
Struktury danych w języku C# (jak to działa dla programistów)
Struktury danych w każdym języku programowania mają kluczowe znaczenie dla tworzenia oprogramowania, pomagając w uporządkowanym i efektywnym przechowywaniu oraz przetwarzaniu danych w aplikacji. Struktury danych odgrywają ważną rolę w efektywnej organizacji i zarządzaniu danymi.
W języku C#, podobnie jak w wielu innych językach programowania, zrozumienie wykorzystania struktur danych ma fundamentalne znaczenie dla tworzenia wydajnego, skalowalnego i łatwego w utrzymaniu oprogramowania. W tym przewodniku zapoznasz się z podstawami struktur danych w języku C# oraz przykładami dostosowanymi do potrzeb początkujących. W dalszej części artykułu zapoznamy się również z dokumentacją IronPDF dostępną na stronie ironpdf.com oraz jej potencjalnymi zastosowaniami.
Podstawowe struktury danych i ich zastosowania
Podstawowe dla każdej aplikacji, struktury danych zapewniają ustrukturyzowane przechowywanie danych, dostosowując się do różnych potrzeb operacyjnych. Wybór odpowiedniej struktury danych może znacząco wpłynąć na wydajność i efektywność pamięciową aplikacji.
Tablice: Podstawy organizacji danych
Tablice należą do najprostszych i najczęściej używanych struktur danych w C#. Przechowują elementy tego samego typu danych w sąsiadujących lokalizacjach pamięci, umożliwiając efektywny dostęp do elementów za pomocą indeksu. Tablice są idealne w sytuacjach, gdy liczba elementów jest znana z góry i nie ulega zmianie.
int[] numbers = new int[5] {1, 2, 3, 4, 5};int[] numbers = new int[5] {1, 2, 3, 4, 5};Dim numbers() As Integer = {1, 2, 3, 4, 5}Dzięki dostępowi do elementów za pośrednictwem ich indeksu, tablice ułatwiają pobieranie danych, z pierwszym elementem zlokalizowanym pod indeksem 0. Na przykład, numbers[0] da dostęp do pierwszego elementu tablicy numbers, który to 1.
Listy: Dynamiczne kolekcje danych
W przeciwieństwie do tablic, listy w C# oferują dynamiczne zmiany rozmiaru, co sprawia, że są odpowiednie w scenariuszach, gdzie liczba elementów może zmieniać się z czasem. C# obsługuje różne typy danych, a dzięki takim strukturom danych jak listy, pozwala na bezpieczne typowanie przechowywania.
List<int> numbers = new List<int> {1, 2, 3, 4, 5};
numbers.Add(6); // Adds a new element to the listList<int> numbers = new List<int> {1, 2, 3, 4, 5};
numbers.Add(6); // Adds a new element to the listDim numbers As New List(Of Integer) From {1, 2, 3, 4, 5}
numbers.Add(6) ' Adds a new element to the listListy są wszechstronne, umożliwiając swobodne dodawanie, usuwanie i dostęp do elementów bez obawy o rozmiar danych leżących u ich podstaw.
Słowniki: Powiązania klucz-wartość
Słowniki przechowują powiązania w postaci par klucz-wartość, co czyni je idealnymi w sytuacjach, gdy trzeba uzyskać dostęp do wartości na podstawie unikalnego klucza. Jest to szczególnie przydatne w zarządzaniu sesjami użytkownika, konfiguracjami lub w każdej sytuacji wymagającej wyszukiwania po kluczu.
Dictionary<string, int> ages = new Dictionary<string, int>();
ages.Add("Alice", 30);
ages.Add("Bob", 25);Dictionary<string, int> ages = new Dictionary<string, int>();
ages.Add("Alice", 30);
ages.Add("Bob", 25);Dim ages As New Dictionary(Of String, Integer)()
ages.Add("Alice", 30)
ages.Add("Bob", 25)W tym przykładzie, imię każdej osoby jest powiązane z jej wiekiem, co pozwala na szybki dostęp do wieku danej osoby na podstawie jej imienia.
Stos i kolejki: Zarządzanie kolekcjami
Stos działa na zasadzie ostatni na wejściu, pierwszy na wyjściu (LIFO), co czyni go doskonałym do zarządzania kolekcjami, w których trzeba uzyskać dostęp do najnowszego dodanego elementu jako pierwszego, na przykład w mechanizmach cofania lub systemach harmonogramowania zadań.
