JavaでString.splitを使用する方法
Javaプログラミングのダイナミックな世界では、文字列操作は開発者がさまざまなタスクで頻繁に使用する基本的なスキルです。 split() メソッドは、java.lang.String クラス内にあり、指定された区切り文字に基づいて文字列を部分文字列に分割するための強力なツールとして際立っています。
この記事では、split() method を深く掘り下げ、その構文、用途を理解し、Java 開発者が文字列操作を習得できるようにするための例を示します。
String.split()の基本を理解する
Java の String.split() メソッドは、パラメータとして指定された文字列区切り文字に基づいて文字列を分割するために使用される強力なツールです。 この方法を利用するとき、開発者は文字列の正規表現パターンや簡単な文字をデリミタとして定義し、与えられた文字列を分割できます。
Java String split() メソッドは public かつ static であり、Java プログラムの main メソッド内によく見られます。このメソッドでは、string args パラメータをコマンドライン入力に使用できます。 メソッドの結果は、分割操作から得られるすべてのサブストリングを含む文字列配列です。
開発者は、limit パラメータに注意する必要があります。このパラメータは、特に正規表現を区切り文字として使用する場合に、配列に含まれる空の文字列の数に影響を与える可能性があるためです。 正規表現パターンと区切り文字の選択を慎重に検討することで、split() メソッドが元の文字列を正確に分割し、後続の処理のための包括的な部分文字列の配列を提供することが保証されます。
スプリットメソッドの構文
メソッドの構文では、分割する文字列全体 str を表す string str と、結果として得られる配列内の部分文字列の最大数を制御するオプションの int limit パラメータが含まれます。 split() メソッドは、分かりやすい構文を提供します。
public String[] split(String regex)public String[] split(String regex)regex: 文字列を分割するための区切り文字として機能する正規表現。
メソッドは指定された正規表現に基づいて元の文字列を分割して得られるサブストリングを表す文字列配列を返します。
String.split()の実用的な応用
トークン化とデータ解析
split() は、特に CSV (カンマ区切り値) や TSV (タブ区切り値) のようなデータ形式を扱う場合に、文字列をトークン化するのに非常に役立ちます。 開発者が文字列を個々のデータ要素に分割できるようにします。
String csvData = "John,Doe,30,New York";
String[] tokens = csvData.split(",");String csvData = "John,Doe,30,New York";
String[] tokens = csvData.split(",");次のトークンは、スプリットメソッドに提供された正規表現に基づいて生成されます:
tokens: ["John", "Doe", "30", "New York"]文章から単語を抽出する
自然言語処理タスクでは、split() は文から個々の単語を抽出するのに便利です。
String sentence = "Java programming is fascinating";
String[] words = sentence.split(" ");String sentence = "Java programming is fascinating";
String[] words = sentence.split(" ");ここでは、Javaのstring splitメソッドがスペースで文章の単語を分割します:
words: ["Java", "programming", "is", "fascinating"]URLコンポーネントの解析
URLを扱う場合、split() を使用すると、プロトコル、ドメイン、パスなどのコンポーネントを抽出できます。
String url = "https://www.example.com/page/index.html";
String[] urlComponents = url.split(":|/|\\.");
// urlComponents: ["https", "https", "www", "example", "com", "page", "index", "html"]String url = "https://www.example.com/page/index.html";
String[] urlComponents = url.split(":|/|\\.");
