
Como converter PDF em imagem em Python
O PDF (Portable Document Format) é o formato de arquivo mais popular para transferência de dados pela internet, pois preserva a formatação do conteúdo e ajuda a proteger os dados com permissões de segurança. Existem situações em que precisamos converter arquivos PDF em imagens JPG ou em qualquer outro formato de imagem, como PNG, BMP, TIFF ou GIF. Existem muitos recursos online disponíveis para conversão de JPG, mas que incrível seria criar nossa própria ferramenta de conversão de PDF para imagem em Python?
O que é Python?
Python é uma linguagem de programação de alto nível usada para construir aplicativos de software, sites, automatizar tarefas, realizar análises de dados e executar tarefas de Inteligência Artificial e Aprendizado de Máquina. É também uma linguagem de script, pois é interpretada, o que a torna mais poderosa em termos de desenvolvimento e teste rápidos.
Para criar um conversor de PDF para imagem, precisamos ter o Python 3 ou superior instalado no computador. Baixe e instale a versão mais recente do site oficial .
Neste artigo, criaremos nosso próprio aplicativo de conversão de imagens usando bibliotecas Python de PDF para imagem. Para isso, utilizaremos duas das bibliotecas mais populares do Python: PDF2Image e PyMuPDF.
Como converter arquivos PDF em arquivos de imagem em Python
- Instale a biblioteca Python para converter PDF em imagem.
- Carregue um arquivo PDF existente de qualquer local.
- Utilize métodos de conversão.
- Percorra as páginas do arquivo.
- Salve cada página como uma imagem JPG ou PNG usando o método de salvamento.
Criar um novo arquivo Python
- Abra o aplicativo Python IDLE e pressione as teclas Ctrl + N. O editor de texto será aberto. Você pode usar o editor de texto de sua preferência para isso.
- Salve o arquivo como pdf2image.py, no mesmo local do arquivo PDF que você deseja converter em imagens.
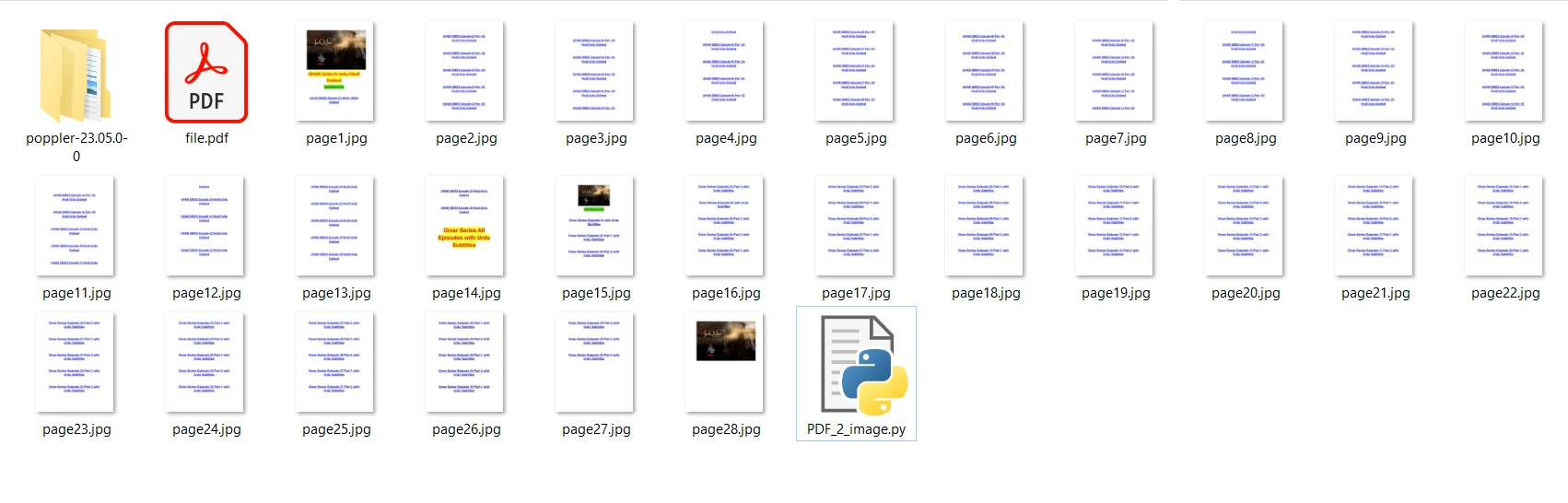
O arquivo PDF de entrada que vamos usar contém 28 páginas e é o seguinte:

