and it also enables creating PDFs from various sources including HTML strings, files, URLs, and images. Furthermore, you can easily add new content, insert signatures with IronPDF, and embed metadata into PDF documents. IronPDF is specifically designed for Java 8+, Scala, and Kotlin, and is compatible with Windows, Linux, and Cloud platforms.
How to Parse a PDF File in Java
- Download the Java library for parsing a PDF file
- Load an existing PDF document using the
fromFilemethod - Extract all text from the parsed PDF using the
extractAllTextmethod - Use the
renderUrlAsPdfmethod to render a PDF from a URL - Extract images from the parsed PDF using the
extractAllImagesmethod
Create PDF File Parser using IronPDF in Java Program
Prerequisites
To make a PDF Parsing project in Java, you will need the following tools:
- Java IDE: You can use any Java-supported IDE. There are multiple Java IDEs available for development. Here this tutorial will be using IntelliJ IDE. You can use NetBeans, Eclipse, etc.
- Maven Project: Maven is a dependency manager and allows control over the Java project. Maven for Java can be downloaded from the Maven official website. IntelliJ Java IDE has built-in support for Maven.
-
IronPDF - You can download and install IronPDF for Java in multiple ways.
-
Adding IronPDF dependency in the
pom.xmlfile in a Maven project.<dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>[LATEST_VERSION]</version> </dependency><dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>[LATEST_VERSION]</version> </dependency>XML - Visit the Maven repository website for the latest IronPDF package for Java.
- A direct download from the Iron Software official download page.
- Manually install IronPDF using the JAR file in your simple Java Application.
-
-
Slf4j-Simple: This dependency is also required to stamp content to an existing document. It can be added using the Maven dependencies manager in IntelliJ, or it can be directly downloaded from the Maven website. Add the following dependency to the
pom.xmlfile:<dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-simple</artifactId> <version>2.0.5</version> </dependency><dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-simple</artifactId> <version>2.0.5</version> </dependency>XML
Adding the Necessary Imports
Once all the prerequisites are installed, the first step is to import the necessary IronPDF packages to work with a PDF document. Add the following code on top of the Main.java file:
