
PythonでPDFを画像に変換する方法
PDF(ポータブル・ドキュメント・フォーマット)は、コンテンツのフォーマットを損なわず、セキュリティ許可によりデータを保護するため、インターネットを介してデータを転送するための最も人気のあるファイル形式です。 PDFファイルをJPG画像やPNG、BMP、TIFF、GIFなどの他の画像形式に変換する必要があるシナリオがあります。 JPG変換用のオンラインリソースはたくさんありますが、Pythonで独自のPDFから画像への変換ツールを作成できたら素晴らしいでしょう。
Pythonとは何か?
Pythonは、高レベルのプログラミング言語であり、ソフトウェアアプリケーション、ウェブサイトの構築、自動化タスクの実行、データ分析の実施、人工知能と機械学習のタスクを実行するために使用されます。 また、スクリプト言語でもあり、インタープリタ型なので、迅速な開発とテストが可能です。
PDFから画像へのコンバーターを作成するには、パソコンにPython 3+がインストールされている必要があります。 公式ウェブサイトから最新バージョンをダウンロードし、インストールします。
この記事では、Python PDFから画像ライブラリを使用して独自の画像変換アプリケーションを作成します。 この目的のために、Pythonの最も人気のある2つのライブラリであるPDF2ImageとPyMuPDFを使用します。
PythonでPDFファイルを画像ファイルに変換する方法
- PDFを画像に変換するため for Pythonライブラリをインストールします。
- 任意の場所から既存のPDFファイルをロードします。
- 変換メソッドを利用します。
- ファイルのページを繰り返し処理します。
- 保存メソッドを使用して各ページをJPGまたはPNG画像として保存します。
新しいPythonファイルを作成します
- Python IDLEアプリケーションを開き、Ctrl + Nキーを押します。 テキストエディタが開きます。 これには好みのテキストエディタを使用できます。
- ファイルをpdf2image.pyとして保存し、画像に変換したいPDFファイルと同じ場所に保存します。
使用する予定の入力PDFファイルは28ページを含み、以下の通りです:

PDF2Imageライブラリを使用してPDFファイルを画像ファイルに変換する
1. PDF2Image Pythonライブラリをインストールする
PDF2Imageはpdftoppmをラップするモジュールです。 Python 3.7+で動作し、PDFをPIL画像オブジェクトに変換します。 以前のリリース履歴から、PDFを画像に変換するためにpdftoppmをラップし、Python 3+でのみ動作することがわかります。
pdf2imageパッケージをインストールするには、WindowsコマンドプロンプトまたはWindows PowerShellを開き、次のpipコマンドを使用します:
pip install pdf2imagepip install pdf2imagePip(Preferred Installer Program)はPythonのパッケージマネージャーです。 Python標準ライブラリにない機能と機能を提供するサードパーティのソフトウェアパッケージをダウンロードし、インストールします。
注意: コマンドラインのどこからでもこのコマンドを実行するには、PythonをPATHに追加する必要があります。 Python 3+の場合、pip3を使用することが推奨されます。これは、pipの更新バージョンです。
2. Popplerをインストールする
Popplerは、PDFファイルを扱うための無料かつオープンソースのライブラリです。 PDFファイルのレンダリング、コンテンツの読み取り、およびPDFファイル内のコンテンツの変更に使用されます。 主にLinuxユーザーによく使用されます。 ただし、Windowsの場合、最新バージョンのPopplerをダウンロードする必要があります。
Windowsの場合
Windowsユーザーは、こちらから最新バージョンのPopplerをダウンロードできます:@oschwartz10612版。 その後、bin/folderをPATH環境変数に追加する必要があります。
Macの場合
MacユーザーもPopplerをインストールする必要があります。 Brewを使用してインストールできます:
brew install popplerbrew install popplerLinuxの場合
ほとんどのLinuxディストリビューションにはpdftocairoコマンドラインユーティリティが付属しています。 これらのユーティリティがインストールされていない場合、パッケージマネージャーを使用してpoppler-utilsをインストールできます。
プラットフォームに依存しない方法(condaを使用)
popplerをインストールします:conda install -c conda-forge popplerconda install -c conda-forge popplerSHELLpdf2imageをインストールする:
pip install pdf2imagepip install pdf2imageSHELL
これで全て準備が整いましたので、PDFを画像に変換するコードを始めます。
3. PDFファイルを画像ファイルに変換するコード
以下のコードは、入力PDFファイルの画像変換を実行します:
from pdf2image import convert_from_path
# Notify the user that the process is starting
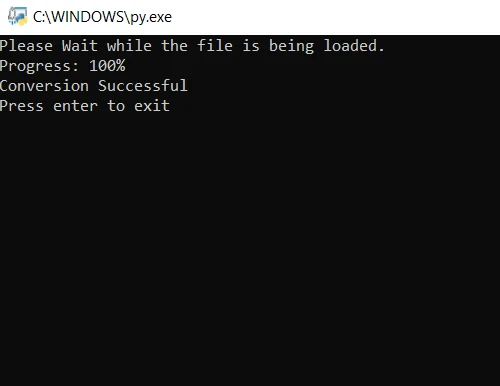
print("Please wait while the file is being loaded.")