Converter arquivos PDF em arquivos de imagem usando a biblioteca PDF2Image
1. Instale a biblioteca PDF2Image do Python.
PDF2Image é um módulo que encapsula pdftocairo e pdftoppm. Funciona no Python 3.7+ para converter PDF em um objeto de imagem PIL. Seu histórico de lançamentos anteriores mostra que ele apenas encapsula pdftoppm para converter PDF em imagens e funcionava apenas no Python 3+.
Para instalar o pacote pdf2image, abra o prompt de comando do Windows ou o Windows PowerShell e use o seguinte comando pip:
pip install pdf2imagepip install pdf2imagePip ( Preferred Installer Program ) é o gerenciador de pacotes para Python. Ele baixa e instala pacotes de software de terceiros que oferecem recursos e funcionalidades não encontrados na biblioteca padrão do Python.
Observação: Para executar este comando em qualquer lugar na linha de comando, o Python deve ser adicionado ao PATH. Para Python 3+, recomenda-se o uso do pip3, pois é a versão atualizada do pip.
2. Instale o Poppler
Poppler é uma biblioteca gratuita e de código aberto para trabalhar com arquivos PDF. É utilizado para renderizar arquivos PDF, ler conteúdo e modificar o conteúdo dentro de arquivos PDF. É comumente utilizado por usuários de Linux. No entanto, para Windows, será necessário baixar a versão mais recente do Poppler.
Para Windows
Usuários do Windows podem baixar a versão mais recente do Poppler aqui: @oschwartz10612 versão . Em seguida, você precisará adicionar a pasta bin/folder à variável de ambiente PATH.
Para Mac
Usuários de Mac também precisarão instalar o Poppler . Pode ser instalado usando o Brew :
brew install popplerbrew install popplerPara Linux
A maioria das distribuições Linux vem com as utilidades de linha de comando pdftoppm e pdftocairo. Se essas utilidades não estiverem instaladas, você pode usar o gerenciador de pacotes para instalar poppler-utils.
Para Plataforma Independente (Usando conda)
-
Instale
poppler:conda install -c conda-forge popplerconda install -c conda-forge popplerSHELL -
Instale o pdf2image:
pip install pdf2imagepip install pdf2imageSHELL
Agora que tudo está pronto, vamos começar com o código para converter PDFs em imagens.
3. Código para converter arquivos PDF em arquivos de imagem
O código a seguir realizará a conversão da imagem do arquivo PDF de entrada:
from pdf2image import convert_from_path
# Notify the user that the process is starting
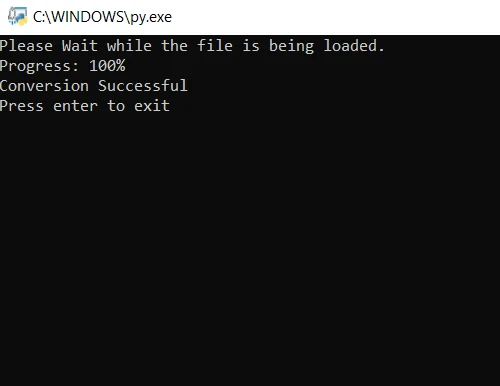
print("Please wait while the file is being loaded.")
