
Cómo Extraer Texto De Un PDF Línea Por Línea
Esta guía mostrará los matices del uso de IronPDF para extraer texto secuencialmente de documentos PDF en Python. Cubrirá todo, desde configurar su entorno de Python hasta ejecutar su primer programa en Python para la extracción de texto de PDF.
Cómo extraer texto de un PDF línea por línea
- Descargue e instale la biblioteca PDF usando Python para extraer texto del archivo PDF línea por línea.
- Cree un proyecto de Python en su IDE preferido.
- Cargue el archivo PDF deseado para recuperar contenido textual.
- Recorra el PDF y extraiga el texto secuencialmente usando la función de la biblioteca integrada.
- Guarde el texto extraído en un archivo.
Librería IronPDF PDF for Python
IronPDF es una herramienta útil que te permite trabajar con archivos PDF en Python. Piénsalo como un asistente útil que hace que leer, crear y editar archivos PDF sea accesible. Ya sea que busques extraer contenido de un documento PDF, incluir información nueva o transformar una página web en un formato PDF, IronPDF ofrece soluciones integrales. Es un paquete de software de pago, pero ofrecen una versión de prueba para que explores antes de decidirte a comprar.
Antes de sumergirte en el script, es esencial configurar tu entorno de Python. Esta guía paso a paso te ayudará a configurar tu entorno, crear un nuevo proyecto de Python en Visual Studio Code y configurar el entorno de la biblioteca IronPDF.
Descargar e instalar Python: si no ha instalado Python, descargue la versión más reciente del sitio web oficial de Python . Sigue las instrucciones de instalación para tu sistema operativo específico.
Compruebe la instalación de Python: abra su terminal o símbolo del sistema y escriba python --version . Este comando debería imprimir la versión de Python instalada, confirmando que la instalación fue exitosa.
Actualizar pip: Pip es el instalador de paquetes de Python. Asegúrate de que esté actualizado ejecutando pip install --upgrade pip.
Creación de un nuevo proyecto Python en Visual Studio Code
Descargar Visual Studio Code: Si no lo tienes, descárgalo desde el sitio web oficial .
Instalar la extensión de Python: abra Visual Studio Code y diríjase al Marketplace de extensiones. Busca la extensión de Python de Microsoft y instálala.
Crear una nueva carpeta: crea una nueva carpeta donde quieras alojar tu proyecto de Python. Ponle un nombre relevante, como PDF_Text_Extractor.
Abrir la carpeta en VS Code: arrastre la carpeta a Visual Studio Code o use la opción de menú Archivo > Abrir carpeta para abrir la carpeta.
Crear un archivo Python: haga clic derecho en el panel Explorador de VS Code y seleccione Nuevo archivo . Nombra el archivo main.py o algo similar. Este archivo contendrá tu programa de Python.
 Crear nuevo archivo de Python en Visual Studio Code
Crear nuevo archivo de Python en Visual Studio Code
Requisitos y configuración de la biblioteca IronPDF
IronPDF es esencial para recuperar contenido textual de PDFs. Aquí se explica cómo instalarlo:
Abrir terminal en VS Code: puedes abrir una terminal dentro de VS Code yendo a Terminal > Nueva terminal .
Instalar IronPDF: En la terminal, ejecute lo siguiente para instalar la última versión de IronPDF:
pip install ironpdf
Este proceso recupera e instala la biblioteca IronPDF junto con cualquier módulo necesario.
 Instalar paquete de IronPDF
Instalar paquete de IronPDF
¡Y ahí lo tienes! Ahora has configurado con éxito tu entorno de Python, creado un nuevo proyecto en Visual Studio Code e instalado la biblioteca IronPDF.
Extraer texto de un PDF línea por línea
Aplicar clave de licencia
Antes de continuar, asegúrate de aplicar tu clave de licencia IronPDF.
from ironpdf import PdfDocument
# Apply your license key to unlock library features
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"from ironpdf import PdfDocument
# Apply your license key to unlock library features
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"Reemplace YOUR-LICENSE-KEY-HERE con su clave de licencia actual de IronPDF . Esta licencia te permite desbloquear todas las funciones de la biblioteca para tu proyecto.
Carga del formato de archivo PDF
Debe cargar un archivo PDF existente en su programa Python. Puedes lograr esto con el método PdfDocument.FromFile de IronPDF.
pdfFileObj = PdfDocument.FromFile("content.pdf")pdfFileObj = PdfDocument.FromFile("content.pdf")"content.pdf" se refiere al archivo PDF que deseas leer. Este archivo PDF cargado se almacena en la variable pdfFileObj, utilizada como lector de PDF o como objeto de archivo PDF pdfFileObj.
