
fastparquet Python(開発者向けのしくみ)
fastparquet は、ビッグデータワークフローで一般的に使用されるParquetファイル形式を扱うために設計されたPythonライブラリです。 DaskやPandasのような他 for Pythonベースのデータ処理ツールとよく統合されます。 その機能を探り、コード例をいくつか見てみましょう。 この記事の後半では、IronPDF、Iron SoftwareからのPDF生成ライブラリについても学びます。
fastparquetの概要
fastparquet は効率的で、幅広いParquetの機能をサポートしています。 その主要な機能のいくつかは以下の通りです:
Parquetファイルの読み書き
Parquetファイルやその他のデータファイルから簡単に読み取り、書き込みができます。
PandasとDaskとの統合
Pandas DataFramesとDaskとシームレスに連携して並列処理が可能です。
圧縮サポート
データファイル内でgzip、snappy、brotli、lz4、zstandardなどのさまざまな圧縮アルゴリズムをサポートします。
効率的なストレージ
parquet列型ファイル形式とファイルへのポインティングメタデータファイルを使用して、大規模なデータセットやデータファイルのストレージと取得の両方に最適化されています。
インストール
pipを使用してfastparquet をインストールできます。
pip install fastparquetpip install fastparquetまたはcondaを使用してインストールできます。
conda install -c conda-forge fastparquetconda install -c conda-forge fastparquet基本的な使い方
こちらはfastparquetを使った簡単な例です。
Parquetファイルの書き込み
Pandas DataFrameをParquetファイルに書き込みできます。
import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
})
# Write the DataFrame to a Parquet file
df.to_parquet('example.parquet', engine='fastparquet')
# Display confirmation message
print("DataFrame successfully written to 'example.parquet'.")import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
})
# Write the DataFrame to a Parquet file
df.to_parquet('example.parquet', engine='fastparquet')
# Display confirmation message
print("DataFrame successfully written to 'example.parquet'.")出力
![]()
Parquetファイルの読み込み
ParquetファイルをPandas DataFrameに読み込めます。
import pandas as pd
# Read a Parquet file
df = pd.read_parquet('example.parquet', engine='fastparquet')
# Display the DataFrame
print(df.head())import pandas as pd
# Read a Parquet file
df = pd.read_parquet('example.parquet', engine='fastparquet')
# Display the DataFrame
print(df.head())出力

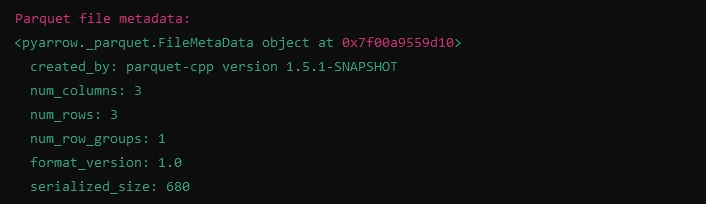
Parquetファイルのメタデータ表示
import fastparquet as fp
# Reading metadata from Parquet file
meta = fp.ParquetFile('example.parquet').metadata
print("Parquet file metadata:")
print(meta)import fastparquet as fp
# Reading metadata from Parquet file
meta = fp.ParquetFile('example.parquet').metadata
print("Parquet file metadata:")
print(meta)出力
高度な機能
並列処理のためのDaskの使用
fastparquetは大規模データセットを並列に処理するためにDaskとよく統合されます。
import dask.dataframe as dd
# Read a Parquet file into a Dask DataFrame
ddf = dd.read_parquet('example.parquet', engine='fastparquet')
# Perform operations on the Dask DataFrame
result = ddf.groupby('name').mean().compute()
# Display the result
print(result)import dask.dataframe as dd
# Read a Parquet file into a Dask DataFrame
ddf = dd.read_parquet('example.parquet', engine='fastparquet')
# Perform operations on the Dask DataFrame
result = ddf.groupby('name').mean().compute()
# Display the result
print(result)圧縮のカスタマイズ
