
Python을 사용하여 PDF를 이미지로 변환하는 방법
PDF(Portable Document Format) 는 콘텐츠 서식을 유지하고 보안 권한을 통해 데이터를 안전하게 보호할 수 있기 때문에 인터넷을 통해 데이터를 전송하는 데 가장 널리 사용되는 파일 형식입니다. PDF 파일을 JPG 이미지 또는 PNG, BMP, TIFF, GIF와 같은 다른 이미지 형식으로 변환해야 하는 경우가 있습니다. 온라인에는 JPG 변환을 위한 다양한 리소스가 있지만, Python으로 직접 PDF를 이미지로 변환하는 도구를 만들면 얼마나 멋질까요?
Python이란 무엇인가요?
Python은 소프트웨어 애플리케이션, 웹사이트 구축, 작업 자동화, 데이터 분석, 인공지능 및 머신러닝 작업 수행에 사용되는 고급 프로그래밍 언어입니다. 또한 인터프리터 방식으로 실행되는 스크립팅 언어이므로 신속한 개발 및 테스트 측면에서 더욱 강력합니다.
PDF를 이미지로 변환하는 프로그램을 만들려면 컴퓨터에 Python 3 이상이 설치되어 있어야 합니다. 공식 웹사이트 에서 최신 버전을 다운로드하여 설치하세요.
이 글에서는 Python PDF-이미지 변환 라이브러리를 사용하여 자체 이미지 변환 애플리케이션을 만들어 보겠습니다. 이를 위해 Python에서 가장 인기 있는 라이브러리 두 가지인 PDF2Image와 PyMuPDF를 사용하겠습니다.
Python을 사용하여 PDF 파일을 이미지 파일로 변환하는 방법
- PDF를 이미지로 변환하는 Python 라이브러리를 설치하세요.
- 어느 위치에 있든 기존 PDF 파일을 불러올 수 있습니다.
- 변환 방법을 활용하십시오.
- 파일의 페이지들을 순회합니다.
- 저장 메서드를 사용하여 각 페이지를 JPG 또는 PNG 이미지로 저장합니다.
새 Python 파일 생성
- Python IDLE 애플리케이션을 열고 Ctrl + N 키를 누릅니다. 텍스트 편집기가 열립니다. 원하는 텍스트 편집기를 사용하시면 됩니다.
- 변환하려는 PDF 파일이 있는 동일한 위치에 파일을 pdf2image.py라는 이름으로 저장하세요.
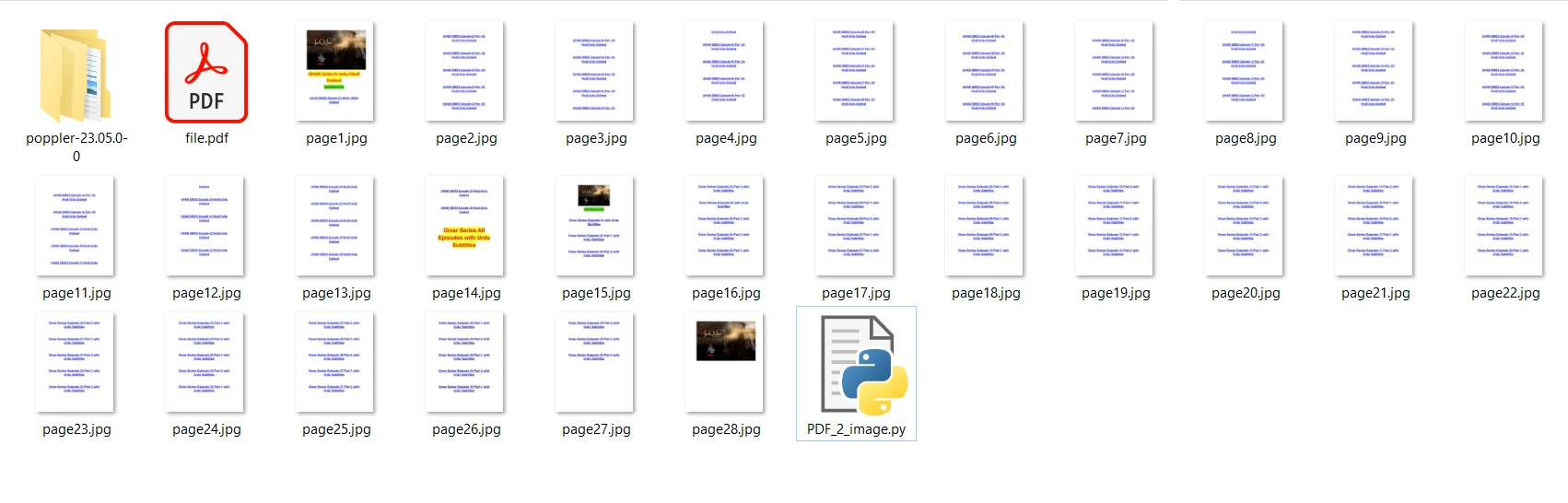
우리가 사용할 입력 PDF 파일은 28페이지로 구성되어 있으며 내용은 다음과 같습니다.