file = convert_from_path('file.pdf')
# Iterate over all pages in the PDF file
for i in range(len(file)):
# Update user on progress
print("Progress: " + str(round(i / len(file) * 100)) + "%")
# Save each page as a JPG image file
file[i].save('page' + str(i + 1) + '.jpg', 'JPEG')
# Notify the user that the conversion is successful
print("Conversion Successful")from pdf2image import convert_from_path
# Notify the user that the process is starting
print("Please wait while the file is being loaded.")
file = convert_from_path('file.pdf')
# Iterate over all pages in the PDF file
for i in range(len(file)):
# Update user on progress
print("Progress: " + str(round(i / len(file) * 100)) + "%")
# Save each page as a JPG image file
file[i].save('page' + str(i + 1) + '.jpg', 'JPEG')
# Notify the user that the conversion is successful
print("Conversion Successful")上記のコードでは、まずconvert_from_pathメソッドを使用してファイルを開きます。 このメソッドは、指定されたパスにあるファイルを開きます。 次に、変換するPDFファイルの各ページをJPG画像に変換するためにループします。 最後にsaveメソッドを使って、変換された各ページをJPG画像ファイルとして保存します。プログラムを実行し、変換が完了するのを待ちます。 出力画像ファイルは、プログラムと同じフォルダーに保存されます。
PyMuPDFライブラリを使用してPDFファイルを画像に変換する
1. PyMuPDF Pythonライブラリをインストールする
PyMuPDFは、軽量の電子書籍、PDF、およびXPSビューア、レンダラー、およびツールキットであるMuPDFへの拡張Pythonバインディングです。 JPGやPNGなどの他の形式にPDFを変換するために使用できます。 PyMuPDFはPython 3.7以上のバージョンで動作します。
PyMuPDFパッケージをインストールするには、WindowsコマンドプロンプトまたはWindows PowerShellを開き、次のpipコマンドを使用します:
pip install pymupdfpip install pymupdfPyMuPDFは、PDF2Imageパッケージのように追加のライブラリを必要としないことに注意してください。
2. PDFファイルを画像に変換するコード
以下のコードは、PDFを画像に変換するためにPyMuPDFからfitzモジュールをインポートします:
import fitz # PyMuPDF
# Open the PDF file
doc = fitz.open("file.pdf")
# Iterate over each page in the document
for x in range(len(doc)):
