
Wie man PDFs in Java parst (Entwickler-Tutorial)
Dieser Artikel wird in Java einen PDF-Parser mit der IronPDF-Bibliothek auf effiziente Weise erstellen.
IronPDF - Java PDF-Bibliothek
IronPDF für Java ist eine Java-PDF-Bibliothek, die das Erstellen, Lesen und Manipulieren von PDF-Dokumenten unkompliziert und präzise ermöglicht. Es basiert auf dem Erfolg von IronPDF for .NET und bietet effiziente Funktionalität auf verschiedenen Plattformen. IronPDF for Java nutzt den IronPdfEngine , der schnell und auf Leistung optimiert ist.
Mit IronPDF können Sie Text und Bilder aus PDF-Dateien extrahieren und es ermöglicht auch das Erstellen von PDFs aus verschiedenen Quellen, einschließlich HTML-Strings, Dateien, URLs und Bildern. Darüber hinaus können Sie problemlos neue Inhalte hinzufügen, Signaturen mit IronPDF einfügen und Metadaten in PDF-Dokumente einbetten. IronPDF ist speziell für Java 8+, Scala und Kotlin entwickelt und ist kompatibel mit Windows-, Linux- und Cloud-Plattformen.
Wie man eine PDF-Datei in Java parst
- Herunterladen der Java-Bibliothek zum Parsen einer PDF-Datei
- Laden eines vorhandenen PDF-Dokuments mit der Methode `fromFile`
- Extrahieren Sie den gesamten Text aus der geparsten PDF-Datei mit der Methode `extractAllText`
- Verwenden Sie die Methode `renderUrlAsPdf`, um eine PDF-Datei aus einer URL zu rendern
- Extrahieren von Bildern aus der geparsten PDF-Datei mit der Methode `extractAllImages`
Erstellen eines PDF-Datei-Parsers mit IronPDF im Java-Programm
Voraussetzungen
Um ein PDF-Parsing-Projekt in Java zu erstellen, benötigen Sie die folgenden Werkzeuge:
- Java-IDE: Sie können jede Java-kompatible IDE verwenden. Für die Entwicklung stehen zahlreiche Java-IDEs zur Verfügung. In diesem Tutorial wird die IntelliJ IDE verwendet. Sie können NetBeans, Eclipse usw. verwenden.
- Maven-Projekt: Maven ist ein Abhängigkeitsmanager und ermöglicht die Kontrolle über das Java-Projekt. Maven für Java kann von der offiziellen Maven-Website heruntergeladen werden. Die IntelliJ Java IDE hat integrierte Unterstützung für Maven.
-
IronPDF - Sie können IronPDF for Java auf verschiedene Weise herunterladen und installieren.
-
Hinzufügen der IronPDF Abhängigkeit in der Datei
pom.xmlin einem Maven -Projekt.<dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>[LATEST_VERSION]</version> </dependency><dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>[LATEST_VERSION]</version> </dependency>XML - Besuchen Sie die Maven-Repository-Website für das neueste IronPDF-Paket für Java.
- Ein direkter Download von der offiziellen Iron Software Download-Seite.
- Manuell mit der JAR-Datei in Ihrer einfachen Java-Anwendung installieren.