// urlComponents: ["https", "https", "www", "example", "com", "page", "index", "html"]Javaコード例でString.split()の使用を示す
例1: 基本トークン化
String array = "Apple,Orange,Banana";
String[] fruits = array.split(",");
for (String fruit : fruits) {
System.out.println(fruit);
}String array = "Apple,Orange,Banana";
String[] fruits = array.split(",");
for (String fruit : fruits) {
System.out.println(fruit);
}出力
Apple
Orange
Banana例2: 単語の抽出
String str = "Java programming is versatile";
String[] words = str.split(" ");
for (String word : words) {
System.out.println(word);
}String str = "Java programming is versatile";
String[] words = str.split(" ");
for (String word : words) {
System.out.println(word);
}出力
Java
programming
is
versatile例3: URLコンポーネントの解析
String url = "https://www.example.com/page/index.html";
String[] urlComponents = url.split(":|/|\\.");
for (String component : urlComponents) {
System.out.println(component);
}String url = "https://www.example.com/page/index.html";
String[] urlComponents = url.split(":|/|\\.");
for (String component : urlComponents) {
System.out.println(component);
}出力
https
www
example
com
page
index
htmlIronPDF for JavaとString.split()の互換性の紹介
IronPDF for Javaの紹介
IronPDF for Javaは、PDFの生成および操作を簡単にするための機能を開発者に提供する堅牢なライブラリとして立っています。 HTMLをPDFにレンダリングすることから既存のファイルを変換することまで、IronPDFはJavaアプリケーションにおけるドキュメント処理の必要性を持つ複雑なPDF関連タスクを簡略化します。
IronPDFをJavaの依存関係として定義
IronPDFをJavaプロジェクトで使用し始めるには、プロジェクトの設定で依存関係として定義する必要があります。 以下のステップは、Mavenを使用してこれを行う方法を示しています。
pom.xml 依存関係
pom.xml ファイルに以下の依存関係を追加してください。
<dependencies>
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>20xx.xx.xxxx</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>2.0.3</version>
</dependency>
</dependencies><dependencies>
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>20xx.xx.xxxx</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>2.0.3</version>
</dependency>
</dependencies>JARファイルのダウンロード
または、SonatypeからJARファイルを手動でダウンロードできます。
IronPDFを使用してPDFドキュメントを作成する
以下は、 IronPDFを使用して Java でHTML 文字列から PDF ドキュメントを生成する方法を示す簡単な例です。
import com.ironsoftware.ironpdf.*;
public class IronPDFExample {
public static void main(String[] args) {
// Create a PDF document
PdfDocument myPdf = PdfDocument.renderHtmlAsPdf("<h1>Hello, IronPDF!</h1>");
