
Java'da PDF'leri Analiz Etme Yöntemi (Geliştirici Eğitimi)
Bu makale, Java'da IronPDF Kütüphanesini kullanarak verimli bir yaklaşımla bir PDF ayrıştırıcı oluşturacaktır.
IronPDF - Java PDF Kütüphanesi
IronPDF for Java, PDF belgelerini kolaylık ve doğrulukla oluşturmayı, okumayı ve manipüle etmeyi sağlayan bir Java PDF kütüphanesidir. Bu, IronPDF for .NET'in başarısı üzerine inşa edilmiştir ve farklı platformlarda verimli işlevsellik sağlar. IronPDF for Java, hızlı ve performans için optimize edilmiş IronPdfEngine kullanır.
IronPDF ile PDF dosyalarından metin ve görüntüleri çıkarabilirsiniz ve ayrıca HTML dizgileri, dosyalar, URL'ler ve görüntüler de dahil olmak üzere çeşitli kaynaklardan PDF oluşturma imkanı sağlar. Bunun yanı sıra, yeni içerik kolayca ekleyebilir, IronPDF ile imzalar ekleyebilir ve PDF belgelerine meta veriler ekleyebilirsiniz. IronPDF, özellikle Java 8+, Scala ve Kotlin için tasarlanmıştır ve Windows, Linux ve Bulut platformları ile uyumludur.
Java'da bir PDF Dosyasını Nasıl Ayrıştırırsınız?
- Bir PDF dosyasını ayrıştırmak için Java kütüphanesini indirin
fromFileyöntemi kullanılarak mevcut bir PDF belgesi yükleyinextractAllTextyöntemiyle ayrıştırılmış PDF'den tüm metni çıkarın- Bir URL'den PDF oluşturmak için
renderUrlAsPdfyöntemini kullanın extractAllImagesyöntemiyle ayrıştırılmış PDF'den görüntüleri çıkarın
Java Programında IronPDF Kullanarak PDF Dosya Ayrıştırıcı Oluşturun
Ön Koşullar
Java'da bir PDF Ayrıştırma projesi yapmak için aşağıdaki araçlara ihtiyacınız olacak:
- Java IDE: Herhangi bir Java destekli IDE'yi kullanabilirsiniz. Geliştirme için birçok Java IDE'si mevcuttur. Bu ders için IntelliJ IDE kullanılacaktır. NetBeans, Eclipse gibi IDE'ler kullanabilirsiniz.
- Maven Projesi: Maven, bir bağımlılık yöneticisidir ve Java projesi üzerinde kontrol sağlar. Java için Maven, Maven resmi web sitesinden indirilebilir. IntelliJ Java IDE, Maven için dahili destek sunar.
-
IronPDF - IronPDF for Java çeşitli yollarla indirilebilir ve yüklenebilir.
-
Bir Maven projesinde
pom.xmldosyasına IronPDF bağımlılığı eklemek.<dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>[LATEST_VERSION]</version> </dependency><dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>[LATEST_VERSION]</version> </dependency>XML - Java için en son IronPDF paketini Maven deposu web sitesini ziyaret ederek bulabilirsiniz.
- Iron Software resmi indirme sayfasından doğrudan indirme.
- Basit Java Uygulamanızda JAR dosyasını kullanarak IronPDF'i manuel olarak yükleyin.
-
-
Slf4j-Simple: Bu bağımlılık, mevcut bir belgeye içerik damgalamak için de gereklidir. IntelliJ'deki Maven bağımlılık yöneticisi kullanılarak eklenebilir veya Maven web sitesinden doğrudan indirilebilir.
