
如何在 Java 中从 PDF 中提取数据
本教程将向您展示如何使用IronPDF 适用于 Java从PDF文件中提取数据。设置环境、导入库、读取输入文件和提取所需数据的步骤均通过代码示例进行解释。
2. IronPDF for Java PDF 库
IronPDF是一个软件库,为开发人员提供了在Java应用程序中生成、编辑和提取PDF文件数据的能力。 它允许您从HTML文档、图片等创建PDF,以及合并多个PDF、拆分PDF文件和操作现有PDF。 IronPDF还提供了通过密码保护功能和向PDF添加数字签名来保护PDF文件的功能,还有其他功能。
IronPDF for Java由Iron Software开发和维护。 其评价最高的功能之一是从PDF文件以及HTML和URL中提取文本和数据。
3. 先决条件
要使用IronPDF从PDF文件中提取数据,您必须满足以下先决条件:
- Java安装:确保Java已安装在您的系统上,并且其路径设置在环境变量中。 如果您尚未安装Java,请参考Java网站上的下载页面以获取说明。
- Java IDE:安装像Eclipse或IntelliJ这样的Java IDE。 您可以从这个Eclipse下载页面下载Eclipse,从这个IntelliJ下载页面下载IntelliJ。
- IronPDF库:下载并将IronPDF库作为项目中的依赖项添加。 访问IronPDF安装说明页面获取安装说明。
- Maven安装:在开始PDF转换过程之前,应安装Maven并集成到您的IDE中。 请参考这个JetBrains上的Maven安装教程以了解安装和集成Maven的步骤。
4. IronPDF for Java安装
如果符合所有要求,安装IronPDF for Java非常简单。 本指南将使用JetBrains的IntelliJ IDEA演示安装并运行示例代码。
以下是要执行的操作:
- 打开IntelliJ IDEA:在系统上启动JetBrains IntelliJ IDEA。
- 创建一个Maven项目:在IntelliJ IDEA中创建一个新的Maven项目。 这将为安装IronPDF for Java提供合适的环境。
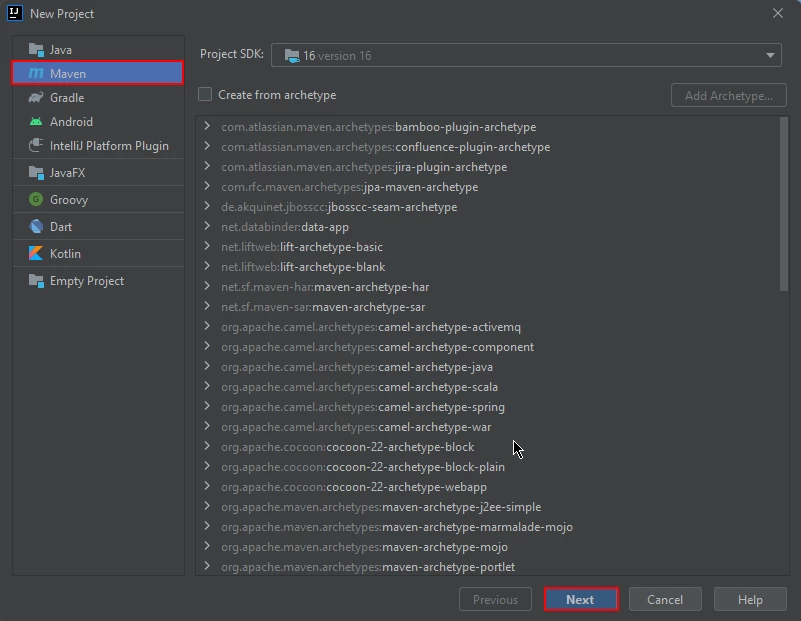 New Maven Project in IntelliJ
New Maven Project in IntelliJ
- 新窗口将打开。 输入项目名称并单击 "完成"。
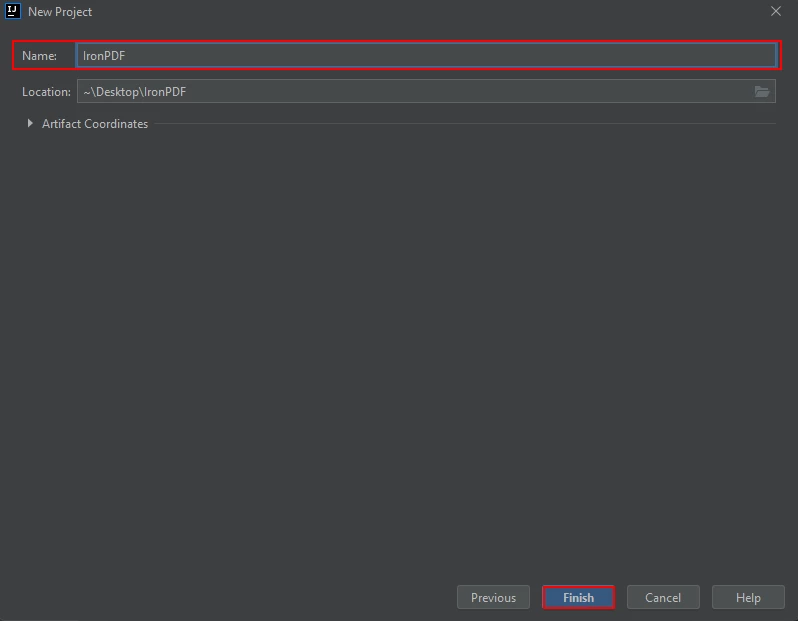 Name the Maven Project and click Finish
