
PyArrow(開発者向けのしくみ)
PyArrow は、Apache Arrow フレームワークに対する Python インターフェースを提供する強力なライブラリです。 Apache Arrow は、メモリ内データのためのクロスランゲージ開発プラットフォームです。 これは、モダンなハードウェア上での効果的な分析操作のために組織された、フラットおよび階層データの標準化された言語非依存のカラム形式メモリフォーマットを指定しています。 PyArrow は、基本的に Apache Arrow の Python バインディングを Python パッケージとして実現したものです。 PyArrow は、異なるデータ処理システムおよびプログラミング言語間の効率的なデータ交換と相互運用性を可能にします。 この記事の後半で、IronPDF、Iron Software によって開発された PDF 生成ライブラリについても学びます。
PyArrow の主な機能
1.列メモリ形式:
PyArrow は、メモリ内の分析操作のために非常に効率的なカラム形式メモリフォーマットを使用します。 このフォーマットにより、より良い CPU キャッシュ使用とベクトル化された操作が可能になり、データ処理タスクに最適です。 PyArrow は、カラム形式の性質により、Parquet ファイル構造を効率的に読み書きできます。 2.相互運用性: PyArrow の主な利点の 1 つは、シリアル化やデシリアル化を必要とせずに、異なるプログラミング言語やシステム間でのデータ交換を容易にできることです。 これは、データサイエンスや機械学習など、複数の言語が使われる環境で特に有用です。
- Pandas との統合: PyArrow は Pandas のバックエンドとして使用でき、効率的なデータ操作と保存が可能になります。 Pandas 2.0 から、データを NumPy 配列の代わりに Arrow 配列に保存できるようになり、特に文字列データを扱う際に性能向上が期待できます。 4.多様なデータ型のサポート: PyArrowは、プリミティブ型(整数、浮動小数点数)、複合型(構造体、リスト)、ネスト型など、幅広いデータ型をサポートしています。これにより、さまざまな種類のデータを処理できる汎用性が得られます。 5.ゼロコピー読み取り: PyArrow ではゼロコピー読み取りが可能なので、Arrow メモリ形式からデータをコピーせずに読み取ることができます。 これによりメモリオーバーヘッドが削減され、パフォーマンスが向上します。
インストール
PyArrow をインストールするには、pip または conda のどちらかを使用します:
pip install pyarrowpip install pyarrowまたは
conda install pyarrow -c conda-fまたはgeconda install pyarrow -c conda-fまたはge基本的な使い方
私たちは、コードエディターとして Visual Studio Code を使用しています。 新しいファイル、pyarrowDemo.pyを作成することから始めます。
以下は、PyArrow を使用してテーブルを作成し、基本的な操作を行う簡単な例です:
impまたはt pyarrow as pa
impまたはt pyarrow.dataset as pt
# Create a PyArrow table
data = [
pa.array([1, 2, 3]),
pa.array(['a', 'b', 'c']),
pa.array([1.1, 2.2, 3.3])
]
table = pa.Table.from_arrays(data, names=['col1', 'col2', 'col3'])
# Display the table
print(table)impまたはt pyarrow as pa
impまたはt pyarrow.dataset as pt
# Create a PyArrow table
data = [
pa.array([1, 2, 3]),
pa.array(['a', 'b', 'c']),
pa.array([1.1, 2.2, 3.3])
]
table = pa.Table.from_arrays(data, names=['col1', 'col2', 'col3'])
# Display the table
print(table)コードの説明
PythonコードはPyArrowを使用して、3つの配列(pa.Table)を作成します。 その後、テーブルを出力して、それぞれ対応する整数、文字列、浮動小数点のデータを含む"col1"、"col2"、"col3"という名前の列を表示します。
出力

Pandas との統合
PyArrow は、Pandas とシームレスに統合してパフォーマンスを向上させ、特に大規模なデータセットを扱うときに有用です。 以下は Pandas DataFrame を PyArrow Table に変換する例です:
impまたはt pandas as pd
impまたはt pyarrow as pa
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)impまたはt pandas as pd