import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;License Key
Some methods available in IronPDF require a license to be used. You can purchase a license or try IronPDF free in a free trial. You can set the key as follows:
License.setLicenseKey("YOUR-KEY");License.setLicenseKey("YOUR-KEY");Step 1: Parse an Existing PDF document
To parse an existing document for content extraction, the PdfDocument class is used. Its static [fromFile](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#fromFile(java.nio.file.Path) method is used to parse a PDF file from a specific path with a specific file name in a Java program. The code is as follows:
PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("sample.pdf"));PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("sample.pdf"));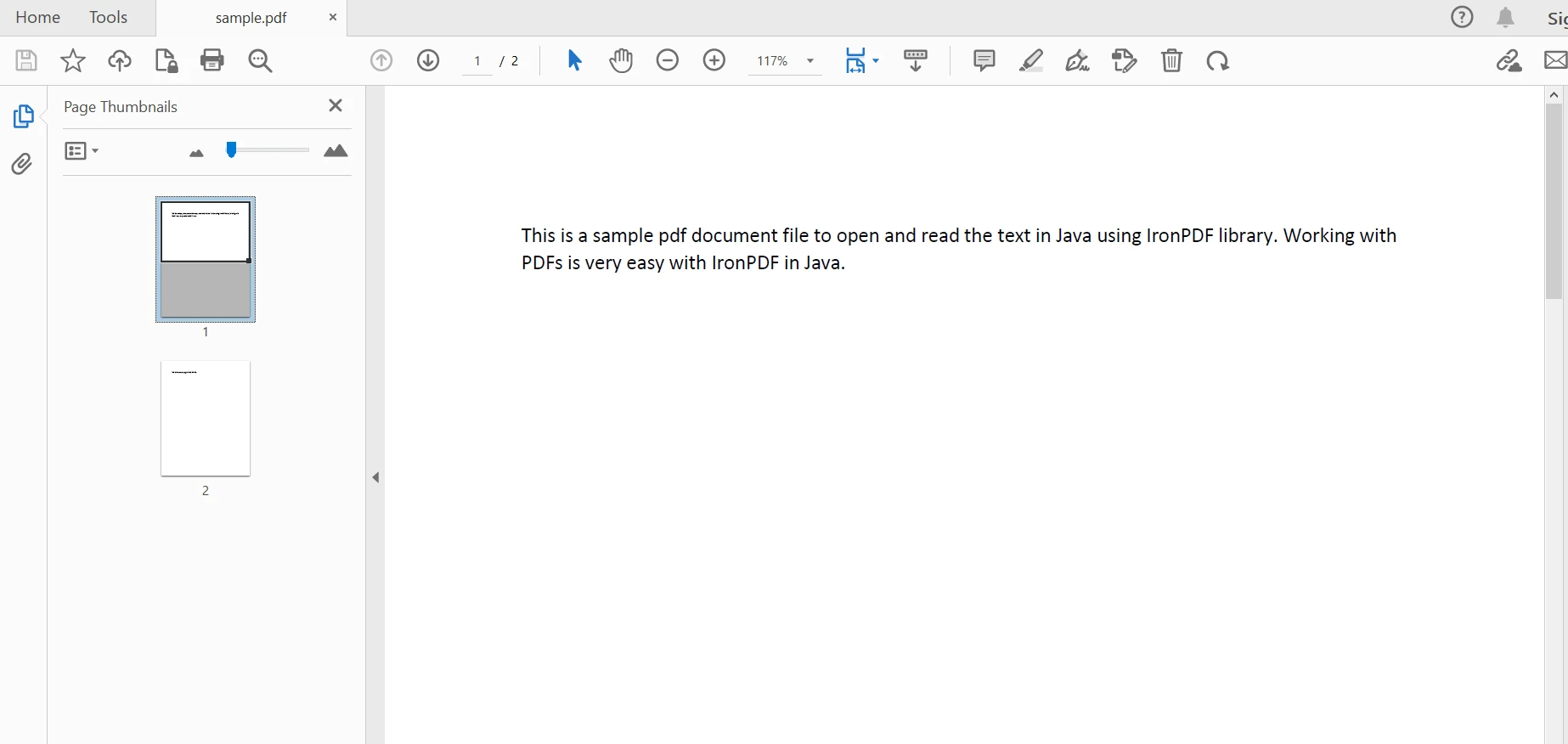 Parsed document
Parsed document
Step 2: Extract Text Data from Parsed PDF file
IronPDF for Java provides an easy method for extracting text from PDF documents. The following code snippet is for extracting text data from a PDF file is below:
String extractedText = parsedDocument.extractAllText();String extractedText = parsedDocument.extractAllText();The above code produces the output given below:
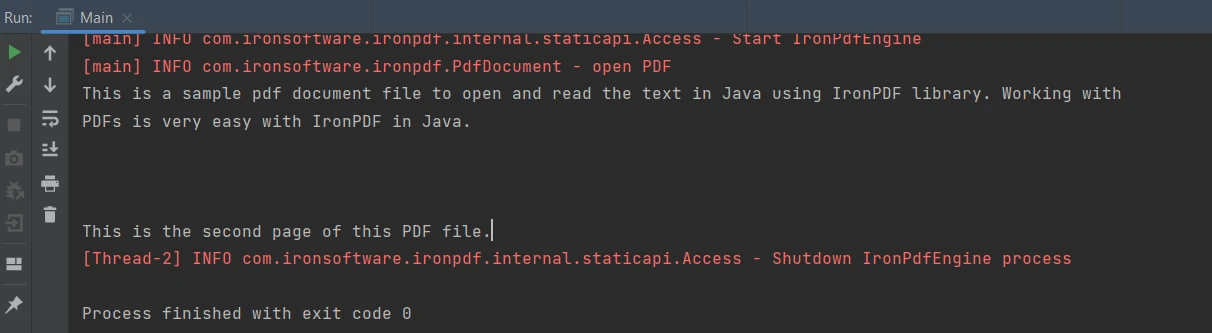 Output
Output
Step 3: Extract Text Data from URLs or HTML String
The capability of IronPDF for Java is not only restricted to existing PDFs, but it can also create and parse a new file to extract content. Here, this tutorial will create a PDF file from a URL and extract content from it. The following example shows how to achieve this task:
public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
String extractedText = parsedDocument.extractAllText();
System.out.println("Text Extracted from URL:\n" + extractedText);
}
}public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
String extractedText = parsedDocument.extractAllText();
System.out.println("Text Extracted from URL:\n" + extractedText);
}
}The output is as follows:
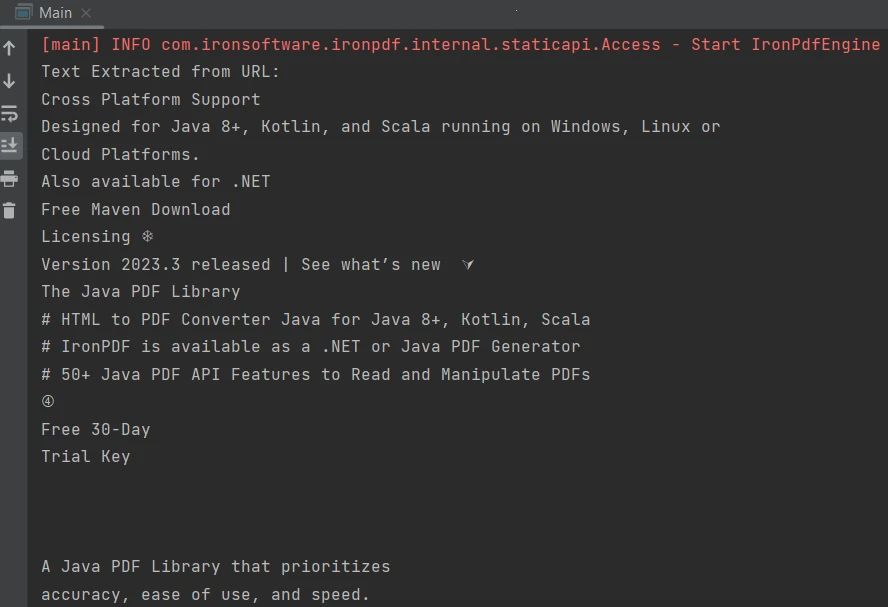 Output
Output
Step 4: Extract Images from Parsed PDF Document
IronPDF also provides an easy option to extract all images from parsed documents. Here the tutorial will use the previous example to see how easily the images are extracted from the PDF files.
