
Java에서 PDF를 파싱하는 방법 (개발자 튜토리얼)
이 글에서는 IronPDF 라이브러리를 사용하여 효율적인 방식으로 자바로 PDF 파서를 만드는 방법을 설명합니다.
IronPDF - 자바 PDF 라이브러리
IronPDF Java용 는 PDF 문서를 쉽고 정확하게 생성, 읽기 및 조작할 수 있도록 해주는 Java PDF 라이브러리입니다. 이 제품은 .NET 용 IronPDF 의 성공을 기반으로 구축되었으며 다양한 플랫폼에서 효율적인 기능을 제공합니다. IronPDF for Java는 IronPdfEngine을 사용하여 빠르고 성능이 최적화되어 있습니다.
IronPDF 사용하면 PDF 파일에서 텍스트와 이미지를 추출 할 수 있을 뿐 아니라 HTML 문자열, 파일, URL 및 이미지를 포함한 다양한 소스에서 PDF를 생성 할 수도 있습니다. 또한 IronPDF 를 사용하면 새 콘텐츠를 쉽게 추가하고, 서명을 삽입하고 , 메타데이터를 PDF 문서에 포함 할 수 있습니다. IronPDF 는 Java 8+, Scala 및 Kotlin에 맞춰 특별히 설계되었으며 Windows, Linux 및 클라우드 플랫폼과 호환됩니다.
Java로 PDF 파일을 파싱하는 방법
- PDF 파일을 파싱하는 Java 라이브러리를 다운로드하세요.
fromFile메서드를 사용하여 기존 PDF 문서를 불러옵니다.extractAllText메서드를 사용하여 파싱된 PDF에서 모든 텍스트를 추출합니다.- URL에서 PDF를 렌더링하려면
renderUrlAsPdf메서드를 사용하십시오. extractAllImages메서드를 사용하여 파싱된 PDF에서 이미지를 추출합니다.
Java 프로그램을 사용하여 IronPDF 이용한 PDF 파일 파서 생성하기
필수 조건
Java로 PDF 파싱 프로젝트를 만들려면 다음과 같은 도구가 필요합니다.
- Java IDE: Java를 지원하는 모든 IDE를 사용할 수 있습니다. 개발에 사용할 수 있는 Java IDE는 여러 가지가 있습니다. 이 튜토리얼에서는 IntelliJ IDE를 사용합니다. NetBeans, Eclipse 등을 사용할 수 있습니다.
- Maven 프로젝트: Maven은 의존성 관리자이며 자바 프로젝트를 관리할 수 있도록 해줍니다. Java용 Maven은 Maven 공식 웹사이트 에서 다운로드할 수 있습니다. IntelliJ Java IDE는 Maven을 기본적으로 지원합니다.
-
IronPDF - IronPDF for Java는 여러 가지 방법으로 다운로드 및 설치할 수 있습니다.
-
Maven 프로젝트의
pom.xml파일에 IronPDF 종속성을 추가합니다.<dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>[LATEST_VERSION]</version> </dependency><dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>[LATEST_VERSION]</version> </dependency>XML - Java용 최신 IronPDF 패키지를 다운로드하려면 Maven 저장소 웹사이트를 방문하세요.
- Iron Software 공식 다운로드 페이지 에서 직접 다운로드할 수 있습니다.
- 간단한 Java 애플리케이션에서 JAR 파일을 사용하여 IronPDF 수동으로 설치하십시오.
-
-
Slf4j-Simple: 이 종속성은 기존 문서에 콘텐츠를 추가하는 데에도 필요합니다. IntelliJ의 Maven 종속성 관리자를 사용하여 추가하거나, Maven 웹사이트에서 직접 다운로드할 수 있습니다. 다음 종속성을
pom.xml파일에 추가합니다:<dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-simple</artifactId> <version>2.0.5</version> </dependency><dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-simple</artifactId> <version>2.0.5</version> </dependency>XML
필요한 임포트 추가
필수 구성 요소가 모두 설치되면 첫 번째 단계는 PDF 문서를 작업하는 데 필요한 IronPDF 패키지를 가져오는 것입니다. 다음 코드를 Main.java 파일 상단에 추가하세요:
import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;라이선스 키
IronPDF 에서 사용할 수 있는 일부 메서드는 사용하려면 라이선스가 필요합니다. 라이선스를 구매하거나 무료 체험판을 통해 IronPDF 사용해 볼 수 있습니다. 다음과 같이 키를 설정할 수 있습니다.