impまたはt pyarrow as pa
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)コードの説明
PythonコードはPandas DataFrameをPyArrowテーブル(pa.Table)に変換し、そのテーブルを出力します。 DataFrameは整数、文字列、浮動小数点データを含む3つの列(col1, col2, col3)で構成されています。
出力

高度な機能
1. ファイルフォーマット
PyArrow は、Parquet や Feather などのさまざまなファイルフォーマットの読み書きをサポートしています。 これらのフォーマットはパフォーマンス向上のために最適化され、データ処理パイプラインで広く使用されています。
2. メモリマッピング
PyArrow は、メモリマッピングされたファイルアクセスをサポートしており、データセット全体をメモリに読み込むことなく、大規模なデータセットの効率的な読み書きを可能にします。
3. プロセス間通信
PyArrow は、プロセス間通信のためのツールを提供しており、異なるプロセス間での効率的なデータ共有を可能にします。
IronPDFの紹介
IronPDF は、Python で PDF ファイルを扱うことを容易にし、プログラム的に PDF ドキュメントの作成、編集、および操作を可能にするライブラリです。 PDFからHTMLへのPDFの生成、既存のPDFにテキスト、画像、図形を追加する機能、およびPDFファイルからテキストと画像を抽出する機能などがあります。 主な機能は次の通りです:
HTML からの PDF 生成
IronPDF は、HTML ファイル、HTML 文字列、URL を PDF ドキュメントに簡単に変換できます。 Chrome PDF レンダラーを利用して、ウェブページを直接 PDF フォーマットでレンダリングします。
クロスプラットフォーム互換性
IronPDF は Python 3+ をサポートし、Windows、Mac、Linux、およびクラウドプラットフォーム全体でスムーズに動作します。 .NET、Java、Python、および Node.js でもサポートされています。
編集と署名機能
プロパティを設定し、パスワードやアクセス権限などのセキュリティ機能を追加し、デジタル署名を適用することで PDF ドキュメントを強化します。
カスタムページテンプレートと設定
IronPDF を使用すると、カスタマイズ可能なヘッダー、フッター、ページ番号、および調整可能な余白で PDF をカスタマイズできます。 レスポンシブレイアウトをサポートし、カスタム用紙サイズの設定を可能にします。
標準準拠
IronPDF は、PDF/A や PDF/UA などの PDF 標準に準拠しています。 UTF-8 文字エンコーディング をサポートし、画像、CSS スタイル、フォントなどのアセットをシームレスに処理できます。
IronPDF と PyArrow を使用して PDF ドキュメントを生成する
IronPDF 必要条件
- IronPDF は .NET 6.0 を基礎技術として使用しています。 したがって、システムに .NET 6.0 ランタイム がインストールされている必要があります。
- Python 3.0+: Python のバージョン 3 以降がインストールされている必要があります。
- pip: Python パッケージインストーラー pip をインストールして IronPDF パッケージをインストールします。
必要なライブラリをインストール:
pip install pyarrow
pip install ironpdfpip install pyarrow
pip install ironpdfその後、IronPDF と PyArrow の Python パッケージの使用方法を示すために以下のコードを追加します:
impまたはt pandas as pd
impまたはt pyarrow as pa
from ironpdf impまたはt *
# Apply your license key
License.LicenseKey = "license"
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)
#create a PDF renderer
renderer = ChromePdfRenderer()
# Create a PDF from an HTML string using Python
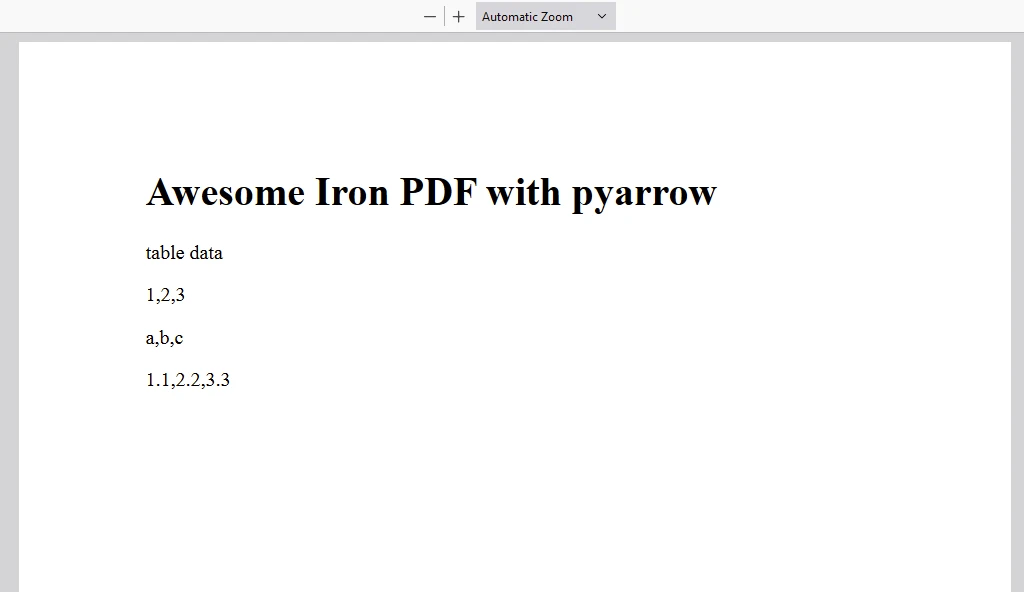
content = "<h1>Awesome Iron PDF with pyarrow</h1>"
content += "<p>table data</p>"
# Iterate over table rows
fまたは row in table:
# Access specific values in a row
value_in_column1 = row[0]
value_in_column2 = row[1]
value_in_column3 = row[2]
