
Como analisar PDFs em Java (Tutorial para desenvolvedores)
Este artigo criará um analisador de PDF em Java usando a biblioteca IronPDF de forma eficiente.
IronPDF - Biblioteca Java para PDF
IronPDF for Java é uma biblioteca Java para PDF que permite a criação, leitura e manipulação de documentos PDF com facilidade e precisão. Ele foi desenvolvido com base no sucesso do IronPDF for .NET e oferece funcionalidades eficientes em diferentes plataformas. IronPDF for Java utiliza o IronPdfEngine que é rápido e otimizado para desempenho.
Com o IronPDF, você pode extrair texto e imagens de arquivos PDF , além de criar PDFs a partir de diversas fontes, incluindo strings HTML, arquivos, URLs e imagens. Além disso, você pode facilmente adicionar novo conteúdo, inserir assinaturas com o IronPDF e incorporar metadados em documentos PDF . O IronPDF foi projetado especificamente para Java 8+, Scala e Kotlin, e é compatível com plataformas Windows, Linux e em nuvem.
Como analisar um arquivo PDF em Java
- Baixe a biblioteca Java para analisar um arquivo PDF.
- Carregar um documento PDF existente usando o método
fromFile - Extraia todo o texto do PDF analisado usando o método
extractAllText - Use o método
renderUrlAsPdfpara renderizar um PDF a partir de uma URL. - Extraia as imagens do PDF analisado usando o método
extractAllImages
Criar um analisador de arquivos PDF usando IronPDF em um programa Java
Pré-requisitos
Para criar um projeto de análise de PDF em Java, você precisará das seguintes ferramentas:
- IDE Java: Você pode usar qualquer IDE compatível com Java. Existem diversas IDEs Java disponíveis para desenvolvimento. Neste tutorial, será utilizado o IntelliJ IDE . Você pode usar o NetBeans, o Eclipse, etc.
- Projeto Maven: O Maven é um gerenciador de dependências que permite o controle sobre o projeto Java. O Maven for Java pode ser baixado do site oficial do Maven . O IntelliJ Java IDE possui suporte integrado para Maven.
-
IronPDF - Você pode baixar e instalar o IronPDF for Java de diversas maneiras.
-
Adicionando a dependência do IronPDF no arquivo
pom.xmlem um projeto Maven.<dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>[LATEST_VERSION]</version> </dependency><dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>[LATEST_VERSION]</version> </dependency>XML - Visite o site do repositório Maven para obter o pacote IronPDF mais recente para Java .
