
Biblioteca de Requests en Python (Cómo Funciona Para Desarrolladores)
Python es ampliamente reconocido por su simplicidad y legibilidad, lo que lo convierte en una opción popular entre los desarrolladores para el web scraping y la interacción con las API. Una de las bibliotecas clave que permite estas interacciones es la biblioteca Python Requests. Requests es una biblioteca de solicitudes HTTP for Python que le permite enviar solicitudes HTTP directamente. En este artículo, profundizaremos en las características de la biblioteca Python Requests, exploraremos su uso con ejemplos prácticos y presentaremos IronPDF, mostrando cómo se puede combinar con Requests para crear y manipular PDF a partir de datos web.
Introducción a la biblioteca Requests
La biblioteca Python Requests se creó para hacer que las solicitudes HTTP sean más simples y amigables para los humanos. Abstrae las complejidades de hacer solicitudes detrás de una API simple para que pueda concentrarse en interactuar con servicios y datos en la web. Ya sea que necesite obtener páginas web, interactuar con API REST, deshabilitar la verificación del certificado SSL o enviar datos a un servidor, la biblioteca Requests lo tiene cubierto.
Características principales
- Simplicidad: Sintaxis fácil de usar y comprender.
- Métodos HTTP: admite todos los métodos HTTP: GET, POST, PUT, DELETE, etc.
- Objetos de sesión: mantiene las cookies en todas las solicitudes.
- Autenticación: simplifica la adición de encabezados de autenticación.
- Proxies: Soporte para proxies HTTP.
- Tiempos de espera: administra eficazmente los tiempos de espera de las solicitudes.
- Verificación SSL: verifica los certificados SSL de forma predeterminada.
Instalando Requests
Para comenzar a utilizar Requests, necesitas instalarlo. Esto se puede hacer usando pip:
pip install requestspip install requestsUso básico
A continuación se muestra un ejemplo sencillo de cómo utilizar Requests para obtener una página web:
import requests
