
Comment convertir un PDF en image en Python
PDF (Portable Document Format) est le format de fichier le plus populaire pour transférer des données sur Internet, car il préserve le formatage du contenu et aide à sécuriser les données avec des autorisations de sécurité. Il existe des scénarios où nous devons convertir des fichiers PDF en images JPG ou tout autre format d'image tel que PNG, BMP, TIFF, ou GIF. Il existe de nombreuses ressources en ligne disponibles pour la conversion JPG, mais ne serait-il pas génial de créer notre propre outil de conversion de PDF en image en Python ?
Qu'est-ce que Python ?
Python est un langage de programmation de haut niveau utilisé pour créer des applications logicielles, des sites web, automatiser des tâches, effectuer des analyses de données et réaliser des tâches d'Intelligence Artificielle et d'Apprentissage Automatique. C'est aussi un langage de script car il est interprété, ce qui le rend plus puissant en termes de développement et de test rapides.
Pour créer un convertisseur de PDF en image, nous devons avoir Python 3+ installé sur l'ordinateur. Téléchargez et installez la dernière version depuis le site officiel.
Dans cet article, nous allons créer notre propre application de conversion d'images en utilisant des bibliothèques Python PDF vers image. À cette fin, nous allons utiliser deux des bibliothèques Python les plus populaires : PDF2Image et PyMuPDF.
Comment convertir des fichiers PDF en images en Python
- Installez la bibliothèque Python pour convertir le PDF en image.
- Chargez un fichier PDF existant depuis n'importe quel emplacement.
- Utilisez des méthodes de conversion.
- Itérez à travers les pages du fichier.
- Enregistrez chaque page sous forme d'image JPG ou PNG en utilisant la méthode save.
Créer un nouveau fichier Python
- Ouvrez l'application Python IDLE et appuyez sur les touches Ctrl + N. L'éditeur de texte s'ouvrira. Vous pouvez utiliser votre éditeur de texte préféré pour cela.
- Enregistrez le fichier sous le nom pdf2image.py, dans le même emplacement que le fichier PDF que vous souhaitez convertir en images.
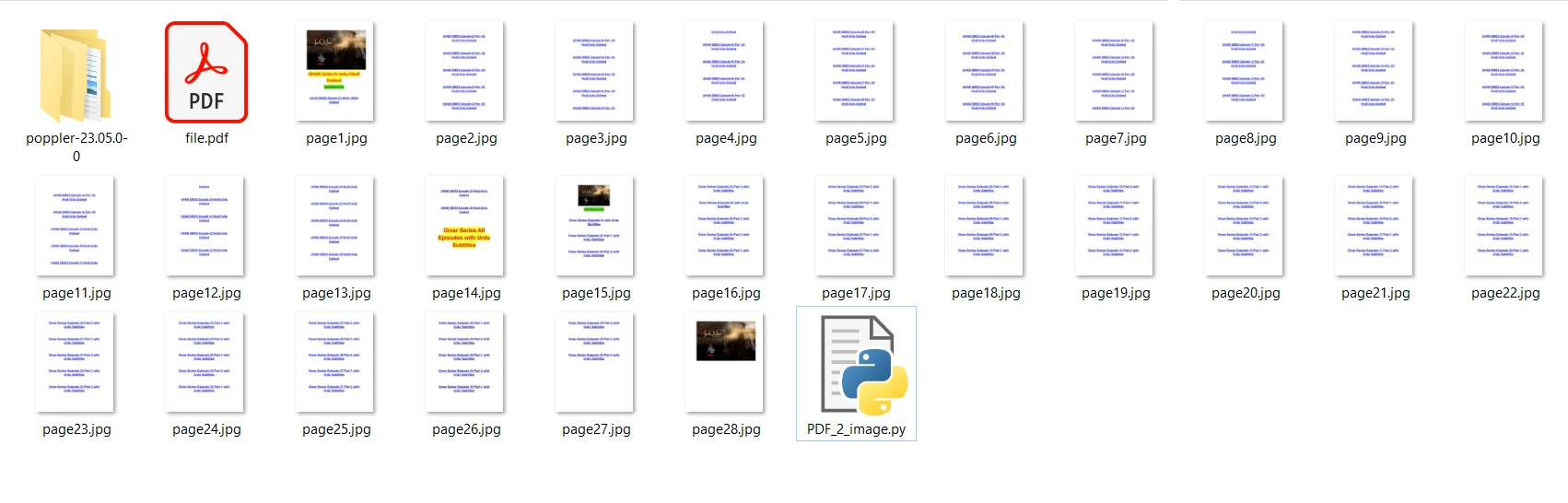
Le fichier PDF d'entrée que nous allons utiliser contient 28 pages et est le suivant :

Convertir des fichiers PDF en images en utilisant la bibliothèque PDF2Image
1. Installer la bibliothèque Python PDF2Image
PDF2Image est un module qui encapsule pdftocairo et pdftoppm. Il fonctionne sous Python 3.7+ pour convertir un PDF en un objet image PIL. Son historique de versions précédentes montre qu'il ne fait qu'encapsuler pdftoppm pour convertir des PDF en images et ne fonctionnait que sur Python 3+.
