
Comment extraire des données d'un PDF en Java
Ce tutoriel vous montrera comment utiliser IronPDF pour Java pour extraire des données d'un fichier PDF. La configuration de l'environnement, l'importation de la bibliothèque, la lecture du fichier d'entrée et l'extraction des données nécessaires sont toutes expliquées avec des exemples de code.
2. Bibliothèque PDF Java IronPDF
IronPDF est une bibliothèque logicielle qui permet aux développeurs de générer, modifier et extraire des données de fichiers PDF avec IronPDF for Java dans leurs applications Java. Il vous permet de créer des PDFs à partir de documents HTML, d'images et bien plus, ainsi que de fusionner plusieurs PDFs, diviser des fichiers PDF et manipuler des PDFs existants. IronPDF offre également la possibilité de sécuriser des PDFs avec des fonctionnalités de protection par mot de passe et d'ajouter des signatures numériques aux PDFs, entre autres fonctionnalités.
IronPDF for Java est développé et maintenu par Iron Software. L'une de ses fonctions les mieux notées est d'extraire du texte et des données de fichiers PDF ainsi que de HTML et d'URL.
3. Prérequis
Pour utiliser IronPDF pour extraire des données de fichiers PDF, vous devez répondre aux prérequis suivants :
- Installation de Java : Assurez-vous que Java est installé sur votre système et que son chemin est défini dans les variables d'environnement. Si vous n'avez pas encore installé Java, consultez cette page de téléchargement sur le site Java pour des instructions.
- IDE Java : Ayez un IDE Java comme Eclipse ou IntelliJ installé. Vous pouvez télécharger Eclipse depuis cette page de téléchargement Eclipse et IntelliJ depuis cette page de téléchargement IntelliJ.
- Bibliothèque IronPDF : Téléchargez et ajoutez la bibliothèque IronPDF en tant que dépendance dans votre projet. Consultez la page des instructions de configuration d'IronPDF pour les instructions d'installation.
- Installation de Maven : Maven doit être installé et intégré à votre IDE avant de commencer le processus de conversion de PDF. Référez-vous à ce tutoriel d'installation de Maven sur JetBrains pour l'installation et l'intégration de Maven.
4. Installation d'IronPDF for Java
L'installation d'IronPDF for Java est simple et facile, à condition que toutes les exigences soient remplies. Ce guide utilisera IntelliJ IDEA de JetBrains pour démontrer l'installation et exécuter un code d'exemple.
Voici ce qu'il faut faire :
- Ouvrez IntelliJ IDEA : Lancez JetBrains IntelliJ IDEA sur votre système.
- Créez un projet Maven : Dans IntelliJ IDEA, créez un nouveau projet Maven. Cela fournira un environnement adéquat pour l'installation d'IronPDF for Java.
 Nouveau projet Maven dans IntelliJ
Nouveau projet Maven dans IntelliJ
- Une nouvelle fenêtre apparaîtra. Entrez le nom du projet et cliquez sur Terminer.
 Nommez le projet Maven et cliquez sur Terminer
Nommez le projet Maven et cliquez sur Terminer
- Un nouveau projet avec un pom.xml s'ouvrira une fois que vous aurez cliqué sur Terminer. Cela sera utilisé pour ajouter les dépendances Maven d'IronPDF for Java.
 Le fichier pom.xml
Le fichier pom.xml
Ajoutez les dépendances suivantes dans le fichier pom.xml ou vous pouvez télécharger le fichier JAR depuis la page de la bibliothèque IronPDF sur Sonatype Central .
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>1.0.0</version>
</dependency><dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>1.0.0</version>
</dependency>Une fois que vous aurez placé les dépendances dans le fichier pom.xml, une petite icône apparaîtra dans le coin supérieur droit du fichier.