Extracción de texto de todo el documento PDF
Si desea obtener todos los datos de texto del archivo PDF a la vez, puede utilizar el método ExtractAllText.
all_text = pdfFileObj.ExtractAllText()all_text = pdfFileObj.ExtractAllText()El método ExtractAllText se utiliza aquí con fines de demostración. Este método extrae todo el texto del archivo PDF y lo almacena en una variable llamada all_text.
Extraer texto de una página PDF específica
IronPDF permite la extracción de texto de una página específica utilizando el método ExtractTextFromPage. Este método es útil cuando solo necesitas texto de algunas páginas.
page_2_text = pdfFileObj.ExtractTextFromPage(1)page_2_text = pdfFileObj.ExtractTextFromPage(1)Aquí, estamos extrayendo texto de la segunda página, que corresponde al índice 1.
Inicialización de un archivo de texto para escribir texto extraído
with open("extracted_text.txt", "w", encoding='utf-8') as text_file:with open("extracted_text.txt", "w", encoding='utf-8') as text_file:Abre un archivo llamado "extracted_text.txt" para guardar los datos de texto. Para ello se utiliza la función incorporada open de Python, que establece el modo de archivo en "escritura" ( "w" ), con encoding='utf-8' para manejar caracteres Unicode.
Bucle a través de cada página para la extracción de texto línea por línea
for i in range(0, pdfFileObj.get_Pages().Count):for i in range(0, pdfFileObj.get_Pages().Count):El código anterior recorre cada página del archivo PDF usando get_Pages().Count de IronPDF para obtener el número total de páginas.
Extraer texto y segmentarlo en líneas
page_text = pdf.ExtractTextFromPage(i)
lines = page_text.split('\n')page_text = pdf.ExtractTextFromPage(i)
lines = page_text.split('\n')Para cada página, se utiliza el método ExtractTextFromPage para obtener todo el texto y luego se utiliza el método split de Python para dividirlo en líneas. Esto resulta en una lista de líneas que se pueden recorrer.
Escribir las líneas extraídas en un archivo de texto
for eachline in lines:
print(eachline)
text_file.write(eachline + '\n')for eachline in lines:
print(eachline)
text_file.write(eachline + '\n')Aquí, el código itera a través de cada línea en la lista de líneas, imprimiéndola en la consola y escribiéndola en el archivo agregando un carácter de nueva línea (\n) después de cada línea para formatear correctamente este texto.
Código completo
Aquí está la implementación completa:
from ironpdf import PdfDocument
# Apply your license key
License.LicenseKey = "Your-License-Key-Here"
# Load an existing PDF file
pdfFileObj = PdfDocument.FromFile("content.pdf")
# Extract text from the entire PDF file
all_text = pdfFileObj.ExtractAllText()
# Extract text from a specific page in the file (Page 2)
page_2_text = pdfFileObj.ExtractTextFromPage(1)
# Initialize a file object for writing the extracted text
with open("extracted_text.txt", "w", encoding='utf-8') as text_file:
# Get the number of pages in the PDF document
num_of_pages = pdfFileObj.get_Pages().Count
