
xml.etree Python (Cómo Funciona Para Desarrolladores)
XML (eXtensible Markup Language) es un formato popular y flexible para representar datos estructurados en el procesamiento de datos y la generación de documentos. La biblioteca estándar incluye xml.etree, una biblioteca de Python que ofrece a los desarrolladores un poderoso conjunto de herramientas para analizar o crear datos XML, manipular elementos secundarios y generar documentos XML mediante programación.
Cuando se combina con IronPDF, una biblioteca .NET para crear y editar documentos PDF, los desarrolladores pueden aprovechar las capacidades combinadas de xml.etree e IronPDF para agilizar el procesamiento de datos de objetos de elementos XML y la generación dinámica de documentos PDF. En esta guía detallada, profundizaremos en el mundo de xml.etree Python, exploraremos sus principales características y funcionalidades, y le mostraremos cómo integrarlo con IronPDF para desbloquear nuevas posibilidades en el procesamiento de datos.
¿Qué es xml.etree?
xml.etree es parte de la biblioteca estándar de Python. Tiene el sufijo .etree, también conocido como ElementTree, que ofrece una API XML de ElementTree sencilla y efectiva para procesar y modificar documentos XML. Permite a los programadores interactuar con datos XML en una estructura de árbol jerárquico, simplificando la navegación, modificación y generación programática de archivos XML.
Aunque es liviano y fácil de usar, xml.etree ofrece una sólida funcionalidad para manejar datos de elementos raíz XML. Proporciona una manera de analizar documentos de datos XML desde archivos, cadenas o cosas que se asemejan a archivos. El archivo XML analizado resultante se muestra como un árbol de objetos Element. Después de eso, los desarrolladores pueden navegar por este árbol, acceder a elementos y atributos, y realizar diferentes acciones como editar, eliminar o agregar elementos.

Características de xml.etree
Parificación de documentos XML
Los métodos para analizar documentos XML a partir de cadenas, archivos u objetos similares a archivos están disponibles en xml.etree. El material XML se puede procesar utilizando la función parse(), que también produce un objeto ElementTree que representa el documento XML analizado con un objeto Element válido.
Navegación por árboles XML
Los desarrolladores pueden usar xml.etree para recorrer los elementos de un árbol XML usando funciones como find(), findall() y iter() una vez que se haya procesado el documento. Acceder a ciertos elementos basados en etiquetas, atributos o expresiones XPath se hace sencillo mediante estos enfoques.
Modificación de documentos XML
Dentro de un documento XML, hay formas de agregar, editar y eliminar componentes y atributos usando xml.etree. Al alterar programáticamente el formato de datos inherentemente jerárquico, la estructura y el contenido del árbol XML, se habilita la modificación, actualización y transformación de datos.
Serialización de documentos XML
xml.etree permite la serialización de árboles XML en cadenas u objetos similares a archivos utilizando funciones como ElementTree.write() después de modificar un documento XML. Esto posibilita que los desarrolladores creen o modifiquen árboles XML y produzcan salida XML a partir de ellos.
Soporte XPath
xml.etree proporciona soporte para XPath, un lenguaje de consulta para elegir nodos de un documento XML. Los desarrolladores pueden realizar actividades sofisticadas de recuperación y manipulación de datos usando expresiones XPath para consultar y filtrar elementos dentro de un árbol XML.
Parseo iterativo
En lugar de cargar todo el documento en la memoria de una sola vez, los desarrolladores pueden manejar documentos XML secuencialmente gracias al soporte de xml.etree para el análisis iterativo. Esto es muy útil para gestionar de manera eficaz archivos XML grandes.
Soporte de espacios de nombres
Los desarrolladores pueden trabajar con documentos XML que utilizan espacios de nombres para la identificación de elementos y atributos mediante el soporte de xml.etree para espacios de nombres XML. Proporciona formas de resolver los prefijos de espacio de nombres XML predeterminados y especificar espacios de nombres dentro de un documento XML.
Manejo de errores
Las capacidades de manejo de errores para documentos XML incorrectos y errores de análisis están incluidas en xml.etree. Ofrece técnicas para el manejo y captura de errores, garantizando fiabilidad y robustez al trabajar con datos XML.
