
Cómo analizar un documento PDF en Node.js
Este artículo demostrará cómo analizar archivos PDF usando Node.js con la biblioteca de análisis PDF Node.js IronPDF.
¿Qué es Node?
El entorno de ejecución de JavaScript Node.js, multiplataforma y de código abierto, permite que el código JavaScript se ejecute fuera de un navegador web. Los programadores pueden crear aplicaciones de red que sean escalables, rápidas y efectivas al habilitar la ejecución del servidor JS o módulo JavaScript. Debido a que Node.js es un modelo de E/S no bloqueante y basado en eventos, es ideal para desarrollar aplicaciones en tiempo real que gestionan múltiples conexiones a la vez con elementos de formulario interactivos.
Node.js se utiliza con frecuencia para crear una amplia gama de aplicaciones, incluyendo servidores web, APIs, aplicaciones de transmisión de estructuras de datos, aplicaciones de chat en tiempo real, dispositivos de Internet de las Cosas (IoT), y más. Considerando todo, Node.js está creciendo en popularidad debido a su eficacia, velocidad y compatibilidad con JavaScript en tanto el front-end como el back-end, proporcionando un único lenguaje para el desarrollo full-stack. Consulta este sitio web de explicación para páginas de documentación y aprender más sobre Node.js.
Cómo analizar un documento PDF en Node.js
- Para analizar archivos PDF para un flujo legible, descarga el paquete de Node.js.
- Instala IronPDF para la biblioteca Node.js.
- Crea un nuevo PDF o importa uno existente con los datos del documento analizado.
- Para extraer cada línea de texto, utilice el método
extractText. - Ver el contenido del PDF analizado para la lectura cruda del PDF.
IronPDF for Node.js
Hasta mi última actualización de conocimientos en enero de 2022, IronPDF era en gran medida una biblioteca .NET construida para trabajar dentro del .NET Framework, permitiendo a los desarrolladores trabajar con documentos PDF usando C# o VB.NET. Sin embargo, no había una versión nativa o directa de IronPDF creada solo for Node.js.
A medida que IronPDF se ha expandido para soportar e incluir enlaces for Node.js, esto probablemente significa que las herramientas para crear, editar y procesar documentos PDF en aplicaciones Node.js ya están disponibles en IronPDF for Node.js.
Características de IronPDF
- Generación de HTML a PDF: La capacidad de convertir contenido HTML en documentos PDF.
- La adición, alteración o eliminación de texto, formas, imágenes y otros elementos de archivos PDF se denomina manipulación de texto e imagen.
- Combinación, extracción de páginas de archivos PDF, división de archivos PDF, y cifrado y descifrado de los mismos son todos ejemplos de alteración de documentos PDF.
- Manejo de formularios abarca completar formularios, adquirir datos de formularios y utilizar formularios PDF a través de la programación.
- La seguridad de PDF es el uso de firmas digitales, cifrado y protección por contraseña para los documentos PDF.
- La recuperación y modificación de archivos PDF se conoce como manejo de metadatos de página.
Si IronPDF ha expandido su gama de productos para incluir una versión de Node.js, esto podría proporcionar una forma para que los desarrolladores que crean aplicaciones Node.js utilicen la funcionalidad de manipulación de PDF de IronPDF. Esto podría ser útil para los desarrolladores que prefieren trabajar con una biblioteca que ofrece características similares a las de IronPDF en el entorno .NET.
La documentación oficial, las notas de lanzamiento o las actualizaciones del equipo de IronPDF deben ser consultadas siempre para obtener la información más actualizada sobre las características, compatibilidad y soporte de IronPDF for Node.js. Ve aquí para aprender más sobre IronPDF y las nuevas características en cada lanzamiento. Para saber más sobre IronPDF, consulta esta página de documentación oficial.
Requisitos del paquete
- Visual Studio Code como IDE
- Node.js
- Yarn o npm pueden ser usados para la gestión de paquetes, lo cual es necesario para las instalaciones de paquetes.
Instalar el paquete IronPDF for Node.js
Lanza el Símbolo del sistema o Terminal: Abre el símbolo del sistema o terminal. Existen varias maneras de acceder dependiendo de tu sistema operativo:
- Windows: PowerShell o Símbolo del sistema
- Terminal en macOS
- Terminal en Linux
Para instalar un paquete, usa el nombre del paquete y el comando npm install. Por ejemplo, para instalar el paquete @ironsoftware/ironpdf, ejecute el siguiente comando en la terminal:
npm install @ironsoftware/ironpdfnpm install @ironsoftware/ironpdfReemplace @ironsoftware/ironpdf con el nombre del paquete que desea instalar si es diferente.
