
Como extrair dados de um PDF em Java
Este tutorial mostrará como usar o IronPDF for Java para extrair dados de um arquivo PDF. A configuração do ambiente, a importação da biblioteca, a leitura do arquivo de entrada e a extração dos dados necessários são explicadas com exemplos de código.
2. Biblioteca IronPDF for Java
IronPDF é uma biblioteca de software que oferece aos desenvolvedores a capacidade de gerar, editar e extrair dados de arquivos PDF usando o IronPDF for Java em seus aplicativos Java. Ele permite criar PDFs a partir de documentos HTML , imagens e muito mais, além de mesclar vários PDFs , dividir arquivos PDF e manipular PDFs existentes. O IronPDF também oferece a possibilidade de proteger PDFs com recursos de proteção por senha e adicionar assinaturas digitais a PDFs , entre outros recursos.
O IronPDF for Java é desenvolvido e mantido pela Iron Software. Uma de suas funcionalidades mais bem avaliadas é a extração de texto e dados de arquivos PDF, bem como de HTML e URLs.
3. Pré-requisitos
Para usar o IronPDF para extrair dados de arquivos PDF, você deve atender aos seguintes pré-requisitos:
- Instalação do Java: Certifique-se de que o Java esteja instalado em seu sistema e que seu caminho esteja configurado nas variáveis de ambiente. Se você ainda não instalou o Java, consulte esta página de download no site do Java para obter instruções.
- IDE Java: Tenha uma IDE Java como o Eclipse ou o IntelliJ instalada. Você pode baixar o Eclipse nesta página de downloads do Eclipse e o IntelliJ nesta página de downloads do IntelliJ .
- Biblioteca IronPDF : Baixe e adicione a biblioteca IronPDF como uma dependência em seu projeto. Visite a página de instruções de configuração do IronPDF para obter instruções de configuração.
- Instalação do Maven: O Maven deve ser instalado e integrado ao seu IDE antes de iniciar o processo de conversão para PDF. Consulte este tutorial de instalação do Maven da JetBrains sobre como instalar e integrar o Maven.
4. Instalação do IronPDF for Java
Instalar o IronPDF for Java é fácil e descomplicado, desde que todos os requisitos sejam atendidos. Este guia utilizará o IntelliJ IDEA da JetBrains para demonstrar a instalação e executar um código de exemplo.
Eis o que fazer:
- Abra o IntelliJ IDEA: Inicie o JetBrains IntelliJ IDEA em seu sistema.
- Criar um projeto Maven: No IntelliJ IDEA, crie um novo projeto Maven. Isso proporcionará um ambiente adequado para a instalação do IronPDF for Java.
 Novo projeto Maven no IntelliJ
Novo projeto Maven no IntelliJ
- Uma nova janela será aberta. Digite o nome do projeto e clique em Concluir.
 Dê um nome ao projeto Maven e clique em Concluir.
Dê um nome ao projeto Maven e clique em Concluir.
- Um novo projeto com um arquivo pom.xml será aberto assim que você clicar em Concluir. Isso será usado para adicionar as dependências do IronPDF Java Maven.
 O arquivo pom.xml
O arquivo pom.xml
Adicione as seguintes dependências no arquivo pom.xml ou você pode baixar o arquivo JAR da página da biblioteca IronPDF no Sonatype Central.
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>1.0.0</version>
</dependency><dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>1.0.0</version>
</dependency>Depois de colocar as dependências no arquivo pom.xml, um pequeno ícone aparecerá no canto superior direito do arquivo.