// Save the PdfDocument to a file
myPdf.saveAs("output.pdf");
System.out.println("PDF created successfully.");
}
}import com.ironsoftware.ironpdf.*;
public class IronPDFExample {
public static void main(String[] args) {
// Create a PDF document
PdfDocument myPdf = PdfDocument.renderHtmlAsPdf("<h1>Hello, IronPDF!</h1>");
// Save the PdfDocument to a file
myPdf.saveAs("output.pdf");
System.out.println("PDF created successfully.");
}
}コード例はHTML文字列から生成されたPDFを生成します。 ここに出力があります:
より複雑なPDFタスクについては、このコード例ページを訪れてください。
String.split()との互換性
それでは、 IronPDFと標準 Java 文字列操作 String.split() との互換性について説明しましょう。 データを取得し、それを文字列変数に格納された HTML テーブルに変換し、IronPDF の renderHtmlAsPdf メソッドを使用して HTML テーブルから PDF を生成する例を作成してみましょう。
従業員データのリストがあると仮定すると、HTMLテーブルを作成し、PDFを生成する方法は以下の通りです。
import com.ironsoftware.ironpdf.*;
public class EmployeeDataToPDF {
// Sample list of employee data (comma-separated values: Name, Age, Position)
public static String employeeData = "John Doe,30,Software Engineer\nJane Smith,25,Graphic Designer\nBob Johnson,35,Manager";
public static void main(String[] args) {
// Split the employeeData into individual records based on newline character
String[] employeeRecords = employeeData.split("\n");
// Create HTML table string
StringBuilder htmlTable = new StringBuilder("<table border='1'><tr><th>Name</th><th>Age</th><th>Position</th></tr>");
// Iterate through each employee record
for (String record : employeeRecords) {
// Split the record into individual details based on the comma character
String[] details = record.split(",");
// Assuming we want to display Name, Age, and Position in the table
String name = details[0];
String age = details[1];
String position = details[2];
// Add a row to the HTML table
htmlTable.append("<tr><td>").append(name).append("</td><td>").append(age).append("</td><td>").append(position).append("</td></tr>");
}
// Close the HTML table
htmlTable.append("</table>");
// Create a PDF document using IronPDF
PdfDocument pdfDocument = PdfDocument.renderHtmlAsPdf(htmlTable.toString());
// Save the PDF to a file
pdfDocument.saveAs("EmployeeDetails.pdf");
}
}import com.ironsoftware.ironpdf.*;
public class EmployeeDataToPDF {
