
Java를 사용하여 PDF에서 데이터를 추출하는 방법
이 튜토리얼에서는 Java용 IronPDF 사용하여 PDF 파일에서 데이터를 추출하는 방법을 보여줍니다. 개발 환경 설정, 라이브러리 가져오기, 입력 파일 읽기, 필요한 데이터 추출 등 모든 과정을 코드 예제와 함께 설명합니다.
2. IronPDF 자바 PDF 라이브러리
IronPDF 는 개발자가 Java 애플리케이션 내에서 IronPDF for Java를 사용하여 PDF 파일을 생성, 편집 및 데이터 추출 할 수 있도록 하는 소프트웨어 라이브러리입니다. 이 프로그램을 사용하면 HTML 문서, 이미지 등을 기반으로 PDF를 생성 할 수 있을 뿐 아니라 여러 PDF 파일을 병합하거나 분할하고 기존 PDF 파일을 조작할 수도 있습니다. IronPDF PDF 파일에 암호 보호 기능을 추가하고 디지털 서명을 삽입하는 등 다양한 기능을 제공하여 PDF를 안전하게 보호할 수 있도록 합니다.
IronPDF for Java는 Iron Software 에서 개발 및 유지 관리합니다. 이 프로그램의 가장 뛰어난 기능 중 하나는 PDF 파일뿐만 아니라 HTML 및 URL에서도 텍스트와 데이터를 추출하는 것입니다.
3. 필수 조건
IronPDF 사용하여 PDF 파일에서 데이터를 추출하려면 다음 전제 조건을 충족해야 합니다.
- Java 설치: 시스템에 Java가 설치되어 있고 환경 변수에 Java 경로가 설정되어 있는지 확인하십시오. 아직 자바를 설치하지 않았다면 자바 웹사이트의 다운로드 페이지를 참조하여 설치 방법을 확인하십시오.
- Java IDE: Eclipse 또는 IntelliJ와 같은 Java IDE가 설치되어 있어야 합니다. 이클립스는 이클립스 다운로드 페이지 에서, 인텔리J는 이 인텔리J 다운로드 페이지 에서 다운로드할 수 있습니다.
- IronPDF 라이브러리: IronPDF 라이브러리를 다운로드하고 프로젝트의 종속성으로 추가하세요. IronPDF 설치 지침 페이지를 방문하여 설치 방법을 확인하십시오.
- Maven 설치: PDF 변환 프로세스를 시작하기 전에 Maven을 설치하고 IDE에 통합해야 합니다. Maven 설치 및 통합에 대한 자세한 내용은 JetBrains의 Maven 설치 튜토리얼을 참조하십시오.
4. Java용 IronPDF 설치
요구 사항을 모두 충족하면 IronPDF for Java 설치는 쉽고 간단합니다. 이 가이드에서는 JetBrains의 IntelliJ IDEA를 사용하여 설치 및 샘플 코드 실행 방법을 설명합니다.
해야 할 일은 다음과 같습니다.
- IntelliJ IDEA 실행: 시스템에서 JetBrains IntelliJ IDEA를 실행합니다.
- Maven 프로젝트 생성: IntelliJ IDEA에서 새 Maven 프로젝트를 생성합니다. 이렇게 하면 Java용 IronPDF 를 설치하기에 적합한 환경이 조성됩니다.
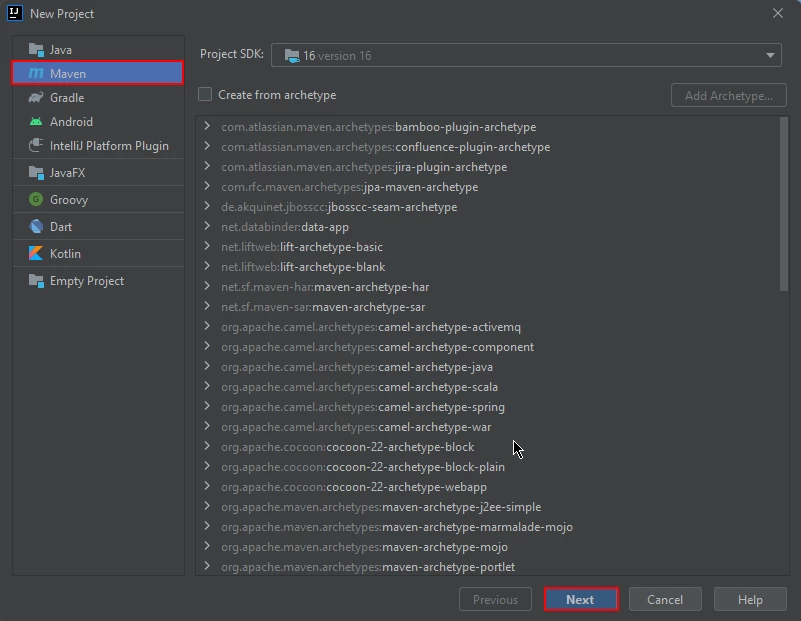 IntelliJ에 새 Maven 프로젝트 생성
IntelliJ에 새 Maven 프로젝트 생성
- 새 창이 나타납니다. 프로젝트 이름을 입력하고 완료를 클릭하세요.
