
如何在 Java 中解析 PDF(開發人員教程)
本文將採用高效率的方法,使用IronPDF程式庫在 Java 中建立一個 PDF 解析器。
IronPDF - Java PDF 庫
IronPDF 適用於 Java是一個 Java PDF 函式庫,它可以輕鬆且準確地建立、讀取和操作 PDF 文件。 它是基於IronPDF for .NET的成功經驗所建構而成,並在不同的平台上提供高效的功能。 IronPDF for Java 利用了IronPdfEngine ,它速度很快,並且針對效能進行了最佳化。
使用IronPDF,您可以從 PDF 文件中提取文字和圖像,它還支援從各種來源建立 PDF,包括 HTML 字串、文件、URL 和圖像。 此外,您還可以使用IronPDF輕鬆新增內容、插入簽名,並將元資料嵌入 PDF 文件中。 IronPDF專為 Java 8+、Scala 和 Kotlin 設計,並相容於 Windows、Linux 和雲端平台。
如何在Java中解析PDF文件
- 下載用於解析 PDF 檔案的 Java 程式庫
- 使用
fromFile方法載入現有 PDF 文檔 - 使用
extractAllText方法從解析後的 PDF 中提取所有文字。 - 使用
renderUrlAsPdf方法從 URL 渲染 PDF。 - 使用
extractAllImages方法從解析後的 PDF 中提取圖像
使用 Java 程式中的IronPDF建立 PDF 檔案解析器
先決條件
要在Java中建立一個PDF解析項目,您需要以下工具:
- Java IDE:您可以使用任何支援 Java 的 IDE。目前有多種 Java IDE 可用於開發。 本教程將使用IntelliJ IDE 。 您可以使用 NetBeans、Eclipse 等工具。
- Maven專案: Maven是依賴管理器,可以控制 Java 專案。 可從Maven官方網站下載Maven 適用於 Java。 IntelliJ Java IDE 內建了對Maven的支援。
-
IronPDF - 您可以透過多種方式下載並安裝適用於 Java 的IronPDF 。
-
在Maven專案的
pom.xml檔案中新增IronPDF依賴項。<dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>[LATEST_VERSION]</version> </dependency><dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>[LATEST_VERSION]</version> </dependency>XML - 造訪Maven儲存庫網站,取得最新的 Java 版IronPDF軟體包。
