
JavaでPDFを解析する方法(開発者チュートリアル)
この記事では、IronPDFライブラリを使用して効率的にJavaでPDFパーサを作成します。
IronPDF - Java PDF ライブラリ
IronPDF Java 向けは、PDFドキュメントの作成、読み取り、操作を容易かつ正確に行うことができるJava PDFライブラリです。 これは、IronPDF for .NETの成功を基に構築されており、さまざまなプラットフォームで効率的に機能します。 IronPDF for Java は、高速でパフォーマンスが最適化されたIronPdfEngineを利用します。
IronPDFを使用すると、PDFファイルからテキストや画像を抽出することができ、さらにHTML文字列、ファイル、URL、画像などのさまざまなソースからPDFを作成することも可能です。 さらに、新しいコンテンツを簡単に追加したり、IronPDFで署名を挿入したり、PDFドキュメントにメタデータを埋め込むことができます。 IronPDFは、Java 8+、Scala、およびKotlinに特化して設計されており、Windows、Linux、クラウドプラットフォームと互換性があります。
JavaでPDFファイルを解析する方法
- PDFファイルを解析するため for Javaライブラリをダウンロードする。
- 既存のPDF文書を`fromFile`メソッドを使って読み込みます。
- `extractAllText`メソッドを使って、解析されたPDFからすべてのテキストを抽出します。
- URLからPDFをレンダリングするには、`renderUrlAsPdf`メソッドを使用してください。
- `extractAllImages`メソッドを使って、解析されたPDFから画像を抽出します。
JavaプログラムでIronPDFを使用してPDFファイルパーサを作成する
前提条件
JavaでPDF解析プロジェクトを作成するには、次のツールが必要です:
- Java IDE: JavaをサポートするIDEであればどれでも使用できます。開発には複数 Java 向け IDEが利用可能です。 ここでは、このチュートリアルではIntelliJ IDEを使用します。 NetBeans、Eclipseなども使用できます。
- Maven プロジェクト: Maven は依存関係マネージャーであり、Java プロジェクトを制御できます。 Java用のMavenはMaven公式サイトからダウンロードできます。 IntelliJ Java IDEにはMavenに対する組み込みサポートがあります。
-
IronPDF - IronPDF for Javaをダウンロードしてインストールするには複数の方法があります。
-
Mavenプロジェクトの
pom.xmlファイルにIronPDF の依存関係を追加します。<dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>[LATEST_VERSION]</version> </dependency><dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>[LATEST_VERSION]</version> </dependency>XML - 最新のIronPDFパッケージを探すにはMavenリポジトリサイトを訪問します。