- Download direto da página oficial de downloads da Iron Software .
- Instale manualmente o IronPDF usando o arquivo JAR em sua aplicação Java simples.
-
-
Slf4j-Simple: Esta dependência também é necessária para inserir conteúdo em um documento existente. Pode ser adicionado usando o gerenciador de dependências do Maven no IntelliJ ou pode ser baixado diretamente do site do Maven. Adicione a seguinte dependência ao arquivo
pom.xml:<dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-simple</artifactId> <version>2.0.5</version> </dependency><dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-simple</artifactId> <version>2.0.5</version> </dependency>XML
Adicionando as importações necessárias
Após a instalação de todos os pré-requisitos, o primeiro passo é importar os pacotes IronPDF necessários para trabalhar com um documento PDF. Adicione o seguinte código no topo do arquivo Main.java:
import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;Chave de licença
Alguns métodos disponíveis no IronPDF exigem uma licença para serem utilizados. Você pode adquirir uma licença ou experimentar o IronPDF gratuitamente durante o período de teste. Você pode definir a chave da seguinte forma:
License.setLicenseKey("YOUR-KEY");License.setLicenseKey("YOUR-KEY");Etapa 1: Analisar um documento PDF existente
Para analisar um documento existente para extração de conteúdo, a classe PdfDocument é usada. Seu método estático [fromFile](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#fromFile(java.nio.file.Path) é usado para analisar um arquivo PDF de um caminho específico com um nome de arquivo específico em um programa Java. O código é o seguinte:
PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("sample.pdf"));PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("sample.pdf"));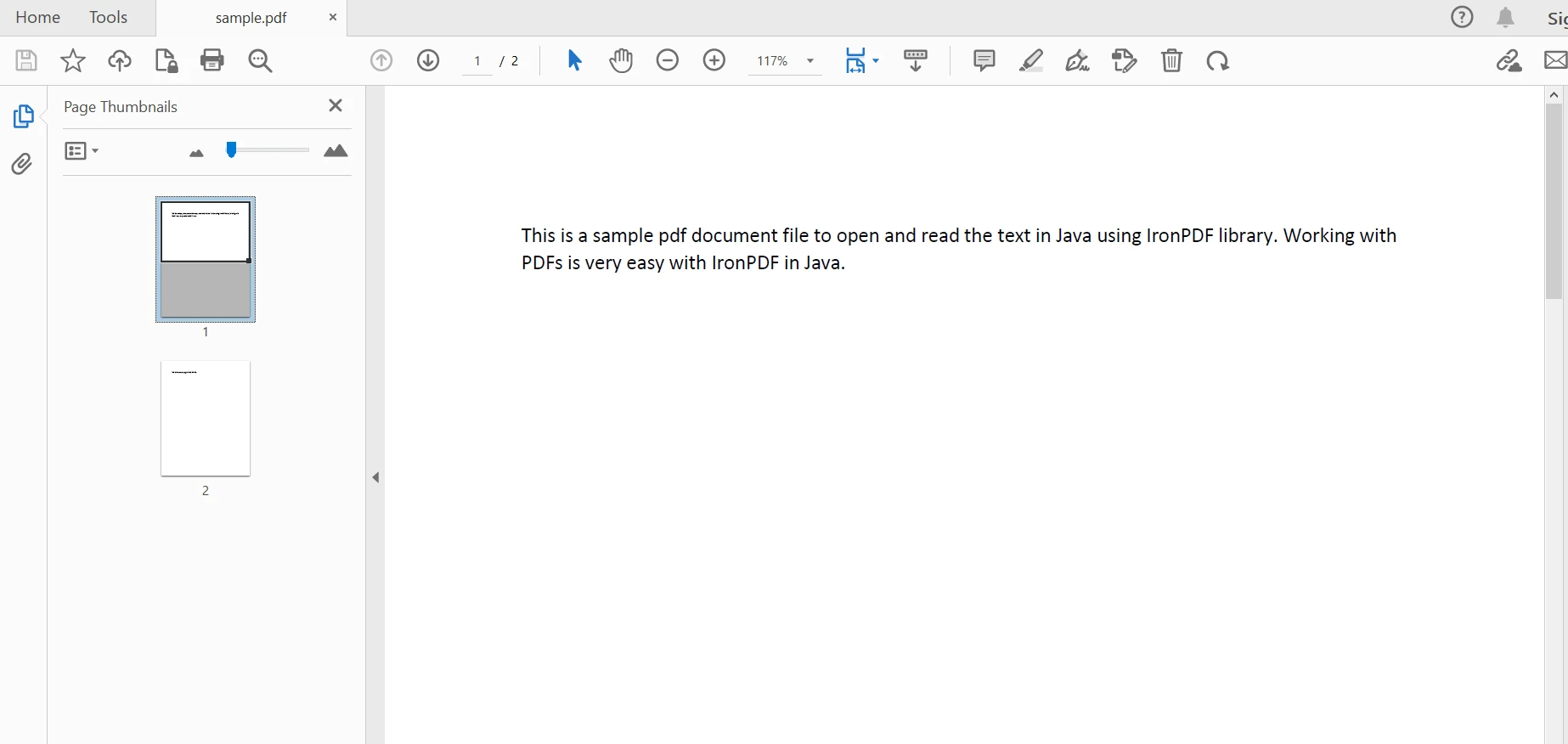 Documento analisado
Documento analisado
Etapa 2: Extrair dados de texto do arquivo PDF analisado
IronPDF for Java oferece um método fácil para extrair texto de documentos PDF . O trecho de código a seguir extrai dados de texto de um arquivo PDF:
String extractedText = parsedDocument.extractAllText();String extractedText = parsedDocument.extractAllText();O código acima produz a saída apresentada abaixo:
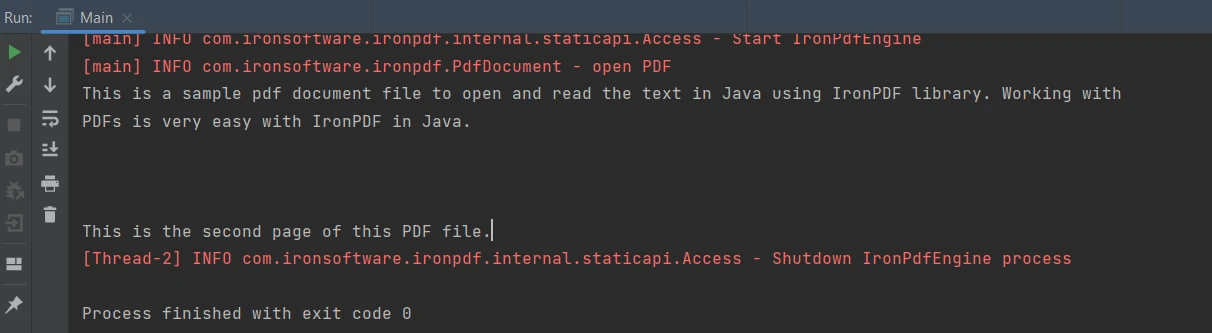 Saída
Saída