 Instalar IronPDF
Instalar IronPDF
Extraer datos de un archivo PDF
A partir de la experimentación, puedes ver que IronPDF ofrece muchas funciones para facilitar el manejo de PDF en Node.js. Está enfocado en generar, ver y modificar cualquier documento PDF en los formatos requeridos. Los archivos PDF son bastante simples de analizar.
const { PdfDocument } = require("@ironsoftware/ironpdf");
const pdfProcess = async () => {
// Load the existing PDF document
const pdf = await PdfDocument.fromFile("Demo.pdf");
// Extract text data from the loaded PDF
const data = await pdf.extractText();
// Output the extracted text to the console
console.log(data);
};
pdfProcess();La importancia de la función fromFile queda demostrada por el código anterior. El método fromFile lee documentos PDF y convierte el archivo PDF en objetos PdfDocument , cargando el archivo desde un sistema de archivos existente. Por lo tanto, PdfDocument contiene los metadatos del PDF. Los metadatos del archivo en el objeto PDF pueden ser utilizados como desee el usuario. Este objeto de datos del documento analizado son el texto y los gráficos contenidos dentro del objeto de página PDF. La función extractText se utiliza para extraer todo el texto del archivo PDF proporcionado. Posteriormente, el texto recuperado se almacena como una cadena y se prepara para su posterior procesamiento, como la creación de un formato JSON.
Extracción de texto página por página
A continuación se ofrece el código para otro enfoque, que extrae explícitamente texto de cada página del archivo PDF.
const pdf = await PdfDocument.fromFile("Demo.pdf");
// Get the total number of pages in the PDF
const pageCount = await pdf.getPageCount();
// Loop through each page to extract text
for (let i = 0; i < pageCount; i++) {
const pageText = await pdf.extractText(i);
// Output the text of each page
console.log(pageText);
}La lectura del PDF sin procesar de un PDF que ya está en la memoria se carga desde el directorio especificado en su totalidad mediante este código de muestra, que luego crea un objeto PdfDocument llamado pdf. Un documento PDF es una estructura de datos compuesta por varios tipos de objetos de datos fundamentales. Cada dato de página en el archivo PDF se recupera usando su número de página o índice de página en el objeto PDF para garantizar que se procese uno tras otro. Primero, usamos el método getPageCount de su objeto PDF para encontrar el número total de páginas en el PDF proporcionado.
El bucle for itera a través de cada página usando este conteo de páginas, invocando la función extractText para recuperar texto de cada página PDF. El texto extraído puede mostrarse en la pantalla del usuario o guardarse en una variable de cadena. Esta técnica hace posible extraer texto de páginas PDF individuales de manera organizada. Estas técnicas demuestran cómo IronPDF, una biblioteca de Node.js creada específicamente para tareas PDF, puede extraer fácilmente y de manera exhaustiva texto de archivos PDF. Esta accesibilidad mejora la utilidad de los PDF en una variedad de contextos y tiene numerosas aplicaciones prácticas.
 Leer PDF página por página
Leer PDF página por página
Ambos códigos anteriores logran el mismo resultado, pero la única diferencia está en la implementación del código basada en los requisitos del usuario. Para saber más sobre IronPDF, consulta estas páginas de documentación detallada.
Conclusión
La biblioteca IronPDF ofrece medidas de seguridad robustas para reducir riesgos y garantizar la seguridad de los datos. Es compatible con todos los navegadores populares y no está limitado a ninguno de ellos. Para satisfacer las diversas demandas de los desarrolladores, la biblioteca ofrece una amplia gama de opciones de licencia, incluyendo una licencia de desarrollador gratuita y licencias de desarrollo adicionales que pueden ser compradas.
Además de una licencia permanente, un año de mantenimiento de software y una garantía de devolución de dinero de treinta días, el paquete $799 Lite incluye posibilidades de actualización. Los usuarios tienen la oportunidad de evaluar el producto en circunstancias de aplicación práctica durante el período de prueba con marcas de agua. Por favor, revisa la página de licencias proporcionada para más detalles sobre el coste, licencias, y versión de prueba de IronPDF. Para saber sobre otros productos ofrecidos por Iron Software, visita el sitio web oficial.
