
PythonでPDFファイルを解析する方法
1.0 はじめに
最新のライブラリでは PDF の作成が合理化されています。 PDF プロジェクト用のライブラリを選択するときは、最適な統合とパフォーマンスを実現するために、ビルド、読み取り、変換機能を考慮してください。 Python には、既存の PDF を効率的に解析できる IronPDF などのツールが用意されています。
2.0 IronPDF
Python は、開発者がグラフィカル ユーザー インターフェイスを迅速かつ簡単に構築できるようにするプログラミング言語です。 他の言語と比較して、プログラマーにとってより大きなダイナミズムを提供します。 したがって、IronPDF ライブラリを Python と統合するのは簡単なプロセスです。
完全に機能する GUI を迅速かつ安全に構築するために、開発者は PyQt、wxWidgets、Kivy、その他多くのパッケージやライブラリなど、プリインストールされたいくつかのツールを利用できます。 IronPDF は純粋な Python PDF ライブラリではないことに注意してください。 代わりに、.NET Core などの他のフレームワークのさまざまな機能を組み込むことができます。
IronPDF は、特に Django、Flask、Pyramid などの Python Web 開発パラダイムの人気により、Python Web の設計と開発を簡素化します。 Reddit、Mozilla、Spotify などの有名な Web サイトやオンライン サービスがこれらのフレームワークを利用しています。 IronPDF での Python の詳細については、IronPDF for Python Web サイトをご覧ください。
2.1 IronPDFの機能
- IronPDF は、HTML、HTML5、ASPX、Razor/MVC ビューなど、さまざまなソースからPDF ファイルを生成できます。 HTML ページや画像から PDF を作成する機能を提供します。
- IronPDF ツールキットには、インタラクティブ PDF の作成、インタラクティブ フォームの入力と送信、PDF ファイルの分割と結合、PDF ファイルからのテキストと画像の抽出、PDF ファイル内の特定の単語の検索、 PDF ページの画像へのラスタライズ、PDF から HTML への変換などのタスクのためのさまざまなツールが用意されています。
- ユーザーエージェント、プロキシ、Cookie、HTTP ヘッダー、シェイプ変数をサポートしているため、IronPDF では HTML ログイン フォームの検証が可能です。
- IronPDF 内の保護されたドキュメントへのアクセスは、ユーザー名とパスワードを使用して許可されます。
- IronPDF は、文字列、ストリーム、URL などのさまざまなソースから、わずか数行のコードで PDF ファイルを生成し、印刷するのに役立ちます。
3.0 Pythonのセットアップ
3.1 環境設定