- Iron Softwareの公式ダウンロードページから直接ダウンロードします。
- 単純なJavaアプリケーションでJARファイルを使用してIronPDFを手動でインストールします。
-
-
Slf4j-Simple:既存のドキュメントにコンテンツをスタンプするには、この依存関係も必要です。 IntelliJ のMaven依存関係マネージャーを使用して追加することも、 Maven Web サイトから直接ダウンロードすることもできます。次の依存関係を
pom.xmlファイルに追加してください。<dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-simple</artifactId> <version>2.0.5</version> </dependency><dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-simple</artifactId> <version>2.0.5</version> </dependency>XML
必要なインポートの追加
すべての必要条件がインストールされたら、最初のステップはPDFドキュメントを操作するために必要なIronPDFパッケージをインポートすることです。 Main.java ファイルの先頭に以下のコードを追加してください。
import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;ライセンスキー
IronPDFで利用可能な一部のメソッドは、使用するためにライセンスが必要です。 ライセンスを購入するか、無料トライアルでIronPDFを無料でお試しいただけます。 キーを次のように設定することができます。
License.setLicenseKey("YOUR-KEY");License.setLicenseKey("YOUR-KEY");ステップ1:既存のPDFドキュメントを解析する
既存のドキュメントを解析してコンテンツを抽出するために、 PdfDocumentクラスが使用されます。 その静的メソッドfromFile は、Java プログラムで特定のパスにある特定のファイル名の PDF ファイルを解析するために使用されます。 コードは次のようになります:
PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("sample.pdf"));PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("sample.pdf"));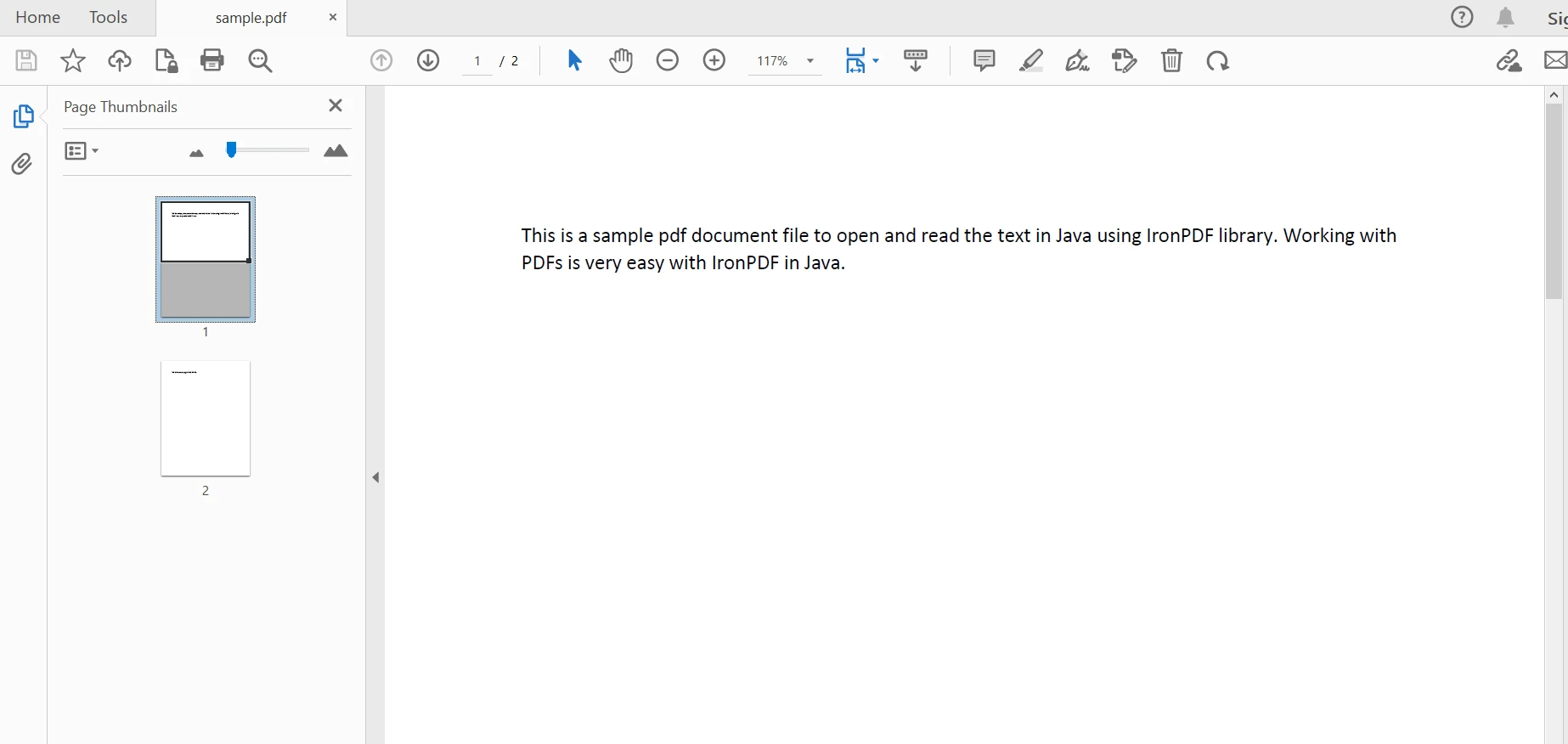 解析されたドキュメント
解析されたドキュメント
ステップ2:解析されたPDFファイルからテキストデータを抽出する