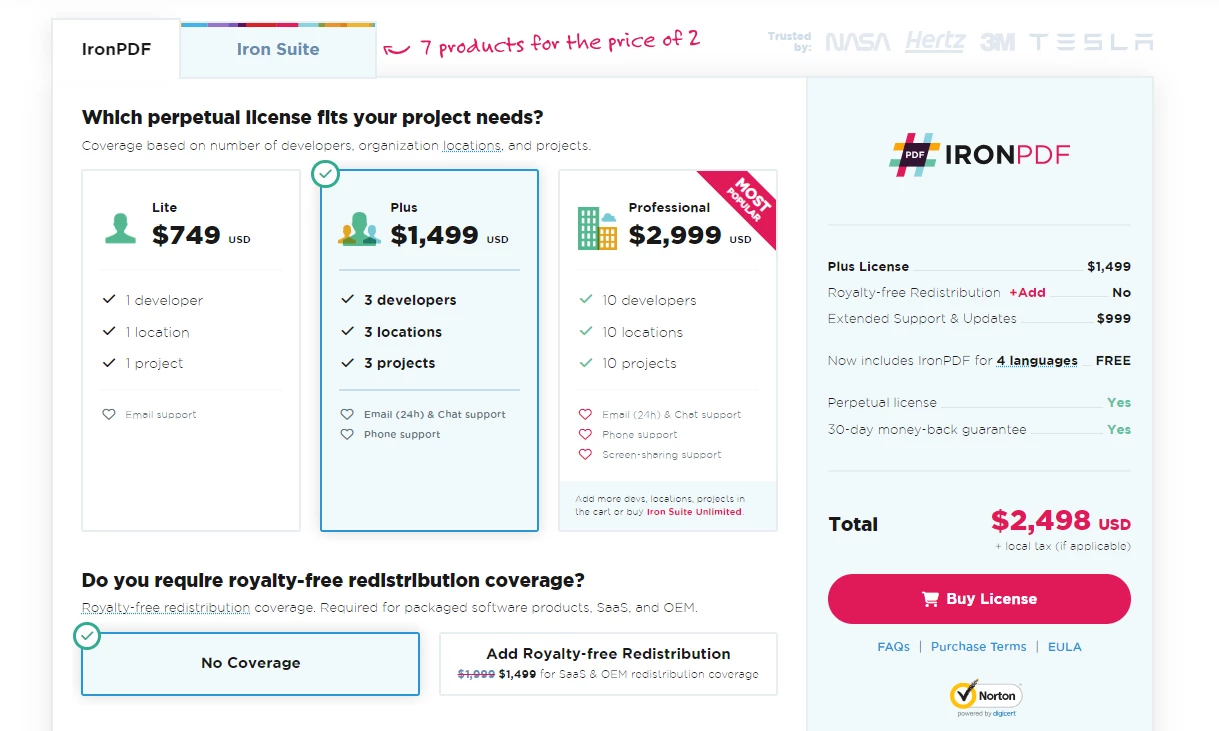 Precios de Iron Software
Precios de Iron Software
Preguntas Frecuentes
¿Cómo analizo un PDF usando Node.js?
Para analizar un PDF usando Node.js, puedes utilizar la biblioteca IronPDF. Comienza instalando el paquete IronPDF con npm install @Iron Software/ironpdf. Luego, carga el PDF con el método fromFile y extrae texto usando el método extractText.
¿Cuáles son los pasos para convertir HTML a PDF en Node.js?
Puedes convertir HTML a PDF en Node.js usando IronPDF. Usa el método RenderHtmlAsPdf para cadenas HTML o RenderHtmlFileAsPdf para archivos HTML para generar PDFs de manera eficiente.
¿Cómo puedo extraer texto de cada página de un PDF usando Node.js?
Con IronPDF, puedes extraer texto de cada página de un PDF iterando a través de las páginas. Usa el método getPageCount para determinar el número de páginas y la función extractText para extraer texto de cada página.
¿Qué características ofrece la biblioteca IronPDF for Node.js?
IronPDF for Node.js ofrece una gama de características que incluyen conversión de HTML a PDF, manipulación de texto e imágenes, combinación y división de PDFs, encriptación, firmas digitales y manejo de formularios.
¿Cómo puedo asegurar la seguridad de los documentos PDF en Node.js?
IronPDF ofrece características de seguridad completas como firmas digitales, encriptación y protección por contraseña para asegurar documentos PDF en aplicaciones de Node.js.
¿Qué debo considerar al elegir una biblioteca de PDF for Node.js?
Al elegir una biblioteca de PDF for Node.js, considera características como compatibilidad con diferentes navegadores, opciones de seguridad, facilidad de uso, documentación completa y flexibilidad de licencias. IronPDF ofrece estas capacidades, lo cual la convierte en una opción fuerte para desarrolladores.
¿Cuáles son las opciones de licencia disponibles para IronPDF en Node.js?
IronPDF ofrece varias opciones de licencia, incluyendo una licencia gratuita para desarrolladores, licencias permanentes y un año de mantenimiento del software. También ofrecen un periodo de prueba con una versión con marca de agua, respondiendo a las diferentes necesidades de los desarrolladores.
¿Es posible manipular imágenes dentro de PDFs usando Node.js?
Sí, con IronPDF puedes manipular imágenes dentro de PDFs en aplicaciones Node.js. Esto incluye añadir, extraer o modificar imágenes incrustadas en documentos PDF.