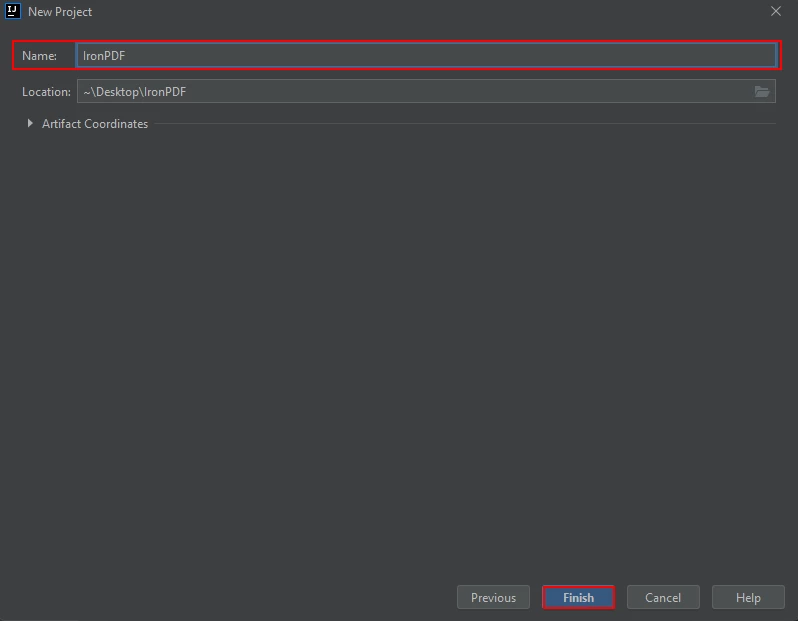 Maven 프로젝트 이름을 지정하고 완료를 클릭합니다.
Maven 프로젝트 이름을 지정하고 완료를 클릭합니다.
- 마침을 클릭하면 pom.xml 파일이 포함된 새 프로젝트가 열립니다. 이 파일은 IronPDF Java Maven 종속성을 추가하는 데 사용됩니다.
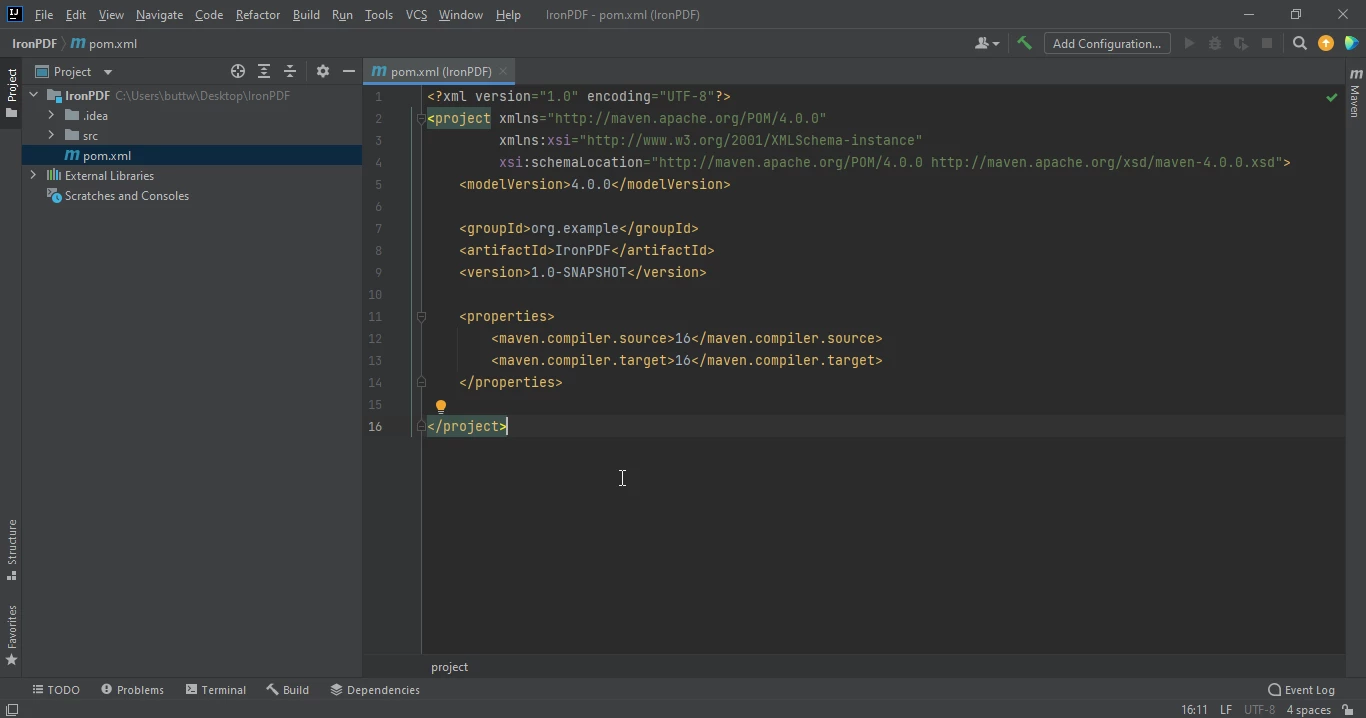 pom.xml 파일
pom.xml 파일
pom.xml 파일에 다음 종속성을 추가하거나 Sonatype Central의 IronPDF 라이브러리 페이지에서 JAR 파일을 다운로드할 수 있습니다.