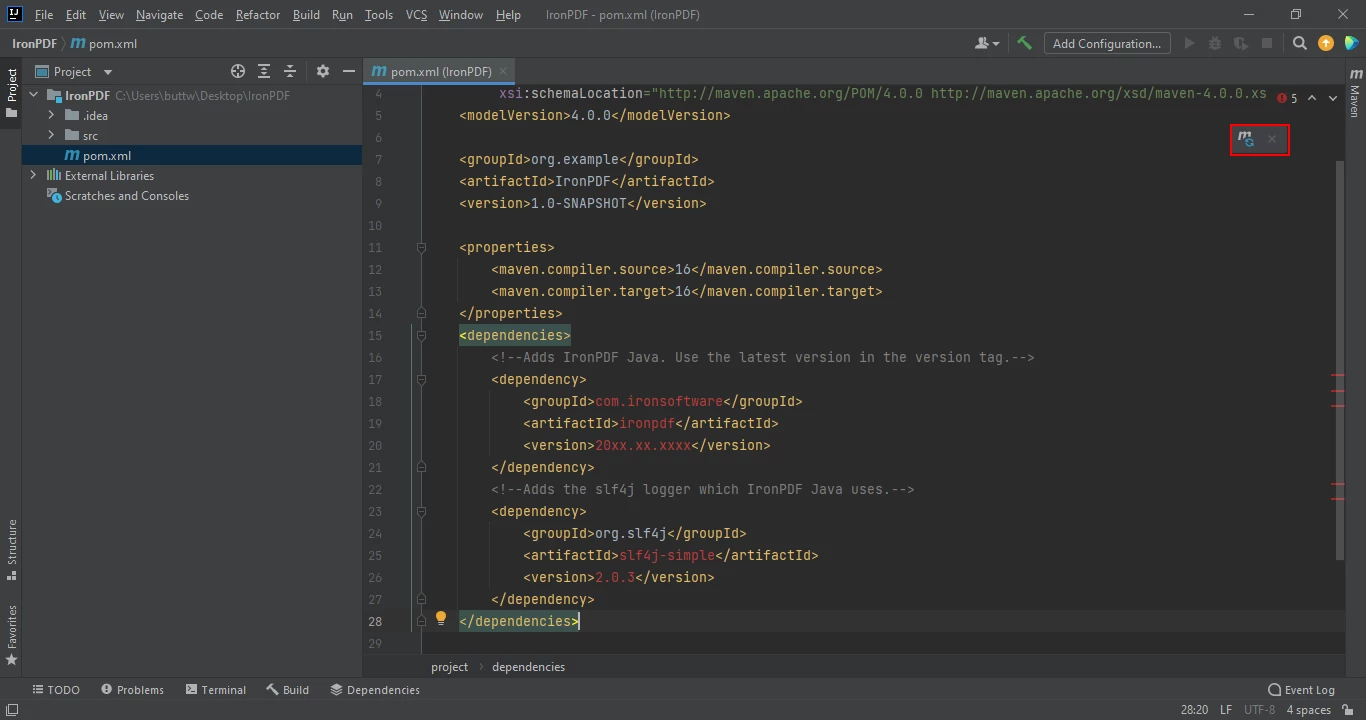 Clique no ícone flutuante para instalar as dependências do Maven automaticamente.
Clique no ícone flutuante para instalar as dependências do Maven automaticamente.
Instale as dependências Maven do IronPDF for Java clicando neste botão. Dependendo da velocidade da sua conexão com a internet, isso deve levar apenas alguns minutos.
5. Extrair dados
IronPDF é uma biblioteca Java para criar, editar e extrair dados de documentos PDF. Ela fornece uma API simples para extrair texto de arquivos PDF, URLs e tabelas.
5.1. Extrair dados de documentos PDF
Utilizando o IronPDF for Java, você pode extrair facilmente dados de texto de documentos PDF. Abaixo está um exemplo de código para extrair dados de um arquivo PDF.
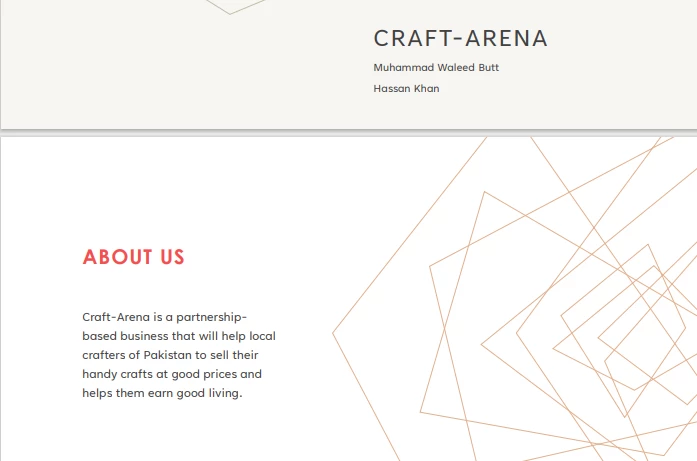 Entrada de PDF
Entrada de PDF
// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
import java.nio.file.Paths;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from the specified file
PdfDocument pdf = PdfDocument.fromFile(Paths.get("business plan.pdf"));
// Extract all text from the PDF document
String text = pdf.extractAllText();
// Print the extracted text to the console
System.out.println("Text extracted from the PDF: " + text);
}
}// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
import java.nio.file.Paths;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from the specified file
PdfDocument pdf = PdfDocument.fromFile(Paths.get("business plan.pdf"));
// Extract all text from the PDF document
String text = pdf.extractAllText();
// Print the extracted text to the console
System.out.println("Text extracted from the PDF: " + text);
}
}O código-fonte produz a saída apresentada abaixo:
> Text extracted from the PDF:
>
> CRAFT-ARENA
>
> Muhammad Waleed Butt
>
> Hassan Khan
>
> ABOUT US
>
> Craft-Arena is a partnership based business that will help local crafters of Pakistan to sell their handicrafts at good prices and helps them earn a good living.5.2. Extrair dados de URLs
O IronPDF for Java converte a URL em PDF em tempo de execução e extrai o texto dela. Este exemplo mostrará o código-fonte para extrair texto de URLs.
// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException {
// Convert a URL to a PDF and load it into a PdfDocument
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
// Extract all text from the PDF document
String text = pdf.extractAllText();
// Print the extracted text to the console
System.out.println("Text extracted from the URLs: " + text);
}
}// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException {
// Convert a URL to a PDF and load it into a PdfDocument
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
// Extract all text from the PDF document
String text = pdf.extractAllText();
// Print the extracted text to the console
System.out.println("Text extracted from the URLs: " + text);
}
}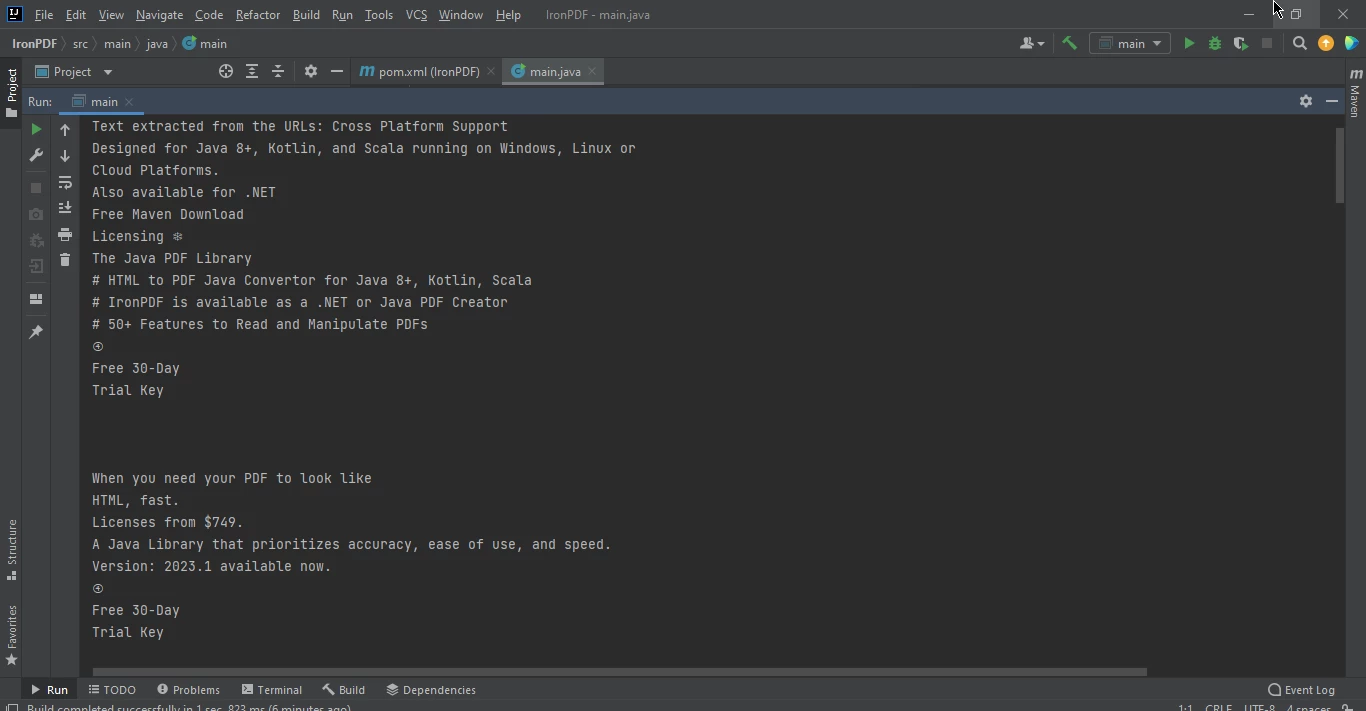 Dados extraídos da página da Web
Dados extraídos da página da Web
5.3. Extrair dados de dados de tabela
Extrair dados de tabelas de um PDF usando o IronPDF for Java é muito simples; Você só precisa de um PDF contendo uma tabela e executar o código abaixo.