Stack<string> books = new Stack<string>();
books.Push("Book 1");
books.Push("Book 2");
string lastAddedBook = books.Pop(); // Removes and returns "Book 2"Stack<string> books = new Stack<string>();
books.Push("Book 1");
books.Push("Book 2");
string lastAddedBook = books.Pop(); // Removes and returns "Book 2"Dim books As New Stack(Of String)()
books.Push("Book 1")
books.Push("Book 2")
Dim lastAddedBook As String = books.Pop() ' Removes and returns "Book 2"Kolejki natomiast działają na zasadzie pierwszy na wejściu, pierwszy na wyjściu (FIFO). Są przydatne w scenariuszach, jak harmonogramowanie zadań drukarki czy obsługi zapytań serwisowych.
Queue<string> customers = new Queue<string>();
customers.Enqueue("Customer 1");
customers.Enqueue("Customer 2");
string firstCustomer = customers.Dequeue(); // Removes and returns "Customer 1"Queue<string> customers = new Queue<string>();
customers.Enqueue("Customer 1");
customers.Enqueue("Customer 2");
string firstCustomer = customers.Dequeue(); // Removes and returns "Customer 1"Dim customers As New Queue(Of String)()
customers.Enqueue("Customer 1")
customers.Enqueue("Customer 2")
Dim firstCustomer As String = customers.Dequeue() ' Removes and returns "Customer 1"Listy wiązane: Niestandardowe struktury danych
Listy wiązane składają się z węzłów zawierających dane i odwołanie do następnego węzła w sekwencji, co pozwala na efektywne wstawianie i usuwanie elementów. Są szczególnie przydatne w aplikacjach, gdzie częsta jest manipulacja indywidualnymi elementami, takich jak lista kontaktów w aplikacji społecznościowej.
public class Node
{
public int data;
public Node next;
public Node(int d) { data = d; next = null; }
}
public class LinkedList
{
public Node head;
// Adds a new node with the given data at the head of the list
public void Add(int data)
{
Node newNode = new Node(data);
newNode.next = head;
head = newNode;
}
// Displays the data for each node in the list
public void Display()
{
Node current = head;
while (current != null)
{
Console.WriteLine(current.data);
current = current.next;
}
}
}public class Node
{
public int data;
public Node next;
public Node(int d) { data = d; next = null; }
}
public class LinkedList
{
public Node head;
// Adds a new node with the given data at the head of the list
public void Add(int data)
{
Node newNode = new Node(data);
newNode.next = head;
head = newNode;
}
// Displays the data for each node in the list
public void Display()
{
Node current = head;
while (current != null)
{
Console.WriteLine(current.data);
current = current.next;
}
}
}Public Class Node
Public data As Integer
Public [next] As Node
Public Sub New(ByVal d As Integer)
data = d
[next] = Nothing
End Sub
End Class
Public Class LinkedList
Public head As Node
' Adds a new node with the given data at the head of the list
Public Sub Add(ByVal data As Integer)
Dim newNode As New Node(data)
newNode.next = head
head = newNode
End Sub
' Displays the data for each node in the list
Public Sub Display()
Dim current As Node = head
Do While current IsNot Nothing
Console.WriteLine(current.data)
current = current.next
Loop
End Sub
End ClassDrzewa i grafy: Złożone struktury danych
Drzewa, takie jak drzewa binarne, organizują dane w sposób hierarchiczny, co pozwala na skuteczne wykonywanie operacji takich jak wyszukiwanie, wstawianie i usuwanie. Drzewa binarne, na przykład, są fundamentalne we wdrażaniu algorytmów takich jak wyszukiwanie binarne i przeszukiwanie wszerz.
Grafy, składające się z węzłów (wierzchołków) i krawędzi (połączeń), są używane do reprezentacji sieci, takich jak grafy społecznościowe czy mapy transportowe. Zarówno drzewa, jak i grafy są ważne w rozwiązywaniu złożonych problemów związanych z danymi hierarchicznymi czy relacjami sieciowymi.
Wybór odpowiedniej struktury danych
Wybór struktury danych znacząco wpływa na efektywność i wydajność aplikacji. Nie chodzi tylko o wybór dowolnej struktury danych; chodzi o identyfikację tej odpowiedniej, która pasuje do specyficznych potrzeb twojego zadania lub algorytmu.
Ten wybór jest zależny od kilku czynników, w tym typu operacji, które najczęściej trzeba wykonać (takich jak wyszukiwanie, wstawianie czy usuwanie danych), szybkości tych operacji oraz użycia pamięci.