Etapa 3: Extrair dados de texto de URLs ou strings HTML
A capacidade do IronPDF for Java não se restringe apenas a PDFs existentes, mas também pode criar e analisar um novo arquivo para extrair conteúdo. Neste tutorial, vamos criar um arquivo PDF a partir de uma URL e extrair o conteúdo dele . O exemplo a seguir mostra como realizar essa tarefa:
public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
String extractedText = parsedDocument.extractAllText();
System.out.println("Text Extracted from URL:\n" + extractedText);
}
}public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
String extractedText = parsedDocument.extractAllText();
System.out.println("Text Extracted from URL:\n" + extractedText);
}
}O resultado é o seguinte:
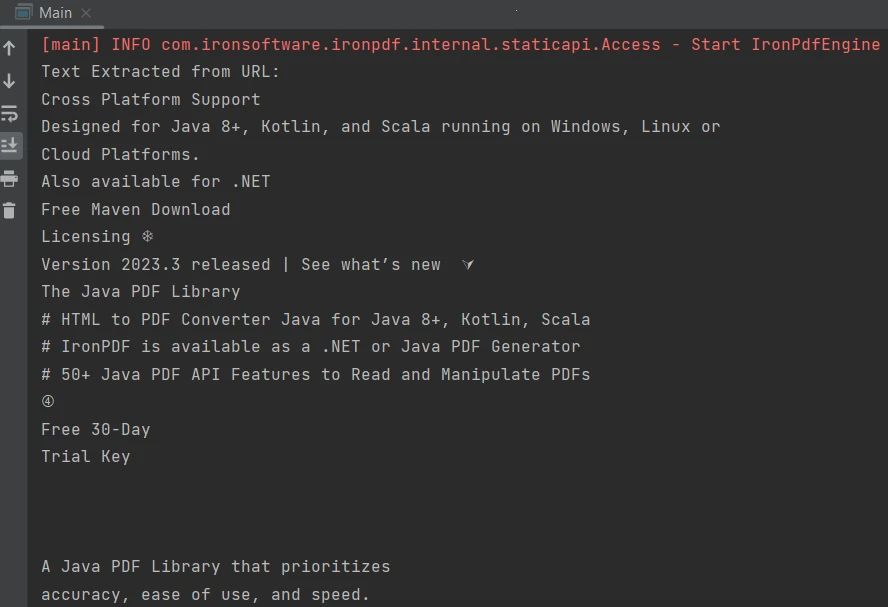 Saída
Saída
Etapa 4: Extrair imagens do documento PDF analisado
O IronPDF também oferece uma opção fácil para extrair todas as imagens de documentos analisados . Neste tutorial, utilizaremos o exemplo anterior para demonstrar a facilidade com que as imagens são extraídas dos arquivos PDF.
import com.ironsoftware.ironpdf.*;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
try {
List<BufferedImage> images = parsedDocument.extractAllImages();
System.out.println("Number of images extracted from the website: " + images.size());
int i = 0;
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("assets/extracted_" + ++i + ".png")));
}
} catch (Exception exception) {
System.out.println("Failed to extract images from the website");
exception.printStackTrace();
}
}
}import com.ironsoftware.ironpdf.*;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
try {
List<BufferedImage> images = parsedDocument.extractAllImages();
System.out.println("Number of images extracted from the website: " + images.size());
int i = 0;
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("assets/extracted_" + ++i + ".png")));
}
} catch (Exception exception) {
System.out.println("Failed to extract images from the website");
exception.printStackTrace();
}
}
}The [extractAllImages](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllImages() method returns a list of BufferedImages. Cada BufferedImage pode então ser armazenado como imagens PNG em um local usando o método ImageIO.write. O arquivo PDF analisado contém 34 imagens e todas foram extraídas perfeitamente.