IronPDF for Javaは、PDFドキュメントからテキストを抽出するための簡単な方法を提供しています。 PDFファイルからテキストデータを抽出するための次のコードスニペットは以下の通りです。
String extractedText = parsedDocument.extractAllText();String extractedText = parsedDocument.extractAllText();上記のコードは以下の出力を生成します:
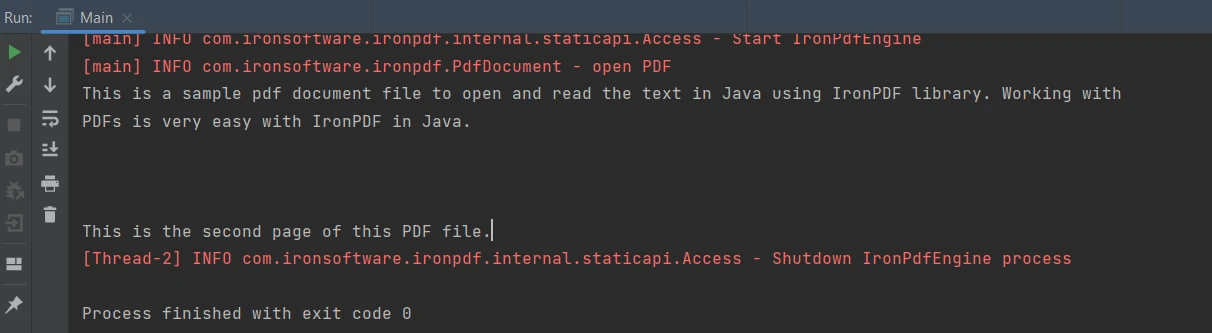 出力
出力
ステップ3:URLまたはHTML文字列からテキストデータを抽出する
IronPDF for Javaの機能は既存のPDFに限定されず、新しいファイルを作成して内容を抽出することもできます。 ここでは、このチュートリアルではURLからPDFファイルを作成し、それからコンテンツを抽出します。 このタスクを達成する方法を示す以下の例があります:
public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
String extractedText = parsedDocument.extractAllText();
System.out.println("Text Extracted from URL:\n" + extractedText);
}
}public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
String extractedText = parsedDocument.extractAllText();
System.out.println("Text Extracted from URL:\n" + extractedText);
}
}出力は以下の通りです。
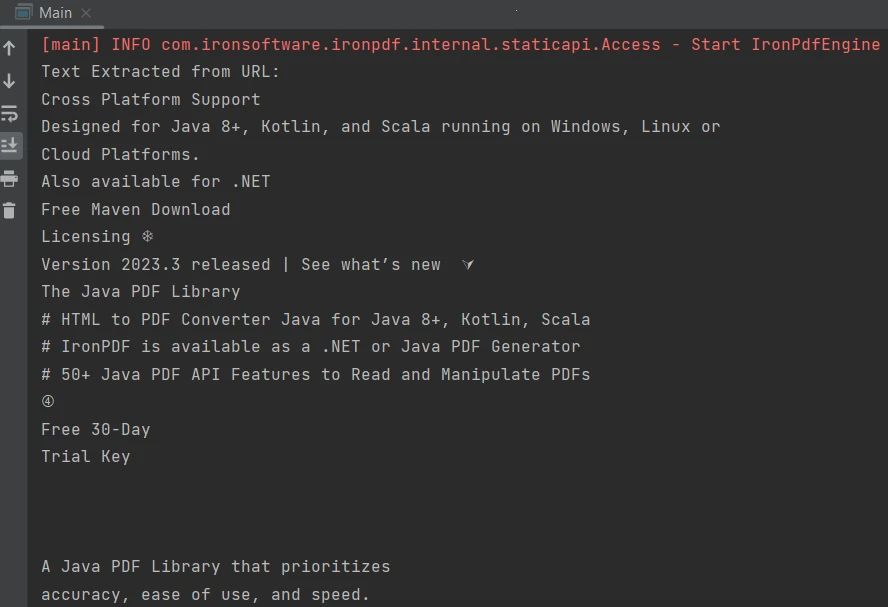 出力
出力
ステップ4:解析されたPDFドキュメントから画像を抽出する
IronPDFは解析されたドキュメントからすべての画像を抽出するための簡単なオプションも提供しています。 ここでは、前の例を使用して、PDFファイルからどのように簡単に画像が抽出されるかを見てみます。
import com.ironsoftware.ironpdf.*;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
try {
List<BufferedImage> images = parsedDocument.extractAllImages();
System.out.println("Number of images extracted from the website: " + images.size());
int i = 0;
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("assets/extracted_" + ++i + ".png")));
}
} catch (Exception exception) {
System.out.println("Failed to extract images from the website");