Kryteria wyboru struktur danych
- Złożoność operacji: Rozważ, jak szybko musisz wykonywać typowe operacje. Na przykład, jeśli wymagany jest częsty dostęp do elementów na podstawie klucza, najbardziej efektywnym wyborem może być tabela mieszania (zaimplementowana w C# jako Dictionary).
- Efektywność pamięciowa: Oceń, ile pamięci struktura danych zużywa, zwłaszcza jeśli pracujesz z dużą ilością danych. Struktury takie jak listy wiązane mogą być bardziej efektywne pamięciowo dla niektórych operacji niż tablice, ponieważ nie przydzielają pamięci na niewykorzystane elementy.
- Łatwość implementacji: Niektóre struktury danych mogą oferować prostsze implementacje dla twojego specyficznego przypadku użycia. Na przykład, jeśli musisz często dodawać i usuwać elementy tylko z jednego końca, Stos lub Kolejka mogą być prostsze do użycia i zrozumienia niż LinkedList.
- Rozmiar danych i skalowalność: Rozważ, czy rozmiar twoich danych jest stały czy dynamiczny. Tablice są idealne dla kolekcji danych o stałym rozmiarze, podczas gdy listy lub listy wiązane są lepsze dla kolekcji danych, które muszą dynamicznie rosnać lub maleć.
Wprowadzenie do IronPDF: biblioteka PDF dla języka C
Zaawansowane funkcje IronPDF to wszechstronna biblioteka zaprojektowana dla programistów do tworzenia, edytowania i wyodrębniania zawartości PDF w aplikacjach .NET. Oferuje prostą metodę konwersji HTML do PDF za pomocą IronPDF, pomagając w tworzeniu piksel-perfect PDF.
Dzięki wszechstronnemu zestawowi funkcji, programiści mogą łatwo implementować złożone funkcje PDF. IronPDF upraszcza proces manipulowania PDF i dodaje efektywne zarządzanie dokumentami w projektach C#.
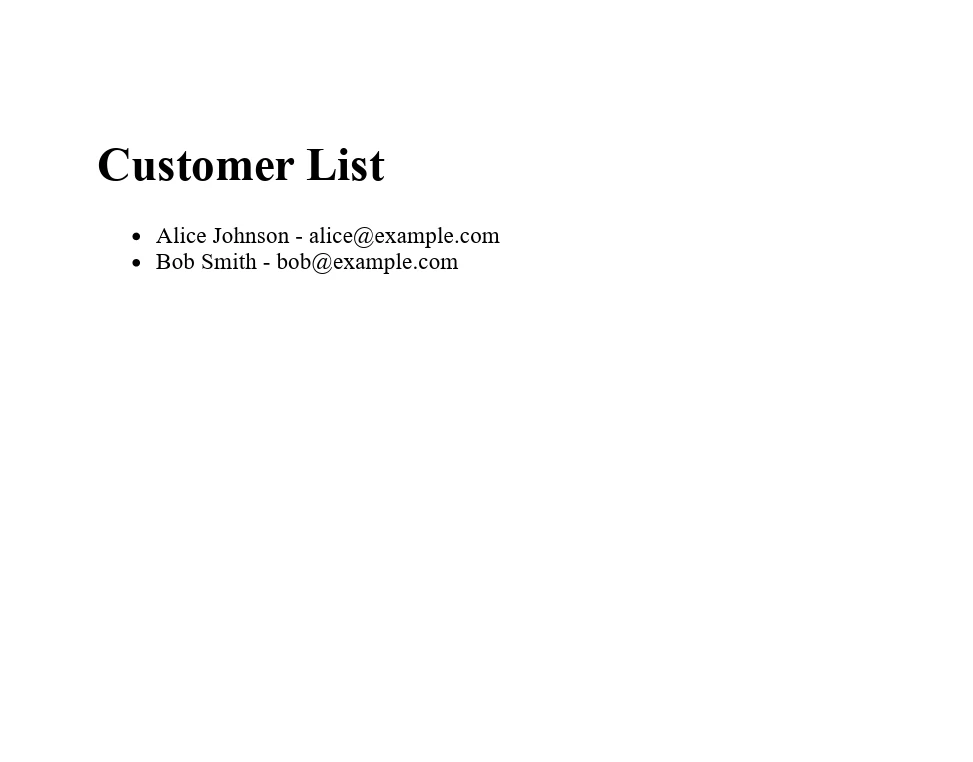
Przykład: Generowanie PDF z listy danych
Rozważ scenariusz, w którym trzeba wygenerować raport z listy nazwisk klientów i adresów e-mail. Najpierw należy ustrukturyzować swoje dane w List niestandardowej klasy, Customer, a następnie użyć IronPDF do stworzenia dokumentu PDF z tej listy.