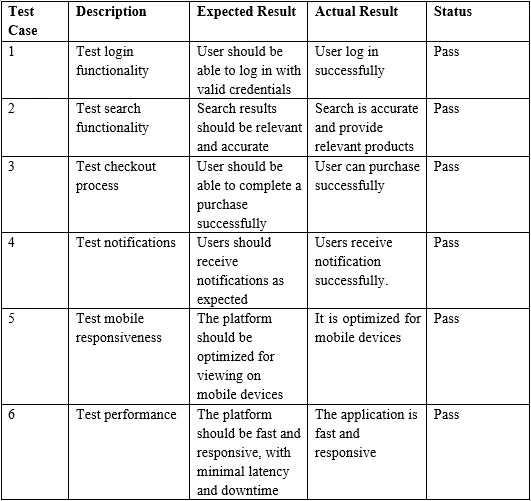 Exemplo de entrada de tabela em PDF
Exemplo de entrada de tabela em PDF
// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
import java.nio.file.Paths;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from the specified file
PdfDocument pdf = PdfDocument.fromFile(Paths.get("table.pdf"));
// Extract all text from the PDF document, including table data
String text = pdf.extractAllText();
// Print the extracted table data to the console
System.out.print("Text extracted from the Marked tables: " + text);
}
}// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
import java.nio.file.Paths;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from the specified file
PdfDocument pdf = PdfDocument.fromFile(Paths.get("table.pdf"));
// Extract all text from the PDF document, including table data
String text = pdf.extractAllText();
// Print the extracted table data to the console
System.out.print("Text extracted from the Marked tables: " + text);
}
}> Test Case Description Expected Result Actual Result Status
>
> 1 Test login functionality User should be able to log in with valid credentials
>
> User log in successfully Pass
>
> 2 Test search functionality Search results should be relevant and accurate
>
> Search is accurate and provide relevant products Pass
>
> 3 Test checkout process User should be able to complete a purchase successfully
>
> User can purchase successfully Pass6. Conclusão
Em conclusão, este tutorial demonstrou como extrair dados, especificamente dados tabulares, de um arquivo PDF usando o IronPDF for Java.
Para obter mais informações, consulte o exemplo de extração de texto de um PDF no site da IronPDF .
IronPDF é uma biblioteca com detalhes de licença comercial, começando em $999. No entanto, você pode avaliá-lo em produção com um teste gratuito usando a licença de avaliação do IronPDF .
Perguntas frequentes
Como extrair texto de um PDF em Java?
Você pode usar o IronPDF for Java para extrair texto de um PDF carregando o documento com a classe PdfDocument e utilizando o método extractAllText para recuperar o texto.
É possível extrair dados de uma URL e convertê-los para PDF em Java?
Sim, o IronPDF for Java permite converter uma URL em PDF em tempo de execução e extrair dados dele usando a classe PdfDocument .
Quais são os passos para configurar o IronPDF no IntelliJ IDEA?
Para configurar o IronPDF no IntelliJ IDEA, crie um novo projeto Maven, adicione a biblioteca IronPDF ao seu arquivo pom.xml e instale as dependências do Maven clicando no ícone flutuante que aparece.
Quais são os pré-requisitos para usar o IronPDF em Java?
Os pré-requisitos incluem ter o Java instalado, uma IDE Java como o Eclipse ou o IntelliJ, a biblioteca IronPDF e o Maven instalado e integrado à sua IDE.
Como posso extrair dados de uma tabela de um PDF usando Java?
Para extrair dados de tabela de um PDF usando o IronPDF for Java, carregue o documento PDF com a classe PdfDocument e use o método extractAllText para recuperar os dados da tabela.
É necessária uma licença comercial para usar o IronPDF for Java?
Sim, o IronPDF for Java requer uma licença comercial, mas uma versão de avaliação gratuita está disponível para fins de avaliação.
Onde posso encontrar tutoriais sobre como usar o IronPDF em Java?
Tutoriais e exemplos de uso do IronPDF for Java podem ser encontrados no site do IronPDF, particularmente nas seções de exemplos e tutoriais.
Quais funcionalidades o IronPDF oferece para desenvolvedores Java?
O IronPDF for Java oferece funcionalidades para criar, editar, mesclar, dividir e manipular arquivos PDF, além de recursos para proteger PDFs com senha e adicionar assinaturas digitais.
Como posso solucionar problemas com a extração de dados de PDFs usando Java?
Certifique-se de que todos os pré-requisitos sejam atendidos, como ter a versão mais recente do Java, uma IDE compatível e a biblioteca IronPDF. Verifique se a integração do Maven e as dependências da biblioteca estão corretas no seu arquivo pom.xml .

















