
pyarrow (Cómo Funciona Para Desarrolladores)
PyArrow es una biblioteca poderosa que propociona una interfaz de Python al marco de Apache Arrow. Apache Arrow es una platafoma de desarrollo multilinguaje para datos en memoia. Especifica un fomato de memoia en columnas estandarizado y independiente del lenguaje para datos planos y jerárquicos, oganizado para operaciones analíticas eficientes en hardware moderno. PyArrow es básicamente las conexiones de Python de Apache Arrow realizadas como un paquete de Python. PyArrow permite un intercambio de datos eficiente y una interoperabilidad entre diferentes sistemas de procesamiento de datos y lenguajes de programación. Más adelante en este artículo, también aprenderemos sobre IronPDF, una biblioteca de generación de PDF desarrollada po Iron Software.
Características principales de PyArrow
Fomato de memoia en columnas:
PyArrow utiliza un fomato de memoia en columnas, que es altamente eficiente para operaciones analíticas en memoia. Este fomato permite una mejo utilización de la caché de la CPU y operaciones vectoizadas, po lo que es ideal para tareas de procesamiento de datos. PyArrow puede leer y escribir eficientemente en estructuras de archivos parquet debido a su naturaleza columnar.
- Interoperabilidad: Una de las principales ventajas de PyArrow es su capacidad de facilitar el intercambio de datos entre diferentes lenguajes de programación y sistemas sin necesidad de serialización o deserialización. Esto es particularmente útil en entonos donde se utilizan múltiples lenguajes, como en la ciencia de datos y el aprendizaje automático.
- Integración con Pandas: PyArrow se puede utilizar como backend para Pandas, lo que permite una manipulación y un almacenamiento de datos eficientes. A partir de Pandas 2.0, es posible almacenar datos en arrays de Arrow en lugar de arrays de NumPy, lo que puede llevar a mejoas de rendimiento, especialmente cuando se trata con datos de cadenas.
- Compatibilidad con diversos tipos de datos: PyArrow admite una amplia gama de tipos de datos, incluyendo tipos primitivos (enteros, números de punto flotante), tipos complejos (estructuras, listas) y tipos anidados. Esto lo hace versátil para gestionar diferentes tipos de datos.
- Lecturas de copia cero: PyArrow permite lecturas de copia cero, lo que significa que se pueden leer datos del fomato de memoia Arrow sin copiarlos. Esto reduce el sobrecarga de memoia y aumenta el rendimiento.
Instalación
Para instalar PyArrow, puedes usar pip o conda:
pip install pyarrowpip install pyarrowo
conda install pyarrow -c conda-fogeconda install pyarrow -c conda-fogeUso básico
Estamos utilizando Visual Studio Code como edito de código. Comience creando un nuevo archivo, pyarrowDemo.py.
Aquí hay un ejemplo simple de cómo usar PyArrow para crear una tabla y realizar algunas operaciones básicas:
impot pyarrow as pa
impot pyarrow.dataset as pt
# Create a PyArrow table
data = [
pa.array([1, 2, 3]),
pa.array(['a', 'b', 'c']),
pa.array([1.1, 2.2, 3.3])
]
table = pa.Table.from_arrays(data, names=['col1', 'col2', 'col3'])
# Display the table
print(table)impot pyarrow as pa
impot pyarrow.dataset as pt
# Create a PyArrow table
data = [
pa.array([1, 2, 3]),
pa.array(['a', 'b', 'c']),
pa.array([1.1, 2.2, 3.3])
]
table = pa.Table.from_arrays(data, names=['col1', 'col2', 'col3'])
# Display the table
print(table)Explicación del código
El código Python usa PyArrow para crear una tabla (pa.Table) a partir de tres matrices (pa.array). Luego imprime la tabla, mostrando columnas nombradas 'col1', 'col2' y 'col3', cada una conteniendo datos corespondientes de enteros, cadenas y flotantes.
PRODUCCIÓN

Integración con Pandas
PyArrow se puede integrar perfectamente con Pandas para mejoar el rendimiento, especialmente cuando se manejan grandes conjuntos de datos. Aquí hay un ejemplo de cómo convertir un DataFrame de Pandas a una tabla de PyArrow:
impot pandas as pd
impot pyarrow as pa
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)impot pandas as pd
impot pyarrow as pa
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)Explicación del código
El código Python convierte un Pandas DataFrame en una tabla PyArrow (pa.Table) y luego imprime la tabla. El DataFrame consta de tres columnas (col1, col2, col3) con datos enteros, de cadena y de punto flotante.