Parquetファイルを書き込む際に異なる圧縮アルゴリズムを指定できます。
import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35]
})
# Write the DataFrame to a Parquet file with gzip compression
df.to_parquet('example.parquet', engine='fastparquet', compression='gzip')import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35]
})
# Write the DataFrame to a Parquet file with gzip compression
df.to_parquet('example.parquet', engine='fastparquet', compression='gzip')IronPDFの紹介
IronPDFは、HTML、CSS、画像、JavaScriptから派生したPDFドキュメントの生成、修正、デジタル署名のために作成された堅牢なPythonライブラリです。 パフォーマンスに優れ、最小限のメモリ占有で動作します。 主な機能は以下の通りです。
1. HTMLからPDFへの変換
HTMLファイル、HTML文字列、URLをIronPDFを使用してPDFドキュメントに変換します。 例えば、Chrome PDFレンダラーを使用してウェブページをPDFにレンダリングできます。
2. クロスプラットフォームサポート
Windows、Mac、Linux、およびさまざまなクラウドプラットフォームでPython 3+と互換性があります。 IronPDFは.NET、Java、Python、Node.js環境でも利用可能です。
3. 編集と署名
ドキュメントのプロパティを修正し、パスワード保護と権限でセキュリティを強化し、IronPDFを使用してPDFにデジタル署名を統合します。
4. ページテンプレートと設定
カスタマイズされたヘッダー、フッター、ページ番号、および調整可能な余白でPDFをカスタマイズします。 レスポンシブレイアウトをサポートし、カスタム用紙サイズに対応しています。
5. 標準準拠
PDF/AやPDF/UAのようなPDF標準に準拠しています。 UTF-8文字エンコーディングを処理し、画像、CSSスタイルシート、フォントなどのアセットを効果的に管理します。
IronPDFとfastparquetを使用してPDFドキュメントを生成する
Python用IronPDFの前提条件
- IronPDF は、基盤技術として.NET 6.0を利用しています。 したがって、.NET 6.0ランタイムがシステムにインストールされていることを確認してください。
- Python 3.0+: Pythonバージョン3以上がインストールされていることを確認してください。
- pip: IronPDFパッケージをインストールするため for Pythonパッケージインストーラーpip をインストールしてください。
インストール
# Install latest version of the libraries
pip install fastparquet
pip install pandas
pip install ironpdf# Install latest version of the libraries
pip install fastparquet
pip install pandas
pip install ironpdfコード例
以下のコード例は、PythonでfastparquetとIronPDFを一緒に使用する方法を示しています。
import pandas as pd
import fastparquet as fp
from ironpdf import ChromePdfRenderer, License
# Apply your license key for IronPDF
License.LicenseKey = "your Key"
# Sample DataFrame
data = {
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
# Writing DataFrame to a Parquet file
fp.write('example.parquet', df)
# Reading from Parquet file into DataFrame
df_read = fp.ParquetFile('example.parquet').to_pandas()
# Displaying the read DataFrame
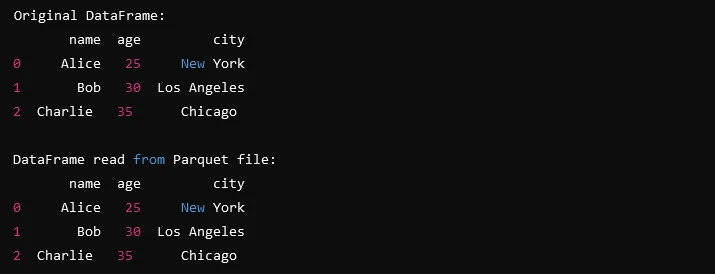
print("Original DataFrame:")
print(df)
print("\nDataFrame read from Parquet file:")
print(df_read)
# Initialize a ChromePdfRenderer instance
renderer = ChromePdfRenderer()
# Create a PDF from a HTML string using IronPDF
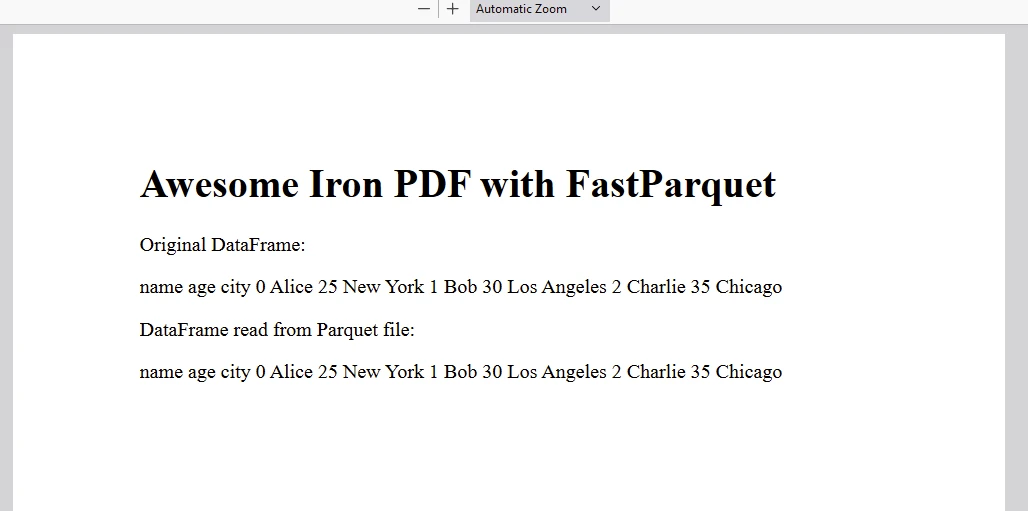
content = "<h1>Awesome Iron PDF with FastParquet</h1>"
content += "<p> Original DataFrame:</p>"
content += "<p>" + f"{str(df)}" + "</p>"
content += "<p> DataFrame read from Parquet file:</p>"
content += "<p>" + f"{str(df_read)}" + "</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Export the PDF to a file
