
Node.js에서 PDF 문서를 파싱하는 방법
이 글에서는 Node.js 용 PDF 파서 라이브러리인 IronPDF 를 사용하여 Node.js 로 PDF 파일을 파싱하는 방법을 설명합니다.
Node란 무엇인가요?
크로스 플랫폼 오픈 소스 Node.js JavaScript 런타임 환경을 사용하면 JavaScript 코드를 웹 브라우저 외부에서 실행할 수 있습니다. 프로그래머는 서버 측 JavaScript 또는 JS 모듈 실행을 활성화함으로써 확장 가능하고 빠르며 효율적인 네트워크 애플리케이션을 만들 수 있습니다. Node.js 는 이벤트 기반의 비동기 I/O 모델이기 때문에, 상호 작용 가능한 폼 요소를 사용하여 여러 연결을 동시에 관리하는 실시간 애플리케이션 개발에 이상적입니다.
Node.js 는 웹 서버, API, 데이터 구조 스트리밍 애플리케이션, 실시간 채팅 애플리케이션, 사물 인터넷(IoT) 장치 등 다양한 애플리케이션을 개발하는 데 널리 사용됩니다. 종합적으로 볼 때, Node.js 효율성, 속도, 그리고 프런트엔드와 백엔드 모두에서 JavaScript 호환성 덕분에 인기를 얻고 있으며, 풀스택 개발을 위한 단일 언어를 제공합니다. Node.js 에 대해 더 자세히 알아보려면 이 설명 웹사이트 의 문서 페이지를 참조하세요.
Node.js 에서 PDF 문서를 파싱하는 방법
- PDF 파일을 읽기 쉬운 스트림으로 파싱하려면 Node.js 패키지를 다운로드하세요.
- Node.js 용 IronPDF 라이브러리를 설치하세요.
- 파싱된 문서 데이터를 사용하여 새 PDF를 생성하거나 기존 PDF를 가져옵니다.
- 모든 텍스트 줄을 추출하려면
extractText메서드를 사용하세요. - 구문 분석된 PDF 콘텐츠를 보려면 원본 PDF를 읽으십시오.
Node.js 용 IronPDF
제가 마지막으로 정보를 업데이트한 2022년 1월 기준으로, IronPDF 주로 .NET Framework 내에서 작동하도록 구축된 .NET 라이브러리였으며, 개발자들이 C# 또는 VB .NET 사용하여 PDF 문서를 다룰 수 있도록 했습니다. 하지만 Node.js 전용으로 제작된 IronPDF 의 네이티브 버전이나 직접적인 버전은 없었습니다.
IronPDF Node.js 용 바인딩을 지원하고 포함하도록 확장됨에 따라, Node.js 애플리케이션에서 PDF 문서를 생성, 편집 및 처리하는 도구가 이제 Node.js 용 IronPDF 에서 사용 가능해졌을 가능성이 높습니다.
IronPDF 의 특징
- HTML을 PDF로 변환 : HTML 콘텐츠를 PDF 문서로 변환하는 기능. PDF 파일에서 텍스트, 도형, 이미지 및 기타 요소를 추가, 변경 또는 제거하는 것을 텍스트 및 이미지 조작 이라고 합니다. PDF 파일을 결합하거나 , 페이지를 추출하거나, 분할하거나 , 암호화 및 복호화하는 것은 모두 PDF 문서 변경의 예입니다.
- 양식 처리에는 양식 작성, 양식 데이터 수집, 프로그래밍을 통한 PDF 양식 활용 등이 포함됩니다.
- PDF 보안이란 PDF 문서에 디지털 서명 , 암호화 및 암호 보호를 사용하는 것을 의미합니다. PDF 파일을 검색하고 수정하는 것을 페이지 메타데이터 처리라고 합니다.
IronPDF 제품군을 확장하여 Node.js 버전을 포함하게 된다면, Node.js 앱을 개발하는 개발자들이 IronPDF의 PDF 조작 기능을 사용할 수 있는 길이 열릴 것입니다. 이는 .NET 환경에서 IronPDF 와 유사한 기능을 제공하는 라이브러리를 사용하려는 개발자에게 유용할 수 있습니다.