License.setLicenseKey("YOUR-KEY");License.setLicenseKey("YOUR-KEY");1단계: 기존 PDF 문서 분석
기존 문서를 파싱하여 내용을 추출하기 위해 PdfDocument 클래스를 사용합니다. Java 프로그램에서 특정 경로와 파일 이름으로 PDF 파일을 파싱하기 위해 정적 [fromFile](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#fromFile(java.nio.file.Path) 메서드를 사용합니다. 코드는 다음과 같습니다.
PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("sample.pdf"));PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("sample.pdf"));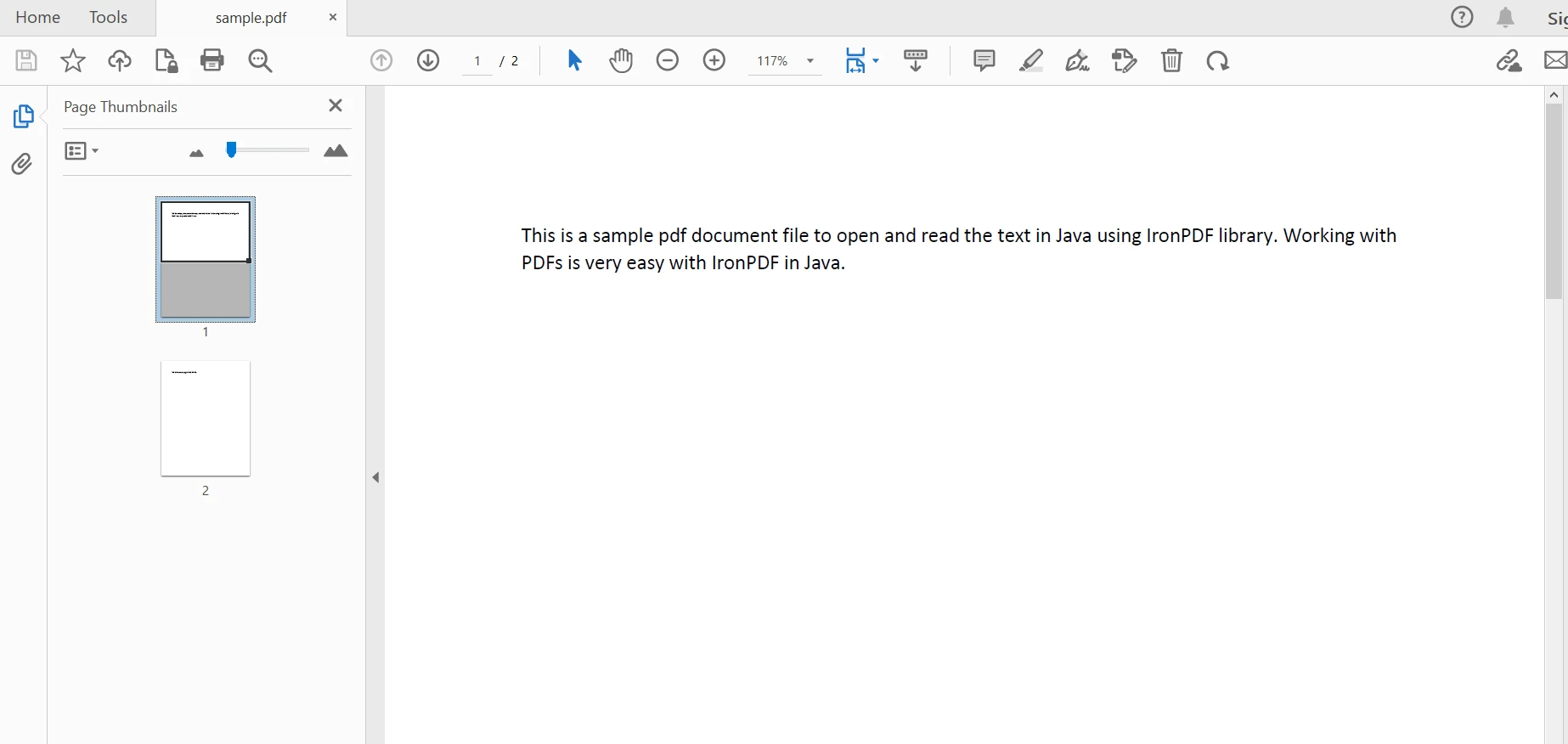 파싱된 문서
파싱된 문서
2단계: 파싱된 PDF 파일에서 텍스트 데이터 추출
IronPDF for Java는 PDF 문서에서 텍스트를 추출하는 간편한 방법을 제공합니다. 다음은 PDF 파일에서 텍스트 데이터를 추출하는 코드 조각입니다.
String extractedText = parsedDocument.extractAllText();String extractedText = parsedDocument.extractAllText();위 코드는 아래와 같은 출력을 생성합니다.