Name the Maven Project and click Finish
- 点击完成后,会打开一个带有pom.xml的新项目。 这将用于添加IronPDF Java Maven依赖项。
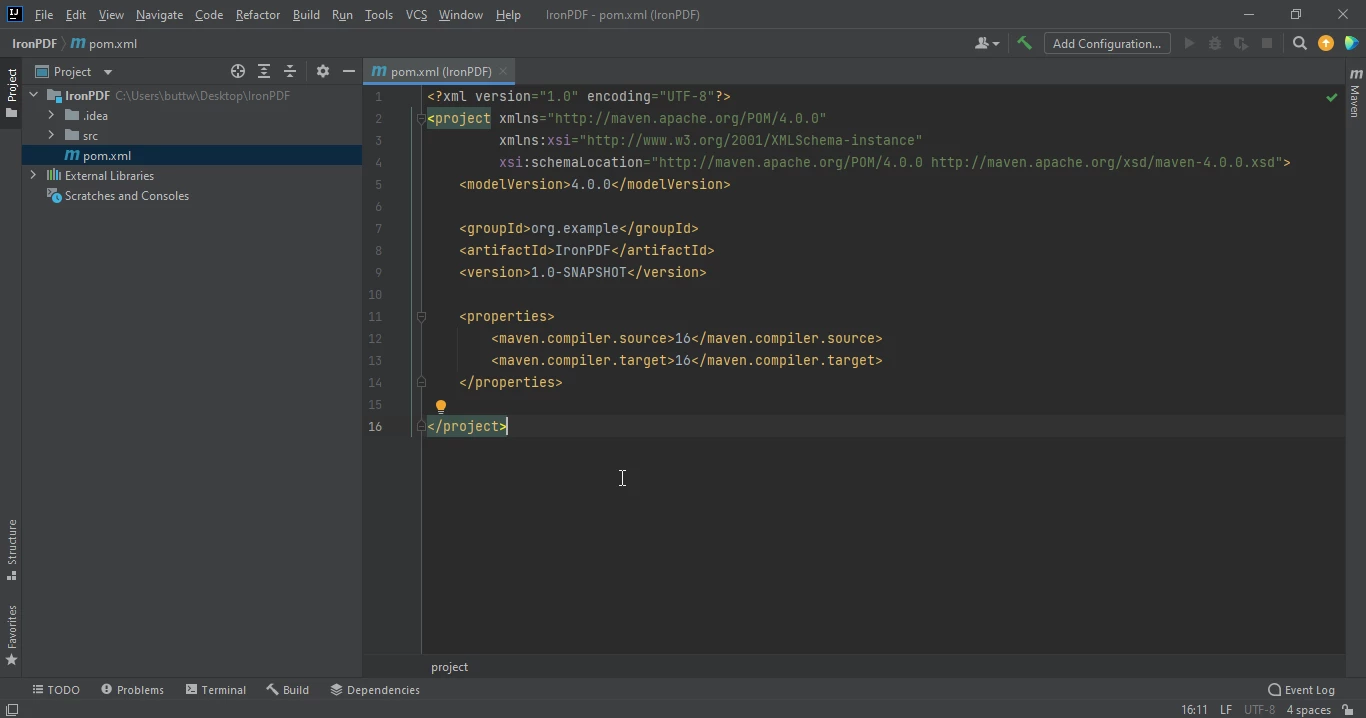 The pom.xml file
The pom.xml file
在 pom.xml 文件中添加以下依赖项,或者您可以从Sonatype Central 上的IronPDF库页面下载 JAR 文件。
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>1.0.0</version>
</dependency><dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>1.0.0</version>
</dependency>将依赖项放入 pom.xml 文件中后,文件右上角会出现一个小图标。
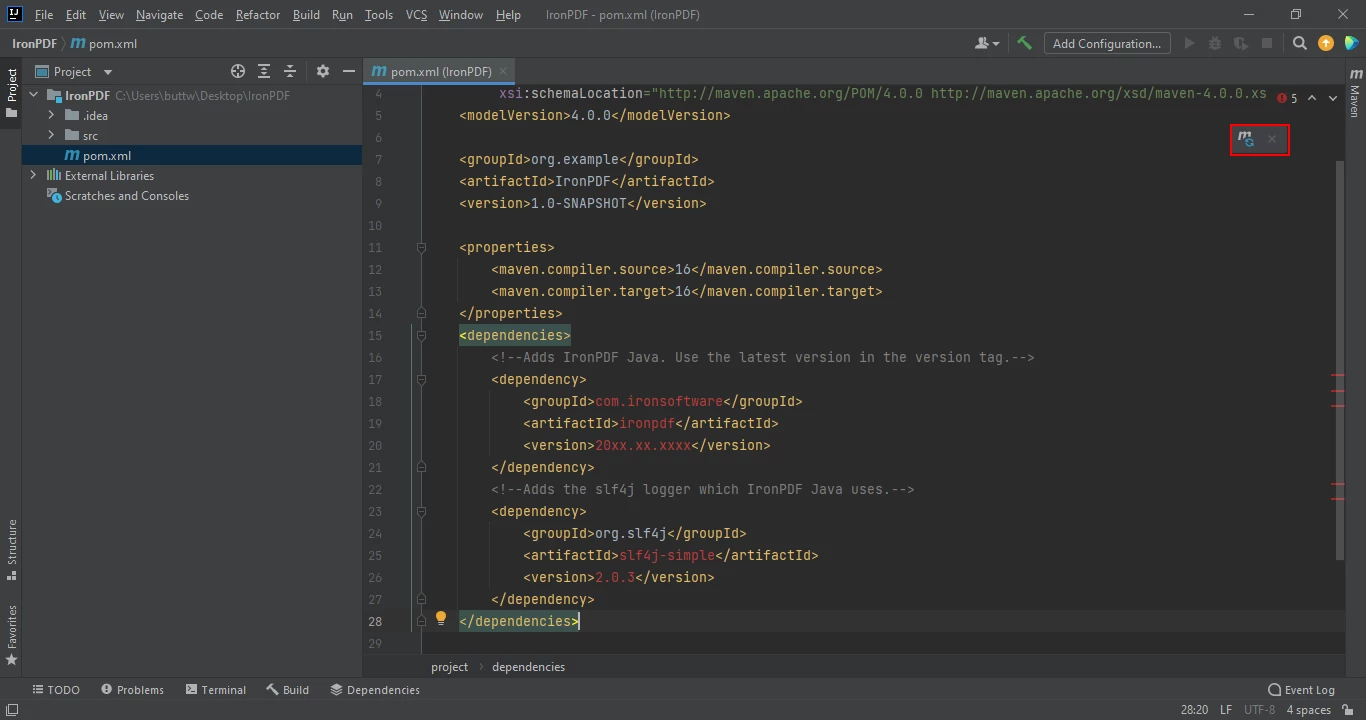 Click the floating icon to install the Maven dependencies automatically
Click the floating icon to install the Maven dependencies automatically
通过点击此按钮安装IronPDF for Java的Maven依赖项。 根据您的互联网连接速度,这应该只需几分钟。
5. 提取数据
IronPDF是一个用于创建、编辑和从PDF文档中提取数据的Java库。 它提供了一个简单的API来从PDF文件、URL和表格中提取文本。
5.1. 从PDF文档中提取数据
使用IronPDF 适用于 Java,您可以轻松地从PDF文档中提取文本数据。 以下是从PDF文件中提取数据的示例代码。
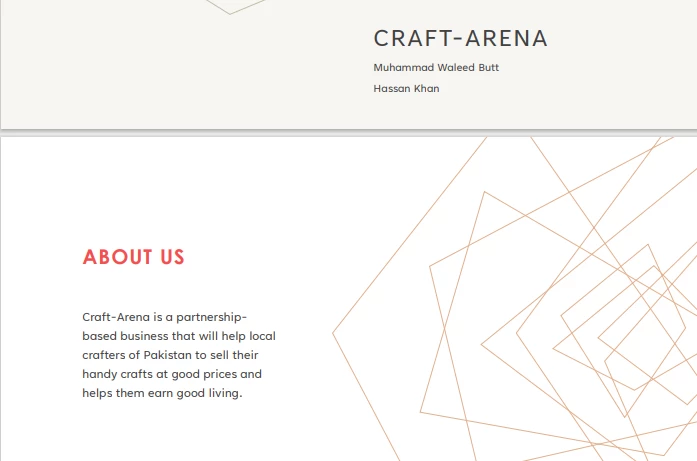 PDF Input
PDF Input
// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
import java.nio.file.Paths;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from the specified file