PDF2Image 라이브러리를 사용하여 PDF 파일을 이미지 파일로 변환하세요.
1. PDF2Image Python 라이브러리를 설치합니다.
PDF2Image는 pdftocairo 및 pdftoppm를 래핑하는 모듈입니다. 이 프로그램은 Python 3.7 이상에서 PDF를 PIL 이미지 객체로 변환하는 데 사용됩니다. 이전 릴리스 기록에 따르면 PDF를 이미지로 변환하기 위해 pdftoppm만을 래핑하며 Python 3+에서만 작동했습니다.
pdf2image 패키지를 설치하려면 Windows 명령 프롬프트 또는 Windows PowerShell을 열고 다음 pip 명령을 사용하십시오.
pip install pdf2imagepip install pdf2imagePip ( Preferred Installer Program )은 Python용 패키지 관리자입니다. Python 표준 라이브러리에는 없는 기능과 특징을 제공하는 타사 소프트웨어 패키지를 다운로드하고 설치합니다.
참고: 명령줄 어디에서든 이 명령을 실행하려면 Python을 PATH 환경 변수에 추가해야 합니다. Python 3 이상 버전에서는 pip의 최신 버전인 pip3를 사용하는 것이 좋습니다.
2. Poppler를 설치하세요
Poppler는 PDF 파일 작업을 위한 무료 오픈 소스 라이브러리입니다. PDF 파일을 렌더링하고, 내용을 읽고, PDF 파일 내의 내용을 수정하는 데 사용됩니다. 리눅스 사용자들이 흔히 사용하는 기능입니다. 하지만 윈도우 사용자의 경우, 최신 버전의 Poppler를 다운로드해야 합니다.
윈도우용
Windows 사용자는 여기에서 Poppler의 최신 버전을 다운로드할 수 있습니다: @oschwartz10612 버전 . 그런 다음 bin/폴더를 PATH 환경 변수에 추가해야 합니다.
맥용
맥 사용자도 Poppler를 설치해야 합니다. Brew를 사용하여 설치할 수 있습니다.
brew install popplerbrew install poppler리눅스용
대부분의 Linux 배포판은 pdftoppm 및 pdftocairo 커맨드 라인 유틸리티를 포함하고 있습니다. 이 유틸리티가 설치되지 않은 경우, 패키지 관리자를 사용하여 poppler-utils을 설치할 수 있습니다.
플랫폼 독립적 (Using conda 사용)
poppler설치:conda install -c conda-forge popplerconda install -c conda-forge popplerSHELLpdf2image를 설치하세요:
pip install pdf2imagepip install pdf2imageSHELL
이제 모든 준비가 끝났으니 PDF 파일을 이미지로 변환하는 코드를 작성해 보겠습니다.
3. PDF 파일을 이미지 파일로 변환하는 코드
다음 코드는 입력 PDF 파일을 이미지로 변환합니다.
from pdf2image import convert_from_path
# Notify the user that the process is starting
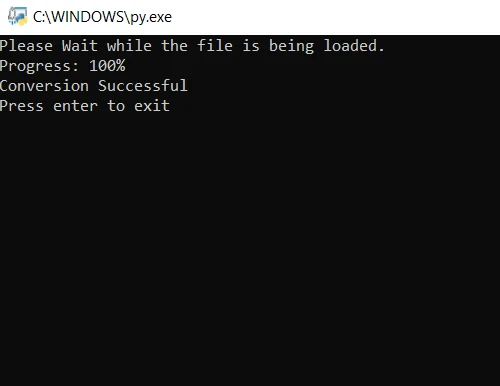
print("Please wait while the file is being loaded.")