IronPDF의 기능, 호환성 및 Node.js 지원과 관련된 최신 정보는 IronPDF 팀의 공식 문서, 릴리스 노트 또는 업데이트를 참조해야 합니다. IronPDF 및 각 릴리스의 새로운 기능에 대한 자세한 내용을 알아보려면 여기를 클릭하십시오. IronPDF 에 대한 자세한 내용은 이 공식 문서 페이지를 참조하십시오.
패키지 요구 사항
- IDE로는 Visual Studio Code를 사용합니다.
- Node.js
- 패키지 관리에는 Yarn 또는 npm을 사용할 수 있으며, 이는 Install-Package에 필수적입니다.
Node.js 용 IronPDF 패키지를 설치하세요.
명령 프롬프트 또는 터미널 실행: 명령 프롬프트 또는 터미널을 엽니다. 사용하는 운영체제에 따라 접근 방법이 다양합니다.
- Windows: PowerShell 또는 명령 프롬프트 macOS 터미널
- 리눅스 터미널
패키지를 설치하려면 패키지 이름과 npm install 명령어를 사용하세요. 예를 들어, 패키지 @ironsoftware/ironpdf을(를) 설치하려면 터미널에서 다음 명령어를 실행하세요.
npm과 @ironsoftware/ironpdf
설치하려는 패키지가 다를 경우 @ironsoftware/ironpdf을(를) 원하는 패키지 이름으로 대체하세요.
 IronPDF 설치하세요
IronPDF 설치하세요
PDF 파일 분석하여 데이터 추출
직접 실험해 보면 IronPDF Node.js 에서 PDF를 다루는 데 도움이 되는 다양한 기능을 제공한다는 것을 알 수 있습니다. 이 프로그램은 필요한 형식으로 모든 PDF 문서를 생성, 보고, 수정하는 데 중점을 두고 있습니다. PDF 파일은 분석하기가 상당히 간단합니다.
const { PdfDocument } = require("@ironsoftware/ironpdf");
const pdfProcess = async () => {
// Load the existing PDF document
const pdf = await PdfDocument.fromFile("Demo.pdf");
// Extract text data from the loaded PDF
const data = await pdf.extractText();
// Output the extracted text to the console
console.log(data);
};
pdfProcess();위의 코드는 fromFile 함수의 중요성을 보여줍니다. fromFile 메서드는 PDF 문서를 읽고, 기존 파일 시스템에서 파일을 로드하여 PDF 파일을 PdfDocument 객체로 변환합니다. 따라서 PdfDocument은(는) PDF의 메타데이터를 보유합니다. PDF 객체의 파일 메타데이터는 사용자가 원하는 대로 사용할 수 있습니다. 이 객체에서 파싱된 문서 데이터는 PDF 페이지 객체에 포함된 텍스트와 그래픽입니다. extractText 함수는 제공된 PDF 파일에서 모든 텍스트를 추출하는 데 사용됩니다. 그런 다음 추출된 텍스트는 문자열로 저장되며, JSON 형식 만들기와 같은 추가 처리를 위해 준비됩니다.
페이지별 텍스트 추출
다음은 PDF 파일의 각 페이지에서 텍스트를 명시적으로 추출하는 또 다른 접근 방식의 코드입니다.
const pdf = await PdfDocument.fromFile("Demo.pdf");
// Get the total number of pages in the PDF
const pageCount = await pdf.getPageCount();
// Loop through each page to extract text
for (let i = 0; i < pageCount; i++) {
const pageText = await pdf.extractText(i);
// Output the text of each page
console.log(pageText);
}이 샘플 코드는 메모리에 이미 있는 PDF의 원시 PDF 읽기를 지정된 디렉토리에서 완전하게 로드한 다음, pdf이라는 이름의 PdfDocument 객체를 생성합니다. PDF 문서는 여러 기본 데이터 객체 유형으로 구성된 데이터 구조입니다. PDF 파일의 모든 페이지 데이터는 PDF 객체 내의 페이지 번호 또는 페이지 인덱스를 사용하여 순차적으로 처리되도록 검색됩니다. 먼저, PDF 객체의 getPageCount 메서드를 사용하여 제공된 PDF의 전체 페이지 수를 찾습니다.