exception.printStackTrace();
}
}
}import com.ironsoftware.ironpdf.*;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
try {
List<BufferedImage> images = parsedDocument.extractAllImages();
System.out.println("Number of images extracted from the website: " + images.size());
int i = 0;
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("assets/extracted_" + ++i + ".png")));
}
} catch (Exception exception) {
System.out.println("Failed to extract images from the website");
exception.printStackTrace();
}
}
}[extractAllImages](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllImages() ) メソッドは、BufferedImages のリストを返します。 各 BufferedImage は、ImageIO.write メソッドを使用して、PNG 画像として場所に保存できます。 解析されたPDFファイルには34枚の画像があり、すべての画像が完璧に抽出されます。
 抽出された画像
抽出された画像
ステップ5:PDFファイル内のテーブルからデータを抽出する
PDFファイル内の表形式の境界からコンテンツを抽出するには[、extractAllText メソッド](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllText())を使用した1行のコードだけで簡単にできます。 PDFファイルのテーブルからテキストを抽出する方法を示す以下のコードスニペットがあります:
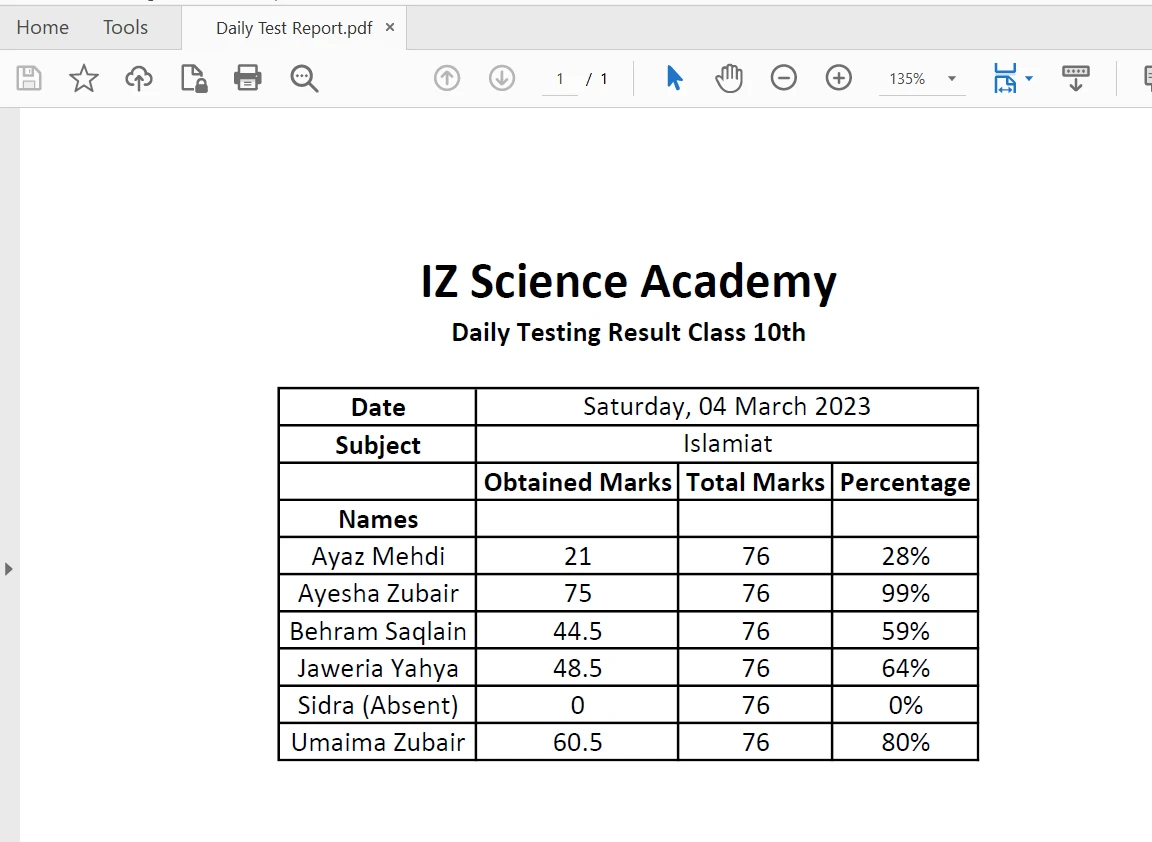 PDF内のテーブル
PDF内のテーブル
PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("table.pdf"));
String extractedText = parsedDocument.extractAllText();
System.out.println(extractedText);PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("table.pdf"));
String extractedText = parsedDocument.extractAllText();
System.out.println(extractedText);出力は以下の通りです。