- 可直接從Iron Software官方下載頁面下載。
- 在您的簡單 Java 應用程式中使用 JAR 檔案手動安裝IronPDF 。
-
-
Slf4j-Simple:此依賴項也是將內容新增至現有文件所必需的。 可以使用 IntelliJ 中的Maven依賴管理器添加,也可以直接從Maven網站下載。將以下依賴項新增至
pom.xml檔案:<dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-simple</artifactId> <version>2.0.5</version> </dependency><dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-simple</artifactId> <version>2.0.5</version> </dependency>XML
新增必要的導入
所有必備條件安裝完畢後,第一步是匯入必要的IronPDF軟體包以處理 PDF 文件。 在 Main.java 檔案頂部新增以下程式碼:
import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;許可證密鑰
IronPDF中的某些功能需要許可證才能使用。 您可以購買許可證,也可以免費試用IronPDF 。 您可以如下設定密鑰:
License.setLicenseKey("YOUR-KEY");License.setLicenseKey("YOUR-KEY");步驟 1:解析現有 PDF 文檔
要解析現有文件以提取內容,可以使用PdfDocument類。 它的靜態方法[(fromFile](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#fromFile(java.nio.file.Path) )用於在 Java 程式中從特定路徑和特定檔案名稱解析 PDF 檔案。 程式碼如下:
PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("sample.pdf"));PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("sample.pdf"));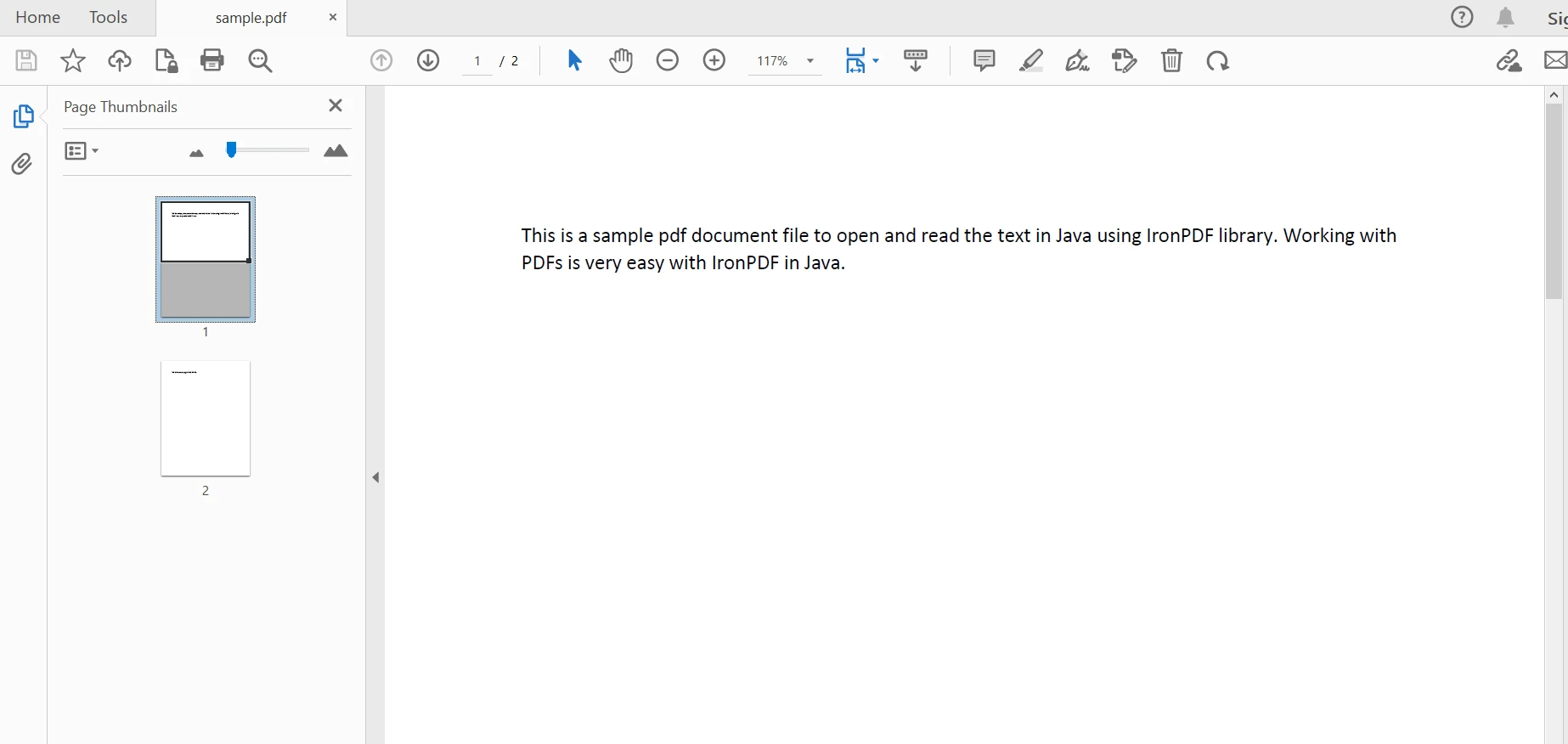 已解析文檔
已解析文檔
步驟 2:從解析後的 PDF 檔案中提取文字數據
IronPDF for Java 提供了一種從 PDF 文件中提取文字的簡單方法。 下面的程式碼片段用於從PDF文件中提取文字資料:
String extractedText = parsedDocument.extractAllText();String extractedText = parsedDocument.extractAllText();上述程式碼產生如下輸出:
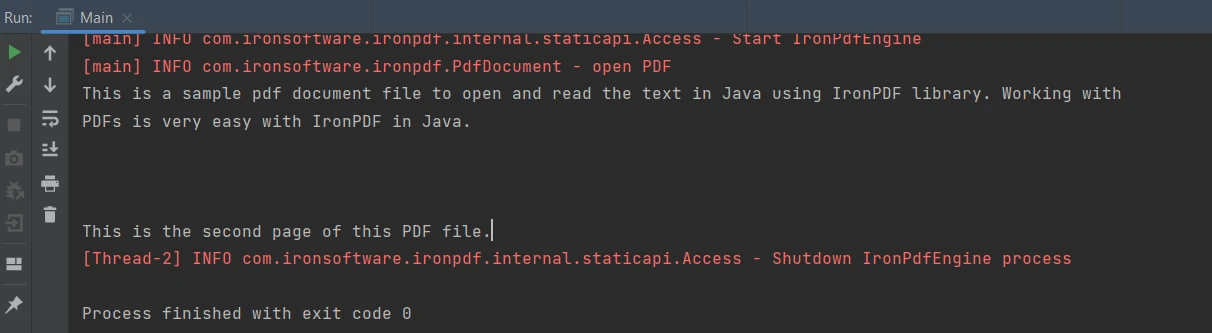 輸出
輸出
步驟 3:從 URL 或 HTML 字串中提取文字數據
IronPDF for Java 的功能不僅限於現有的 PDF 文件,它還可以建立和解析新文件以提取內容。 本教學將從URL 建立 PDF 檔案並從中提取內容。 以下範例展示如何完成此任務:
public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
String extractedText = parsedDocument.extractAllText();
System.out.println("Text Extracted from URL:\n" + extractedText);
}
}public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
String extractedText = parsedDocument.extractAllText();
System.out.println("Text Extracted from URL:\n" + extractedText);
}
}輸出結果如下:
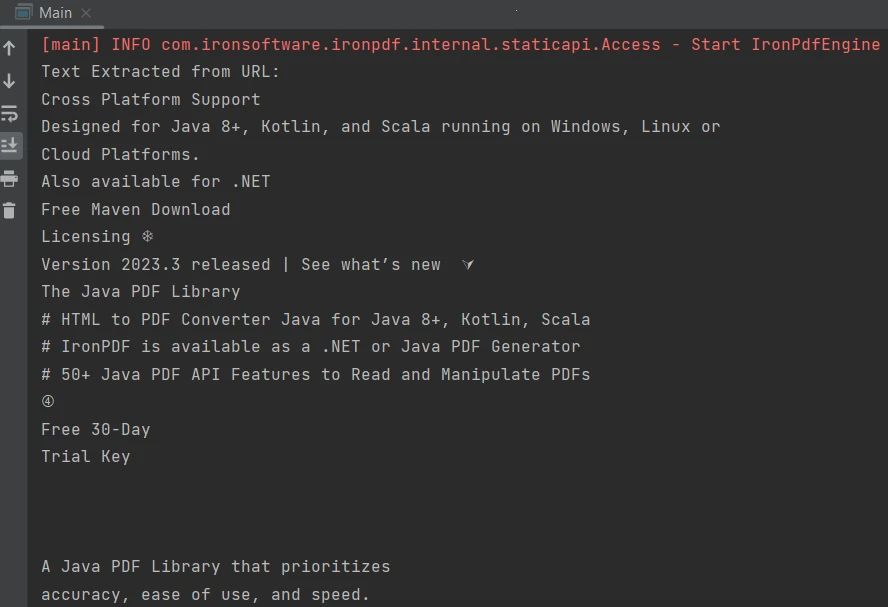 輸出
輸出
步驟 4:從解析後的 PDF 文件中擷取影像
IronPDF也提供了一個簡單的選項,可以從解析後的文件中提取所有影像。 本教學將以前面的範例為例,展示如何輕鬆地從 PDF 檔案中擷取影像。
import com.ironsoftware.ironpdf.*;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
try {
List<BufferedImage> images = parsedDocument.extractAllImages();
System.out.println("Number of images extracted from the website: " + images.size());
int i = 0;
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("assets/extracted_" + ++i + ".png")));
}
} catch (Exception exception) {