-
-
Slf4j-Simple: Diese Abhängigkeit wird auch benötigt, um einem bestehenden Dokument Inhalte hinzuzufügen. Es kann über den Maven Abhängigkeitsmanager in IntelliJ hinzugefügt oder direkt von der Maven Website heruntergeladen werden. Fügen Sie die folgende Abhängigkeit zur Datei
pom.xmlhinzu:<dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-simple</artifactId> <version>2.0.5</version> </dependency><dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-simple</artifactId> <version>2.0.5</version> </dependency>XML
Hinzufügen der notwendigen Importe
Sobald alle Voraussetzungen installiert sind, ist der erste Schritt, die notwendigen IronPDF-Pakete zu importieren, um mit einem PDF-Dokument zu arbeiten. Fügen Sie den folgenden Code am Anfang der Datei Main.java ein:
import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;Lizenzschlüssel
Einige in IronPDF verfügbare Methoden erfordern eine Lizenz zur Nutzung. Erwerben Sie eine Lizenz oder testen Sie IronPDF kostenlos. Sie können den Schlüssel wie folgt festlegen:
License.setLicenseKey("YOUR-KEY");License.setLicenseKey("YOUR-KEY");Schritt 1: Parsen eines bestehenden PDF-Dokuments
Zum Parsen eines bestehenden Dokuments zur Inhaltsextraktion wird die Klasse PdfDocument verwendet. Seine statische Methode fromFile wird verwendet, um eine PDF-Datei von einem bestimmten Pfad mit einem bestimmten Dateinamen in einem Java-Programm zu parsen. Der Code sieht wie folgt aus:
PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("sample.pdf"));PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("sample.pdf"));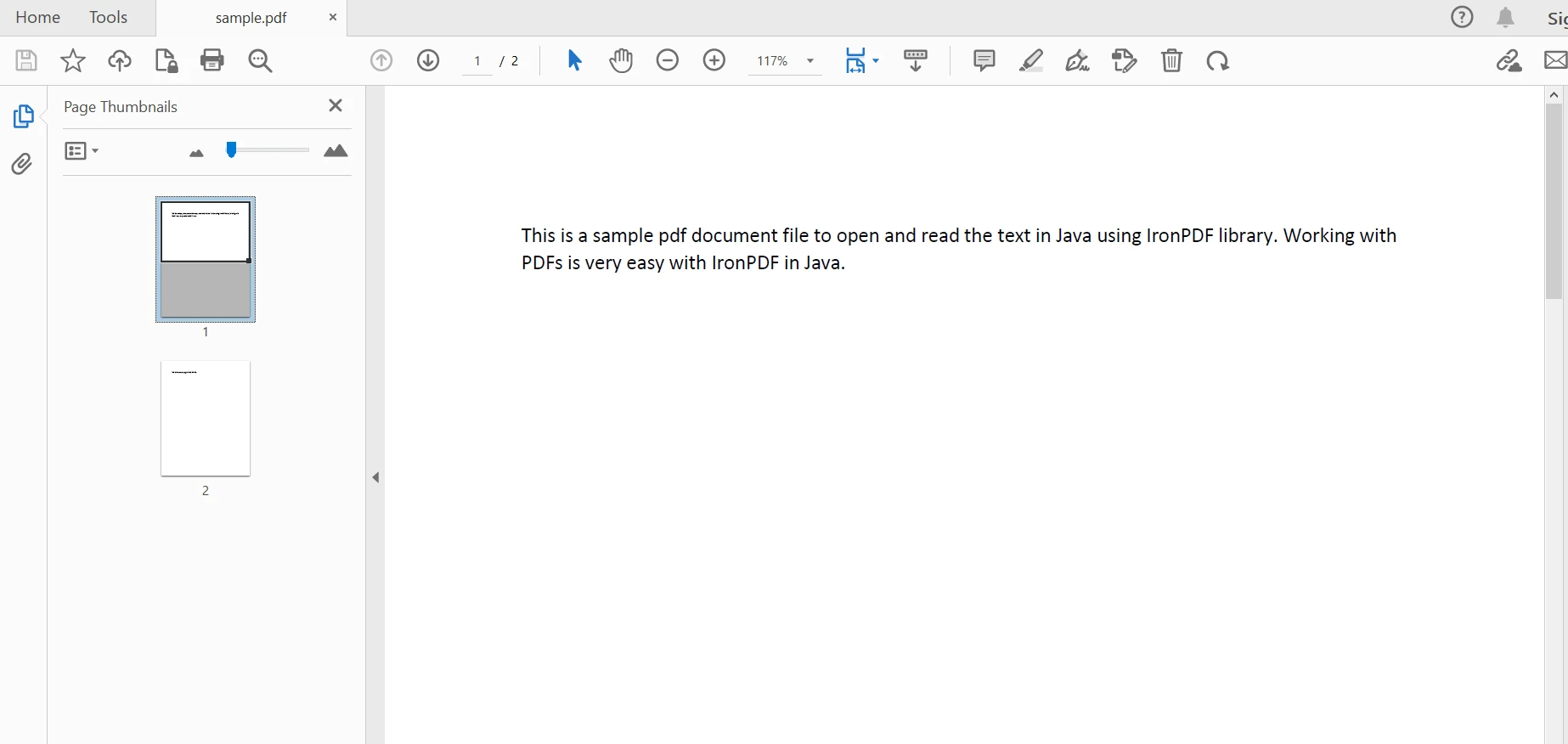 Geparstes Dokument
Geparstes Dokument
Schritt 2: Extrahieren von Textdaten aus geparster PDF-Datei
IronPDF for Java bietet eine einfache Methode zum Extrahieren von Text aus PDF-Dokumenten. Der folgende Codeausschnitt zeigt, wie Textdaten aus einer PDF-Datei extrahiert werden:
String extractedText = parsedDocument.extractAllText();String extractedText = parsedDocument.extractAllText();Der obige Code führt zu dem unten angegebenen Ergebnis:
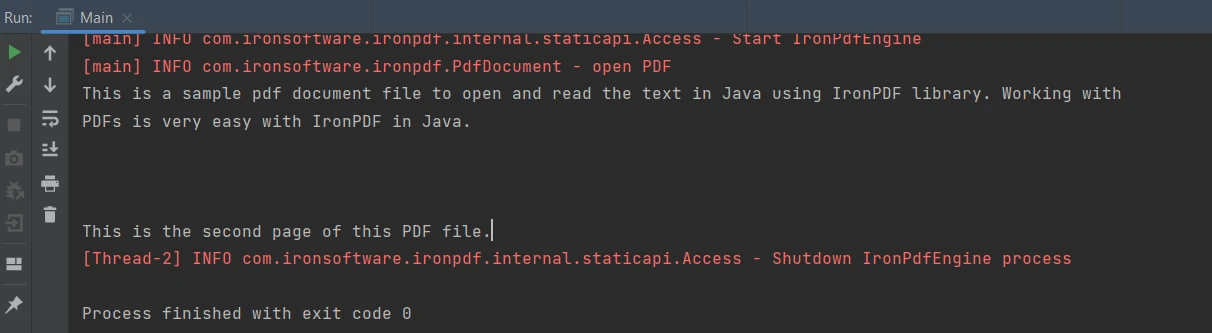 Ausgabe
Ausgabe
Schritt 3: Extrahieren von Textdaten aus URLs oder HTML-Strings
Die Fähigkeit von IronPDF for Java ist nicht nur auf bestehende PDFs beschränkt, sondern es kann auch eine neue Datei erstellen und parsen, um Inhalte zu extrahieren. Hier wird in diesem Tutorial eine PDF-Datei aus einer URL erstellt und Inhalte daraus extrahiert. Das folgende Beispiel zeigt, wie diese Aufgabe erreicht werden kann:
public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
String extractedText = parsedDocument.extractAllText();
System.out.println("Text Extracted from URL:\n" + extractedText);
}
}public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
String extractedText = parsedDocument.extractAllText();
System.out.println("Text Extracted from URL:\n" + extractedText);
}
}Das Ergebnis ist wie folgt:
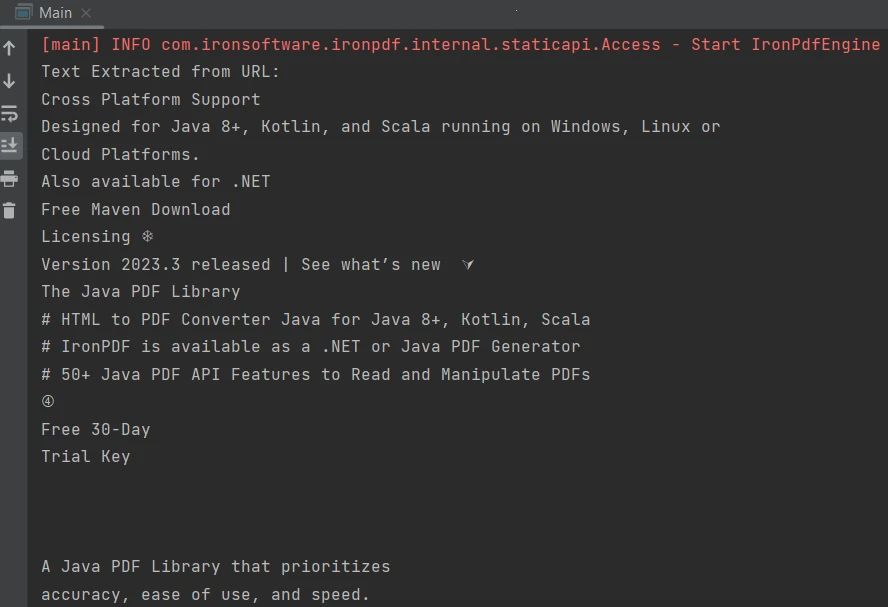 Ausgabe
Ausgabe