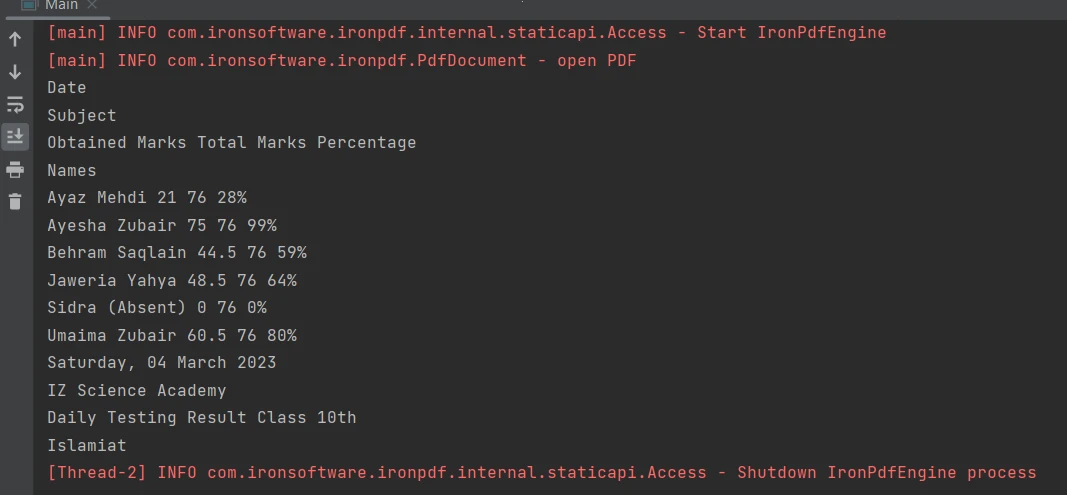 出力
出力
結論
この記事では、JavaでIronPDFを使用して既存のPDFドキュメントを解析する方法や、URLから新しいPDFパーサファイルを作成してデータを抽出する方法を示しました。 ファイルを開いた後、PDFから表形式のデータ、画像、およびテキストを抽出でき、抽出されたテキストをテキストファイルに追加して後で使用することもできます。
Javaでプログラム的にPDFファイルを操作する方法の詳細情報については、これらのPDFファイル作成例を参照してください。
IronPDF for Javaライブラリは、無料トライアルが利用可能な開発目的のために無料です。 ただし、商用利用の場合は、 IronSoftware からライセンスを取得できます。ライセンス番号は $999 です。
よくある質問
JavaでPDFパーサーを作成するにはどうすればよいですか?
JavaでPDFパーサーを作成するには、IronPDFライブラリを使用できます。IronPDFをダウンロードしてインストールし、fromFileメソッドを使用してPDFドキュメントをロードすることから始めてください。extractAllTextおよびextractAllImagesメソッドを使用してテキストと画像を抽出できます。
IronPDFはJava 8+と一緒に使用できますか?
はい、IronPDFはJava 8以上、Scala、Kotlinとも互換性があります。Windows、Linux、クラウド環境など、複数のプラットフォームをサポートしています。
JavaでIronPDFを使用してPDFを解析するための主要な手順は何ですか?
主なステップには、Mavenプロジェクトの設定、IronPDF依存関係の追加、fromFileでのPDFドキュメントのロード、extractAllTextを使用したテキストの抽出、extractAllImagesを使用した画像の抽出が含まれます。
JavaでURLをPDFに変換するにはどうすればよいですか?
IronPDFのrenderUrlAsPdfメソッドを使用してJavaでURLをPDFに変換できます。これにより、ウェブページをPDFドキュメントとして効率的にレンダリングできます。
IronPDFはクラウドベース for Javaアプリケーションに適していますか?
はい、IronPDFは汎用性があり、クラウドベースの環境をサポートしているため、クラウド内でPDF機能を必要とするJavaアプリケーションの開発に適しています。
Java PDF解析プロジェクトの依存関係を管理するにはどうすればよいですか?
Javaプロジェクトの依存関係を管理するためにMavenを使用できます。プロジェクトのpom.xmlファイルにIronPDFライブラリを追加して依存関係として含めます。
IronPDFのライセンスオプションはどのようになっていますか?
IronPDFは開発目的のために無料トライアルを提供しています。ただし、商業目的で使用する場合はライセンスが必要です。これにより、すべての機能へのアクセスと優先サポートが確保されます。

