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>1.0.0</version>
</dependency><dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>1.0.0</version>
</dependency>pom.xml 파일에 종속성을 놓으면, 파일의 오른쪽 상단 모서리에 작은 아이콘이 나타납니다.
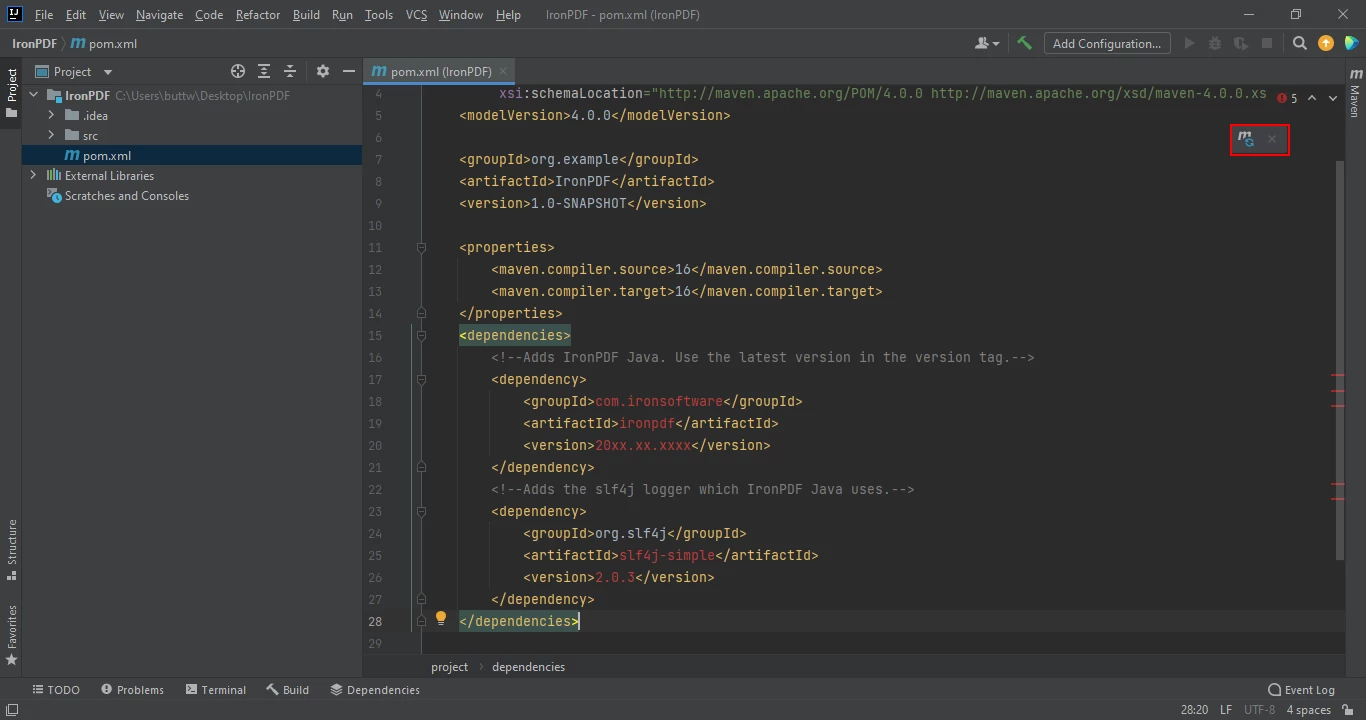 플로팅 아이콘을 클릭하면 Maven 종속성이 자동으로 설치됩니다.