Schritt 4: Bilder aus geparstem PDF-Dokument extrahieren
IronPDF bietet auch eine einfache Option, um alle Bilder aus geparsten Dokumenten zu extrahieren. Hier wird das Tutorial das vorherige Beispiel verwenden, um zu sehen, wie leicht die Bilder aus den PDF-Dateien extrahiert werden.
import com.ironsoftware.ironpdf.*;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
try {
List<BufferedImage> images = parsedDocument.extractAllImages();
System.out.println("Number of images extracted from the website: " + images.size());
int i = 0;
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("assets/extracted_" + ++i + ".png")));
}
} catch (Exception exception) {
System.out.println("Failed to extract images from the website");
exception.printStackTrace();
}
}
}import com.ironsoftware.ironpdf.*;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
License.setLicenseKey("YOUR-KEY");
PdfDocument parsedDocument = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
try {
List<BufferedImage> images = parsedDocument.extractAllImages();
System.out.println("Number of images extracted from the website: " + images.size());
int i = 0;
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Paths.get("assets/extracted_" + ++i + ".png")));
}
} catch (Exception exception) {
System.out.println("Failed to extract images from the website");
exception.printStackTrace();
}
}
}Die Methode [extractAllImages](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllImages() ) gibt eine Liste von BufferedImages zurück. Jedes BufferedImage kann dann mithilfe der ImageIO.write-Methode als PNG-Bild an einem Speicherort gespeichert werden. Es gibt 34 Bilder in der geparsten PDF-Datei und jedes Bild wird perfekt extrahiert.
 Extrahierte Bilder
Extrahierte Bilder
Schritt 5: Extrahieren von Daten aus Tabellen in PDF-Dateien
Das Extrahieren von Inhalten aus Tabellengrenzen in einer PDF-Datei wird durch die Verwendung der [Methode extractAllText](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllText() mit nur einer Codezeile vereinfacht. Der folgende Codeausschnitt zeigt, wie Text aus einer Tabelle in einer PDF-Datei extrahiert wird:
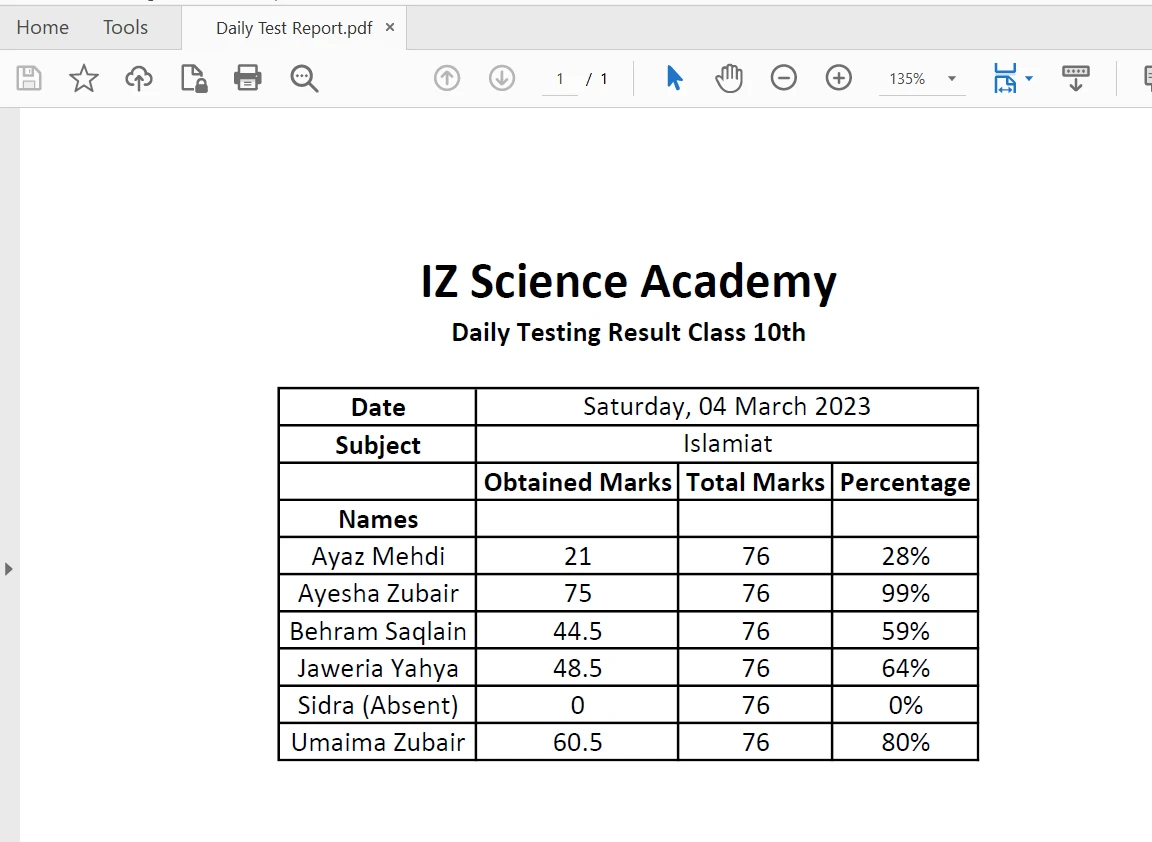 Tabelle in PDF
Tabelle in PDF
PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("table.pdf"));
String extractedText = parsedDocument.extractAllText();
System.out.println(extractedText);PdfDocument parsedDocument = PdfDocument.fromFile(Paths.get("table.pdf"));
String extractedText = parsedDocument.extractAllText();
System.out.println(extractedText);Das Ergebnis ist wie folgt:
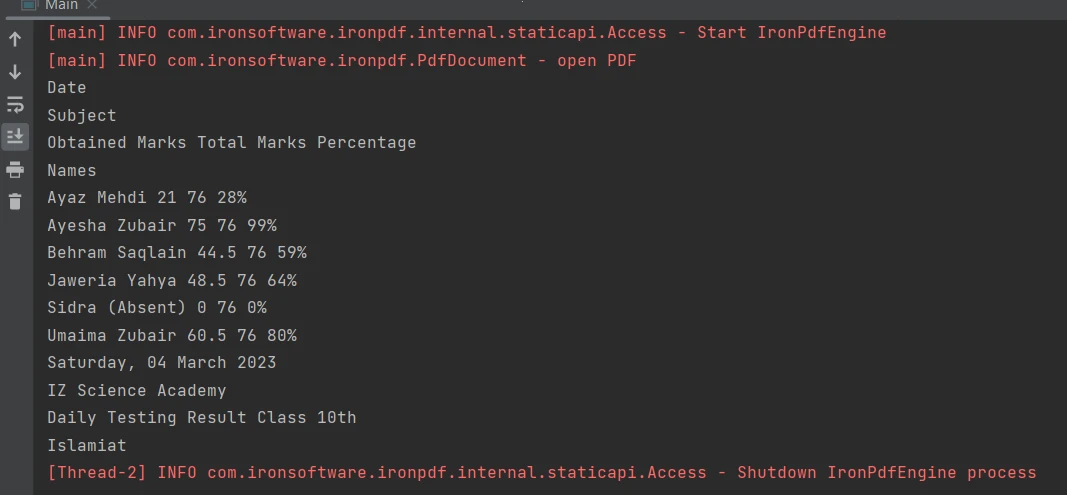 Ausgabe
Ausgabe
Abschluss
Dieser Artikel zeigte, wie man ein bestehendes PDF-Dokument parst oder eine neue PDF-Parser-Datei aus einer URL erstellt, um Daten daraus in Java mit IronPDF zu extrahieren. Nach dem Öffnen der Datei können tabellare Daten, Bilder und Text aus dem PDF extrahiert und der extrahierte Text in eine Textdatei für eine spätere Verwendung eingefügt werden.