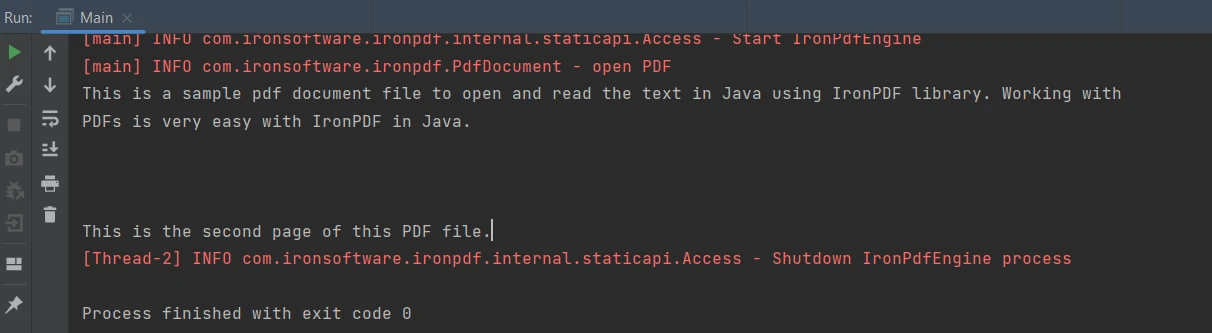 산출
산출
3단계: URL 또는 HTML 문자열에서 텍스트 데이터 추출
IronPDF for Java는 기존 PDF 파일에만 국한되지 않고, 새로운 파일을 생성하고 구문 분석하여 콘텐츠를 추출할 수도 있습니다. 이 튜토리얼에서는 URL에서 PDF 파일을 생성하고 해당 파일에서 콘텐츠를 추출하는 방법을 설명합니다 . 다음 예시는 이 작업을 수행하는 방법을 보여줍니다.
public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
String extractedText = parsedDocument.extractAllText();
System.out.println("Text Extracted from URL:\n" + extractedText);
}
}public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
String extractedText = parsedDocument.extractAllText();
System.out.println("Text Extracted from URL:\n" + extractedText);
}
}출력 결과는 다음과 같습니다.