file = convert_from_path('file.pdf')
# Iterate over all pages in the PDF file
for i in range(len(file)):
# Update user on progress
print("Progress: " + str(round(i / len(file) * 100)) + "%")
# Save each page as a JPG image file
file[i].save('page' + str(i + 1) + '.jpg', 'JPEG')
# Notify the user that the conversion is successful
print("Conversion Successful")from pdf2image import convert_from_path
# Notify the user that the process is starting
print("Please wait while the file is being loaded.")
file = convert_from_path('file.pdf')
# Iterate over all pages in the PDF file
for i in range(len(file)):
# Update user on progress
print("Progress: " + str(round(i / len(file) * 100)) + "%")
# Save each page as a JPG image file
file[i].save('page' + str(i + 1) + '.jpg', 'JPEG')
# Notify the user that the conversion is successful
print("Conversion Successful")위 코드에서 우리는 먼저 convert_from_path 메서드를 사용하여 파일을 엽니다. 이 메서드는 지정된 경로에 있는 파일을 엽니다. 그런 다음 PDF 파일의 각 페이지를 순회하면서 JPG 이미지로 변환합니다. 마지막으로, save 메서드를 사용하여 변환된 각 페이지를 JPG 이미지 파일로 저장합니다. 이제 프로그램을 실행하고 변환이 완료될 때까지 기다리세요. 출력 이미지 파일은 프로그램이 설치된 동일한 폴더에 저장됩니다.
PyMuPDF 라이브러리를 사용하여 PDF 파일을 이미지로 변환
1. PyMuPDF Python 라이브러리를 설치합니다.
PyMuPDF는 경량 전자책, PDF 및 XPS 뷰어, 렌더러 및 툴킷인 MuPDF에 대한 확장된 Python 바인딩입니다. 이 프로그램은 PDF 파일을 JPG나 PNG와 같은 다른 형식으로 변환하는 데 사용할 수 있습니다. PyMuPDF는 Python 3.7 이상 버전에서 작동합니다.
PyMuPDF 패키지를 설치하려면 Windows 명령 프롬프트 또는 Windows PowerShell을 열고 다음 pip 명령을 사용하십시오.
pip install pymupdfpip install pymupdfPyMuPDF는 PDF2Image 패키지와 달리 추가 라이브러리가 필요하지 않다는 점에 유의하십시오.
2. PDF 파일을 이미지로 변환하는 코드
아래 코드는 fitz 모듈을 PyMuPDF에서 가져와 PDF를 이미지로 변환할 수 있도록 합니다:
import fitz # PyMuPDF
# Open the PDF file
doc = fitz.open("file.pdf")
# Iterate over each page in the document
for x in range(len(doc)):
page = doc.load_page(x) # Load a specific page
pix = page.get_pixmap() # Render page to image
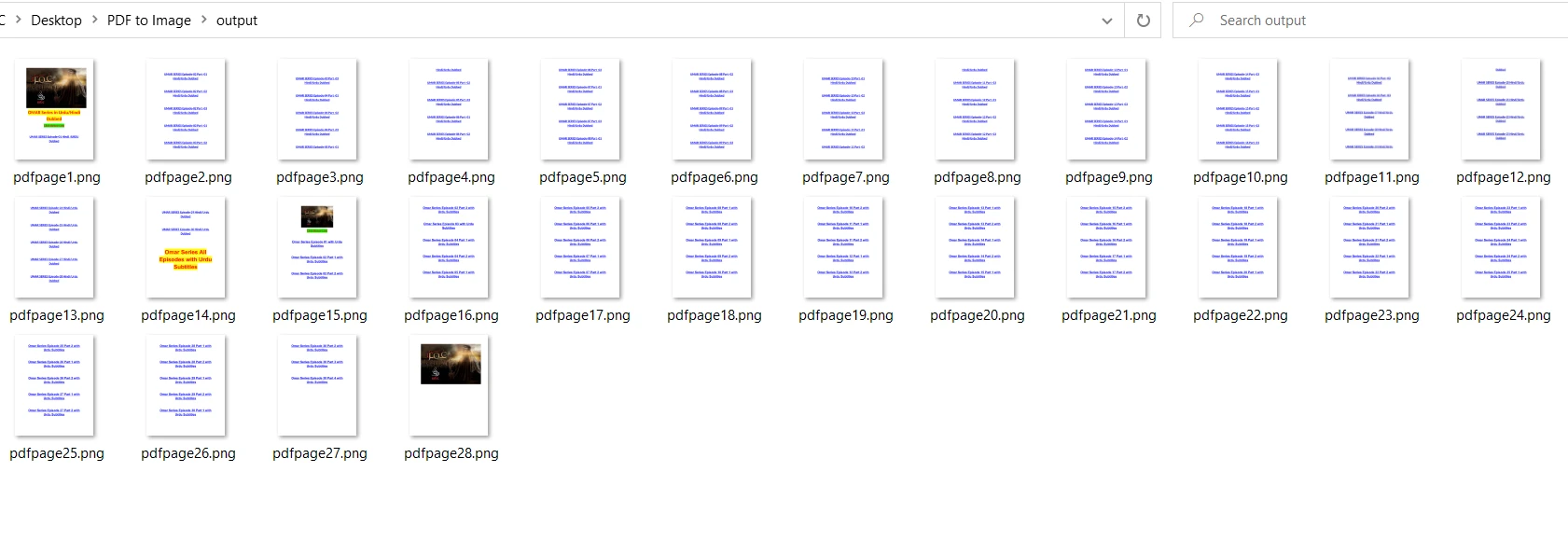