Pour installer le package pdf2image, ouvrez votre invite de commande Windows ou Windows PowerShell et utilisez la commande pip suivante :
pip install pdf2imagepip install pdf2imagePip (Preferred Installer Program) est le gestionnaire de packages pour Python. Il télécharge et installe des packages logiciels tiers qui offrent des fonctionnalités non présentes dans la bibliothèque standard Python.
Remarque : Pour exécuter cette commande depuis n'importe quel emplacement de ligne de commande, Python doit être ajouté au PATH. Pour Python 3+, il est recommandé d'utiliser pip3 car c'est la version mise à jour de pip.
2. Installer Poppler
Poppler est une bibliothèque libre et open-source pour travailler avec des fichiers PDF. Elle est utilisée pour rendre les fichiers PDF, lire le contenu, et modifier le contenu à l'intérieur des fichiers PDF. Elle est couramment utilisée par les utilisateurs de Linux. Cependant, pour Windows, nous devons télécharger la dernière version de Poppler.
Pour Windows
Les utilisateurs de Windows peuvent télécharger la dernière version de Poppler ici : version @oschwartz10612. Vous devrez ensuite ajouter le dossier bin/ au variable environnement PATH.
Pour Mac
Les utilisateurs de Mac devront également installer Poppler. Il peut être installé en utilisant Brew :
brew install popplerbrew install popplerPour Linux
La plupart des distributions Linux sont livrées avec les utilitaires de ligne de commande pdftoppm et pdftocairo. Si ces utilitaires ne sont pas installés, vous pouvez utiliser le Package Manager pour installer poppler-utils.
Pour les plateformes indépendantes (utilisation de conda)
-
Installez
poppler:conda install -c conda-forge popplerconda install -c conda-forge popplerSHELL -
Installez pdf2image :
pip install pdf2imagepip install pdf2imageSHELL
Maintenant tout est prêt, commençons avec le code pour convertir les PDF en images.
3. Code pour convertir des fichiers PDF en images
Le code suivant effectuera la conversion d'images du fichier PDF d'entrée :
from pdf2image import convert_from_path
# Notify the user that the process is starting
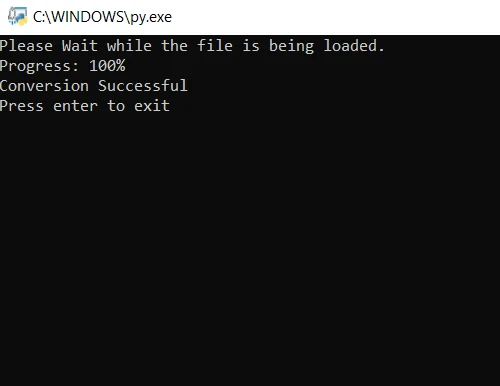
print("Please wait while the file is being loaded.")