pom.xmldosyasına aşağıdaki bağımlılığı ekleyin:<dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-simple</artifactId> <version>2.0.5</version> </dependency><dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-simple</artifactId> <version>2.0.5</version> </dependency>XML
Gerekli İthalatları Eklemek
Tüm ön koşullar yüklendikten sonra, ilk adım bir PDF belgesiyle çalışmak için gerekli IronPDF paketlerini ithal etmektir. Main.java dosyasının üstüne aşağıdaki kodu ekleyin:
import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;Lisans Anahtarı
IronPDF'de mevcut olan bazı yöntemler kullanım için lisans gerektirir. Bir lisans satın alabilir veya ücretsiz bir deneme süresinde IronPDF'i ücretsiz olarak deneyebilirsiniz. Anahtarı aşağıdaki şekilde ayarlayabilirsiniz:
License.setLicenseKey("YOUR-KEY");License.setLicenseKey("YOUR-KEY");Adım 1: Mevcut bir PDF belgesini ayrıştırın
İçerik çıkarma işlemi için mevcut bir belgeyi ayrıştırmak için PdfDocument sınıfı kullanılır. Belirli bir yol ve dosya adıyla PDF dosyasını bir Java programında ayrıştırmak için statik [fromFile](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#fromFile(java.nio.file.Path) yöntemi kullanılır. Kod şu şekildedir:
PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("sample.pdf"));PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("sample.pdf")); Ayrıştırılmış belge
Ayrıştırılmış belge
Adım 2: Ayrıştırılmış PDF dosyasından Metin Verilerini Çıkarın
IronPDF for Java, PDF belgelerinden metin çıkartma için kolay bir yöntem sağlar. Aşağıdaki kod parçası PDF dosyasından metin verilerini çıkarmak içindir:
String extractedText = parsedDocument.extractAllText();String extractedText = parsedDocument.extractAllText();Yukarıdaki kod aşağıdaki çıktıyı üretir:
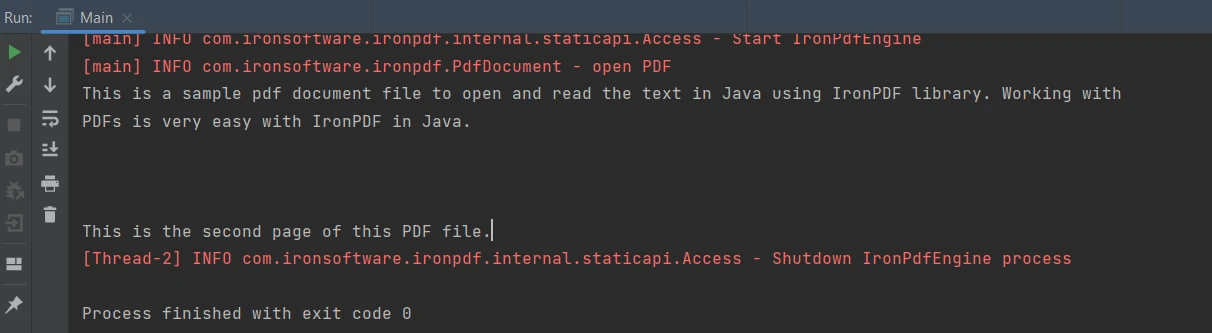 Çıktı
Çıktı
Adım 3: URL'den veya HTML Dizgisinden Metin Verilerini Çıkarın
IronPDF for Java'nın yetenekleri yalnızca mevcut PDF'lerle sınırlı değildir, aynı zamanda içerik çıkarmak için yeni bir dosya da oluşturabilir ve ayrıştırabilir. Burada, bu ders bir URL'den bir PDF dosyası oluşturacak ve içerik çıkartacak. Aşağıdaki örnek bu görevin nasıl gerçekleştirileceğini göstermektedir:
public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
String extractedText = parsedDocument.extractAllText();
System.out.println("Text Extracted from URL:\n" + extractedText);
}
}public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
String extractedText = parsedDocument.extractAllText();
System.out.println("Text Extracted from URL:\n" + extractedText);
}
}Çıktı şu şekildedir:
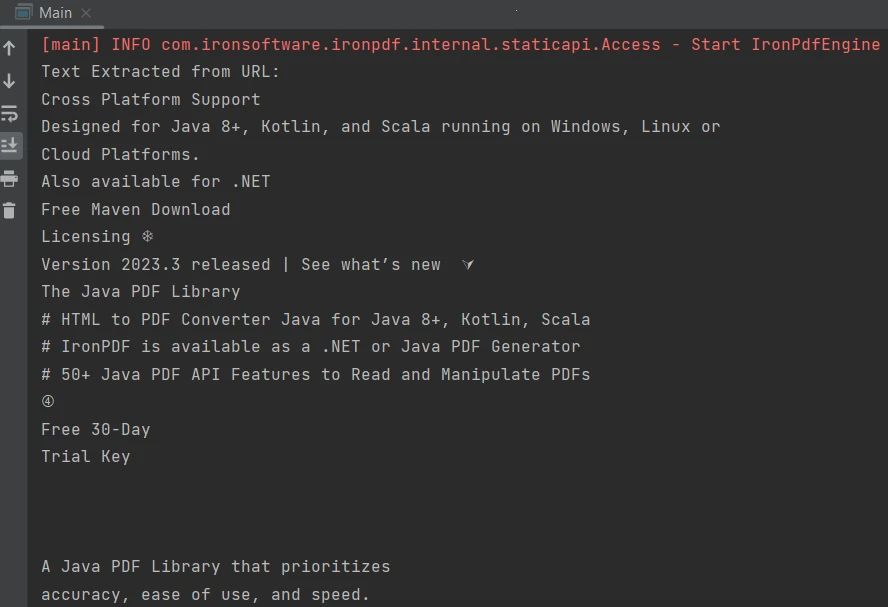 Çıktı
Çıktı
Adım 4: Ayrıştırılmış PDF Belgesinden Görüntüleri Çıkarın
IronPDF ayrıca ayrıştırılmış belgelerden tüm görüntüleri çıkarmak için kolay bir seçenek sunar. Burada, bu eğitimde önceki örnek kullanılacak ve PDF dosyalarından görüntülerin ne kadar kolayca çıkarıldığını gösterecektir.
import com.ironsoftware.ironpdf.*;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
try {
List<BufferedImage> images = parsedDocument.extractAllImages();
System.out.println("Number of images extracted from the website: " + images.size());
int i = 0;
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("assets/extracted_" + ++i + ".png")));
}
} catch (Exception exception) {
System.out.println("Failed to extract images from the website");
exception.printStackTrace();
}
}
}import com.ironsoftware.ironpdf.*;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
try {
List<BufferedImage> images = parsedDocument.extractAllImages();
System.out.println("Number of images extracted from the website: " + images.size());
int i = 0;
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("assets/extracted_" + ++i + ".png")));
}
} catch (Exception exception) {
System.out.println("Failed to extract images from the website");
exception.printStackTrace();
}
}
}[extractAllImages](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllImages() yöntemi, BufferedImages listesini döndürür. Her bir BufferedImage, ImageIO.write yöntemi kullanılarak bir konum üzerine PNG görüntüleri olarak depolanabilir. Ayrıştırılmış PDF dosyasında 34 görüntü vardır ve her bir görüntü mükemmel bir şekilde çıkarılmıştır.