PC に Python がインストールされていることを確認してください。 公式の Python Web サイトにアクセスして、ご使用のオペレーティング システムに適した最新バージョンの Python をダウンロードしてインストールしてください。 Python をインストールしたら、プロジェクトの依存関係を分離するための仮想環境を設定します。 "venv"モジュールを使用して仮想環境を作成および管理し、変換プロジェクトにクリーンで独立したワークスペースを提供します。
3.2 PyCharmでの新規プロジェクト
このデモでは、Python コードを記述するための IDE である PyCharm を使用します。
PyCharm IDE を起動した後、"新規プロジェクト"をクリックします。
 PyCharmのウェルカム画面
PyCharmのウェルカム画面
"新しいプロジェクト"を選択すると、新しいウィンドウが表示され、プロジェクトの場所と環境を指定できるようになります。 この新しいウィンドウは、下のスクリーンショットで確認できます。
 PyCharmの新しいプロジェクト画面
PyCharmの新しいプロジェクト画面
プロジェクトの場所と環境パスを設定した後、 [作成]ボタンをクリックして新しいプロジェクトを開始します。 これにより、プログラムを開発できる新しいウィンドウが開きます。 このチュートリアルでは Python 3.9 を推奨しています。
 PyCharmで開いたメインファイル
PyCharmで開いたメインファイル
3.3 IronPDFライブラリの要件
PythonライブラリであるIronPDFは、主に.NET 6.0に依存しています。そのため、Python用IronPDFを使用するには、PCに.NET 6.0ランタイムがインストールされている必要があります。 Linux および Mac ユーザーがこの Python モジュールを使用する前に、.NET をインストールする必要がある場合があります。 必要なランタイム環境は、.NET Web サイトから入手できます。
3.4 IronPDFライブラリのセットアップ
".pdf"拡張子のファイルを作成、編集、開くには、"ironpdf"パッケージをインストールする必要があります。 PyCharm にパッケージをインストールするには、ターミナル ウィンドウを開いて次のコマンドを入力します。
pip install ironpdfpip install ironpdf下のスクリーンショットは、"ironpdf"パッケージのセットアップを示しています。
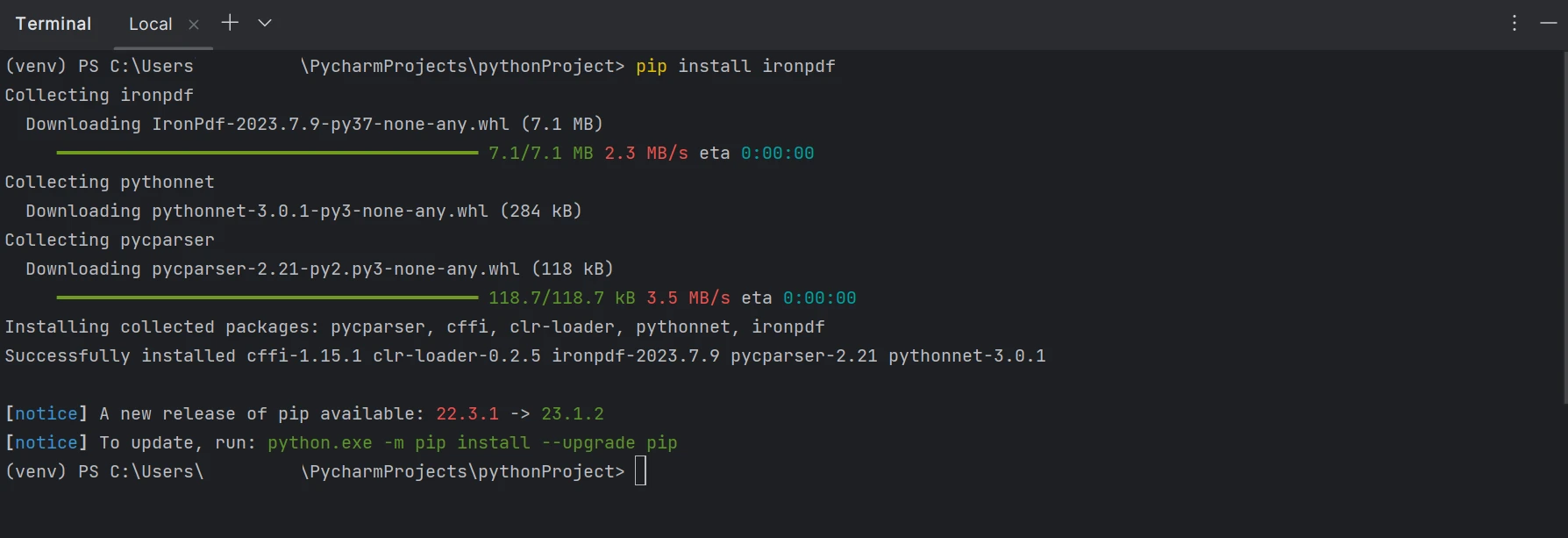 pipを使用してIronPDFをインストールしたことを示すターミナル
pipを使用してIronPDFをインストールしたことを示すターミナル
4.0 IronPDFでPDFを解析する
IronPDF ライブラリの支援により、PDF ファイルからテキストを抽出することができます。 IronPDF はテキスト抽出のためのさまざまなテクニックを提供します。 最初のアプローチでは、ページ上のすべてのコンテンツを 1 つの文字列として取得します。 2 番目のアプローチでは、最初のページから始めて、コンテンツをページごとに読みます。 次のコード スニペットは、IronPDF を使用して現在の PDF ファイルを検査するパターンを示しています。
PDF からデータを抽出するには、次の 2 つの方法があります。
