
Comment analyser les PDF en Java (Tutoriel pour développeur)
Cet article créera un analyseur PDF en Java en utilisant la bibliothèque IronPDF de manière efficace.
IronPDF - Bibliothèque de PDF pour Java
IronPDF pour Java est une bibliothèque PDF Java qui permet la création, la lecture et la manipulation de documents PDF avec facilité et précision. Il est construit sur le succès de IronPDF for .NET et fournit des fonctionnalités efficaces sur différentes plateformes. IronPDF for Java utilise le IronPdfEngine qui est rapide et optimisé pour les performances.
Avec IronPDF, vous pouvez extraire du texte et des images des fichiers PDF et il permet également la création de PDF à partir de diverses sources y compris des chaînes HTML, des fichiers, des URL et des images. De plus, vous pouvez facilement ajouter du nouveau contenu, insérer des signatures avec IronPDF, et intégrer des métadonnées dans des documents PDF. IronPDF est spécialement conçu pour Java 8+, Scala, et Kotlin, et est compatible avec les plateformes Windows, Linux, et Cloud.
Comment analyser un fichier PDF en Java
- Téléchargez la bibliothèque Java pour analyser un fichier PDF
- Charger un document PDF existant à l'aide de la méthode `fromFile`
- Extrayez tout le texte du PDF analysé à l'aide de la méthode `extractAllText`
- Utilisez la méthode `renderUrlAsPdf` pour rendre un PDF à partir d'une URL
- Extrayez les images du PDF analysé à l'aide de la méthode `extractAllImages`
Créer un analyseur de fichier PDF avec IronPDF dans un programme Java
Prérequis
Pour réaliser un projet d'analyse PDF en Java, vous aurez besoin des outils suivants :
- IDE Java : Vous pouvez utiliser n'importe quel IDE compatible avec Java. Plusieurs IDE Java sont disponibles pour le développement. Ici, ce tutoriel utilisera IntelliJ IDE. Vous pouvez utiliser NetBeans, Eclipse, etc.
- Projet Maven : Maven est un gestionnaire de dépendances qui permet de contrôler le projet Java. Maven pour Java peut être téléchargé depuis le site officiel de Maven. IntelliJ Java IDE dispose d'un support intégré pour Maven.
-
IronPDF - Vous pouvez télécharger et installer IronPDF for Java de plusieurs manières.
-
Ajout de la dépendance IronPDF dans le fichier
pom.xmld'un projet Maven .<dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>[LATEST_VERSION]</version> </dependency><dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>[LATEST_VERSION]</version> </dependency>XML - Visitez le site du dépôt Maven pour le dernier package IronPDF for Java.