 Çıkarılmış görüntüler
Çıkarılmış görüntüler
Adım 5: PDF Dosyalarındaki Tablolardan Veri Çıkarın
PDF dosyasındaki tablo sınırlarından içerik çıkarmak, [extractAllText yöntemi](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllText() ile tek bir satır kod kullanılarak kolaylaştırılmıştır. Aşağıdaki kod parçası, bir PDF dosyasındaki tablodan metin çıkarmanın nasıl yapılacağını göstermektedir:
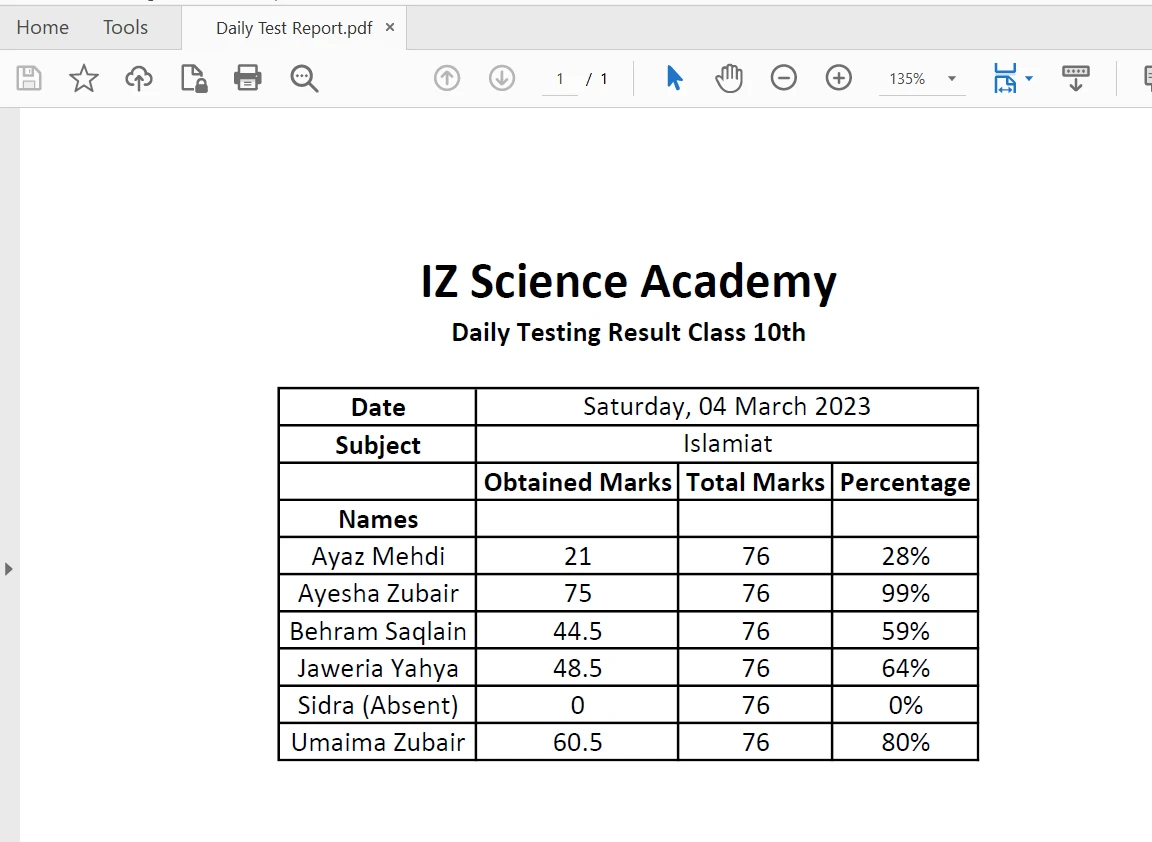 PDF'de Tablo
PDF'de Tablo
PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("table.pdf"));
String extractedText = parsedDocument.extractAllText();
System.out.println(extractedText);PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("table.pdf"));
String extractedText = parsedDocument.extractAllText();
System.out.println(extractedText);Çıktı şu şekildedir:
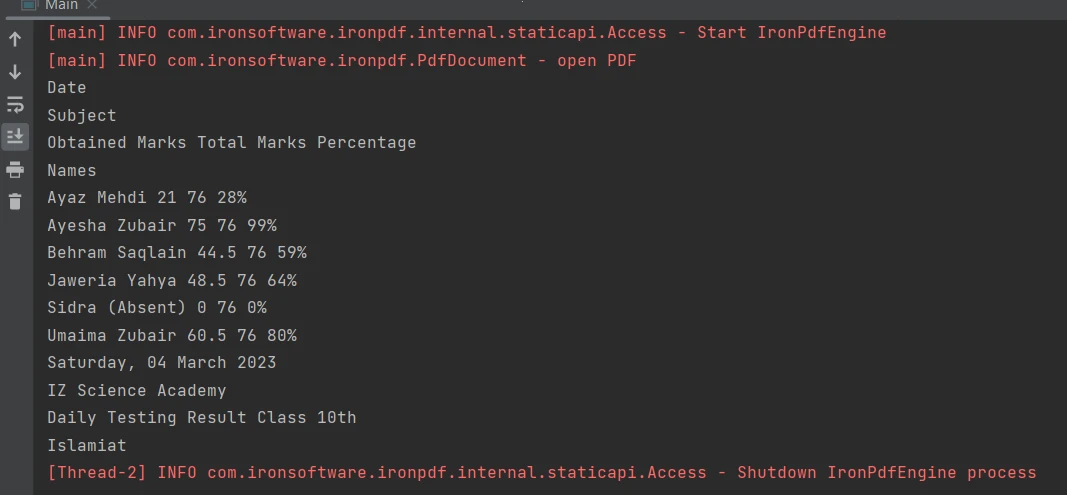 Çıktı
Çıktı
Sonuç
Bu makale, Java'da IronPDF kullanarak mevcut bir PDF belgesini nasıl ayrıştıracağınızı veya bir URL'den yeni bir PDF ayrıştırıcı dosyası oluşturup verileri nasıl çıkaracağınızı göstermiştir. Dosyayı açtıktan sonra, tablolardan veri, görüntüler ve metin çıkartabilir ve çıkarılan metni daha sonra kullanmak üzere bir metin dosyasına ekleyebilir.