Compatibilidad y portabilidad
Dado que xml.etree es un componente de la biblioteca estándar de Python, puede usarse inmediatamente en programas Python sin necesidad de instalaciones adicionales. Es portátil y compatible con muchas configuraciones de Python porque funciona tanto con Python 2 como con Python 3.
Crear y configurar xml.etree
Crear un documento XML
Al construir objetos que representan los elementos del árbol XML de importación y adjuntarlos a un elemento raíz, puede generar un documento XML. Este es un ejemplo de cómo crear datos XML:
import xml.etree.ElementTree as ET
# Create a root element
root = ET.Element("catalog")
# Parent element
book1 = ET.SubElement(root, "book")
# Set attribute for book1
book1.set("id", "1")
# Child elements for book1
title1 = ET.SubElement(book1, "title")
title1.text = "Python Programming"
author1 = ET.SubElement(book1, "author")
author1.text = "John Smith"
# Parent element
book2 = ET.SubElement(root, "book")
# Set attribute for book2
book2.set("id", "2")
# Child elements for book2
title2 = ET.SubElement(book2, "title")
title2.text = "Data Science Essentials"
author2 = ET.SubElement(book2, "author")
author2.text = "Jane Doe"
# Create ElementTree object
tree = ET.ElementTree(root)import xml.etree.ElementTree as ET
# Create a root element
root = ET.Element("catalog")
# Parent element
book1 = ET.SubElement(root, "book")
# Set attribute for book1
book1.set("id", "1")
# Child elements for book1
title1 = ET.SubElement(book1, "title")
title1.text = "Python Programming"
author1 = ET.SubElement(book1, "author")
author1.text = "John Smith"
# Parent element
book2 = ET.SubElement(root, "book")
# Set attribute for book2
book2.set("id", "2")
# Child elements for book2
title2 = ET.SubElement(book2, "title")
title2.text = "Data Science Essentials"
author2 = ET.SubElement(book2, "author")
author2.text = "Jane Doe"
# Create ElementTree object
tree = ET.ElementTree(root)Escribir documento XML en archivo
La función write() del objeto ElementTree se puede utilizar para escribir el archivo XML:
# Write XML document to file
tree.write("catalog.xml")# Write XML document to file
tree.write("catalog.xml")El documento XML se creará en un archivo llamado "catalog.xml" como resultado.
Preparar un documento XML
El ElementTree analiza datos XML mediante la función parse():
# Parse an XML document
tree = ET.parse("catalog.xml")
root = tree.getroot()# Parse an XML document
tree = ET.parse("catalog.xml")
root = tree.getroot()El documento XML "catalog.xml" será analizado de esta manera, obteniendo el elemento raíz del árbol XML.
Elementos de acceso y atributos
Utilizando una variedad de técnicas y características ofrecidas por los objetos Element, puede acceder a los elementos y atributos del documento XML. Por ejemplo, para ver el título del primer libro:
# Reading single XML element
first_book_title = root[0].find("title").text
print("Title of first book:", first_book_title)# Reading single XML element
first_book_title = root[0].find("title").text
print("Title of first book:", first_book_title)Modificar documento XML
El documento XML puede ser alterado agregando, cambiando o eliminando componentes y atributos. Para cambiar el autor del segundo libro, por ejemplo:
# Modify XML document
root[1].find("author").text = "Alice Smith"# Modify XML document
root[1].find("author").text = "Alice Smith"Serializar documento XML
La función tostring() del módulo ElementTree se puede utilizar para serializar el documento XML en una cadena:
# Serialize XML document to string
xml_string = ET.tostring(root, encoding="unicode")
print(xml_string)# Serialize XML document to string
xml_string = ET.tostring(root, encoding="unicode")
print(xml_string)Cómo empezar con IronPDF
¿Qué es IronPDF?
IronPDF es una poderosa biblioteca .NET para crear, editar y alterar documentos PDF programáticamente en C#, VB.NET y otros lenguajes .NET. Dado que ofrece a los desarrolladores un amplio conjunto de funciones para crear dinámicamente PDFs de alta calidad, es una opción popular para muchos programas.