- PDF からページごとに抽出します。
- PDF 全体をテキストとして抽出します。
以下はこの記事で使用する PDF ファイルです。 2ページあります。
 各ページの上部にページ番号が表示されたPDF
各ページの上部にページ番号が表示されたPDF
4.0.1 ページによるテキスト抽出
以下のサンプル コードは、ページ番号を使用して PDF ファイルからデータを取得する方法を示しています。
from ironpdf import PdfDocument
# Open a PDF file and create a PDF document object
pdfDocument = PdfDocument.FromFile("F:\\PDF\\1.pdf")
# Extract text from the first page (index 0)
AllText = pdfDocument.ExtractTextFromPage(0)
# Print the extracted text from the first page
print(AllText)from ironpdf import PdfDocument
# Open a PDF file and create a PDF document object
pdfDocument = PdfDocument.FromFile("F:\\PDF\\1.pdf")
# Extract text from the first page (index 0)
AllText = pdfDocument.ExtractTextFromPage(0)
# Print the extracted text from the first page
print(AllText)コードスニペットはFromFile関数を使用してPDFファイルを読み込み、PDFドキュメントオブジェクトを作成する方法を示しています。 このオブジェクトを使用すると、PDF 内のテキストや画像にアクセスできます。 特定のページからテキストを抽出するには、ページ番号をパラメータとして提供することにより、ExtractTextFromPageメソッドを使用できます。 このメソッドは、指定されたページ上のすべての単語を含む文字列を返します。 出力は以下のように表示されます。
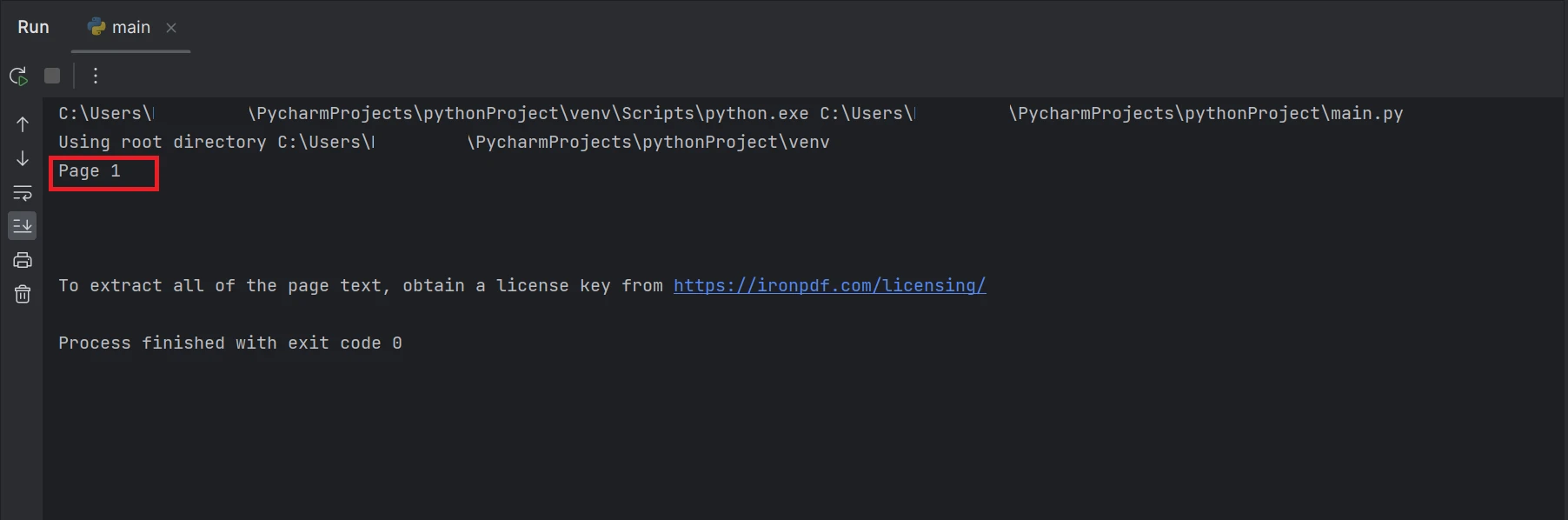 "ページ1"というテキスト出力のある端末のスクリーンショット
"ページ1"というテキスト出力のある端末のスクリーンショット
結果で強調表示された長方形のボックスは、インデックスが 0 であるページ番号 1 の PDF ファイルから抽出されたデータテキストです。
4.0.2 全ページからの抜粋
すべての PDF コンテンツを文字列としてすばやく簡単に取得する最初の方法を次のコード例に示します。
from ironpdf import PdfDocument
# Create a PDF file object from the file path
pdf = PdfDocument.FromFile('F:\\PDF\\1.pdf')
# Extract all text from the entire PDF
all_text = pdf.ExtractAllText()