Java'da programlı olarak PDF dosyaları ile çalışma hakkında daha fazla ayrıntılı bilgi için, lütfen bu PDF dosya oluşturma örneklerini ziyaret edin.
IronPDF for Java kütüphanesi, geliştirme amaçlı olarak ücretsiz deneme sürümü ile ücretsizdir. Ancak, ticari kullanım için, Iron Software aracılığıyla lisanlanabilir ve $999 ile başlamaktadır.
Sıkça Sorulan Sorular
Java'da bir PDF ayrıştırıcısı nasıl oluşturabilirim?
Java'da bir PDF ayrıştırıcısı oluşturmak için IronPDF kütüphanesini kullanabilirsiniz. IronPDF'yi indirip yükleyerek başlayın, ardından PDF belgenizi fromFile yöntemini kullanarak yükleyin. Metin ve görüntüleri sırasıyla extractAllText ve extractAllImages yöntemlerini kullanarak çıkarabilirsiniz.
IronPDF, Java 8+ ile kullanılabilir mi?
Evet, IronPDF Java 8 ve üstü sürümlerle uyumludur ve Scala ve Kotlin'i de destekler. Windows, Linux ve Bulut ortamları dahil olmak üzere birçok platformu desteklemektedir.
Java'da IronPDF kullanarak PDF'leri ayrıştırmanın temel adımları nelerdir?
Temel adımlar arasında bir Maven projesi kurma, IronPDF bağımlılığını ekleme, bir PDF belgesi yüklemek için fromFile kullanma, metni çıkarmak için extractAllText ve görüntüleri çıkarmak için extractAllImages kullanma yer alır.
Java'da bir URL'yi PDF'ye nasıl dönüştürebilirim?
IronPDF'nin renderUrlAsPdf yöntemini kullanarak Java'da bir URL'yi PDF'ye dönüştürebilirsiniz. Bu, web sayfalarını PDF belgeleri olarak verimli bir şekilde oluşturmanızı sağlar.
IronPDF, bulut tabanlı Java uygulamaları için uygun mudur?
Evet, IronPDF, bulut tabanlı ortamları da destekleyen çok yönlü bir tasarıma sahiptir, bu da bulutta PDF işlevselliği gerektiren Java uygulamaları geliştirirken uygun hale getirir.
Bir Java PDF ayrıştırma projesi için bağımlılıkları nasıl yönetirim?
Java projesinde bağımlılıkları yönetmek için Maven'i kullanabilirsiniz. IronPDF kütüphanesini projenizin pom.xml dosyasına ekleyerek bağımlılık olarak dahil edin.
IronPDF için hangi lisans seçenekleri mevcuttur?
IronPDF, geliştirme amacıyla ücretsiz bir deneme sürümü sunar. Ancak, ticari kullanım için lisans gereklidir. Bu, tüm özelliklere erişimi ve öncelikli desteği sağlar.

