Características principales de IronPDF
Generación de PDF:
Usando IronPDF, los programadores pueden crear nuevos documentos PDF o convertir etiquetas HTML existentes, texto, imágenes y otros formatos de archivo en PDFs. Esta característica es muy útil para crear informes, facturas, recibos y otros documentos de manera dinámica.
Conversión de HTML a PDF:
IronPDF facilita a los desarrolladores transformar documentos HTML, incluyendo estilos de JavaScript y CSS, en archivos PDF. Esto permite la creación de PDFs a partir de páginas web, contenido generado dinámicamente y plantillas HTML.
Modificación y Edición de Documentos PDF:
IronPDF proporciona un conjunto completo de funcionalidades para modificar y alterar documentos PDF preexistentes. Los desarrolladores pueden fusionar varios archivos PDF, separarlos en otros documentos, eliminar páginas y agregar marcadores, anotaciones y marcas de agua, entre otras características, para personalizar los PDFs según sus necesidades.
IronPDF y xml.etree combinados
Esta próxima sección demostrará cómo generar documentos PDF con IronPDF basándose en datos XML analizados. Esto muestra que al aprovechar las fortalezas tanto de XML como de IronPDF, puede transformar eficientemente datos estructurados en documentos PDF profesionales. Aquí tienes una guía detallada:
Instalación
Asegúrate de que IronPDF esté instalado antes de comenzar. Se puede instalar usando pip:
pip install IronPdfpip install IronPdfGenerar un documento PDF con IronPDF utilizando XML analizado
IronPDF puede ser utilizado para crear un documento PDF en función de los datos que ha extraído del XML después de que ha sido procesado. Hagamos un documento PDF con una tabla que contenga los nombres de los libros y los autores:
from ironpdf import *
# Sample parsed XML books data
books = [
{'title': 'Python Programming', 'author': 'John Smith'},
{'title': 'Data Science Essentials', 'author': 'Jane Doe'}
]
# Create HTML content for PDF from the parsed XML elements
html_content = """
<html>
<body>
<h1>Books</h1>
<table border='1'>
<tr><th>Title</th><th>Author</th></tr>
"""
# Iterate over books to add each book's data to the HTML table
for book in books:
html_content += f"<tr><td>{book['title']}</td><td>{book['author']}</td></tr>"
# Close the table and body tags
html_content += """
</table>
</body>
</html>
"""
# Generate and save the PDF document
pdf = IronPdf()
pdf.HtmlToPdf.RenderHtmlAsPdf(html_content)