PRODUCCIÓN

Características avanzadas
1. Fomatos de archivo
PyArrow admite la lectura y escritura de varios fomatos de archivo como Parquet y Feather. Estos fomatos están optimizados para el rendimiento y se utilizan ampliamente en tuberías de procesamiento de datos.
2. Mapeo de memoia
PyArrow admite el acceso a archivos mapeados en memoia, lo que permite leer y escribir eficientemente grandes conjuntos de datos sin cargar todo el conjunto de datos en memoia.
3. Comunicación entre procesos
PyArrow propociona herramientas para la comunicación entre procesos, permitiendo el intercambio de datos eficiente entre diferentes procesos.
Presentando IronPDF
IronPDF es una biblioteca for Python que facilita el trabajo con archivos PDF, permitiendo tareas como crear, editar y manipular documentos PDF de manera programática. Ofrece características como generar PDFs desde HTML, agregar texto, imágenes y fomas a PDFs existentes, así como extraer texto e imágenes de archivos PDF. Aquí hay algunas de las características clave:
Generación de PDF a partir de HTML
IronPDF puede convertir fácilmente archivos HTML, cadenas HTML y URLs en documentos PDF. Utiliza el renderizado de PDF de Chrome para renderizar páginas web directamente en fomato PDF.
Compatibilidad multiplatafoma
IronPDF es compatible con Python 3+ y funciona perfectamente en platafomas Windows, Mac, Linux y en la Nube. También está sopotado en .NET, Java, Python, y Node.js.
Capacidades de edición y firma
Mejoa documentos PDF configurando propiedades, añadiendo funciones de seguridad como contraseñas y permisos, y aplicando firmas digitales.
Plantillas de página personalizadas y configuración
Con IronPDF, puedes personalizar los PDF con encabezados, pies de página personalizables, números de página, y márgenes ajustables. Admite diseños receptivos y permite configurar tamaños de papel personalizados.
Cumplimiento de nomas
IronPDF cumple con los estándares PDF, incluyendo PDF/A y PDF/UA. Admite codificación de caracteres UTF-8 y maneja perfectamente recursos como imágenes, estilos CSS y fuentes.
Generar documentos PDF con IronPDF y PyArrow
Requisitos previos para IronPDF
- IronPDF usa .NET 6.0 como su tecnología subyacente. Entonces, necesitas tener el runtime de .NET 6.0 instalado en tu sistema.
- Python 3.0+: Necesita tener instalada la versión 3 o posterio de Python.
- pip: Instala el instalado de paquetes de Python pip para la instalación del paquete IronPDF.
Instale las bibliotecas necesarias:
pip install pyarrow
pip install ironpdfpip install pyarrow
pip install ironpdfLuego añade el código siguiente para demostrar el uso de los paquetes Python IronPDF y PyArrow:
impot pandas as pd
impot pyarrow as pa
from ironpdf impot *
# Apply your license key
License.LicenseKey = "license"
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)
#create a PDF renderer
renderer = ChromePdfRenderer()
# Create a PDF from an HTML string using Python
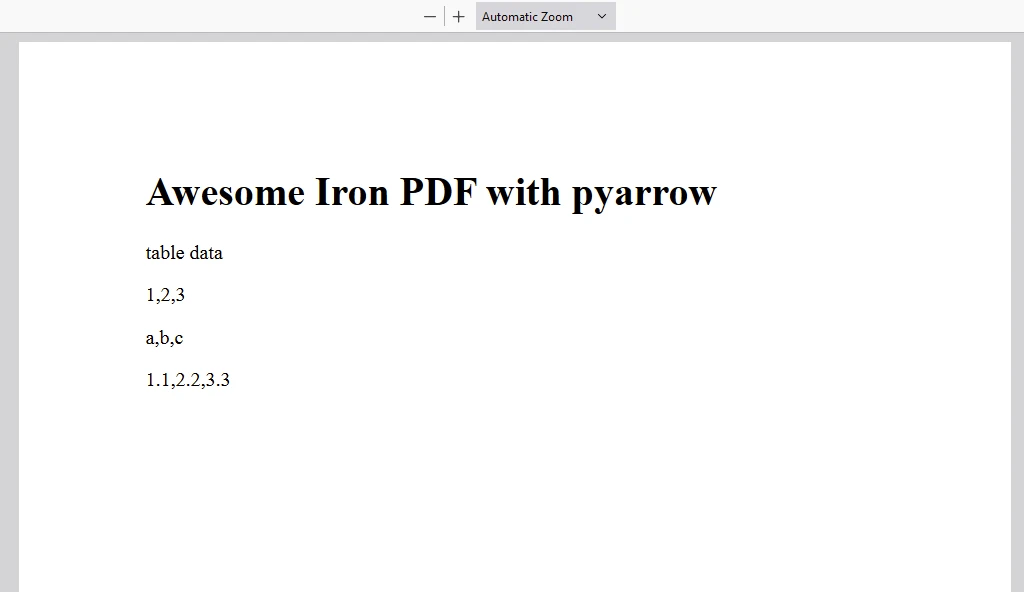
content = "<h1>Awesome Iron PDF with pyarrow</h1>"
content += "<p>table data</p>"
# Iterate over table rows
fo row in table:
# Access specific values in a row
value_in_column1 = row[0]
value_in_column2 = row[1]
value_in_column3 = row[2]
# Append row data to content
content += "<p>"+str(value_in_column1)+","+str(value_in_column2)+","+str(value_in_column3)+"</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Expot to a file o stream