import com.ironsoftware.ironpdf.*;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
try {
List<BufferedImage> images = parsedDocument.extractAllImages();
System.out.println("Number of images extracted from the website: " + images.size());
int i = 0;
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("assets/extracted_" + ++i + ".png")));
}
} catch (Exception exception) {
System.out.println("Failed to extract images from the website");
exception.printStackTrace();
}
}
}import com.ironsoftware.ironpdf.*;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
try {
List<BufferedImage> images = parsedDocument.extractAllImages();
System.out.println("Number of images extracted from the website: " + images.size());
int i = 0;
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("assets/extracted_" + ++i + ".png")));
}
} catch (Exception exception) {
System.out.println("Failed to extract images from the website");
exception.printStackTrace();
}
}
}The [extractAllImages](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllImages() method returns a list of BufferedImages. Each BufferedImage can then be stored as PNG images on a location using the ImageIO.write method. There are 34 images in the parsed PDF file and every image is perfectly extracted.
 Extracted images
Extracted images
Step 5: Extract Data from Table in PDF Files
Extracting content from tabular boundaries in a PDF file is made easy with just a one-line code using the [extractAllText method](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllText(). The following code snippet demonstrates how to extract text from a table in a PDF file:
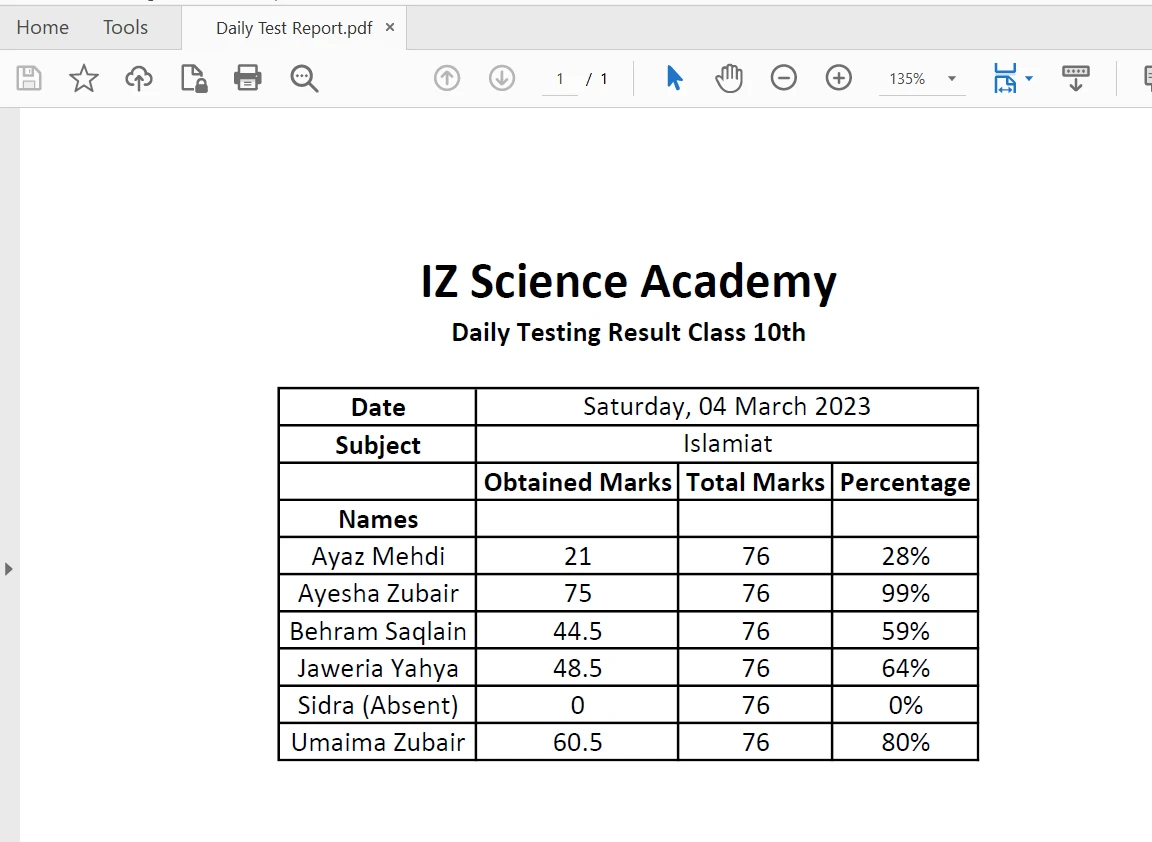 Table in PDF
Table in PDF
PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("table.pdf"));
String extractedText = parsedDocument.extractAllText();
System.out.println(extractedText);PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("table.pdf"));
String extractedText = parsedDocument.extractAllText();
System.out.println(extractedText);The output is as follows:
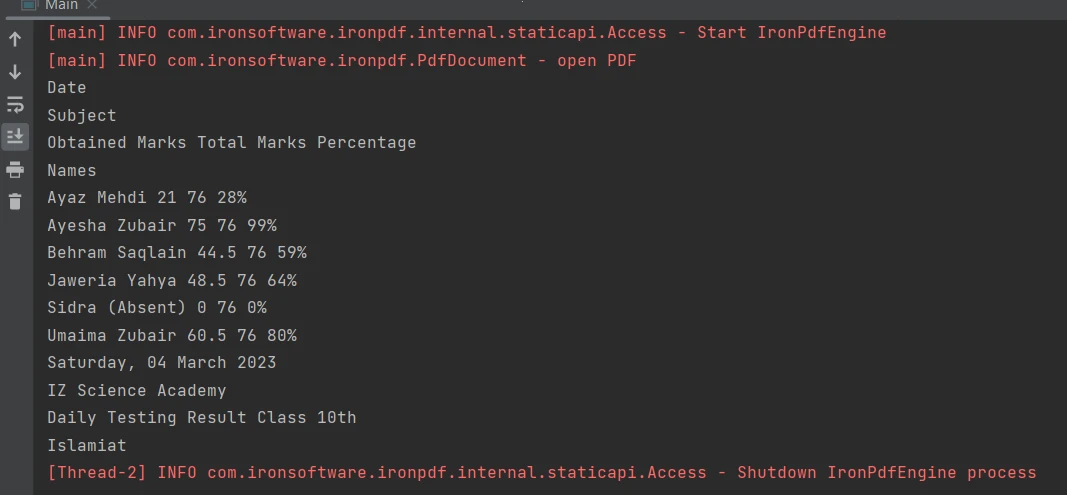 Output
Output
Conclusion