file = convert_from_path('file.pdf')
# Iterate over all pages in the PDF file
for i in range(len(file)):
# Update user on progress
print("Progress: " + str(round(i / len(file) * 100)) + "%")
# Save each page as a JPG image file
file[i].save('page' + str(i + 1) + '.jpg', 'JPEG')
# Notify the user that the conversion is successful
print("Conversion Successful")from pdf2image import convert_from_path
# Notify the user that the process is starting
print("Please wait while the file is being loaded.")
file = convert_from_path('file.pdf')
# Iterate over all pages in the PDF file
for i in range(len(file)):
# Update user on progress
print("Progress: " + str(round(i / len(file) * 100)) + "%")
# Save each page as a JPG image file
file[i].save('page' + str(i + 1) + '.jpg', 'JPEG')
# Notify the user that the conversion is successful
print("Conversion Successful")No código acima, primeiro abrimos o arquivo usando o método convert_from_path. Este método abre o arquivo localizado no caminho especificado. Em seguida, percorremos cada página do arquivo PDF para convertê-las em imagens JPG. Finalmente, o método save é usado para salvar cada página convertida como um arquivo de imagem JPG. Agora, execute o programa e aguarde a conclusão da conversão. Os arquivos de imagem resultantes são salvos na mesma pasta do programa.
Converter arquivos PDF em imagens usando a biblioteca PyMuPDF
1. Instale a biblioteca PyMuPDF do Python.
PyMuPDF é uma extensão em Python do MuPDF, que é um visualizador, renderizador e conjunto de ferramentas leve para e-books, PDFs e XPS. Ele pode ser usado para converter PDF para outros formatos, como JPG ou PNG. PyMuPDF funciona em versões do Python 3.7 ou superiores.
Para instalar o pacote PyMuPDF, abra o prompt de comando do Windows ou o Windows PowerShell e use o seguinte comando pip:
pip install pymupdfpip install pymupdfNote que o PyMuPDF não requer nenhuma biblioteca adicional, ao contrário do pacote PDF2Image.
2. Código para converter arquivos PDF em imagens
O código a seguir importará o módulo fitz do PyMuPDF, para que possamos converter o PDF em imagens:
import fitz # PyMuPDF
# Open the PDF file
doc = fitz.open("file.pdf")
# Iterate over each page in the document
for x in range(len(doc)):
page = doc.load_page(x) # Load a specific page
pix = page.get_pixmap() # Render page to image
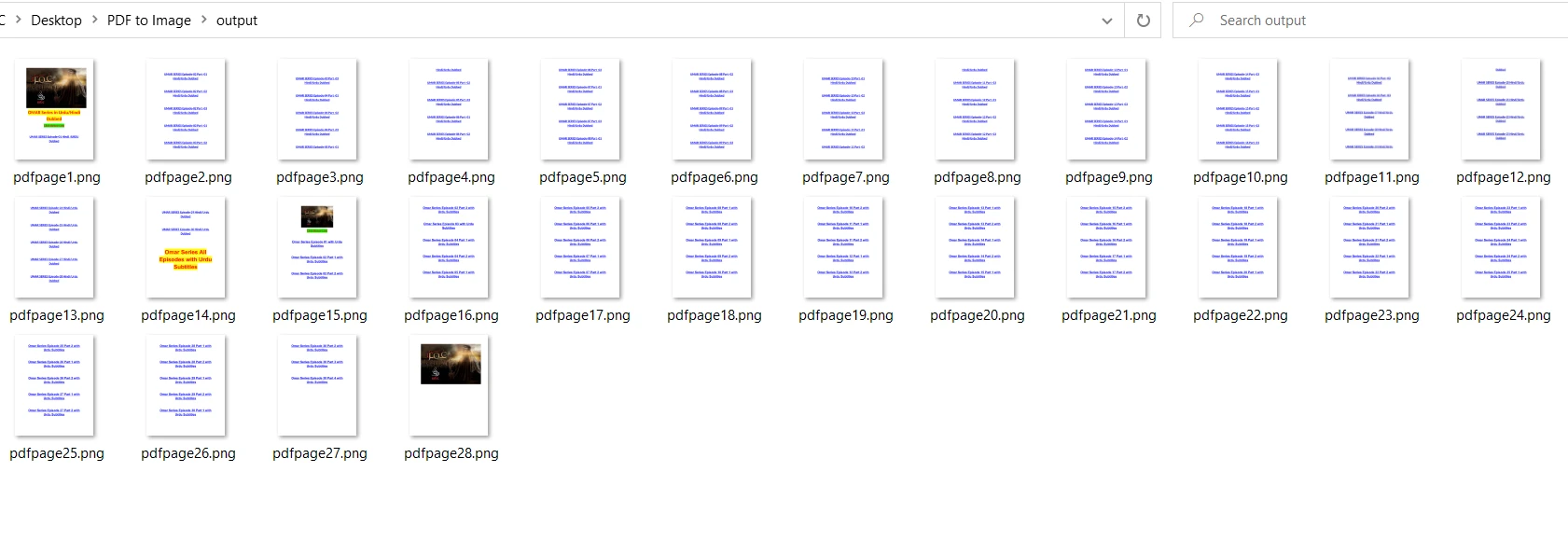
output = "output/pdfpage" + str(x + 1) + ".png" # Specify output path