pdf.SaveAs("books.pdf")from ironpdf import *
# Sample parsed XML books data
books = [
{'title': 'Python Programming', 'author': 'John Smith'},
{'title': 'Data Science Essentials', 'author': 'Jane Doe'}
]
# Create HTML content for PDF from the parsed XML elements
html_content = """
<html>
<body>
<h1>Books</h1>
<table border='1'>
<tr><th>Title</th><th>Author</th></tr>
"""
# Iterate over books to add each book's data to the HTML table
for book in books:
html_content += f"<tr><td>{book['title']}</td><td>{book['author']}</td></tr>"
# Close the table and body tags
html_content += """
</table>
</body>
</html>
"""
# Generate and save the PDF document
pdf = IronPdf()
pdf.HtmlToPdf.RenderHtmlAsPdf(html_content)
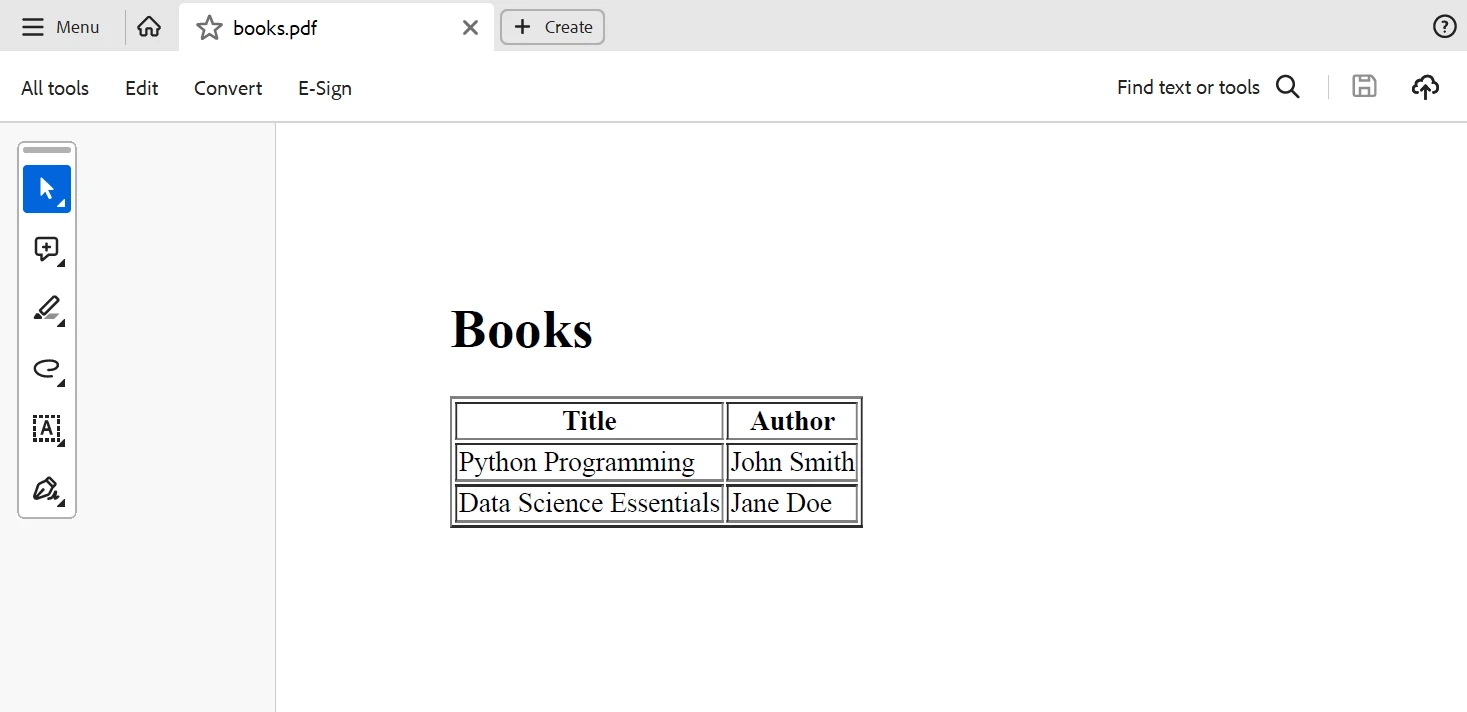
pdf.SaveAs("books.pdf")Este código Python genera una tabla HTML que contiene los nombres de los libros y los autores, que luego IronPDF convierte en un documento PDF. A continuación se muestra la salida generada a partir del código anterior.
Resultado
Conclusión
En conclusión, los desarrolladores que buscan analizar datos XML y producir documentos PDF dinámicos basados en los datos analizados encontrarán una solución sólida en la combinación de IronPDF y xml.etree Python. Con la ayuda de la confiable y efectiva API de Python xml.etree, los desarrolladores pueden extraer fácilmente datos estructurados de documentos XML. Sin embargo, IronPDF mejora esto al ofrecer la capacidad de crear documentos PDF estéticamente agradables y editables a partir de los datos XML que han sido procesados.
Juntos, xml.etree Python e IronPDF permiten a los desarrolladores automatizar tareas de procesamiento de datos, extraer información valiosa de fuentes de datos XML y presentarla de manera profesional y visualmente atractiva a través de documentos PDF. Ya sea generar informes, crear facturas o producir documentación, la sinergia entre xml.etree Python e IronPDF abre nuevas posibilidades en el procesamiento de datos y la generación de documentos.
Se incluye una licencia de por vida con IronPDF, que tiene un precio bastante razonable cuando se compra en un paquete. El paquete ofrece un valor excelente: solo cuesta $799 (una compra única para varios sistemas). Aquellos con licencias tienen acceso 24/7 a soporte técnico en línea. Para más detalles sobre la tarifa, por favor visita este sitio web. Visita esta página para conocer más sobre los productos de Iron Software.
