# Send a GET request to the specified URL
response = requests.get('https://www.example.com')
# Print the status code of the response (e.g., 200 for success)
print(response.status_code)
# Print the HTML content of the page
print(response.text)import requests
# Send a GET request to the specified URL
response = requests.get('https://www.example.com')
# Print the status code of the response (e.g., 200 for success)
print(response.status_code)
# Print the HTML content of the page
print(response.text)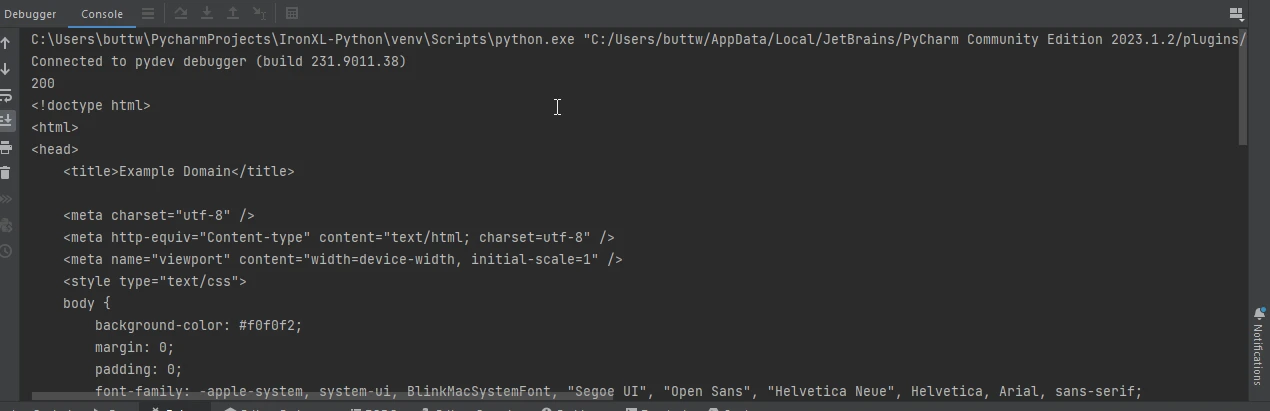
Envío de parámetros en URL
A menudo, necesita pasar parámetros a la URL. El módulo Python Requests hace esto fácil con la palabra clave params:
import requests
# Define the parameters to be sent in the URL
params = {'key1': 'value1', 'key2': 'value2'}
# Send a GET request with parameters
response = requests.get('https://www.example.com', params=params)
# Print the full URL including the parameters
print(response.url)import requests
# Define the parameters to be sent in the URL
params = {'key1': 'value1', 'key2': 'value2'}
# Send a GET request with parameters
response = requests.get('https://www.example.com', params=params)
# Print the full URL including the parameters
print(response.url)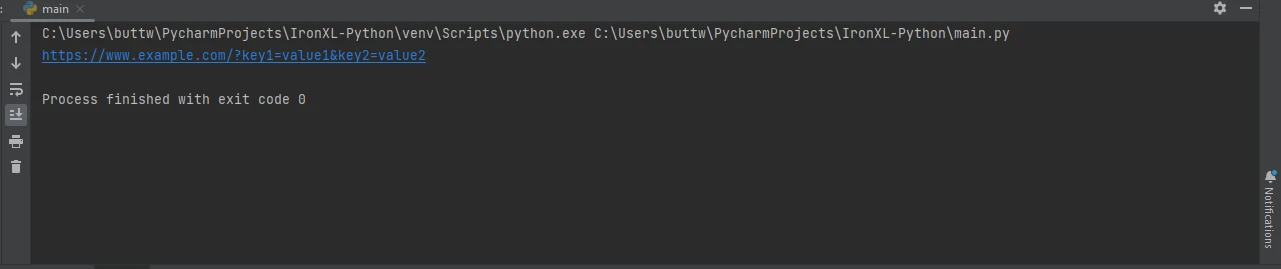
Manejo de datos JSON
Interactuar con APIs usualmente involucra datos JSON. Requests simplifica esto con soporte JSON incorporado:
import requests
# Send a GET request to retrieve JSON data
response = requests.get('https://jsonplaceholder.typicode.com/todos/1')
# Convert the JSON response to a Python dictionary
data = response.json()
# Print the JSON data
print(data)import requests
# Send a GET request to retrieve JSON data
response = requests.get('https://jsonplaceholder.typicode.com/todos/1')
# Convert the JSON response to a Python dictionary
data = response.json()
# Print the JSON data
print(data)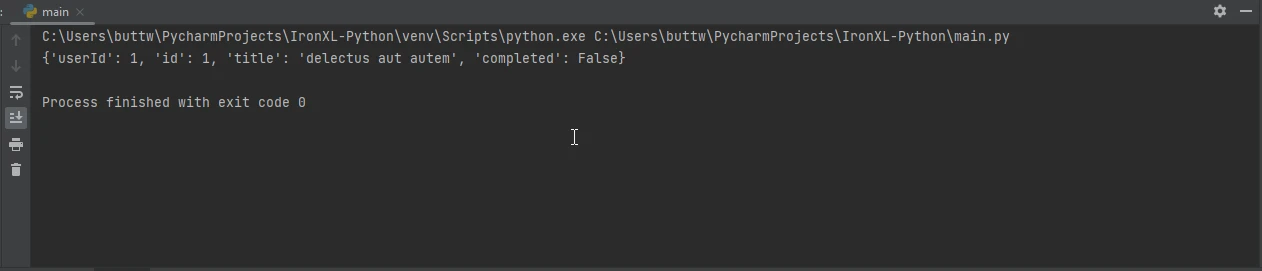
Trabajando con cabeceras
Los encabezados son cruciales para las solicitudes HTTP. Puede agregar encabezados personalizados a sus solicitudes de esta manera:
import requests
# Define custom headers
headers = {'User-Agent': 'my-app/0.0.1'}
# Send a GET request with custom headers
response = requests.get('https://www.example.com', headers=headers)
# Print the response text
print(response.text)import requests
# Define custom headers
headers = {'User-Agent': 'my-app/0.0.1'}
# Send a GET request with custom headers
response = requests.get('https://www.example.com', headers=headers)
# Print the response text
print(response.text)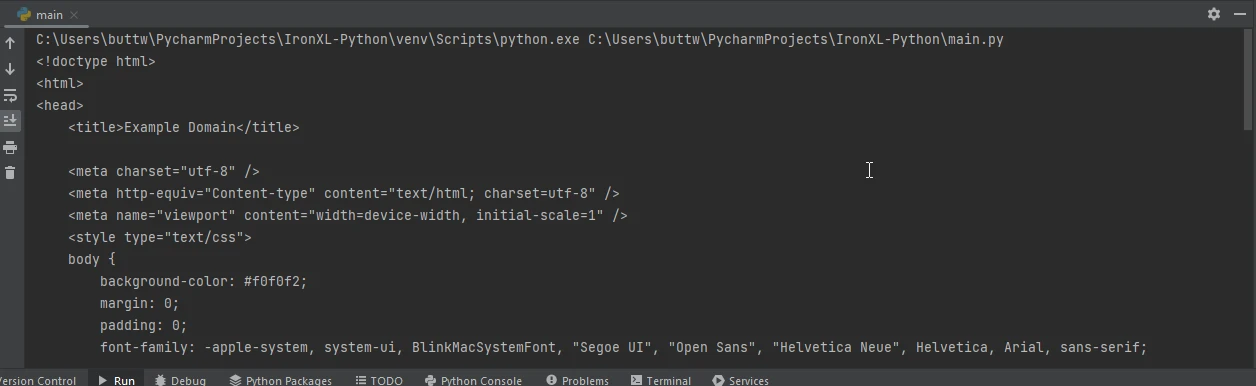
Carga de archivos
Requests también admite cargas de archivos. Aquí está cómo puede cargar un archivo:
import requests
# Define the files to be uploaded
files = {'file': open('report.txt', 'rb')}
# Send a POST request with the file
response = requests.post('https://www.example.com/upload', files=files)
# Print the status code of the response
print(response.status_code)import requests
# Define the files to be uploaded
files = {'file': open('report.txt', 'rb')}
# Send a POST request with the file
response = requests.post('https://www.example.com/upload', files=files)
# Print the status code of the response
print(response.status_code)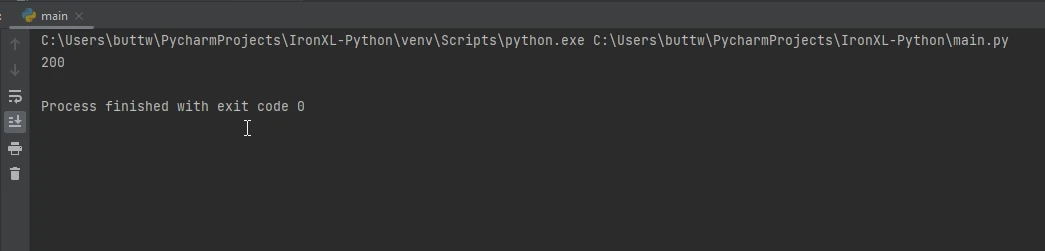
Presentación de IronPDF for Python
IronPDF es una biblioteca versátil de generación de PDF que puede usarse para crear, editar y manipular PDFs dentro de sus aplicaciones de Python. Es particularmente útil cuando necesita generar PDFs a partir de contenido HTML, convirtiéndolo en una herramienta excelente para crear informes, facturas o cualquier otro tipo de documento que deba distribuirse en un formato portátil.
Instalación de IronPDF
Para instalar IronPDF, use pip:
pip install ironpdf
Usando IronPDF con Requests
La combinación de Requests y IronPDF le permite obtener datos de la web y convertirlos directamente en documentos PDF. Esto puede ser particularmente útil para crear informes a partir de datos web o guardar páginas web como PDFs.