output = "output/pdfpage" + str(x + 1) + ".png" # Specify output path
pix.save(output) # Save the image to the output path
# Close the document
doc.close()import fitz # PyMuPDF
# Open the PDF file
doc = fitz.open("file.pdf")
# Iterate over each page in the document
for x in range(len(doc)):
page = doc.load_page(x) # Load a specific page
pix = page.get_pixmap() # Render page to image
output = "output/pdfpage" + str(x + 1) + ".png" # Specify output path
pix.save(output) # Save the image to the output path
# Close the document
doc.close()위 코드에서 파일 이름은 fitz.open 메서드에 인수로 전달되어 파일을 엽니다. 다음으로, 전체 문서를 반복하여 각 페이지를 별도로 로드합니다. get_pixmap 메서드는 각 문서 페이지를 이미지 픽셀로 변환하는 데 사용되며 save 메서드를 사용하여 결과 이미지를 출력 폴더에 저장합니다. 마지막으로 열려 있던 문서가 닫혀 메모리가 해제됩니다.
PDF2Image와 비교했을 때, PyMuPDF는 PDF를 PNG로 변환할 때 더 빠릅니다. PDF2Image는 압축률 때문에 PNG 형식의 경우 속도가 느릴 수 있습니다. 출력 결과는 PDF2Image의 출력 결과와 동일합니다.
Rendering PDF to Image Conversions in C
IronPDF 라이브러리
IronPDF 는 PDF 파일을 생성, 읽기 및 조작하는 데 사용되는 라이브러리입니다. 이 프로그램의 특징은 크로뮴 엔진을 이용하여 HTML을 PDF로 변환하는 기능입니다. 이러한 기능 덕분에 HTML 파일이나 URL을 PDF 문서로 변환해야 하는 개발자들 사이에서 인기가 높습니다. 또한, 다양한 형식의 파일을 PDF 파일로 변환하는 기능도 제공합니다.
또한 단 두 줄의 코드로 PDF 파일을 이미지로 래스터화할 수도 있습니다. 다음 코드는 PDF 파일을 다양한 이미지 형식으로 변환하는 방법을 보여줍니다.
using IronPdf;
var Renderer = new IronPdf.ChromePdfRenderer();
var PDF = Renderer.RenderUrlAsPdf("https://example.com");
PDF.SaveAs("html.pdf");
// Rasterize the PDF
List<string> Images = PDF.RasterizeToImageFiles(ImageType.Png);using IronPdf;
var Renderer = new IronPdf.ChromePdfRenderer();
var PDF = Renderer.RenderUrlAsPdf("https://example.com");
PDF.SaveAs("html.pdf");
// Rasterize the PDF
List<string> Images = PDF.RasterizeToImageFiles(ImageType.Png);Imports IronPdf
Private Renderer = New IronPdf.ChromePdfRenderer()
Private PDF = Renderer.RenderUrlAsPdf("https://example.com")
PDF.SaveAs("html.pdf")
' Rasterize the PDF
Dim Images As List(Of String) = PDF.RasterizeToImageFiles(ImageType.Png)