# Print the extracted text from the entire PDF
print(all_text)from ironpdf import PdfDocument
# Create a PDF file object from the file path
pdf = PdfDocument.FromFile('F:\\PDF\\1.pdf')
# Extract all text from the entire PDF
all_text = pdf.ExtractAllText()
# Print the extracted text from the entire PDF
print(all_text)上記の例コードは、既存のファイルパスからPDFを読み取り、FromFile関数を使用してPDFファイルオブジェクトに変換する方法を説明しています。 PDFのプレーンテキストはオブジェクトのExtractAllText関数を使用して抽出され、文字列として変換され、ターミナルで抽出されたテキストを印刷します。 結果は以下のように表示されます。
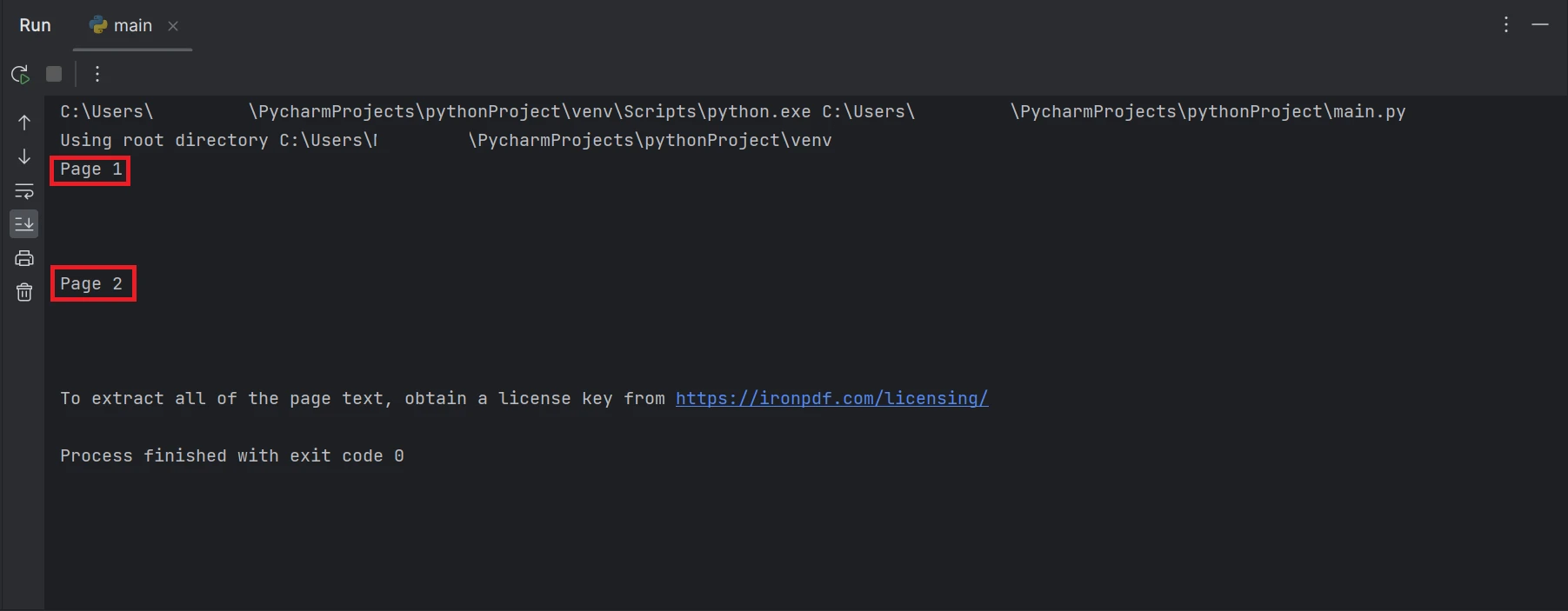 "ページ1"と"ページ2"というテキスト出力が表示された端末のスクリーンショット
"ページ1"と"ページ2"というテキスト出力が表示された端末のスクリーンショット
結果で強調表示された長方形のボックスには、PDF ファイルのすべてのページから抽出されたテキストのデータが含まれています。
IronPDF の助けを借りて、C# を使用して PDF を作成できます。 IronPDF の詳細については、 IronPDF の Web サイトをご覧ください。
5.0 結論
リスクを最小限に抑え、データ保護を確実にするために、IronPDF ライブラリは強力なセキュリティ対策を提供します。 一般的に使用されているすべてのブラウザと互換性があり、特定のブラウザに限定されません。 IronPDF を使用すると、プログラマーはわずか数行のコードで PDF ファイルを簡単に作成および読み取ることができます。 開発者のさまざまなニーズに対応するために、IronPDF ライブラリでは、無料の開発者ライセンスや購入可能な追加の開発ライセンスなど、さまざまなライセンス オプションを提供しています。
$799 Liteパッケージには、永続ライセンス、30日間返金保証、1年間のソフトウェアサポート、およびアップグレードの可能性が含まれています。 初回購入以降は追加料金はかかりません。 運用、ステージング、開発環境のすべてでこれらのライセンスが使用されます。 IronPDF は、いくつかの時間と再配布の制限が付いた無料ライセンスも提供しています。 無料試用期間中、ユーザーは透かしなしで実際の使用環境で製品をテストできます。 IronPDF の試用版の料金とライセンスの詳細については、 IronPDF のライセンス ページをご覧ください。
よくある質問
Python を使用して PDF ドキュメントを解析するにはどうすればよいですか?