file = convert_from_path('file.pdf')
# Iterate over all pages in the PDF file
for i in range(len(file)):
# Update user on progress
print("Progress: " + str(round(i / len(file) * 100)) + "%")
# Save each page as a JPG image file
file[i].save('page' + str(i + 1) + '.jpg', 'JPEG')
# Notify the user that the conversion is successful
print("Conversion Successful")from pdf2image import convert_from_path
# Notify the user that the process is starting
print("Please wait while the file is being loaded.")
file = convert_from_path('file.pdf')
# Iterate over all pages in the PDF file
for i in range(len(file)):
# Update user on progress
print("Progress: " + str(round(i / len(file) * 100)) + "%")
# Save each page as a JPG image file
file[i].save('page' + str(i + 1) + '.jpg', 'JPEG')
# Notify the user that the conversion is successful
print("Conversion Successful")Dans le code ci-dessus, nous ouvrons d'abord le fichier en utilisant la méthode convert_from_path. Cette méthode ouvre le fichier situé à l'emplacement spécifié. Ensuite, nous parcourons chaque page du fichier PDF à convertir en images JPG. Enfin, la méthode save est utilisée pour enregistrer chaque page convertie au format image JPG. Exécutez ensuite le programme et patientez jusqu'à la fin de la conversion. Les fichiers images de sortie sont enregistrés dans le même dossier que le programme.
Convertir des fichiers PDF en images en utilisant la bibliothèque PyMuPDF
1. Installer la bibliothèque Python PyMuPDF
PyMuPDF est une liaison Python étendue à MuPDF, qui est un visualiseur, un moteur de rendu et une boîte à outils léger pour e-books, PDF et XPS. Il peut être utilisé pour convertir des PDF en d'autres formats comme JPG ou PNG. PyMuPDF fonctionne sur les versions Python 3.7+.
Pour installer le package PyMuPDF, ouvrez votre invite de commande Windows ou Windows PowerShell et utilisez la commande pip suivante :
pip install pymupdfpip install pymupdfNotez que PyMuPDF ne nécessite pas de bibliothèques supplémentaires contrairement au package PDF2Image.
2. Code pour convertir des fichiers PDF en images
Le code suivant importera le module fitz de PyMuPDF, afin de pouvoir convertir le PDF en images :
import fitz # PyMuPDF
# Open the PDF file
doc = fitz.open("file.pdf")
# Iterate over each page in the document
for x in range(len(doc)):
page = doc.load_page(x) # Load a specific page
pix = page.get_pixmap() # Render page to image
output = "output/pdfpage" + str(x + 1) + ".png" # Specify output path