PdfDocument pdf = PdfDocument.fromFile(Paths.get("business plan.pdf"));
// Extract all text from the PDF document
String text = pdf.extractAllText();
// Print the extracted text to the console
System.out.println("Text extracted from the PDF: " + text);
}
}// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
import java.nio.file.Paths;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from the specified file
PdfDocument pdf = PdfDocument.fromFile(Paths.get("business plan.pdf"));
// Extract all text from the PDF document
String text = pdf.extractAllText();
// Print the extracted text to the console
System.out.println("Text extracted from the PDF: " + text);
}
}源代码生成以下输出:
> Text extracted from the PDF:
>
> CRAFT-ARENA
>
> Muhammad Waleed Butt
>
> Hassan Khan
>
> ABOUT US
>
> Craft-Arena is a partnership based business that will help local crafters of Pakistan to sell their handicrafts at good prices and helps them earn a good living.5.2. 从URLs中提取数据
IronPDF for Java在运行时将URL转换为PDF并从中提取文本。 此示例将展示从URLs中提取文本的源代码。
// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException {
// Convert a URL to a PDF and load it into a PdfDocument
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
// Extract all text from the PDF document
String text = pdf.extractAllText();
// Print the extracted text to the console
System.out.println("Text extracted from the URLs: " + text);
}
}// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException {
// Convert a URL to a PDF and load it into a PdfDocument
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
// Extract all text from the PDF document
String text = pdf.extractAllText();
// Print the extracted text to the console
System.out.println("Text extracted from the URLs: " + text);
}
}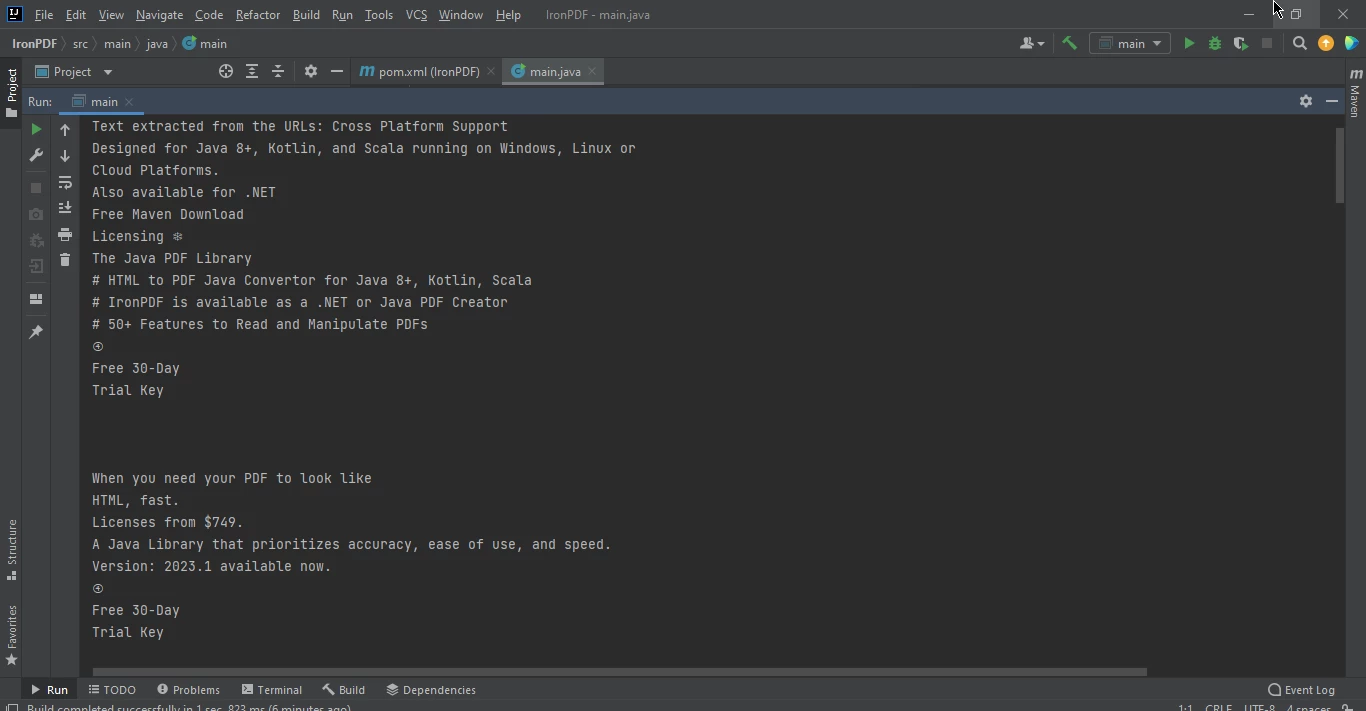 Extracted Web Page Data
Extracted Web Page Data
5.3. 从表格数据中提取数据
要从PDF中提取表格数据,使用IronPDF for Java非常简单; 您只需拥有一个包含表格的PDF,并运行以下代码。
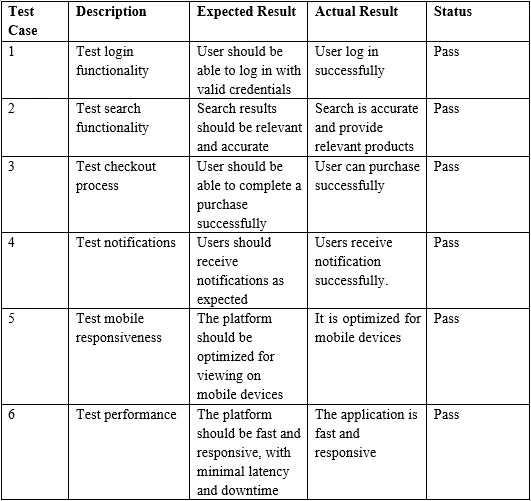 Sample PDF Table Input
Sample PDF Table Input
// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
import java.nio.file.Paths;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from the specified file
PdfDocument pdf = PdfDocument.fromFile(Paths.get("table.pdf"));