Python で IronPDF を使用して PDF ドキュメントを解析できます。このライブラリの ExtractTextFromPage メソッドや ExtractAllText メソッドを使用して、特定のページまたはドキュメント全体からテキストを抽出できます。
Python 環境で IronPDF を実行するための前提条件は何ですか?
Python 環境で IronPDF を実行するには、システムに .NET 6.0 ランタイムがインストールされている必要があります。IronPDF はその動作に .NET を利用しています。
IronPDF は人気のある Python ウェブフレームワークと一緒に使用できますか?
はい、IronPDF は Django、Flask、Pyramid などの人気のある Python ウェブフレームワークとシームレスに統合され、ウェブ開発プロジェクトにおいて多用途に利用できるツールです。
Python 仮想環境に IronPDF をインストールする方法は?
Python 仮想環境に IronPDF をインストールするには、まず Python がインストールされていることを確認し、仮想環境を作成します。IDE のターミナルで pip install ironpdf コマンドを使用してパッケージをインストールします。
Python 開発者向けの IronPDF の主な機能は何ですか?
4. IronPDFは、HTML、画像、文字列、ストリームからPDFを生成する、インタラクティブPDFの作成、フォームの記入、PDFの分割と結合、テキストと画像の抽出といった機能を提供しています。
IronPDFは異なるオペレーティングシステムと互換性がありますか?
はい、IronPDF は異なるオペレーティングシステムと互換性があります。ただし、Linux および Mac ユーザーは Python モジュールを使用するために .NET がシステムにインストールされていることを確認する必要があります。
IronPDFのライセンスオプションはどのようになっていますか?
IronPDF は、制限付きの無料開発者ライセンスと、追加機能を備えた 30 日間の返金保証付きの有料 Lite パッケージを含む、柔軟なライセンスオプションを提供します。これらのオプションは、開発ニーズに応じて選択可能です。
PyCharm で新しい IronPDF プロジェクトを設定するにはどうすればよいですか?
PyCharm で新しい IronPDF プロジェクトを設定するには、IDE を開き、「新しいプロジェクト」をクリックし、プロジェクトの場所と環境を構成します。PyCharm のターミナルを使用して pip install ironpdf をインストールします。
IronPDFはPDFドキュメントのセキュリティをどのように保証していますか?
IronPDF は、PDF ドキュメントの安全性と整合性を確保するために強力なセキュリティ対策を組み込んでおり、PDF 処理を必要とするアプリケーションにおいて信頼性の高い選択肢となります。
IronPDF を使用して PDF から画像を抽出できますか?
はい、IronPDF を使用してドキュメントオブジェクトにアクセスし、適切なメソッドを使用して画像データを取得することで PDF から画像を抽出できます。
