플로팅 아이콘을 클릭하면 Maven 종속성이 자동으로 설치됩니다.
이 버튼을 클릭하여 IronPDF for Java의 Maven 종속성을 설치하세요. 인터넷 연결 속도에 따라 몇 분 정도 소요될 수 있습니다.
5. 데이터 추출
IronPDF 는 PDF 문서를 생성, 편집 및 데이터 추출하기 위한 Java 라이브러리입니다. 이 도구는 PDF 파일, URL 및 표에서 텍스트를 추출하는 간단한 API를 제공합니다.
5.1. PDF 문서에서 데이터 추출
IronPDF for Java를 사용하면 PDF 문서에서 텍스트 데이터를 쉽게 추출할 수 있습니다. 다음은 PDF 파일에서 데이터를 추출하는 예제 코드입니다.
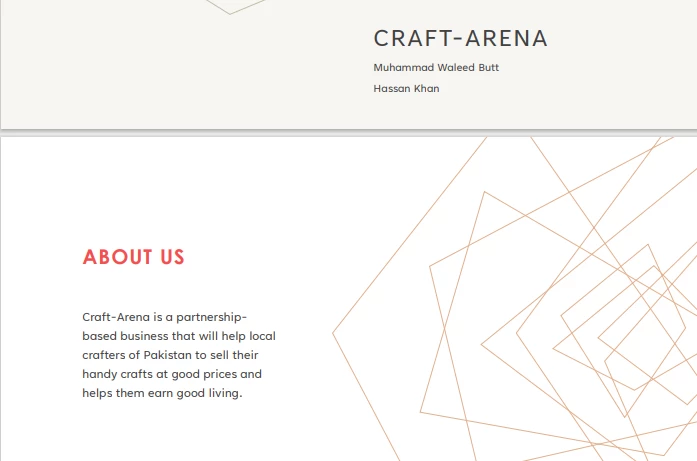 PDF 입력
PDF 입력
// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
import java.nio.file.Paths;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from the specified file
PdfDocument pdf = PdfDocument.fromFile(Paths.get("business plan.pdf"));
// Extract all text from the PDF document
String text = pdf.extractAllText();
// Print the extracted text to the console
System.out.println("Text extracted from the PDF: " + text);
}
}// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
import java.nio.file.Paths;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from the specified file
PdfDocument pdf = PdfDocument.fromFile(Paths.get("business plan.pdf"));
// Extract all text from the PDF document
String text = pdf.extractAllText();
// Print the extracted text to the console
System.out.println("Text extracted from the PDF: " + text);
}
}소스 코드는 아래와 같은 출력을 생성합니다.
> Text extracted from the PDF:
>
> CRAFT-ARENA
>
> Muhammad Waleed Butt
>
> Hassan Khan
>
> ABOUT US
>
> Craft-Arena is a partnership based business that will help local crafters of Pakistan to sell their handicrafts at good prices and helps them earn a good living.5.2. URL에서 데이터 추출
IronPDF for Java는 런타임에 URL을 PDF로 변환하고 PDF에서 텍스트를 추출합니다. 이 예제에서는 URL에서 텍스트를 추출하는 소스 코드를 보여줍니다.
// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException {
// Convert a URL to a PDF and load it into a PdfDocument
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
// Extract all text from the PDF document
String text = pdf.extractAllText();
// Print the extracted text to the console
System.out.println("Text extracted from the URLs: " + text);
}
}// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException {
// Convert a URL to a PDF and load it into a PdfDocument
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
// Extract all text from the PDF document
String text = pdf.extractAllText();
// Print the extracted text to the console
System.out.println("Text extracted from the URLs: " + text);
}
}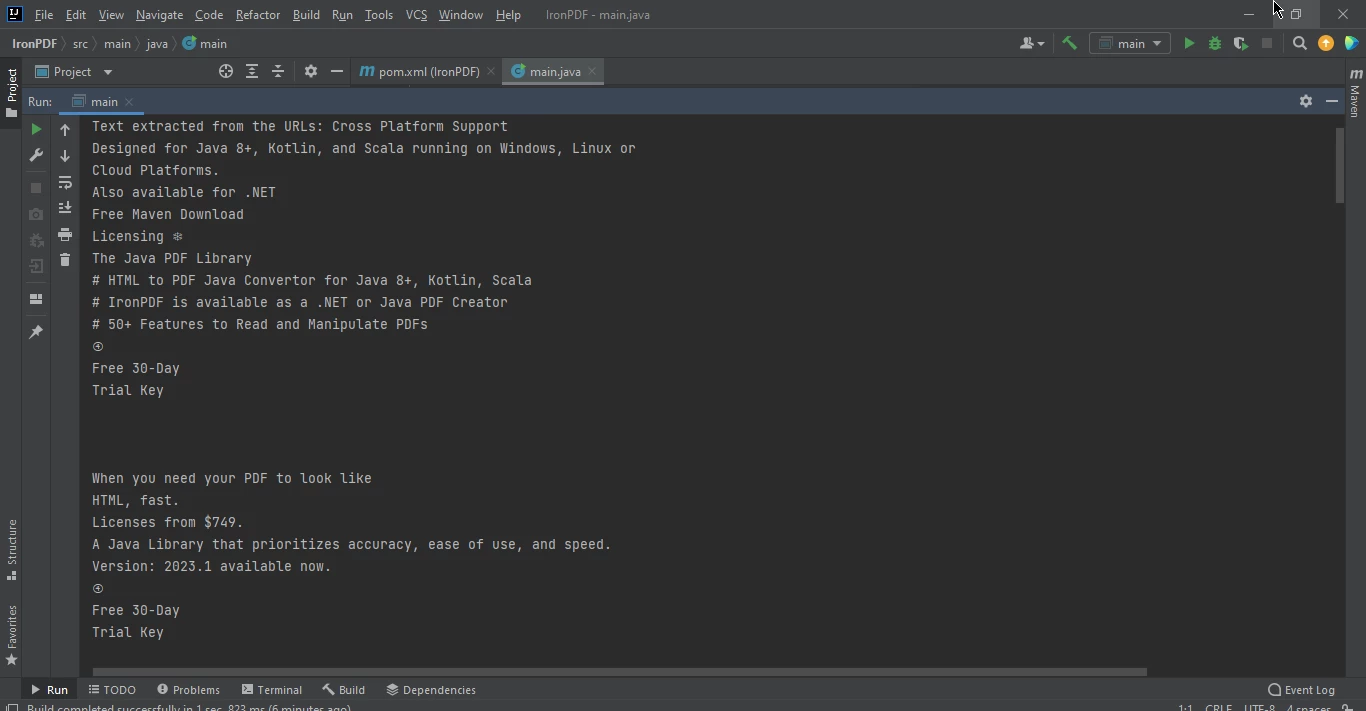 추출된 웹 페이지 데이터
추출된 웹 페이지 데이터
5.3. 테이블 데이터에서 데이터 추출
Java용 IronPDF 사용하여 PDF에서 표 데이터를 추출하는 것은 매우 간단합니다. 표가 포함된 PDF 파일과 아래 코드를 실행하기만 하면 됩니다.