- Un téléchargement direct depuis la page de téléchargement officielle de Iron Software.
- Installer manuellement IronPDF en utilisant le fichier JAR dans votre simple application Java.
-
-
Slf4j-Simple : Cette dépendance est également requise pour ajouter du contenu à un document existant. Il est possible de l'ajouter via le gestionnaire de dépendances Maven d'IntelliJ, ou de le télécharger directement depuis le site web de Maven . Ajoutez la dépendance suivante au fichier
pom.xml:<dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-simple</artifactId> <version>2.0.5</version> </dependency><dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-simple</artifactId> <version>2.0.5</version> </dependency>XML
Ajouter les imports nécessaires
Une fois que toutes les prérequis sont installés, la première étape consiste à importer les packages nécessaires d'IronPDF pour travailler avec un document PDF. Ajoutez le code suivant en haut du fichier Main.java :
import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;Clé de licence
Certaines méthodes disponibles dans IronPDF nécessitent une licence pour être utilisées. Vous pouvez acheter une licence ou essayer IronPDF avec un essai gratuit. Vous pouvez définir la clé comme suit :
License.setLicenseKey("YOUR-KEY");License.setLicenseKey("YOUR-KEY");Étape 1 : Analyser un document PDF existant
Pour analyser un document existant en vue d'en extraire le contenu, la classe PdfDocument est utilisée. Sa méthode statique fromFile est utilisée pour analyser un fichier PDF à partir d'un chemin spécifique avec un nom de fichier spécifique dans un programme Java. Le code est le suivant :
PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("sample.pdf"));PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("sample.pdf"));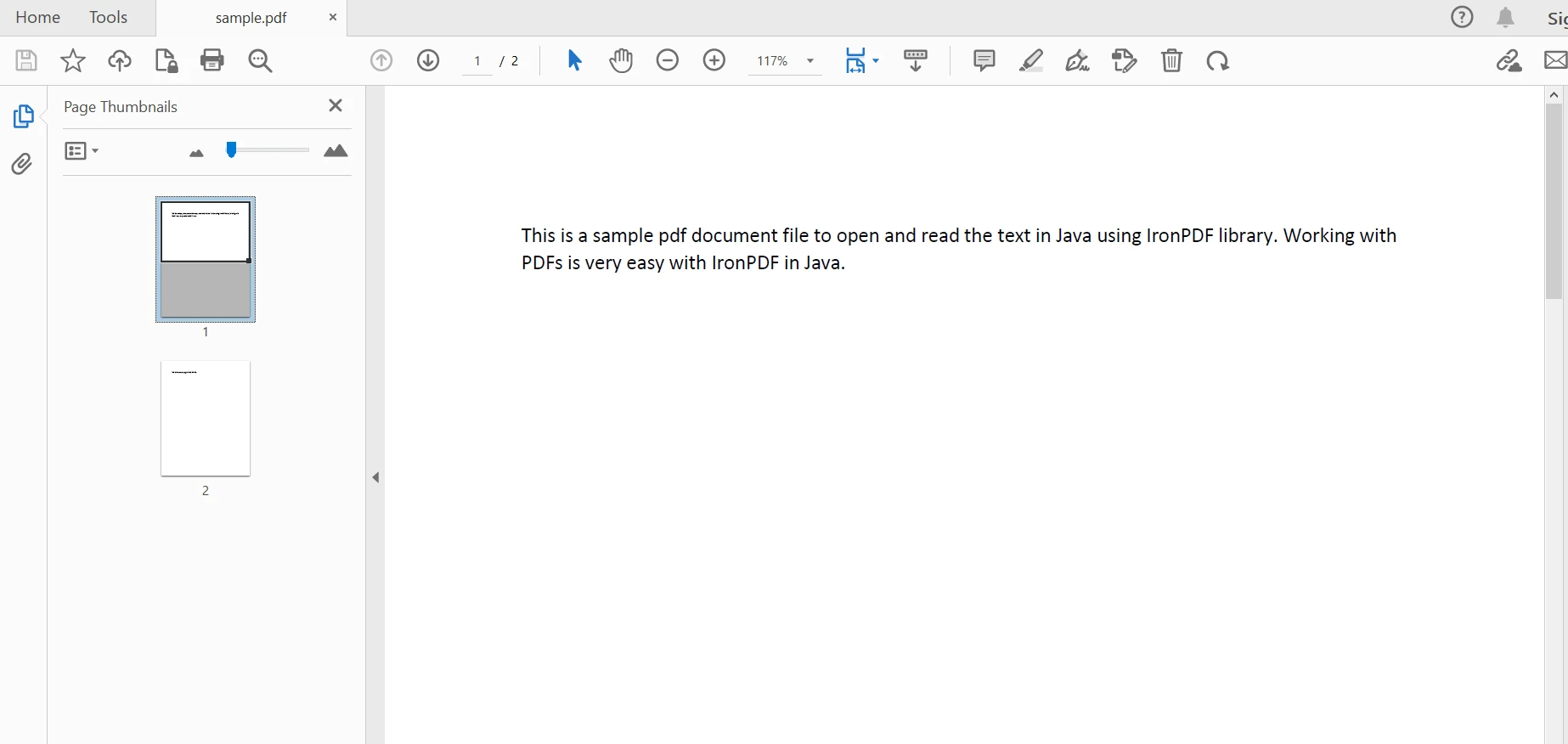 Document analysé
Document analysé
Étape 2 : Extraire des données textuelles du fichier PDF analysé
IronPDF for Java fournit une méthode facile pour extraire du texte à partir de documents PDF. Le snippet de code suivant est pour extraire des données textuelles d'un fichier PDF se trouve ci-dessous :
String extractedText = parsedDocument.extractAllText();String extractedText = parsedDocument.extractAllText();Le code ci-dessus produit la sortie donnée ci-dessous :
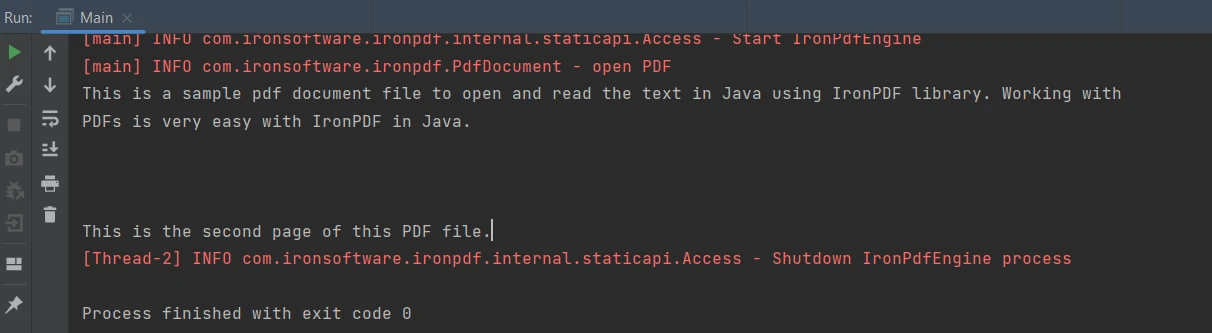 Sortie
Sortie