System.out.println("Failed to extract images from the website");
exception.printStackTrace();
}
}
}import com.ironsoftware.ironpdf.*;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
try {
List<BufferedImage> images = parsedDocument.extractAllImages();
System.out.println("Number of images extracted from the website: " + images.size());
int i = 0;
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("assets/extracted_" + ++i + ".png")));
}
} catch (Exception exception) {
System.out.println("Failed to extract images from the website");
exception.printStackTrace();
}
}
}[extractAllImages](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllImages() ) 方法傳回一個 BufferedImages 清單。 然後可以使用 BufferedImage 方法將每個 ImageIO.write 映像儲存為 PNG 映像。 解析後的 PDF 檔案中有 34 張圖片,每張圖片都已完美擷取。
 提取的圖像
提取的圖像
步驟 5:從 PDF 文件中的表格提取數據
使用[extractAllText 方法](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllText(),只需一行程式碼即可輕鬆從 PDF 文件中的表格邊界提取內容)。 以下程式碼片段示範如何從 PDF 檔案中的表格中擷取文字:
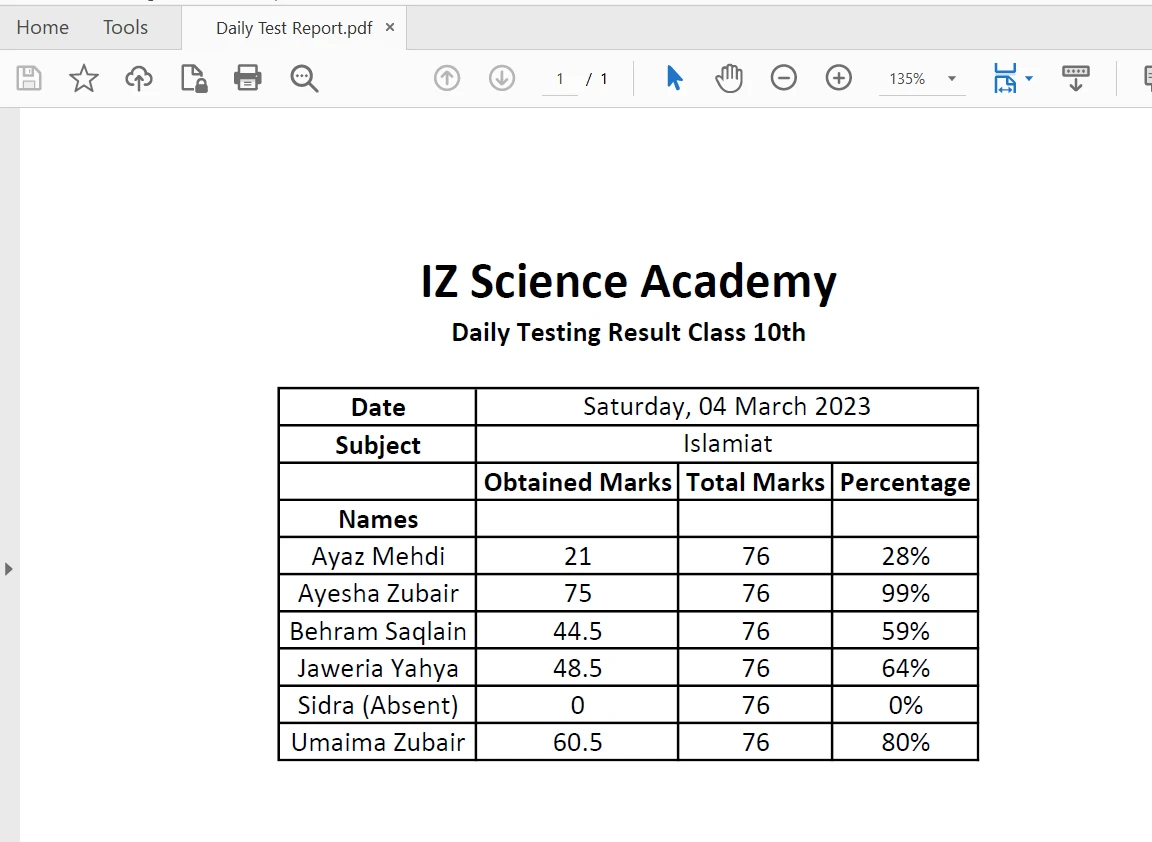 PDF 表格
PDF 表格
PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("table.pdf"));
String extractedText = parsedDocument.extractAllText();