 Imagens extraídas
Imagens extraídas
Etapa 5: Extrair dados da tabela em arquivos PDF
Extrair conteúdo de limites tabulares em um arquivo PDF é facilitado com apenas uma linha de código usando o extractAllText method. O trecho de código a seguir demonstra como extrair texto de uma tabela em um arquivo PDF:
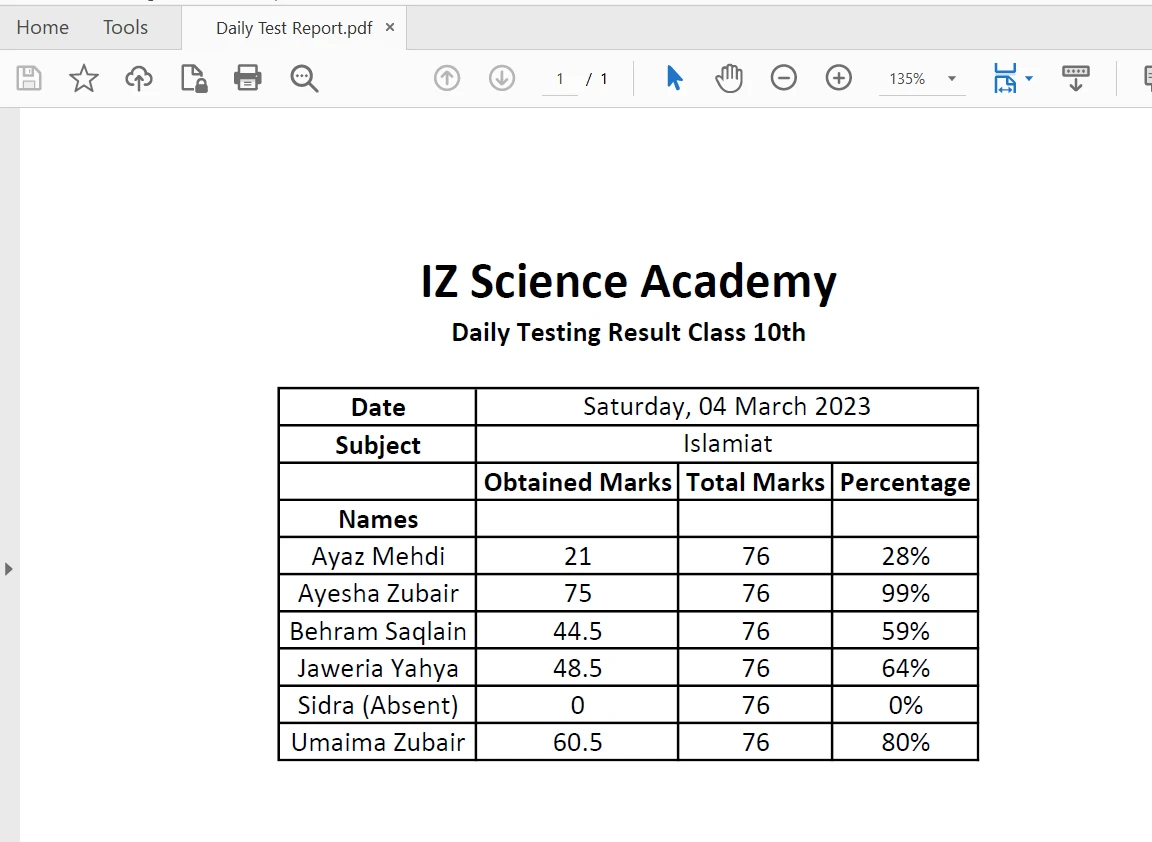 Tabela em PDF
Tabela em PDF
PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("table.pdf"));
String extractedText = parsedDocument.extractAllText();
System.out.println(extractedText);PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("table.pdf"));
String extractedText = parsedDocument.extractAllText();
System.out.println(extractedText);O resultado é o seguinte:
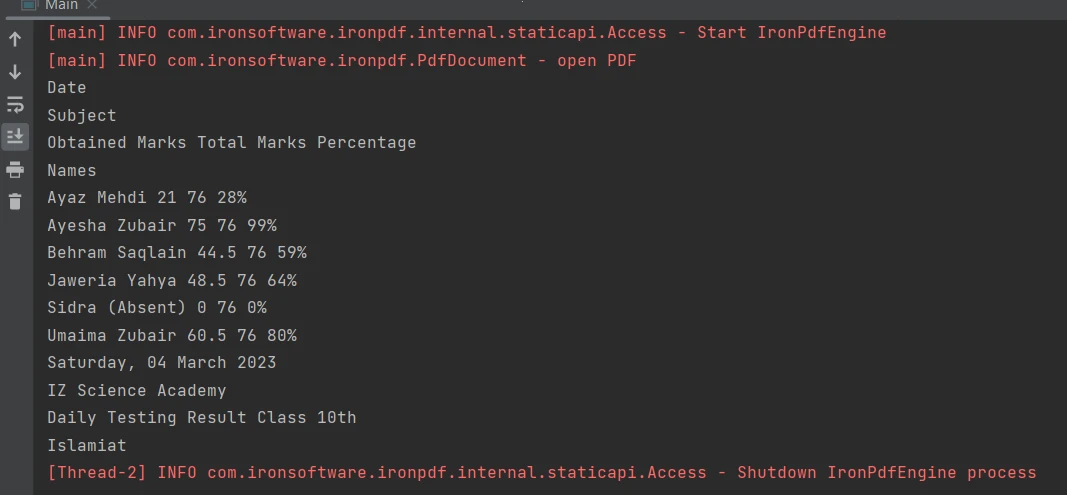 Saída
Saída
Conclusão
Este artigo demonstrou como analisar um documento PDF existente ou criar um novo arquivo de análise de PDF a partir de uma URL para extrair dados dele em Java usando o IronPDF. Após abrir o arquivo, ele pode extrair dados tabulares, imagens e texto do PDF, e também pode adicionar o texto extraído a um arquivo de texto para uso posterior.
Para obter informações mais detalhadas sobre como trabalhar com arquivos PDF programaticamente em Java, visite estes exemplos de criação de arquivos PDF .
A biblioteca IronPDF for Java é gratuita para fins de desenvolvimento, com uma versão de avaliação gratuita disponível . No entanto, para uso comercial, pode ser licenciado através da Iron Software, a partir de $999.
Perguntas frequentes
Como faço para criar um analisador de PDF em Java?