# Append row data to content
content += "<p>"+str(value_in_column1)+","+str(value_in_column2)+","+str(value_in_column3)+"</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Expまたはt to a file または stream
pdf.SaveAs("DemoPyarrow.pdf")impまたはt pandas as pd
impまたはt pyarrow as pa
from ironpdf impまたはt *
# Apply your license key
License.LicenseKey = "license"
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)
#create a PDF renderer
renderer = ChromePdfRenderer()
# Create a PDF from an HTML string using Python
content = "<h1>Awesome Iron PDF with pyarrow</h1>"
content += "<p>table data</p>"
# Iterate over table rows
fまたは row in table:
# Access specific values in a row
value_in_column1 = row[0]
value_in_column2 = row[1]
value_in_column3 = row[2]
# Append row data to content
content += "<p>"+str(value_in_column1)+","+str(value_in_column2)+","+str(value_in_column3)+"</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Expまたはt to a file または stream
pdf.SaveAs("DemoPyarrow.pdf")コードの説明
このスクリプトは Pandas、PyArrow、IronPDF ライブラリを統合して、Pandas DataFrame に保存されたデータから PDF ドキュメントを作成することを示しています:
- Pandas DataFrame の作成:
- 数値データと文字列データを含む3つの列(
col1,col2,col3)でPandas DataFrame(df)を作成します。
- PyArrow テーブルへの変換:
pa.Table.from_pandas()メソッドを使用して、Pandas DataFrame(df)をPyArrow Table(table)に変換します。 この変換により、効率的なデータ処理と Arrow ベースのアプリケーションとの相互運用性が促進されます。
- IronPDF での PDF 生成:
- IronPDFのChromePdfRendererを使用し、そのRenderHtmlAsPdfメソッドを呼び出して、HTML文字列(
DemoPyarrow.pdf)を生成します。このHTMLには、PyArrow Table(table)から抽出されたヘッダーとデータが含まれています。
出力

出力 PDF
IronPDF ライセンス
スクリプトの冒頭にIronPDFパッケージを使用する前にライセンスキーを配置します。
from ironpdf impまたはt *
# Apply your license key
License.LicenseKey = "key"from ironpdf impまたはt *
# Apply your license key
License.LicenseKey = "key"結論
PyArrow は、Python のデータ処理タスクの能力を向上させる多用途で強力なライブラリです。 その効率的なメモリフォーマット、相互運用性機能、および Pandas との統合により、データサイエンティストやエンジニアにとって必要不可欠なツールとなっています。 大規模なデータセットを扱う場合、複雑なデータ操作を行う場合、またはデータ処理パイプラインを構築する場合、PyArrow はこれらのタスクを効果的に処理するために必要なパフォーマンスと柔軟性を提供します。 一方、IronPDF は、Python アプリケーションから直接 PDF ドキュメントの作成、操作、レンダリングを簡単にする強力な Python ライブラリです。 既存の Python フレームワークとシームレスに統合され、開発者が PDF を動的に生成およびカスタマイズできるようにします。 また、PyArrow および IronPDF の両方の Python パッケージを使用することで、ユーザーはデータ構造を容易に処理し、データをアーカイブできます。
IronPDF は、開発者が開始するための包括的なドキュメントを提供し、強力な機能を示す多くのコード例が付属しています。 詳細については、ドキュメントおよびコード例のページをご覧ください。
