print("Number of pages in given document are ", num_of_pages)
# Loop through each page using the Count property
for i in range(0, num_of_pages):
# Extract text from the current page
page_text = pdfFileObj.ExtractTextFromPage(i)
# Split the text by lines from this page object
lines = page_text.split('\n')
# Loop through the lines and print/write them
for eachline in lines:
print(eachline) # Print each line to the console
# Write each line to the text document
text_file.write(eachline + '\n')from ironpdf import PdfDocument
# Apply your license key
License.LicenseKey = "Your-License-Key-Here"
# Load an existing PDF file
pdfFileObj = PdfDocument.FromFile("content.pdf")
# Extract text from the entire PDF file
all_text = pdfFileObj.ExtractAllText()
# Extract text from a specific page in the file (Page 2)
page_2_text = pdfFileObj.ExtractTextFromPage(1)
# Initialize a file object for writing the extracted text
with open("extracted_text.txt", "w", encoding='utf-8') as text_file:
# Get the number of pages in the PDF document
num_of_pages = pdfFileObj.get_Pages().Count
print("Number of pages in given document are ", num_of_pages)
# Loop through each page using the Count property
for i in range(0, num_of_pages):
# Extract text from the current page
page_text = pdfFileObj.ExtractTextFromPage(i)
# Split the text by lines from this page object
lines = page_text.split('\n')
# Loop through the lines and print/write them
for eachline in lines:
print(eachline) # Print each line to the console
# Write each line to the text document
text_file.write(eachline + '\n')Resultado
Ejecuta el archivo de Python escribiendo el siguiente comando en el terminal de Visual Studio Code:
python main.pypython main.pyEste resultado se mostrará en el terminal:
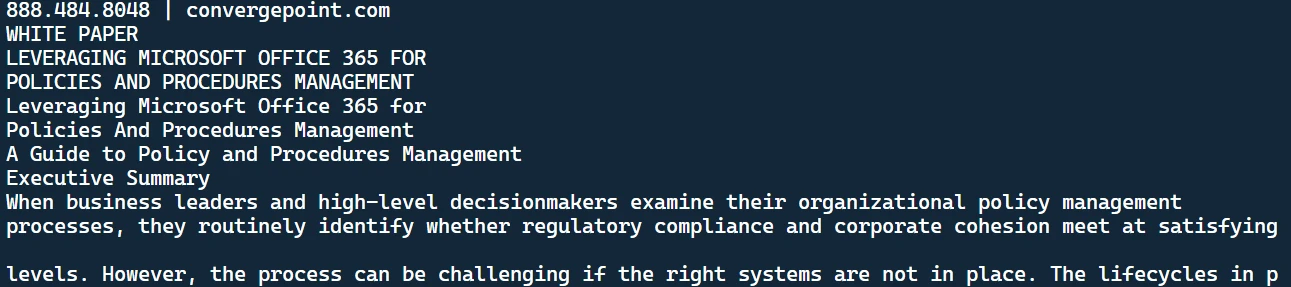 El texto extraído
El texto extraído
Es el texto recuperado del archivo PDF. También notarás un documento de texto creado en tu directorio.
 El texto extraído almacenado en un archivo TXT
El texto extraído almacenado en un archivo TXT
En este archivo de texto, encontrarás el formato de texto que se ha recuperado, presentado de manera secuencial.
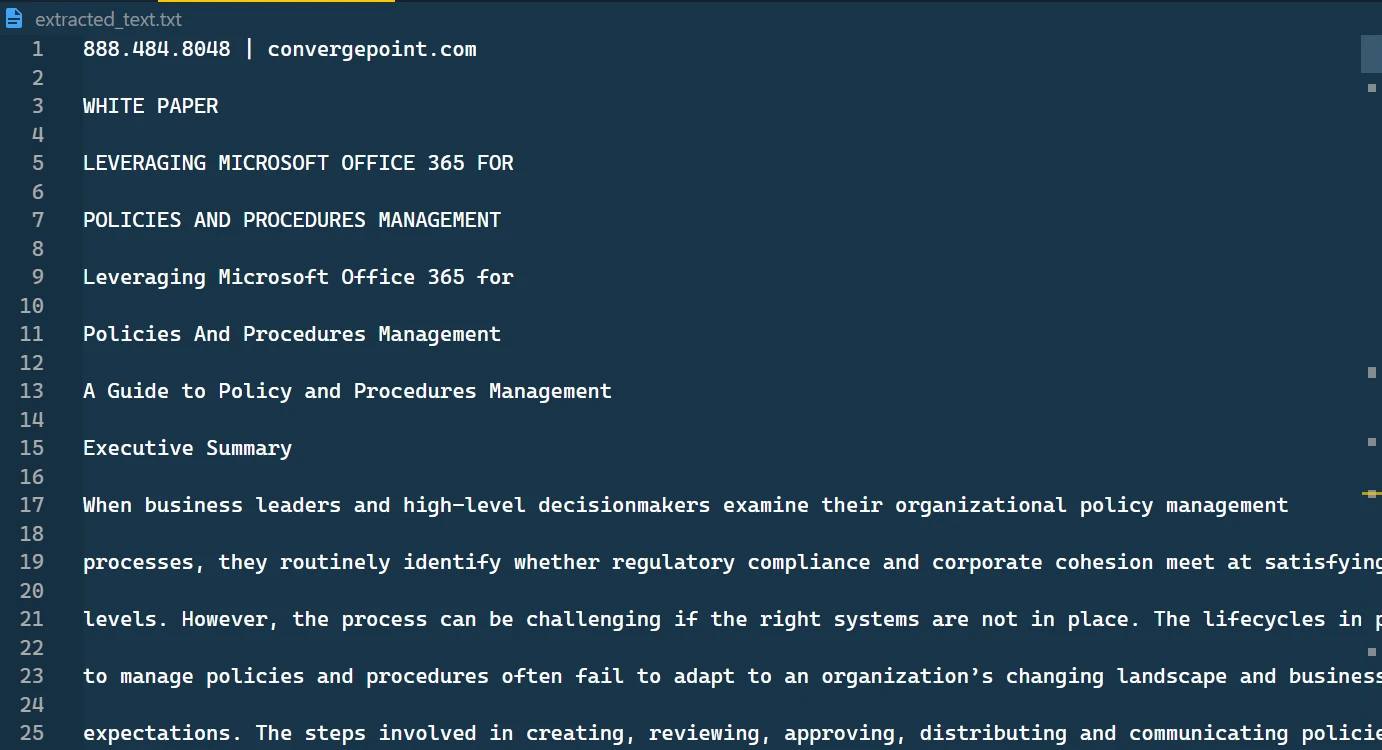 El contenido del archivo de texto extraído
El contenido del archivo de texto extraído
Conclusión
En conclusión, usar IronPDF y Python para extraer texto de archivos PDF es un enfoque robusto y sencillo, ya sea extrayendo texto de todo el documento, de páginas específicas o incluso línea por línea. El beneficio adicional de guardar este texto recuperado en un archivo de texto te permite gestionar y utilizar eficientemente los datos para procesamiento futuro. IronPDF resulta ser una herramienta invaluable en el manejo de PDFs, ofreciendo una variedad de funcionalidades más allá de solo la extracción de texto. También puedes convertir PDF a Texto en Python utilizando IronPDF.