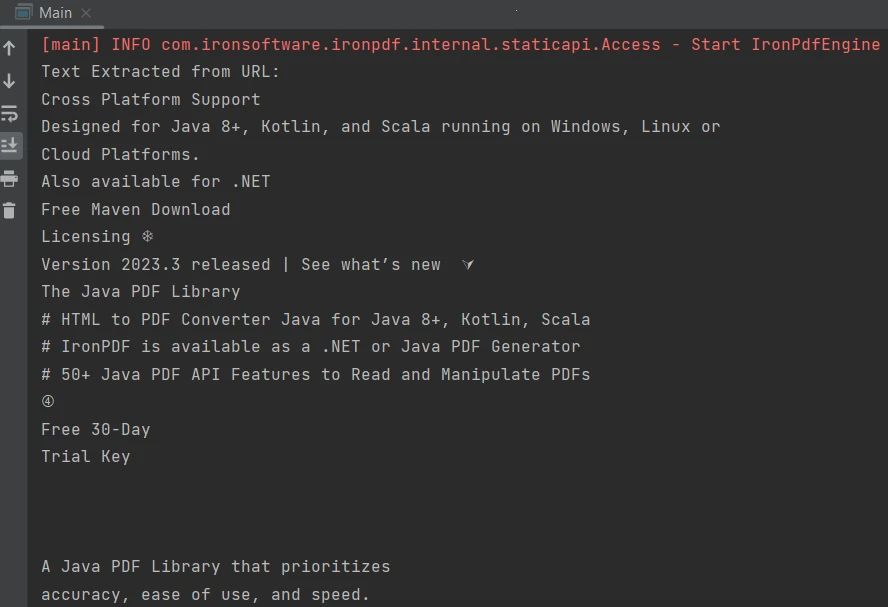 산출
산출
4단계: 파싱된 PDF 문서에서 이미지 추출
IronPDF 분석된 문서에서 모든 이미지를 쉽게 추출 할 수 있는 옵션도 제공합니다. 이 튜토리얼에서는 이전 예제를 사용하여 PDF 파일에서 이미지를 얼마나 쉽게 추출할 수 있는지 살펴보겠습니다.
import com.ironsoftware.ironpdf.*;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
try {
List<BufferedImage> images = parsedDocument.extractAllImages();
System.out.println("Number of images extracted from the website: " + images.size());
int i = 0;
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("assets/extracted_" + ++i + ".png")));
}
} catch (Exception exception) {
System.out.println("Failed to extract images from the website");
exception.printStackTrace();
}
}
}import com.ironsoftware.ironpdf.*;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
try {
List<BufferedImage> images = parsedDocument.extractAllImages();
System.out.println("Number of images extracted from the website: " + images.size());
int i = 0;
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("assets/extracted_" + ++i + ".png")));
}
} catch (Exception exception) {
System.out.println("Failed to extract images from the website");
exception.printStackTrace();
}
}
}extractAllImages 메서드는 BufferedImages 목록을 반환합니다. 그 후, 각각의 BufferedImage를 ImageIO.write 메서드를 사용하여 PNG 이미지로 특정 위치에 저장할 수 있습니다. 분석된 PDF 파일에는 34개의 이미지가 있으며 모든 이미지가 완벽하게 추출되었습니다.
 추출된 이미지
추출된 이미지
5단계: PDF 파일의 표에서 데이터 추출
PDF 파일의 테이블 경계 내에서 내용을 추출하는 것은 extractAllText 메서드 만으로 한 줄의 코드로 매우 쉽게 수행할 수 있습니다. 다음 코드 조각은 PDF 파일의 표에서 텍스트를 추출하는 방법을 보여줍니다.