Étape 3 : Extraire des données textuelles à partir d'URLs ou de chaînes HTML
La capacité d'IronPDF for Java n'est pas seulement limitée aux PDF existants, mais elle peut également créer et analyser un nouveau fichier pour en extraire du contenu. Ici, ce tutoriel va créer un fichier PDF à partir d'une URL et en extraire le contenu. L'exemple suivant montre comment réaliser cette tâche :
public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
String extractedText = parsedDocument.extractAllText();
System.out.println("Text Extracted from URL:\n" + extractedText);
}
}public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
String extractedText = parsedDocument.extractAllText();
System.out.println("Text Extracted from URL:\n" + extractedText);
}
}La sortie est la suivante :
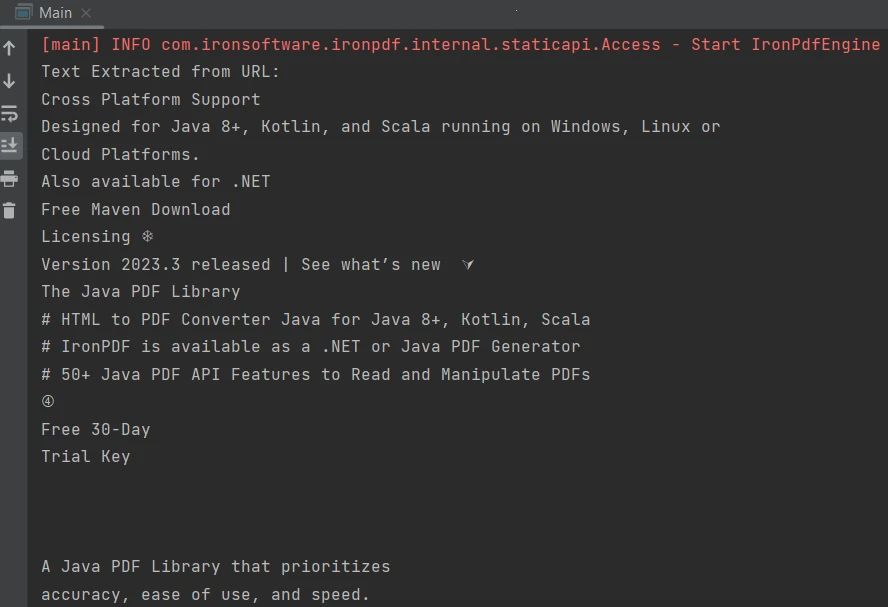 Sortie
Sortie
Étape 4 : Extraire des images du document PDF analysé
IronPDF fournit également une option facile pour extraire toutes les images des documents analysés. Ici, le tutoriel utilisera l'exemple précédent pour voir à quel point il est facile d'extraire les images des fichiers PDF.
import com.ironsoftware.ironpdf.*;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
try {
List<BufferedImage> images = parsedDocument.extractAllImages();
System.out.println("Number of images extracted from the website: " + images.size());
int i = 0;
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("assets/extracted_" + ++i + ".png")));
}
} catch (Exception exception) {
System.out.println("Failed to extract images from the website");
exception.printStackTrace();
}
}
}import com.ironsoftware.ironpdf.*;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
try {
List<BufferedImage> images = parsedDocument.extractAllImages();
System.out.println("Number of images extracted from the website: " + images.size());
int i = 0;
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("assets/extracted_" + ++i + ".png")));
}
} catch (Exception exception) {
System.out.println("Failed to extract images from the website");
exception.printStackTrace();
}
}
}La méthode [extractAllImages](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllImages() ) renvoie une liste de BufferedImages. Chaque BufferedImage peut ensuite être stocké sous forme d'images PNG à un emplacement en utilisant la méthode ImageIO.write. Il y a 34 images dans le fichier PDF analysé et chaque image est parfaitement extraite.