Además, la creación de PDFs interactivos, completar y enviar formularios interactivos, fusionar y dividir archivos PDF, extraer texto e imágenes, buscar texto dentro de archivos PDF, rasterizar PDF en imágenes, cambiar el tamaño de fuente, color de borde y de fondo, y convertir archivos PDF son todas tareas con las que el kit de herramientas de IronPDF puede ayudar.
IronPDF no es una biblioteca de Python de código abierto. Si está considerando utilizar IronPDF para sus proyectos, la licencia del paquete comienza en $799. Sin embargo, si necesitas aclaración sobre la inversión, IronPDF ofrece una prueba gratuita para explorar a fondo sus características.
Preguntas Frecuentes
¿Cómo puedo extraer texto de un PDF usando Python?
Puede usar IronPDF para extraer texto de archivos PDF en Python. Implica cargar el PDF con el método PdfDocument.FromFile e iterar a través de las páginas para extraer texto línea por línea.
¿Qué se requiere para comenzar a extraer texto de PDF en Python?
Para extraer texto de PDFs en Python, necesita tener Python instalado, junto con la biblioteca IronPDF, que puede instalarse a través de pip. Se recomienda un IDE como Visual Studio Code para escribir y ejecutar sus scripts.
¿Puede IronPDF extraer texto de una página específica en un PDF?
Sí, IronPDF le permite extraer texto de una página específica de un PDF usando el método ExtractTextFromPage, especificando el índice de la página.
¿Cómo puedo guardar el texto extraído en un archivo en Python?
Después de extraer texto usando IronPDF, puede guardarlo en un archivo escribiendo las líneas de texto extraídas en un archivo de texto utilizando los métodos de manejo de archivos de Python.
¿Qué características adicionales ofrece IronPDF además de la extracción de texto?
IronPDF ofrece una amplia gama de características que incluyen la creación, edición y conversión de PDFs, la fusión y división de documentos PDF, la extracción de imágenes y la conversión de PDFs a otros formatos de archivo.
¿Cómo licencio IronPDF en mi proyecto Python?
Para licenciar IronPDF, establezca su clave de licencia en el script de Python usando la propiedad License.LicenseKey, que desbloquea la funcionalidad completa de la biblioteca.
¿Es posible probar IronPDF antes de comprarlo?
Sí, IronPDF ofrece una versión de prueba que le permite evaluar sus características antes de decidir comprar una licencia completa.
¿Qué debo hacer si encuentro problemas durante la extracción de texto de PDF?
Asegúrese de que IronPDF esté correctamente instalado y con licencia, y que su entorno Python esté correctamente configurado. Consulte la documentación o los recursos de soporte para solucionar problemas comunes.
¿Puedo convertir un PDF a una imagen usando IronPDF?
Sí, IronPDF proporciona funcionalidad para rasterizar PDFs en imágenes, lo que le permite convertir documentos completos o páginas específicas en archivos de imagen.
¿Cómo ejecuto un script de Python para la extracción de texto de PDF?
Después de escribir su script, puede ejecutarlo ejecutando python main.py en el terminal de su IDE, donde main.py es el nombre de su archivo de script.
