page = doc.load_page(x) # Load a specific page
pix = page.get_pixmap() # Render page to image
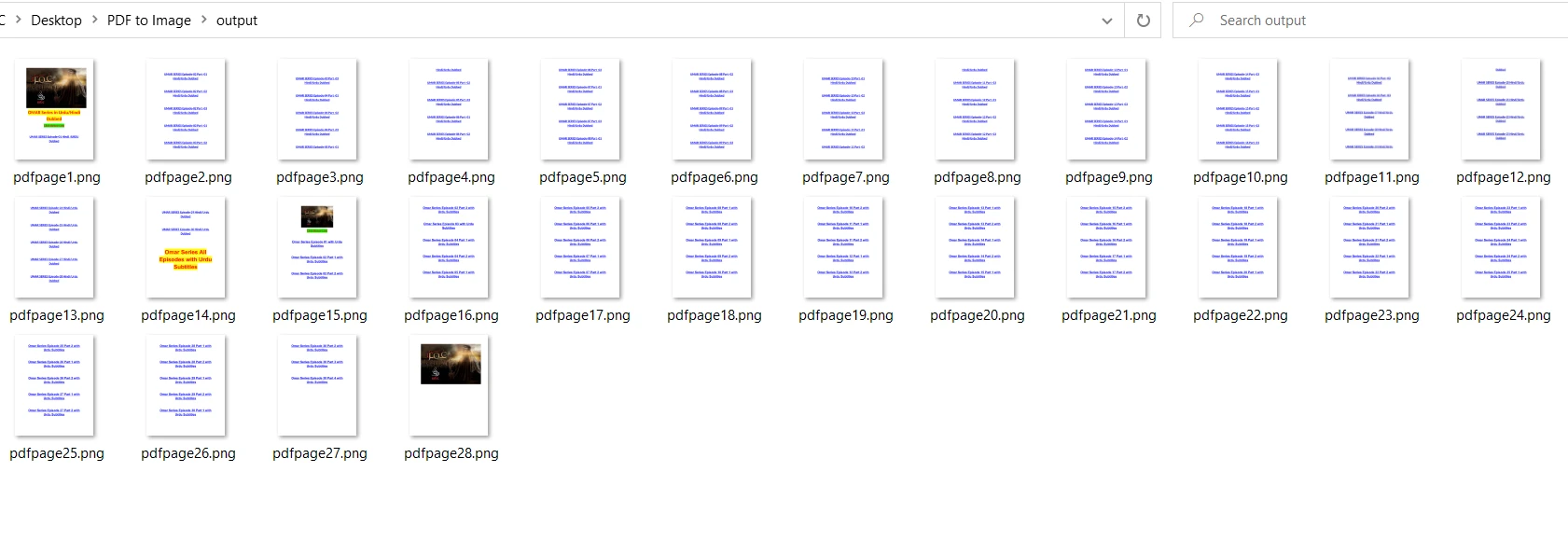
output = "output/pdfpage" + str(x + 1) + ".png" # Specify output path
pix.save(output) # Save the image to the output path
# Close the document
doc.close()import fitz # PyMuPDF
# Open the PDF file
doc = fitz.open("file.pdf")
# Iterate over each page in the document
for x in range(len(doc)):
page = doc.load_page(x) # Load a specific page
pix = page.get_pixmap() # Render page to image
output = "output/pdfpage" + str(x + 1) + ".png" # Specify output path
pix.save(output) # Save the image to the output path
# Close the document
doc.close()上記のコードでは、ファイル名をfitz.openメソッドの引数として渡してファイルを開きます。次に、文書全体をループして、各ページを別々に読み込みます。 saveメソッドで出力フォルダーに画像を保存します。 最後に、開かれたドキュメントを閉じてメモリを解放します。
PDF2Imageと比較すると、PyMuPDFはPDFをPNGに変換する際に高速です。 PDF2Imageはその圧縮率によりPNG形式では遅くなることがあります。 出力はPDF2Imageと同じです:
Rendering PDF to Image Conversions in C#
IronPDFライブラリ
IronPDFは、PDFファイルを生成、読み取り、操作するためのライブラリです。 その特技は、Chromiumエンジンを用いてHTMLをPDFにレンダリングすることです。この機能は、HTMLファイルやURLをPDFドキュメントに変換する必要がある開発者の間で人気があります。 さらに、さまざまな形式からPDFファイルへの変換を提供します。
PDFファイルを画像にラスタライズするのも、たった2行のコードで可能です。 次のコードは、PDFを異なる画像形式に変換する方法を示しています:
using IronPdf;
var Renderer = new IronPdf.ChromePdfRenderer();
var PDF = Renderer.RenderUrlAsPdf("https://example.com");
PDF.SaveAs("html.pdf");
// Rasterize the PDF
List<string> Images = PDF.RasterizeToImageFiles(ImageType.Png);using IronPdf;
var Renderer = new IronPdf.ChromePdfRenderer();
var PDF = Renderer.RenderUrlAsPdf("https://example.com");
PDF.SaveAs("html.pdf");
// Rasterize the PDF
List<string> Images = PDF.RasterizeToImageFiles(ImageType.Png);