 Images extraites
Images extraites
Étape 5 : Extraire des données d'un tableau dans des fichiers PDF
L'extraction du contenu des limites tabulaires d'un fichier PDF est facilitée par une simple ligne de code utilisant la [méthode extractAllText](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllText() ). Le snippet de code suivant montre comment extraire du texte d'un tableau dans un fichier PDF :
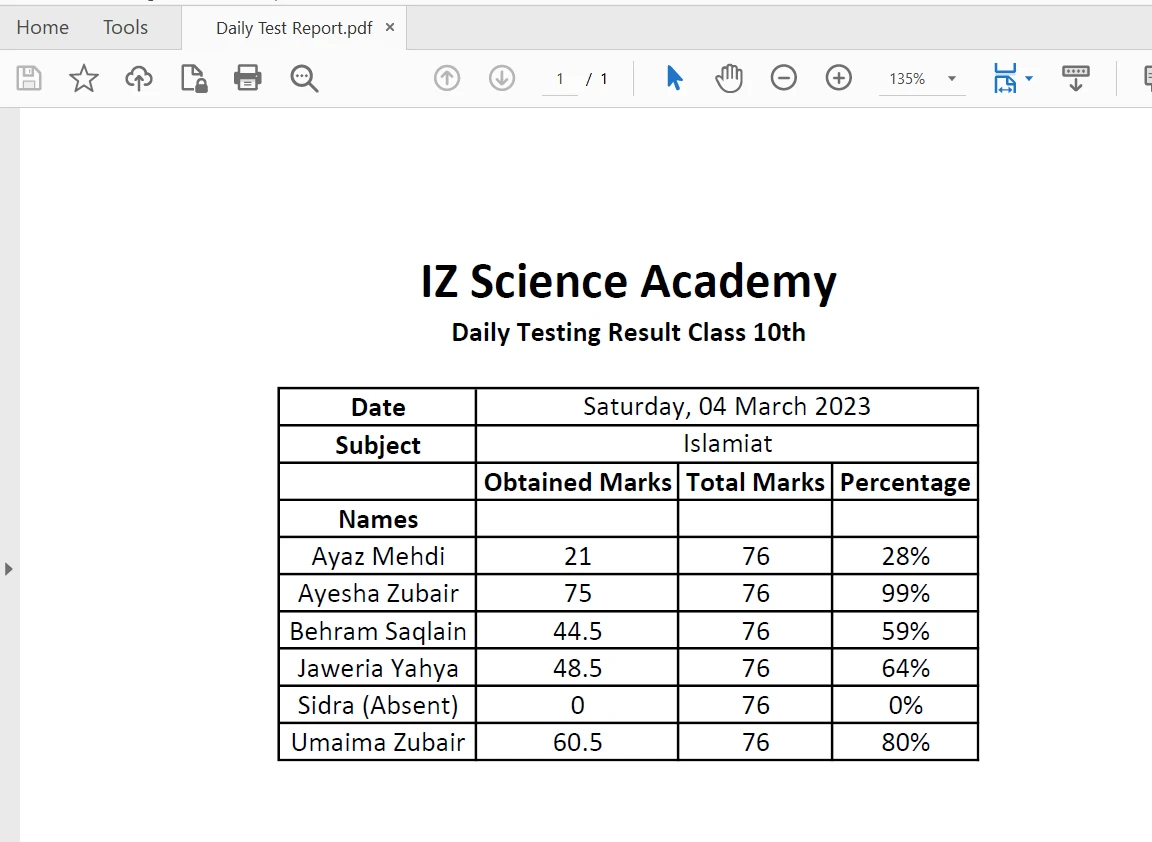 Tableau dans un PDF
Tableau dans un PDF
PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("table.pdf"));
String extractedText = parsedDocument.extractAllText();
System.out.println(extractedText);PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("table.pdf"));
String extractedText = parsedDocument.extractAllText();
System.out.println(extractedText);La sortie est la suivante :
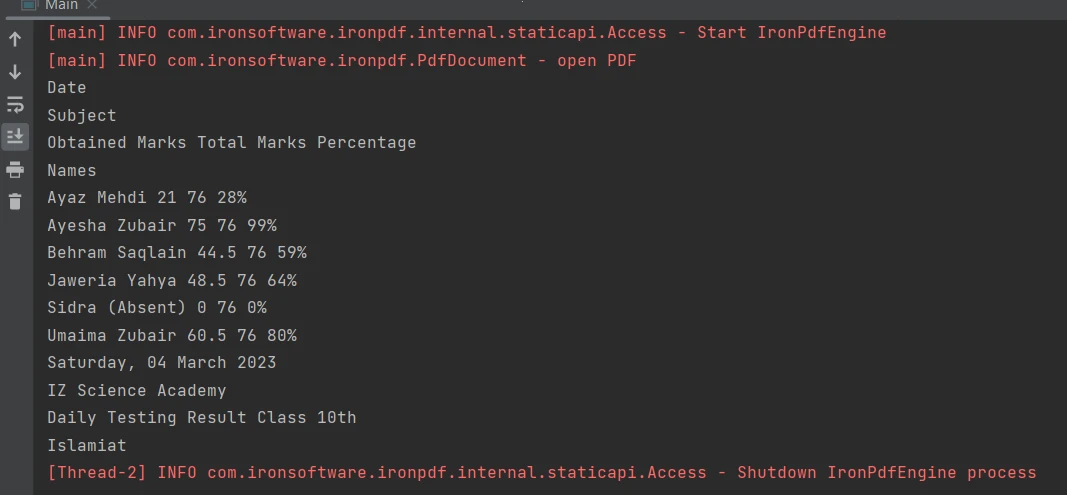 Sortie
Sortie
Conclusion
Cet article a démontré comment analyser un document PDF existant ou créer un nouveau fichier analyseur PDF à partir d'une URL pour en extraire des données en Java avec IronPDF. Après ouverture du fichier, il peut extraire des données tabulaires, des images, et du texte du PDF, et peut également ajouter le texte extrait à un fichier texte pour une utilisation ultérieure.
Pour des informations plus détaillées sur la façon de travailler avec des fichiers PDF de manière programmatique en Java, veuillez visiter ces exemples de création de fichiers PDF.
La bibliothèque IronPDF for Java est gratuite à des fins de développement avec un essai gratuit disponible. Toutefois, pour une utilisation commerciale, il peut être concédé sous licence via IronSoftware , à partir de $999.
Questions Fréquemment Posées
Comment créer un analyseur de PDF en Java ?