// Extract all text from the PDF document, including table data
String text = pdf.extractAllText();
// Print the extracted table data to the console
System.out.print("Text extracted from the Marked tables: " + text);
}
}// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
import java.nio.file.Paths;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from the specified file
PdfDocument pdf = PdfDocument.fromFile(Paths.get("table.pdf"));
// Extract all text from the PDF document, including table data
String text = pdf.extractAllText();
// Print the extracted table data to the console
System.out.print("Text extracted from the Marked tables: " + text);
}
}> Test Case Description Expected Result Actual Result Status
>
> 1 Test login functionality User should be able to log in with valid credentials
>
> User log in successfully Pass
>
> 2 Test search functionality Search results should be relevant and accurate
>
> Search is accurate and provide relevant products Pass
>
> 3 Test checkout process User should be able to complete a purchase successfully
>
> User can purchase successfully Pass6.结论
总之,本教程演示了如何使用IronPDF for Java从PDF文件中提取数据,特别是表格数据。
有关更多信息,请参考IronPDF网站上的从PDF提取文本示例。
IronPDF是一个具有商业许可详情的库,详情从 $999 开始。 不过,您可以使用IronPDF试用许可证进行免费试用在生产中评估它。
常见问题解答
如何在 Java 中从 PDF 中提取文本?
您可以使用 IronPDF for Java 通过加载 PdfDocument 类中的文档并利用 extractAllText 方法来提取 PDF 中的文本。
我可以从 URL 中提取数据并在 Java 中将其转换为 PDF 吗?
是的,IronPDF 适用于 Java 允许您在运行时将 URL 转换为 PDF,并使用 PdfDocument 类从中提取数据。
在 IntelliJ IDEA 中设置 IronPDF 的步骤有哪些?
要在 IntelliJ IDEA 中设置 IronPDF,请创建一个新的 Maven 项目,将 IronPDF 库添加到您的 pom.xml 文件中,然后通过点击出现的浮动图标安装 Maven 依赖项。
使用 IronPDF 在 Java 中的先决条件是什么?
先决条件包括安装 Java、Java IDE(如 Eclipse 或 IntelliJ)、IronPDF 库,并安装和集成 Maven 到你的 IDE 中。
如何使用 Java 从 PDF 中提取表格数据?
要使用 IronPDF for Java 从 PDF 中提取表格数据,请加载 PdfDocument 类中的 PDF 文档并使用 extractAllText 方法来获取表格数据。
使用 IronPDF for Java 是否需要商业许可证?
是的,IronPDF 适用于 Java 需要商业许可证,但可以通过免费试用来进行评估。
在哪里可以找到使用 IronPDF 在 Java 中的教程?
可以在 IronPDF 网站上的示例和教程部分找到使用 IronPDF for Java 的教程和示例。
IronPDF 为 Java 开发者提供了哪些功能?
IronPDF for Java 提供创建、编辑、合并、拆分及操作 PDF 文件的功能,以及通过密码保护和加入数字签名来安全地保护 PDF 的功能。
如何排除使用 Java 从 PDF 中提取数据的问题?
请确保满足所有先决条件,例如拥有最新的 Java 版本、兼容的 IDE 和 IronPDF 库。检查您的 pom.xml 文件中的正确 Maven 集成和库依赖项。

