 PDF 테이블 입력 예시
PDF 테이블 입력 예시
// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
import java.nio.file.Paths;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from the specified file
PdfDocument pdf = PdfDocument.fromFile(Paths.get("table.pdf"));
// Extract all text from the PDF document, including table data
String text = pdf.extractAllText();
// Print the extracted table data to the console
System.out.print("Text extracted from the Marked tables: " + text);
}
}// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
import java.nio.file.Paths;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from the specified file
PdfDocument pdf = PdfDocument.fromFile(Paths.get("table.pdf"));
// Extract all text from the PDF document, including table data
String text = pdf.extractAllText();
// Print the extracted table data to the console
System.out.print("Text extracted from the Marked tables: " + text);
}
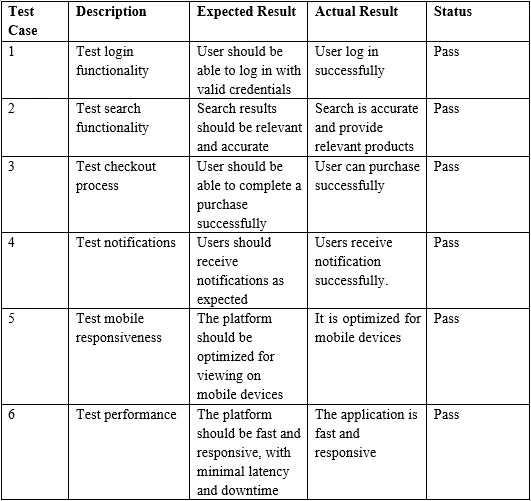
}> Test Case Description Expected Result Actual Result Status
>
> 1 Test login functionality User should be able to log in with valid credentials
>
> User log in successfully Pass
>
> 2 Test search functionality Search results should be relevant and accurate
>
> Search is accurate and provide relevant products Pass
>
> 3 Test checkout process User should be able to complete a purchase successfully
>
> User can purchase successfully Pass6. 결론
결론적으로, 이 튜토리얼에서는 Java용 IronPDF 사용하여 PDF 파일에서 데이터, 특히 표 형식 데이터를 추출하는 방법을 설명했습니다.
더 자세한 내용은 IronPDF 웹사이트의 PDF에서 텍스트 추출 예시 를 참조하십시오.
IronPDF는 상용 라이선스 세부 정보를 가진 라이브러리로, $999에서 시작합니다. 하지만 IronPDF 평가판 라이선스를 사용하여 무료 체험판 으로 실제 사용 환경에서 평가해 볼 수 있습니다.
자주 묻는 질문
Java를 사용하여 PDF에서 텍스트를 추출하는 방법은 무엇인가요?
IronPDF for Java를 사용하면 PdfDocument 클래스로 문서를 불러온 다음 extractAllText 메서드를 활용하여 텍스트를 추출할 수 있습니다.
자바를 이용해 URL에서 데이터를 추출하고 PDF로 변환할 수 있나요?
예, Java용 IronPDF를 사용하면 런타임에 URL을 PDF로 변환하고 PdfDocument 클래스를 사용하여 PDF에서 데이터를 추출할 수 있습니다.
IntelliJ IDEA에서 IronPDF를 설정하는 단계는 무엇입니까?
IntelliJ IDEA에서 IronPDF를 설정하려면 새 Maven 프로젝트를 생성하고 pom.xml 파일에 IronPDF 라이브러리를 추가한 다음 나타나는 플로팅 아이콘을 클릭하여 Maven 종속성을 설치하십시오.
Java에서 IronPDF를 사용하기 위한 필수 조건은 무엇입니까?
필수 조건으로는 Java 설치, Eclipse 또는 IntelliJ와 같은 Java IDE, IronPDF 라이브러리, 그리고 Maven이 IDE에 설치되어 통합되어 있어야 합니다.
Java를 사용하여 PDF에서 표 데이터를 추출하는 방법은 무엇입니까?
IronPDF for Java를 사용하여 PDF에서 테이블 데이터를 추출하려면 PdfDocument 클래스를 사용하여 PDF 문서를 로드하고 extractAllText 메서드를 사용하여 테이블 데이터를 가져옵니다.
Java용 IronPDF를 사용하려면 상업용 라이선스가 필요한가요?
네, IronPDF for Java는 상업용 라이선스가 필요하지만, 평가 목적으로 무료 체험판을 이용할 수 있습니다.
Java에서 IronPDF를 사용하는 방법에 대한 튜토리얼은 어디에서 찾을 수 있나요?
IronPDF for Java 사용에 대한 튜토리얼과 예제는 IronPDF 웹사이트, 특히 예제 및 튜토리얼 섹션에서 찾을 수 있습니다.
IronPDF는 Java 개발자에게 어떤 기능을 제공합니까?
IronPDF for Java는 PDF 파일을 생성, 편집, 병합, 분할 및 조작하는 기능은 물론 암호 보호 및 디지털 서명 추가를 통해 PDF를 보호하는 기능도 제공합니다.
Java를 사용하여 PDF에서 데이터를 추출할 때 발생하는 문제를 어떻게 해결할 수 있을까요?
최신 Java 버전, 호환되는 IDE, IronPDF 라이브러리 등 모든 필수 조건을 충족했는지 확인하십시오. pom.xml 파일에서 Maven 통합 및 라이브러리 종속성이 올바르게 설정되었는지 확인하십시오.

