for 루프는 이 페이지 수를 사용하여 각 페이지를 반복하며, extractText 함수를 호출하여 각 PDF 페이지에서 텍스트를 가져옵니다. 추출된 텍스트는 사용자의 화면에 표시되거나 문자열 변수에 저장될 수 있습니다. 이 기술을 사용하면 개별 PDF 페이지에서 텍스트를 체계적인 방식으로 추출할 수 있습니다. 이러한 기술들은 PDF 작업에 특화된 Node.js 라이브러리인 IronPDF 사용하여 PDF 파일에서 텍스트를 쉽고 완벽하게 추출하는 방법을 보여줍니다. 이러한 접근성은 다양한 맥락에서 PDF의 유용성을 높여주며, 수많은 실용적인 활용 사례를 제공합니다.
 PDF 파일을 페이지별로 읽어보세요.
PDF 파일을 페이지별로 읽어보세요.
위의 두 코드는 모두 동일한 결과를 생성하지만, 사용자 요구 사항에 따라 코드 구현 방식이 다를 뿐입니다. IronPDF 에 대해 더 자세히 알아보려면 이 상세 문서 페이지를 참조하십시오.
결론
IronPDF 라이브러리는 위험을 줄이고 데이터 보안을 보장하기 위해 강력한 보안 조치를 제공합니다. 이 프로그램은 모든 인기 브라우저와 호환되며 특정 브라우저에 국한되지 않습니다. 다양한 개발자들의 요구를 충족시키기 위해, 이 라이브러리는 무료 개발자 라이선스와 추가 개발자 라이선스 구매 옵션을 포함한 폭넓은 라이선스 선택지를 제공합니다.
영구 라이선스, 1년간의 소프트웨어 유지보수, 30일 환불 보장 외에도, $999 Lite 번들은 업그레이드 가능성을 포함합니다. 사용자는 워터마크가 표시된 평가 기간 동안 실제 사용 환경에서 제품을 평가할 수 있는 기회를 갖습니다. IronPDF의 비용, 라이선스 및 평가판에 대한 자세한 내용은 제공된 라이선스 페이지를 참조하십시오. Iron Software 에서 제공하는 다른 제품에 대해 알아보려면 공식 웹사이트를 확인하세요.
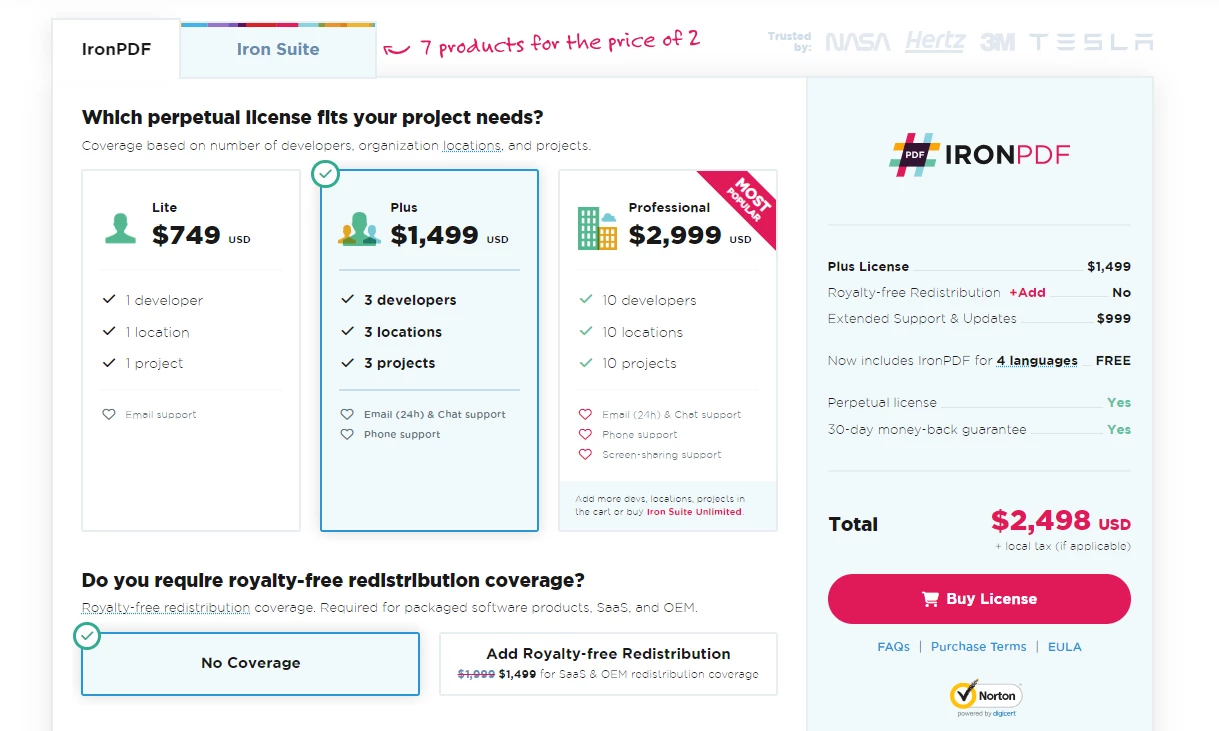 Iron Software 가격
Iron Software 가격
자주 묻는 질문
Node.js를 사용하여 PDF를 파싱하는 방법은 무엇인가요?