Pour créer un analyseur de PDF en Java, vous pouvez utiliser la bibliothèque IronPDF. Commencez par télécharger et installer IronPDF, puis chargez votre document PDF en utilisant la méthode fromFile. Vous pouvez extraire du texte et des images en utilisant respectivement les méthodes extractAllText et extractAllImages.
IronPDF peut-il être utilisé avec Java 8+ ?
Oui, IronPDF est compatible avec Java 8 et supérieur, ainsi qu'avec Scala et Kotlin. Il prend en charge plusieurs plateformes, y compris Windows, Linux et les environnements cloud.
Quelles sont les principales étapes pour analyser des PDF avec IronPDF en Java ?
Les principales étapes incluent la configuration d'un projet Maven, l'ajout de la dépendance IronPDF, le chargement d'un document PDF avec fromFile, l'extraction de texte avec extractAllText et l'extraction d'images avec extractAllImages.
Comment puis-je convertir une URL en PDF en Java ?
Vous pouvez convertir une URL en PDF en Java en utilisant la méthode renderUrlAsPdf de IronPDF. Cela vous permet de générer des pages web sous forme de documents PDF de manière efficace.
IronPDF est-il adapté aux applications Java basées sur le cloud ?
Oui, IronPDF est conçu pour être polyvalent et prend en charge les environnements basés sur le cloud, ce qui le rend adapté au développement d'applications Java nécessitant des fonctionnalités PDF dans le cloud.
Comment gérer les dépendances pour un projet d'analyse PDF en Java ?
Pour gérer les dépendances dans un projet Java, vous pouvez utiliser Maven. Ajoutez la bibliothèque IronPDF au fichier pom.xml de votre projet pour l'inclure en tant que dépendance.
Quelles sont les options de licence disponibles pour IronPDF ?
IronPDF propose un essai gratuit à des fins de développement. Cependant, pour une utilisation commerciale, une licence est requise. Cela garantit l'accès à toutes les fonctionnalités et un support prioritaire.
