Für ausführlichere Informationen darüber, wie man programmatisch mit PDF-Dateien in Java arbeitet, besuchen Sie bitte diese Beispiele zur PDF-Dateierstellung.
Die IronPDF for Java-Bibliothek ist für Entwicklungszwecke mit einer kostenlosen Testversion verfügbar. Für die kommerzielle Nutzung kann es jedoch über IronSoftware lizenziert werden, beginnend mit $999.
Häufig gestellte Fragen
Wie erstelle ich einen PDF-Parser in Java?
Um einen PDF-Parser in Java zu erstellen, können Sie die IronPDF-Bibliothek verwenden. Beginnen Sie mit dem Herunterladen und Installieren von IronPDF, laden Sie dann Ihr PDF-Dokument mit der Methode fromFile. Sie können Texte und Bilder mit den Methoden extractAllText und extractAllImages extrahieren.
Kann IronPDF mit Java 8+ verwendet werden?
Ja, IronPDF ist kompatibel mit Java 8 und höher sowie mit Scala und Kotlin. Es unterstützt mehrere Plattformen, einschließlich Windows, Linux und Cloud-Umgebungen.
Was sind die wichtigsten Schritte zum Parsen von PDFs mit IronPDF in Java?
Wichtige Schritte umfassen das Einrichten eines Maven-Projekts, das Hinzufügen der IronPDF-Abhängigkeit, das Laden eines PDF-Dokuments mit fromFile, das Extrahieren von Text mit extractAllText und das Extrahieren von Bildern mit extractAllImages.
Wie kann ich eine URL in ein PDF in Java umwandeln?
Sie können eine URL in ein PDF in Java umwandeln, indem Sie die renderUrlAsPdf-Methode von IronPDF verwenden. Dies ermöglicht Ihnen, Webseiten effizient als PDF-Dokumente zu rendern.
Ist IronPDF für Cloud-basierte Java-Anwendungen geeignet?
Ja, IronPDF ist so konzipiert, dass es vielseitig ist und unterstützt Cloud-basierte Umgebungen, was es geeignet für die Entwicklung von Java-Anwendungen macht, die PDF-Funktionalitäten in der Cloud erfordern.
Wie verwalte ich Abhängigkeiten für ein Java-PDF-Parsing-Projekt?
Zum Verwalten von Abhängigkeiten in einem Java-Projekt können Sie Maven verwenden. Fügen Sie die IronPDF-Bibliothek zur pom.xml-Datei Ihres Projekts hinzu, um sie als Abhängigkeit einzuschließen.
Welche Lizenzoptionen gibt es für IronPDF?
IronPDF bietet eine kostenlose Testversion für Entwicklungszwecke an. Für den kommerziellen Gebrauch ist jedoch eine Lizenz erforderlich. Dies gewährleistet den Zugang zu allen Funktionen und Prioritätssupport.

