// Sample list of employee data (comma-separated values: Name, Age, Position)
public static String employeeData = "John Doe,30,Software Engineer\nJane Smith,25,Graphic Designer\nBob Johnson,35,Manager";
public static void main(String[] args) {
// Split the employeeData into individual records based on newline character
String[] employeeRecords = employeeData.split("\n");
// Create HTML table string
StringBuilder htmlTable = new StringBuilder("<table border='1'><tr><th>Name</th><th>Age</th><th>Position</th></tr>");
// Iterate through each employee record
for (String record : employeeRecords) {
// Split the record into individual details based on the comma character
String[] details = record.split(",");
// Assuming we want to display Name, Age, and Position in the table
String name = details[0];
String age = details[1];
String position = details[2];
// Add a row to the HTML table
htmlTable.append("<tr><td>").append(name).append("</td><td>").append(age).append("</td><td>").append(position).append("</td></tr>");
}
// Close the HTML table
htmlTable.append("</table>");
// Create a PDF document using IronPDF
PdfDocument pdfDocument = PdfDocument.renderHtmlAsPdf(htmlTable.toString());
// Save the PDF to a file
pdfDocument.saveAs("EmployeeDetails.pdf");
}
}この例では、StringBuilder を使用して HTML テーブル文字列を動的に生成し、各行を従業員の詳細で囲みます。 このHTMLテーブルには、Name、Age、およびPositionなどのヘッダーが組み込まれており、社員データの構造化された表現を保証します。 IronPDFのrenderHtmlAsPdfメソッドを活用することで、HTMLテーブルをPDFドキュメントにシームレスに変換し、JavaでHTMLとPDFの世界をシームレスに融合させます。 生成されたPDFは、視覚的に魅力的な形式で社員のタブラー詳細をカプセル化しています。 最後に、プログラムは"EmployeeDetails.pdf"として結果のPDFを保存し、社員データを保存し提示するための便利で共有可能な形式を提供します。
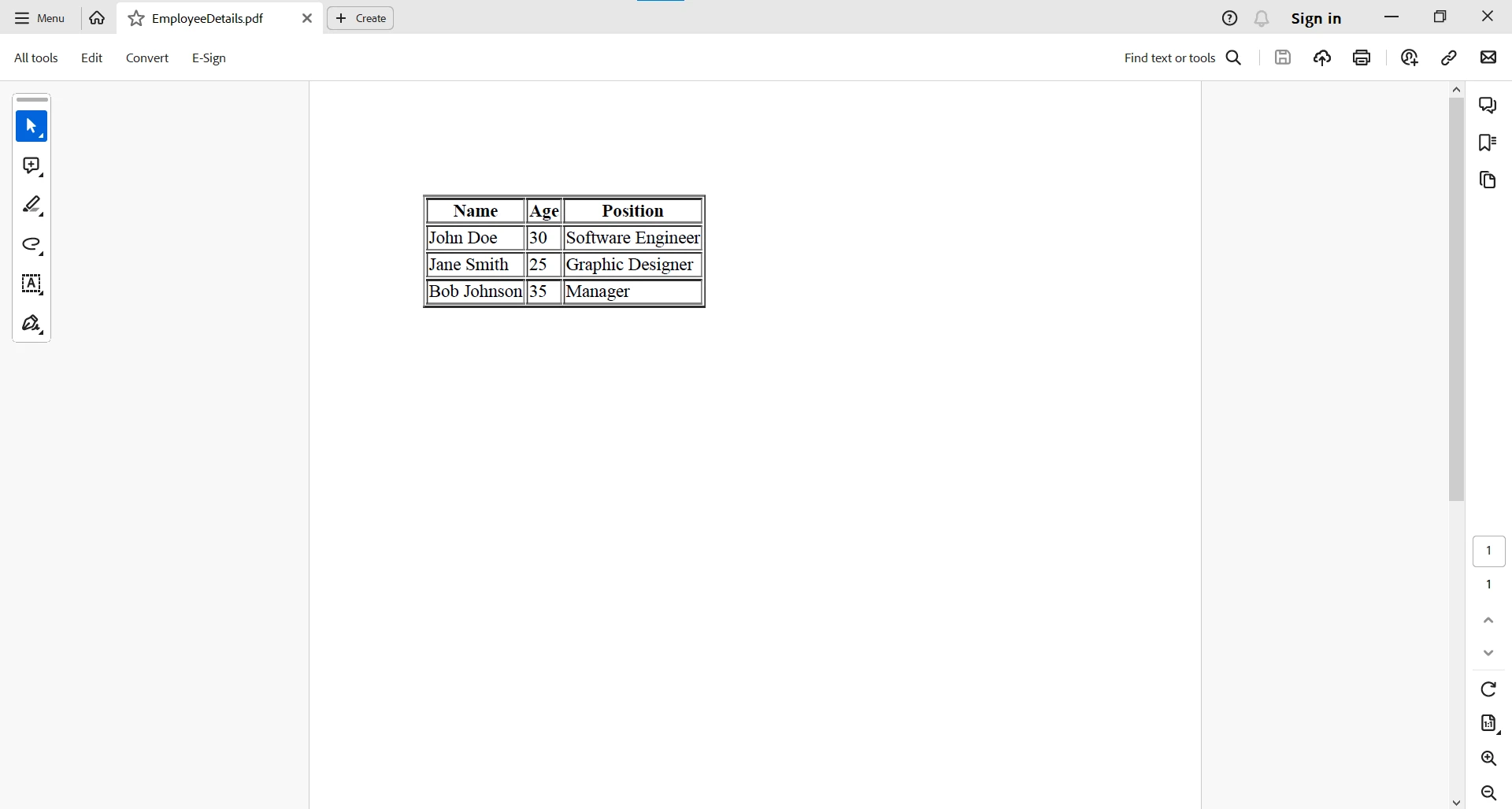
結論
JavaのStringクラスのメソッドsplit()を使用すると、開発者は文字列を簡単に解析および操作できます。 その柔軟性とさまざまなシナリオにおける適用性から、データ解析やURLコンポーネント抽出などの用途において、Java開発者のツールキットにとって貴重なツールとなります。 split() 文字列メソッドを習得することで、開発者はすべての文字列を効率的に処理できるようになり、堅牢で汎用性の高い Java アプリケーションの開発に貢献できます。 データの分解、意味のある情報の抽出、文字の分割、テキストのトークン化など、split() メソッドは、進化し続ける Java プログラミングの分野で、文字列操作のための強力なメカニズムを提供します。
詳細な互換性シナリオにより、IronPDFの能力を標準Java文字列操作と一緒に自信を持って活用し、アプリケーション全体の機能性と汎用性を強化することができます。 PDFドキュメントを操作しても文字列を処理しても、IronPDFと標準Java操作の間のシナジーにより、包括的で機能豊富なJavaアプリケーションを作成できます。
PDF関連タスクの作業方法について詳しくは、ドキュメントページをご覧ください。
IronPDFは商用使用のための無料試用版を提供します。