pdf.SaveAs("Demo-FastParquet.pdf")import pandas as pd
import fastparquet as fp
from ironpdf import ChromePdfRenderer, License
# Apply your license key for IronPDF
License.LicenseKey = "your Key"
# Sample DataFrame
data = {
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
# Writing DataFrame to a Parquet file
fp.write('example.parquet', df)
# Reading from Parquet file into DataFrame
df_read = fp.ParquetFile('example.parquet').to_pandas()
# Displaying the read DataFrame
print("Original DataFrame:")
print(df)
print("\nDataFrame read from Parquet file:")
print(df_read)
# Initialize a ChromePdfRenderer instance
renderer = ChromePdfRenderer()
# Create a PDF from a HTML string using IronPDF
content = "<h1>Awesome Iron PDF with FastParquet</h1>"
content += "<p> Original DataFrame:</p>"
content += "<p>" + f"{str(df)}" + "</p>"
content += "<p> DataFrame read from Parquet file:</p>"
content += "<p>" + f"{str(df_read)}" + "</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Export the PDF to a file
pdf.SaveAs("Demo-FastParquet.pdf")コードの説明
このコードスニペットは、HTMLコンテンツからデータを操作し、PDFドキュメントを生成するためにいくつか for Pythonライブラリを利用する方法を示しています。
1.インポートとセットアップ:データ操作、Parquet ファイルの読み取りと書き込み、PDF 生成に必要なライブラリをインポートします。
2.ライセンス キーの設定: IronPDFのライセンス キーを設定し、すべての機能を有効にします。
サンプルDataFrameの作成: 個人情報(名前、年齢、都市)を含むサンプルDataFrame (
df) を定義します。DataFrameをParquetに書き込む: DataFrame
dfをexample.parquetという名前のParquetファイルに書き込みます。Parquetファイルから読み込む: Parquetファイル (
example.parquet) からデータを読み込み、DataFrame (df_read) に戻します。- HTMLからPDFを生成する:
- IronPDFを使用してChromePdfRendererインスタンスを初期化します。
- 見出し (
<h1>) と段落 (<p>) を含むHTML文字列 (content) を構築し、元のDataFrame (df) とParquetファイルから読み込まれたDataFrame (df_read) を表示します。 - IronPDFでHTMLコンテンツをPDFドキュメントとしてレンダリングします。
- 生成されたPDF文書を
Demo-FastParquet.pdfとして保存します。
このコードは、FastParquetのサンプルコードを示しており、データ処理機能とPDF生成を統合して、parquetファイルに保存されたデータに基づいてレポートや文書を作成するのに役立ちます。
出力
出力 PDF
IronPDFライセンス
ライセンス情報については、IronPDFライセンスページをご覧ください。
スクリプトを開始する前に、IronPDFパッケージを使用する前にライセンスキーを配置します。
from ironpdf import License
# Apply your license key
License.LicenseKey = "your Key"from ironpdf import License
# Apply your license key
License.LicenseKey = "your Key"結論
fastparquet は、PythonでParquetファイルを操作するための強力で効率的なライブラリです。 PandasやDaskとの統合により、Pythonベースのビッグデータワークフローで大規模なデータセットを扱うための優れた選択肢となっています。 IronPDF は、Pythonアプリケーションから直接PDFドキュメントの作成、操作、レンダリングを支援する堅牢なPythonライブラリです。 HTMLコンテンツをPDFドキュメントに変換し、インタラクティブなフォームを作成したり、ファイルの結合やウォーターマークの追加などのさまざまなPDF操作を簡単に行えます。 IronPDFは既存 for Pythonフレームワークと環境とシームレスに統合され、動的にPDFドキュメントを生成・カスタマイズするための多目的な解決策を開発者に提供します。 fastparquetとIronPDFを組み合わせることで、Parquetファイルフォーマットでのデータ操作とPDF生成をシームレスに行えます。
IronPDFは、開発者がその機能を最大限に活用するための包括的なドキュメントとコード例を提供しています。 詳細については、ドキュメントおよびコード例ページをご覧ください。
