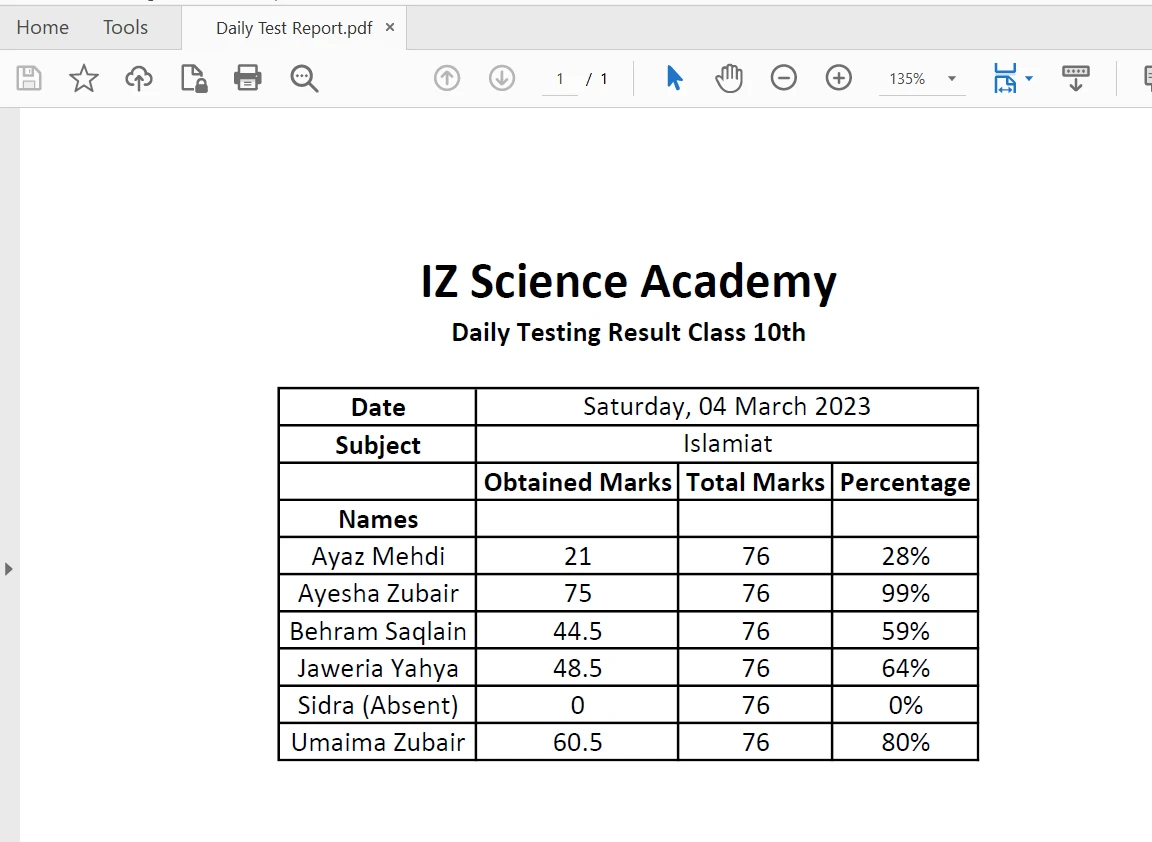 PDF의 표
PDF의 표
PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("table.pdf"));
String extractedText = parsedDocument.extractAllText();
System.out.println(extractedText);PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("table.pdf"));
String extractedText = parsedDocument.extractAllText();
System.out.println(extractedText);출력 결과는 다음과 같습니다.
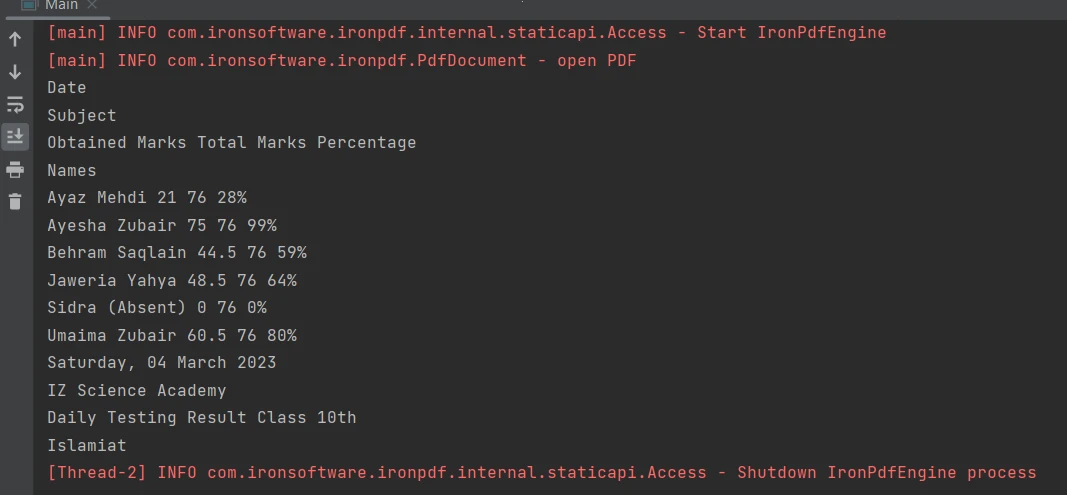 산출
산출
결론
이 글에서는 IronPDF 사용하여 Java 환경에서 기존 PDF 문서를 구문 분석하거나 URL에서 새 PDF 파서 파일을 생성하여 데이터를 추출하는 방법을 설명했습니다. 파일을 열면 PDF에서 표 형식 데이터, 이미지 및 텍스트를 추출할 수 있으며, 추출된 텍스트를 나중에 사용할 수 있도록 텍스트 파일에 추가할 수도 있습니다.