pix.save(output) # Save the image to the output path
# Close the document
doc.close()import fitz # PyMuPDF
# Open the PDF file
doc = fitz.open("file.pdf")
# Iterate over each page in the document
for x in range(len(doc)):
page = doc.load_page(x) # Load a specific page
pix = page.get_pixmap() # Render page to image
output = "output/pdfpage" + str(x + 1) + ".png" # Specify output path
pix.save(output) # Save the image to the output path
# Close the document
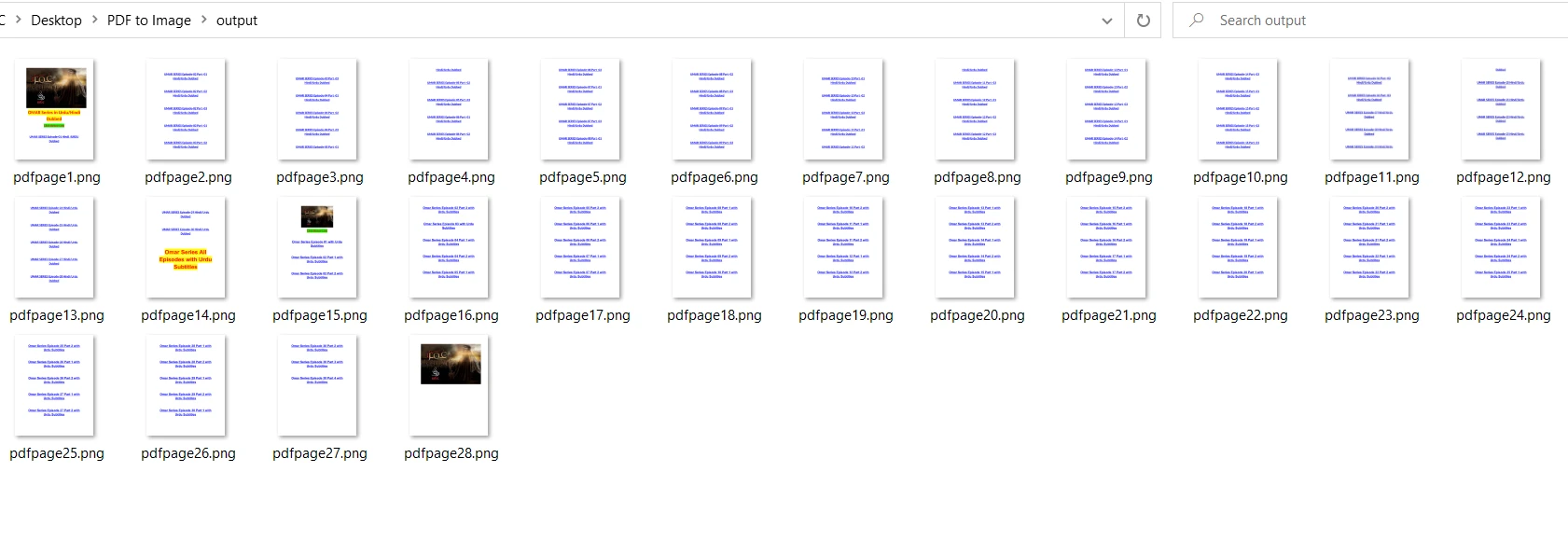
doc.close()Dans le code ci-dessus, le nom du fichier est passé comme argument à la méthode fitz.open pour ouvrir le fichier. Ensuite, je parcours l'intégralité du document et charge chaque page séparément. La méthode get_pixmap est utilisée pour convertir chaque page du document en pixels d'image, et l'image résultante est enregistrée dans le dossier de sortie à l'aide de la méthode save. Enfin, le document ouvert est fermé pour libérer la mémoire.
Comparé à PDF2Image, PyMuPDF est plus rapide pour convertir des PDF en PNG. PDF2Image peut être lent pour le format PNG en raison de son taux de compression. La sortie est la même que celle de PDF2Image :
Rendu de PDF en image en C
La bibliothèque IronPDF
IronPDF est une bibliothèque utilisée pour générer, lire et manipuler des fichiers PDF. Sa spécialité réside dans le rendu HTML en PDF avec l'aide du moteur Chromium. Cette fonctionnalité la rend populaire auprès des développeurs qui ont besoin de convertir des fichiers HTML ou des URLs en documents PDF. De plus, il fournit la conversion de divers formats en fichiers PDF.
Vous pouvez également rasteriser un fichier PDF en images avec seulement deux lignes de code. Le code suivant montre comment convertir des PDF en différents formats d'image :
using IronPdf;
var Renderer = new IronPdf.ChromePdfRenderer();
var PDF = Renderer.RenderUrlAsPdf("https://example.com");
PDF.SaveAs("html.pdf");
// Rasterize the PDF
List<string> Images = PDF.RasterizeToImageFiles(ImageType.Png);using IronPdf;
var Renderer = new IronPdf.ChromePdfRenderer();
var PDF = Renderer.RenderUrlAsPdf("https://example.com");
PDF.SaveAs("html.pdf");
// Rasterize the PDF
List<string> Images = PDF.RasterizeToImageFiles(ImageType.Png);Imports IronPdf
Private Renderer = New IronPdf.ChromePdfRenderer()
Private PDF = Renderer.RenderUrlAsPdf("https://example.com")
PDF.SaveAs("html.pdf")
' Rasterize the PDF
Dim Images As List(Of String) = PDF.RasterizeToImageFiles(ImageType.Png)Téléchargez IronPDF et essayez-le gratuitement .
