pix.save(output) # Save the image to the output path
# Close the document
doc.close()import fitz # PyMuPDF
# Open the PDF file
doc = fitz.open("file.pdf")
# Iterate over each page in the document
for x in range(len(doc)):
page = doc.load_page(x) # Load a specific page
pix = page.get_pixmap() # Render page to image
output = "output/pdfpage" + str(x + 1) + ".png" # Specify output path
pix.save(output) # Save the image to the output path
# Close the document
doc.close()No código acima, o nome do arquivo é passado como argumento para o método fitz.open para abrir o arquivo. Em seguida, eu percorro todo o documento e carrego cada página separadamente. O método get_pixmap é usado para converter cada página do documento em pixels de imagem, e a imagem resultante é salva na pasta de saída usando o método save. Por fim, o documento aberto é fechado para liberar memória.
Em comparação com o PDF2Image, o PyMuPDF é mais rápido na conversão de PDF para PNG. O PDF2Image pode ser lento para o formato PNG devido à sua taxa de compressão. O resultado é o mesmo que o do PDF2Image:
Rendering PDF to Image Conversions in C
Biblioteca IronPDF
IronPDF é uma biblioteca usada para gerar, ler e manipular arquivos PDF. Sua especialidade reside na renderização de HTML para PDF com a ajuda do mecanismo Chromium. Esse recurso o torna popular entre desenvolvedores que precisam converter arquivos HTML ou URLs em documentos PDF. Além disso, oferece conversão de vários formatos para arquivos PDF.
Você também pode rasterizar um arquivo PDF em imagens usando apenas duas linhas de código. O código a seguir demonstra como converter PDFs em diferentes formatos de imagem:
using IronPdf;
var Renderer = new IronPdf.ChromePdfRenderer();
var PDF = Renderer.RenderUrlAsPdf("https://example.com");
PDF.SaveAs("html.pdf");
// Rasterize the PDF
List<string> Images = PDF.RasterizeToImageFiles(ImageType.Png);using IronPdf;
var Renderer = new IronPdf.ChromePdfRenderer();
var PDF = Renderer.RenderUrlAsPdf("https://example.com");
PDF.SaveAs("html.pdf");
// Rasterize the PDF
List<string> Images = PDF.RasterizeToImageFiles(ImageType.Png);Imports IronPdf
Private Renderer = New IronPdf.ChromePdfRenderer()
Private PDF = Renderer.RenderUrlAsPdf("https://example.com")
PDF.SaveAs("html.pdf")
' Rasterize the PDF
Dim Images As List(Of String) = PDF.RasterizeToImageFiles(ImageType.Png)Baixe o IronPDF e experimente gratuitamente .
