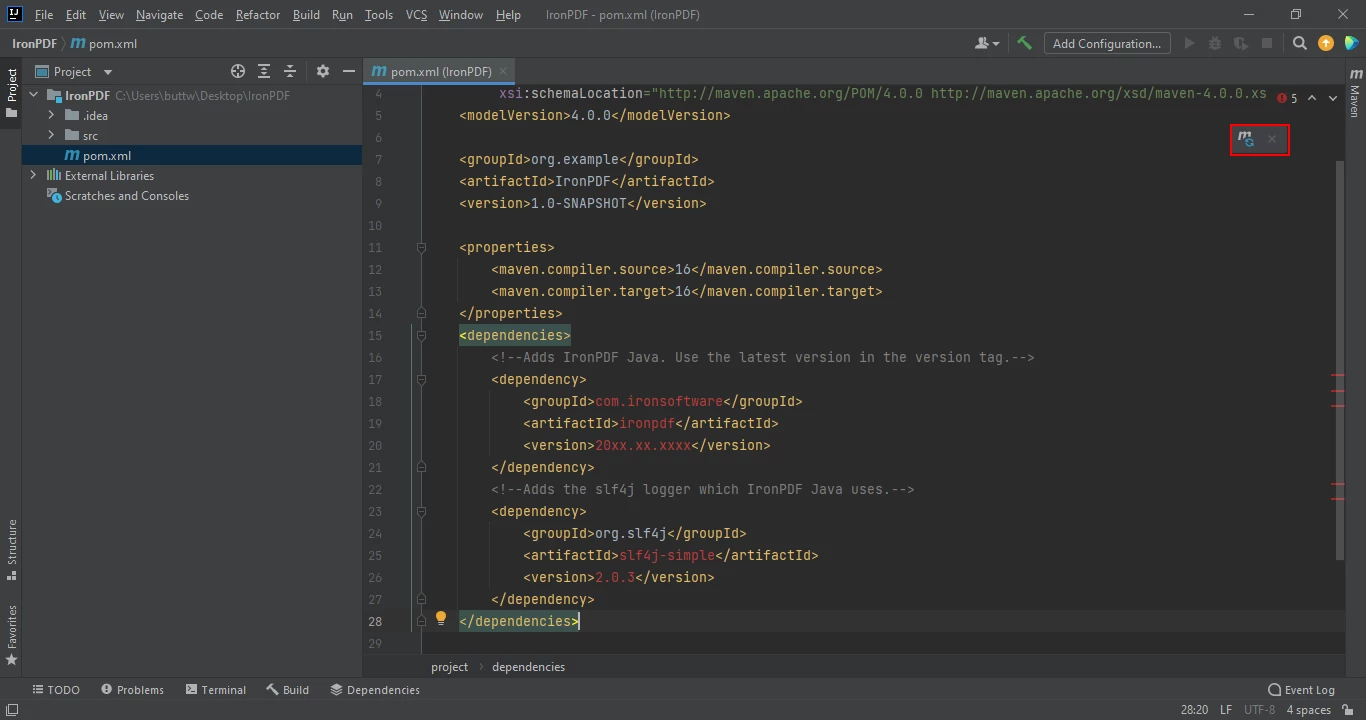 Cliquez sur l'icône flottante pour installer automatiquement les dépendances Maven
Cliquez sur l'icône flottante pour installer automatiquement les dépendances Maven
Installez les dépendances Maven d'IronPDF for Java en cliquant sur ce bouton. En fonction de la vitesse de votre connexion Internet, cela ne devrait prendre que quelques minutes.
5. Extraction de données
IronPDF est une bibliothèque Java pour créer, modifier et extraire des données de documents PDF. Elle fournit une API simple pour extraire du texte de fichiers PDF, d'URL et de tableaux.
5.1. Extraire des données de documents PDF
En using IronPDF for Java, vous pouvez facilement extraire des données de texte des documents PDF. Ci-dessous se trouve le code d'exemple pour extraire des données d'un fichier PDF.