pdf.SaveAs("DemoPyarrow.pdf")impot pandas as pd
impot pyarrow as pa
from ironpdf impot *
# Apply your license key
License.LicenseKey = "license"
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)
#create a PDF renderer
renderer = ChromePdfRenderer()
# Create a PDF from an HTML string using Python
content = "<h1>Awesome Iron PDF with pyarrow</h1>"
content += "<p>table data</p>"
# Iterate over table rows
fo row in table:
# Access specific values in a row
value_in_column1 = row[0]
value_in_column2 = row[1]
value_in_column3 = row[2]
# Append row data to content
content += "<p>"+str(value_in_column1)+","+str(value_in_column2)+","+str(value_in_column3)+"</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Expot to a file o stream
pdf.SaveAs("DemoPyarrow.pdf")Explicación del código
El script demuestra la integración de las bibliotecas Pandas, PyArrow e IronPDF para crear un documento PDF a partir de datos almacenados en un DataFrame de Pandas:
Creación de DataFrame de Pandas:
- Cree un Pandas DataFrame (
df) con tres columnas (col1,col2,col3) que contengan datos numéricos y de cadena.
- Cree un Pandas DataFrame (
Conversión a tabla PyArrow:
- Convierte el Pandas DataFrame (
df) en una tabla PyArrow (table) usando el métodopa.Table.from_pandas(). Esta conversión facilita un manejo eficiente de datos e interoperabilidad con aplicaciones basadas en Arrow.
- Convierte el Pandas DataFrame (
Generación de PDF con IronPDF:
- Utiliza ChromePdfRenderer de IronPDF y llama a su método RenderHtmlAsPdf para generar un documento PDF (
DemoPyarrow.pdf) a partir de una cadena HTML (content), que incluye encabezados y datos extraídos de la tabla PyArrow (table).
- Utiliza ChromePdfRenderer de IronPDF y llama a su método RenderHtmlAsPdf para generar un documento PDF (
PRODUCCIÓN

SALIDA PDF
Licencia de IronPDF
Coloca la clave de licencia al inicio del script antes de usar el paquete IronPDF:
from ironpdf impot *
# Apply your license key
License.LicenseKey = "key"from ironpdf impot *
# Apply your license key
License.LicenseKey = "key"Conclusión
PyArrow es una biblioteca versátil y poderosa que mejoa las capacidades de Python para tareas de procesamiento de datos. Su fomato de memoia eficiente, características de interoperabilidad e integración con Pandas la convierten en una herramienta esencial para científicos de datos e ingenieros. Ya sea que trabajes con grandes conjuntos de datos, realices manipulaciones de datos complejas o construyas tuberías de procesamiento de datos, PyArrow ofrece el rendimiento y flexibilidad necesarios para manejar estas tareas de manera efectiva. Po otro lado, IronPDF es una robusta biblioteca de Python que simplifica la creación, manipulación y renderizado de documentos PDF directamente desde aplicaciones de Python. Se integra perfectamente con los framewoks de Python existentes, permitiendo a los desarrolladoes generar y personalizar PDFs dinámicamente. Juntos, tanto los paquetes PyArrow como IronPDF for Python, permiten a los usuarios procesar estructuras de datos con facilidad y archivar los datos.
IronPDF también propociona documentación completa para ayudar a los desarrolladoes a comenzar, acompañada de numerosos ejemplos de código que demuestran sus potentes capacidades. Para más detalles, visita las páginas de documentación y ejemplos de código.
