Java에서 PDF 파일을 프로그래밍 방식으로 처리하는 방법에 대한 자세한 내용은 다음 PDF 파일 생성 예제를 참조하십시오.
IronPDF for Java 라이브러리는 개발 목적으로 무료로 사용할 수 있으며 무료 평가판도 제공됩니다 . 그러나 상업적 사용을 위해서는 Iron Software를 통해 라이선스를 구매할 수 있습니다, 시작 가격은 $999입니다.
자주 묻는 질문
자바로 PDF 파서를 어떻게 만들 수 있나요?
Java에서 PDF 파서를 만들려면 IronPDF 라이브러리를 사용할 수 있습니다. 먼저 IronPDF를 다운로드하여 설치한 다음, fromFile 메서드를 사용하여 PDF 문서를 불러오세요. extractAllText 메서드를 사용하면 텍스트가 추출되고, extractAllImages 메서드를 사용하면 이미지가 추출됩니다.
IronPDF는 Java 8 이상 버전에서 사용할 수 있습니까?
네, IronPDF는 Java 8 이상, Scala 및 Kotlin과 호환됩니다. Windows, Linux 및 클라우드 환경을 포함한 다양한 플랫폼을 지원합니다.
Java에서 IronPDF를 사용하여 PDF를 파싱하는 주요 단계는 무엇입니까?
주요 단계에는 Maven 프로젝트 설정, IronPDF 종속성 추가, fromFile 사용하여 PDF 문서 불러오기, extractAllText 사용하여 텍스트 추출, extractAllImages 사용하여 이미지 추출이 포함됩니다.
자바에서 URL을 PDF로 변환하는 방법은 무엇인가요?
IronPDF의 renderUrlAsPdf 메서드를 사용하면 Java에서 URL을 PDF로 변환할 수 있습니다. 이를 통해 웹 페이지를 PDF 문서로 효율적으로 렌더링할 수 있습니다.
IronPDF는 클라우드 기반 Java 애플리케이션에 적합한가요?
네, IronPDF는 다용도로 설계되었으며 클라우드 기반 환경을 지원하므로 클라우드 환경에서 PDF 기능을 필요로 하는 Java 애플리케이션 개발에 적합합니다.
Java PDF 파싱 프로젝트에서 종속성을 어떻게 관리해야 하나요?
Java 프로젝트에서 종속성을 관리하려면 Maven을 사용할 수 있습니다. IronPDF 라이브러리를 프로젝트의 pom.xml 파일에 추가하여 종속성으로 포함시키세요.
IronPDF에 사용할 수 있는 라이선스 옵션은 무엇인가요?
IronPDF는 개발 목적으로 무료 평가판을 제공합니다. 하지만 상업적 용도로 사용하려면 라이선스가 필요합니다. 라이선스를 취득하면 모든 기능을 이용하고 우선적인 지원을 받을 수 있습니다.

