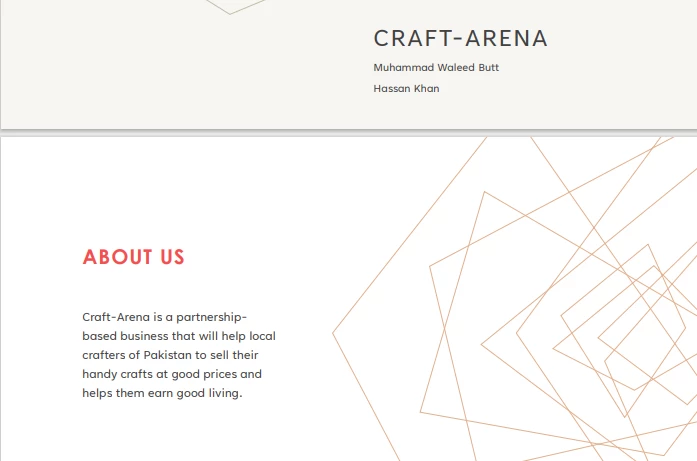 Entrée PDF
Entrée PDF
// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
import java.nio.file.Paths;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from the specified file
PdfDocument pdf = PdfDocument.fromFile(Paths.get("business plan.pdf"));
// Extract all text from the PDF document
String text = pdf.extractAllText();
// Print the extracted text to the console
System.out.println("Text extracted from the PDF: " + text);
}
}// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
import java.nio.file.Paths;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from the specified file
PdfDocument pdf = PdfDocument.fromFile(Paths.get("business plan.pdf"));
// Extract all text from the PDF document
String text = pdf.extractAllText();
// Print the extracted text to the console
System.out.println("Text extracted from the PDF: " + text);
}
}Le code source produit la sortie donnée ci-dessous :
> Text extracted from the PDF:
>
> CRAFT-ARENA
>
> Muhammad Waleed Butt
>
> Hassan Khan
>
> ABOUT US
>
> Craft-Arena is a partnership based business that will help local crafters of Pakistan to sell their handicrafts at good prices and helps them earn a good living.5.2. Extraire des données d'URL
IronPDF for Java convertit l'URL en PDF à l'exécution et en extrait le texte. Cet exemple montrera le code source pour extraire du texte d'URL.
// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException {
// Convert a URL to a PDF and load it into a PdfDocument
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
// Extract all text from the PDF document
String text = pdf.extractAllText();
// Print the extracted text to the console
System.out.println("Text extracted from the URLs: " + text);
}
}// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException {
// Convert a URL to a PDF and load it into a PdfDocument
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
// Extract all text from the PDF document
String text = pdf.extractAllText();
// Print the extracted text to the console
System.out.println("Text extracted from the URLs: " + text);
}
} Données de page web extraites
Données de page web extraites
5.3. Extraire des données de tableaux
Pour extraire des données de tableaux d'un PDF avec IronPDF for Java est très simple ; il suffit d'avoir un PDF contenant un tableau et d'exécuter le code ci-dessous.