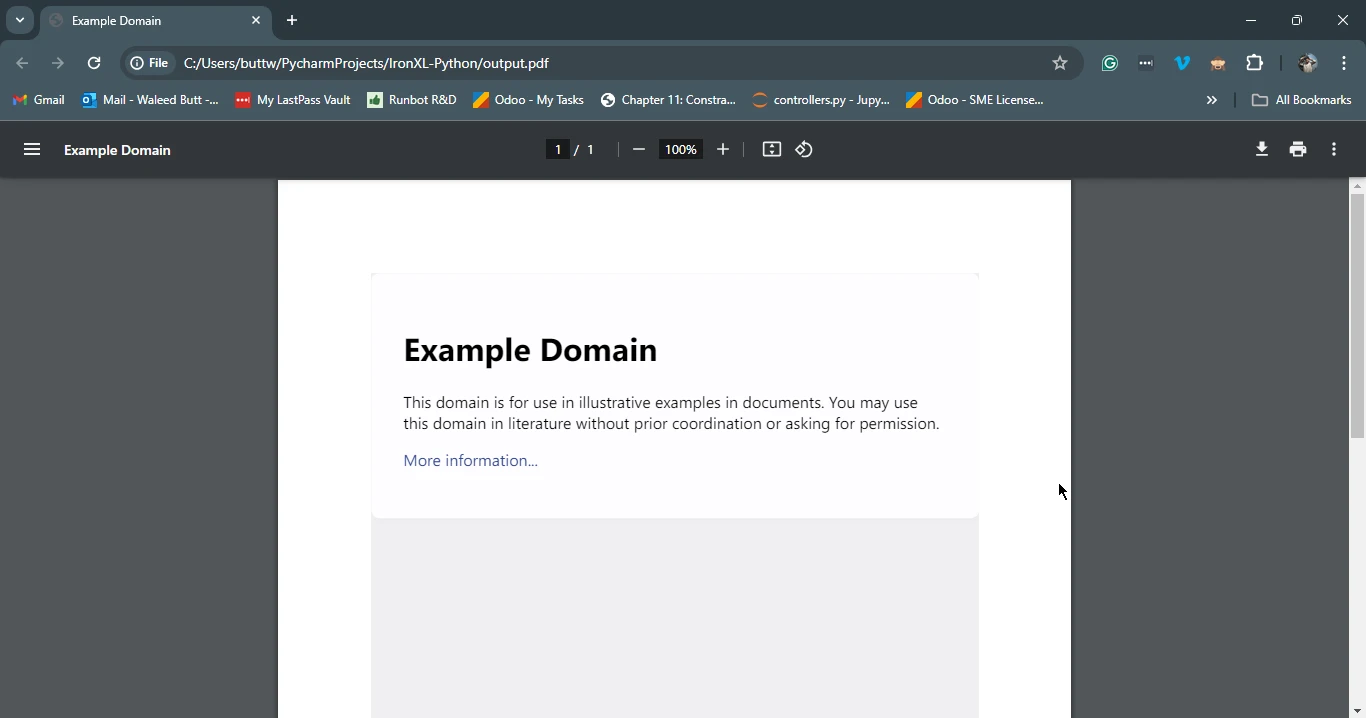
A continuación se muestra un ejemplo de cómo utilizar Requests para obtener una página web y luego utilizar IronPDF para guardarla como PDF:
import requests
from ironpdf import ChromePdfRenderer
# Fetch a web page
url = 'https://www.example.com'
response = requests.get(url)
if response.status_code == 200:
# Extract the HTML content from the response
html_content = response.text
# Initialize the PDF renderer
renderer = ChromePdfRenderer()
# Render the HTML content as a PDF
pdf = renderer.RenderHtmlAsPdf(html_content)
# Save the generated PDF to a file
pdf.save('output.pdf')
print('PDF created successfully')
else:
# Print an error message if the request was not successful
print(f'Failed to retrieve the webpage. Status code: {response.status_code}')import requests
from ironpdf import ChromePdfRenderer
# Fetch a web page
url = 'https://www.example.com'
response = requests.get(url)
if response.status_code == 200:
# Extract the HTML content from the response
html_content = response.text
# Initialize the PDF renderer
renderer = ChromePdfRenderer()
# Render the HTML content as a PDF
pdf = renderer.RenderHtmlAsPdf(html_content)
# Save the generated PDF to a file
pdf.save('output.pdf')
print('PDF created successfully')
else:
# Print an error message if the request was not successful
print(f'Failed to retrieve the webpage. Status code: {response.status_code}')Este script primero obtiene el contenido HTML de la URL especificada usando Requests. Luego usa IronPDF para convertir el contenido HTML de este objeto de respuesta en un PDF y guarda el PDF resultante en un archivo.
Conclusión
La biblioteca Requests es una herramienta esencial para cualquier desarrollador de Python que necesite interactuar con API web. Su simplicidad y facilidad de uso la convierten en la opción ideal para realizar solicitudes HTTP. Cuando se combina con IronPDF, se abren aún más posibilidades, permitiéndole obtener datos de la web y convertirlos en documentos PDF de calidad profesional. Ya sea que esté creando informes, facturas o archivando contenido web, la combinación de Requests y IronPDF proporciona una solución poderosa para sus necesidades de generación de PDF.
Para obtener más información sobre las licencias de IronPDF, consulte la página de licencias de IronPDF. También puede explorar nuestro tutorial detallado sobre la Conversión de HTML a PDF para obtener más información.
