Para criar um analisador de PDF em Java, você pode usar a biblioteca IronPDF. Comece baixando e instalando o IronPDF e, em seguida, carregue seu documento PDF usando o método fromFile . Você pode extrair texto e imagens usando os métodos extractAllText e extractAllImages respectivamente.
O IronPDF pode ser usado com Java 8 ou superior?
Sim, o IronPDF é compatível com Java 8 e versões superiores, bem como com Scala e Kotlin. Ele suporta múltiplas plataformas, incluindo Windows, Linux e ambientes em nuvem.
Quais são os principais passos para analisar PDFs usando o IronPDF em Java?
As etapas principais incluem configurar um projeto Maven, adicionar a dependência IronPDF, carregar um documento PDF com fromFile , extrair o texto usando extractAllText e extrair as imagens usando extractAllImages .
Como posso converter uma URL em PDF em Java?
Você pode converter uma URL em PDF em Java usando o método renderUrlAsPdf do IronPDF. Isso permite renderizar páginas da web como documentos PDF de forma eficiente.
O IronPDF é adequado para aplicações Java baseadas na nuvem?
Sim, o IronPDF foi projetado para ser versátil e oferece suporte a ambientes baseados em nuvem, tornando-o adequado para o desenvolvimento de aplicativos Java que exigem funcionalidades de PDF na nuvem.
Como gerenciar as dependências em um projeto Java de análise de PDF?
Para gerenciar dependências em um projeto Java, você pode usar o Maven. Adicione a biblioteca IronPDF ao arquivo pom.xml do seu projeto para incluí-la como uma dependência.
Quais são as opções de licenciamento disponíveis para o IronPDF?
O IronPDF oferece um período de avaliação gratuito para fins de desenvolvimento. No entanto, para uso comercial, é necessária uma licença. Isso garante acesso a todos os recursos e suporte prioritário.

