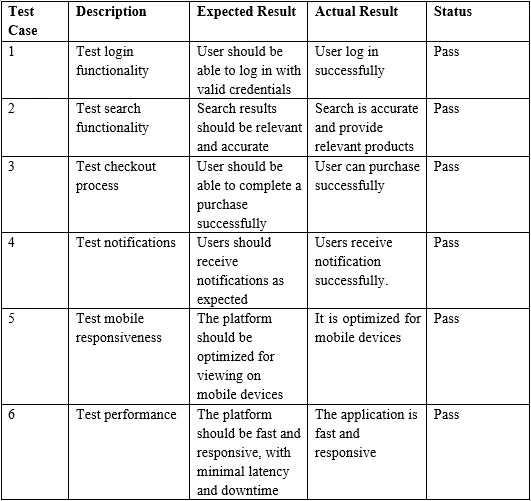 Exemple d'entrée tableau PDF
Exemple d'entrée tableau PDF
// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
import java.nio.file.Paths;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from the specified file
PdfDocument pdf = PdfDocument.fromFile(Paths.get("table.pdf"));
// Extract all text from the PDF document, including table data
String text = pdf.extractAllText();
// Print the extracted table data to the console
System.out.print("Text extracted from the Marked tables: " + text);
}
}// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
import java.nio.file.Paths;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from the specified file
PdfDocument pdf = PdfDocument.fromFile(Paths.get("table.pdf"));
// Extract all text from the PDF document, including table data
String text = pdf.extractAllText();
// Print the extracted table data to the console
System.out.print("Text extracted from the Marked tables: " + text);
}
}> Test Case Description Expected Result Actual Result Status
>
> 1 Test login functionality User should be able to log in with valid credentials
>
> User log in successfully Pass
>
> 2 Test search functionality Search results should be relevant and accurate
>
> Search is accurate and provide relevant products Pass
>
> 3 Test checkout process User should be able to complete a purchase successfully
>
> User can purchase successfully Pass6. Conclusion
En conclusion, ce tutoriel a démontré comment extraire des données, spécifiquement des données tabulaires, d'un fichier PDF avec IronPDF for Java.
Pour plus d'informations, veuillez consulter l'exemple d'extraction de texte d'un PDF sur le site IronPDF.
IronPDF est une bibliothèque avec des détails de licence commerciale , commençant à $999. Cependant, vous pouvez l'évaluer en production avec un essai gratuit en utilisant la licence d'essai d'IronPDF.
Questions Fréquemment Posées
Comment extraire du texte d'un PDF en Java ?
Vous pouvez utiliser IronPDF for Java pour extraire du texte d'un PDF en chargeant le document avec la classe PdfDocument et en utilisant la méthode extractAllText pour récupérer le texte.
Puis-je extraire des données d'une URL et la convertir en PDF en Java ?
Oui, IronPDF for Java vous permet de convertir une URL en PDF à l'exécution et d'en extraire les données en utilisant la classe PdfDocument.
Quelles sont les étapes pour configurer IronPDF dans IntelliJ IDEA ?
Pour configurer IronPDF dans IntelliJ IDEA, créez un nouveau projet Maven, ajoutez la bibliothèque IronPDF à votre fichier pom.xml, et installez les dépendances Maven en cliquant sur l'icône flottante qui apparaît.
Quels sont les prérequis pour utiliser IronPDF en Java ?
Les prérequis incluent d'avoir Java installé, un IDE Java comme Eclipse ou IntelliJ, la bibliothèque IronPDF, et Maven installé et intégré à votre IDE.
Comment puis-je extraire des données de tableau d'un PDF en utilisant Java ?
Pour extraire des données de tableau d'un PDF en using IronPDF for Java, chargez le document PDF avec la classe PdfDocument et utilisez la méthode extractAllText pour récupérer les données du tableau.
Une licence commerciale est-elle requise pour utiliser IronPDF for Java ?
Oui, IronPDF for Java nécessite une licence commerciale, mais un essai gratuit est disponible à des fins d'évaluation.
Où puis-je trouver des tutoriels pour utiliser IronPDF en Java ?
Des tutoriels et des exemples pour utiliser IronPDF for Java peuvent être trouvés sur le site Web IronPDF, notamment dans les sections exemples et tutoriels.
Quelles fonctionnalités offre IronPDF aux développeurs Java ?
IronPDF for Java offre des fonctionnalités pour créer, éditer, fusionner, diviser et manipuler des fichiers PDF, ainsi que des fonctionnalités pour sécuriser des PDFs avec une protection par mot de passe et l'ajout de signatures numériques.
Comment puis-je résoudre les problèmes d'extraction de données à partir de PDF en utilisant Java ?
Assurez-vous que toutes les conditions préalables sont respectées, telles que disposer de la dernière version de Java, d'un IDE compatible et de la bibliothèque IronPDF. Vérifiez l'intégration correcte de Maven et les dépendances de bibliothèque dans votre pom.xml.
