Node.js를 사용하여 PDF를 파싱하려면 IronPDF 라이브러리를 활용할 수 있습니다. 먼저 npm install @ironsoftware/ironpdf 명령어로 IronPDF 패키지를 설치하세요. 그런 다음 fromFile 메서드를 사용하여 PDF 파일을 불러오고 extractText 메서드를 사용하여 텍스트를 추출합니다.
Node.js를 사용하여 HTML을 PDF로 변환하는 단계는 무엇인가요?
Node.js 환경에서 IronPDF를 사용하면 HTML을 PDF로 변환할 수 있습니다. HTML 문자열의 경우 RenderHtmlAsPdf 메서드를, HTML 파일의 경우 RenderHtmlFileAsPdf 메서드를 사용하여 효율적으로 PDF를 생성하세요.
Node.js를 사용하여 PDF 파일의 각 페이지에서 텍스트를 추출하는 방법은 무엇인가요?
IronPDF를 사용하면 PDF 파일의 각 페이지를 순회하면서 텍스트를 추출할 수 있습니다. getPageCount 메서드를 사용하여 페이지 수를 확인하고 extractText 함수를 사용하여 각 페이지에서 텍스트를 추출하세요.
IronPDF 라이브러리는 Node.js에서 어떤 기능을 제공하나요?
Node.js용 IronPDF는 HTML을 PDF로 변환, 텍스트 및 이미지 조작, PDF 병합 및 분할, 암호화, 디지털 서명, 양식 처리 등 다양한 기능을 제공합니다.
Node.js 환경에서 PDF 문서의 보안을 어떻게 확보할 수 있을까요?
IronPDF는 디지털 서명, 암호화, 암호 보호와 같은 포괄적인 보안 기능을 제공하여 Node.js 애플리케이션에서 PDF 문서를 안전하게 보호합니다.
Node.js용 PDF 라이브러리를 선택할 때 무엇을 고려해야 할까요?
Node.js용 PDF 라이브러리를 선택할 때는 다양한 브라우저와의 호환성, 보안 옵션, 사용 편의성, 포괄적인 문서, 그리고 유연한 라이선스 정책과 같은 기능을 고려해야 합니다. IronPDF는 이러한 기능을 모두 제공하므로 개발자들에게 강력한 선택지가 될 수 있습니다.
Node.js에서 IronPDF를 사용하기 위한 라이선스 옵션은 무엇인가요?
IronPDF는 무료 개발자 라이선스, 영구 라이선스, 1년 소프트웨어 유지보수 등 다양한 라이선스 옵션을 제공합니다. 또한 개발자의 다양한 요구를 충족하기 위해 워터마크가 포함된 평가판도 제공합니다.
Node.js를 사용하여 PDF 내의 이미지를 조작하는 것이 가능할까요?
네, IronPDF를 사용하면 Node.js 애플리케이션에서 PDF 문서 내 이미지를 조작할 수 있습니다. 여기에는 PDF 문서에 포함된 이미지를 추가, 추출 또는 수정하는 작업이 포함됩니다.