This article demonstrated how to parse an existing PDF document or create a new PDF parser file from a URL to extract data from it in Java using IronPDF. After opening the file, it can extract tabular data, images, and text from the PDF, and can also add the extracted text to a text file for later use.
For more detailed information on how to work with PDF files programmatically in Java, please visit these PDF file creation examples.
The IronPDF for Java library is free for development purposes with a free trial available. However, for commercial use it can be licensed through Iron Software, starting at $999.
Frequently Asked Questions
How do I create a PDF parser in Java?
To create a PDF parser in Java, you can use the IronPDF library. Start by downloading and installing IronPDF, then load your PDF document using the fromFile method. You can extract text and images using the extractAllText and extractAllImages methods respectively.
Can IronPDF be used with Java 8+?
Yes, IronPDF is compatible with Java 8 and higher, as well as Scala and Kotlin. It supports multiple platforms including Windows, Linux, and Cloud environments.
What are the key steps to parsing PDFs using IronPDF in Java?
Key steps include setting up a Maven project, adding the IronPDF dependency, loading a PDF document with fromFile, extracting text using extractAllText, and extracting images using extractAllImages.
How can I convert a URL to a PDF in Java?
You can convert a URL to a PDF in Java using IronPDF's renderUrlAsPdf method. This allows you to render web pages as PDF documents efficiently.
Is IronPDF suitable for cloud-based Java applications?
Yes, IronPDF is designed to be versatile and supports cloud-based environments, making it suitable for developing Java applications that require PDF functionalities in the cloud.
How do I manage dependencies for a Java PDF parsing project?
For managing dependencies in a Java project, you can use Maven. Add the IronPDF library to your project's pom.xml file to include it as a dependency.
What licensing options are available for IronPDF?
IronPDF offers a free trial for development purposes. However, for commercial use, a license is required. This ensures access to all features and priority support.

