System.out.println(extractedText);PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("table.pdf"));
String extractedText = parsedDocument.extractAllText();
System.out.println(extractedText);輸出結果如下:
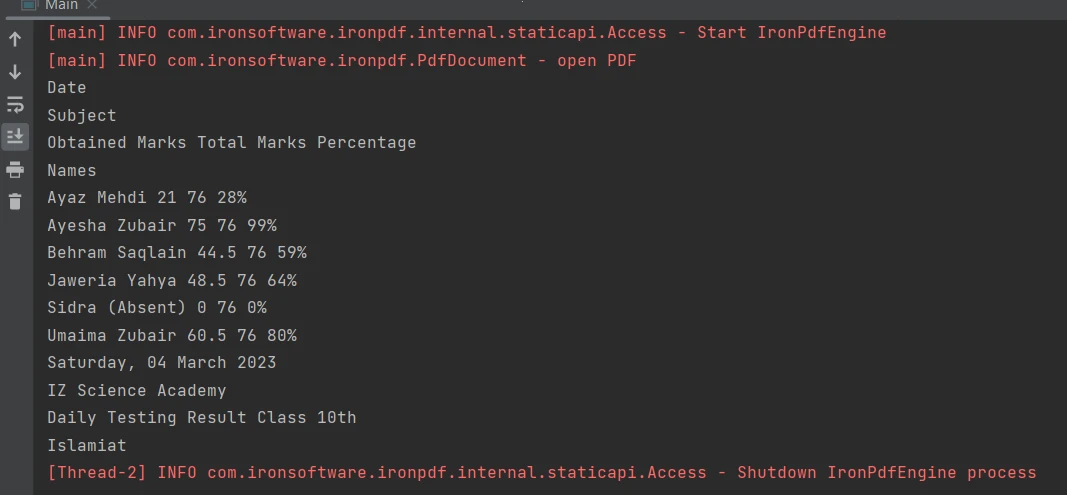 輸出
輸出
結論
本文示範如何使用IronPDF在 Java 中解析現有的 PDF 文件或從URL 建立新的 PDF 解析器文件,以從中提取資料。 打開文件後,它可以從 PDF 中提取表格數據、圖像和文本,還可以將提取的文本添加到文本文件中以供以後使用。
有關如何在 Java 中以程式設計方式處理 PDF 文件的更多詳細信息,請訪問這些PDF 文件創建範例。
IronPDF for Java 程式庫可免費用於開發目的,並提供免費試用版。 但是,商業用途可以透過 IronSoftware 獲得許可,價格從 $999 起。
常見問題
如何在Java中創建PDF解析器?
要在Java中創建PDF解析器,您可以使用IronPDF庫。首先下載並安裝IronPDF,然後使用fromFile方法加載您的PDF文檔。您可以分別使用extractAllText和extractAllImages方法提取文本和圖像。
IronPDF可以與Java 8+一起使用嗎?
可以,IronPDF兼容Java 8及以上版本,以及Scala和Kotlin。它支持多個平台,包括Windows, Linux和雲環境。
在Java中使用IronPDF解析PDF的關鍵步驟是什麼?
關鍵步驟包括設置Maven項目,添加IronPDF依賴項,用fromFile加載PDF文檔,使用extractAllText提取文本,並使用extractAllImages提取圖像。
如何在Java中將URL轉換為PDF?
您可以使用IronPDF的renderUrlAsPdf方法在Java中將URL轉換為PDF。這允許您將網頁高效渲染為PDF文檔。
IronPDF 是否適合雲端 Java 應用?
可以,IronPDF設計得非常多功能,支持基於雲的環境,非常適合開發需要在雲中進行PDF功能的Java應用程序。
如何管理Java PDF解析項目的依賴項?
對於管理Java項目的依賴項,您可以使用Maven。將IronPDF庫添加到您的項目的pom.xml文件中以作為依賴項。
IronPDF 的許可選擇有哪些?
IronPDF為開發目的提供免費試用版。不過,用於商業用途則需要授權。這確保獲得所有功能和優先支持。

