using IronPdf;
using System.Collections.Generic;
// Define a customer class with properties for name and email
public class Customer
{
public string Name { get; set; }
public string Email { get; set; }
}
class Program
{
static void Main(string[] args)
{
// Set your IronPDF license key here. Replace "License-Key" with your actual key
License.LicenseKey = "License-Key";
// Create a list of customers
List<Customer> customers = new List<Customer>
{
new Customer { Name = "Alice Johnson", Email = "alice@example.com" },
new Customer { Name = "Bob Smith", Email = "bob@example.com" }
};
// Initialize the HTML to PDF converter
var renderer = new ChromePdfRenderer();
// Generate HTML content from the list of customers
var htmlContent = "<h1>Customer List</h1><ul>";
foreach (var customer in customers)
{
htmlContent += $"<li>{customer.Name} - {customer.Email}</li>";
}
htmlContent += "</ul>";
// Convert HTML to PDF
var pdf = renderer.RenderHtmlAsPdf(htmlContent);
// Save the PDF document
pdf.SaveAs("CustomerList.pdf");
}
}using IronPdf;
using System.Collections.Generic;
// Define a customer class with properties for name and email
public class Customer
{
public string Name { get; set; }
public string Email { get; set; }
}
class Program
{
static void Main(string[] args)
{
// Set your IronPDF license key here. Replace "License-Key" with your actual key
License.LicenseKey = "License-Key";
// Create a list of customers
List<Customer> customers = new List<Customer>
{
new Customer { Name = "Alice Johnson", Email = "alice@example.com" },
new Customer { Name = "Bob Smith", Email = "bob@example.com" }
};
// Initialize the HTML to PDF converter
var renderer = new ChromePdfRenderer();
// Generate HTML content from the list of customers
var htmlContent = "<h1>Customer List</h1><ul>";
foreach (var customer in customers)
{
htmlContent += $"<li>{customer.Name} - {customer.Email}</li>";
}
htmlContent += "</ul>";
// Convert HTML to PDF
var pdf = renderer.RenderHtmlAsPdf(htmlContent);
// Save the PDF document
pdf.SaveAs("CustomerList.pdf");
}
}Imports IronPdf
Imports System.Collections.Generic
' Define a customer class with properties for name and email
Public Class Customer
Public Property Name() As String
Public Property Email() As String
End Class
Friend Class Program
Shared Sub Main(ByVal args() As String)
' Set your IronPDF license key here. Replace "License-Key" with your actual key
License.LicenseKey = "License-Key"
' Create a list of customers
Dim customers As New List(Of Customer) From {
New Customer With {
.Name = "Alice Johnson",
.Email = "alice@example.com"
},
New Customer With {
.Name = "Bob Smith",
.Email = "bob@example.com"
}
}
' Initialize the HTML to PDF converter
Dim renderer = New ChromePdfRenderer()
' Generate HTML content from the list of customers
Dim htmlContent = "<h1>Customer List</h1><ul>"
For Each customer In customers
htmlContent &= $"<li>{customer.Name} - {customer.Email}</li>"
Next customer
htmlContent &= "</ul>"
' Convert HTML to PDF
Dim pdf = renderer.RenderHtmlAsPdf(htmlContent)
' Save the PDF document
pdf.SaveAs("CustomerList.pdf")
End Sub
End ClassW tym przykładzie IronPDF współpracuje z danymi struktury List
Wnioski
Podsumowując, wybór optymalnej struktury danych jest kluczowym krokiem w rozwoju oprogramowania. Dla programistów, zrozumienie tych struktur i ich praktycznych zastosowań jest niezbędne. Dodatkowo, dla tych, którzy interesują się generowaniem i manipulowaniem PDF w projektach .NET, IronPDF oferuje solidne rozwiązanie z bezpłatną wersją próbną IronPDF do rozpoczęcia w $799, oferując szereg funkcji odpowiednich dla różnych potrzeb rozwojowych.
Często Zadawane Pytania
Jak mogę przekonwertować HTML na PDF w języku C#?
Możesz użyć metody RenderHtmlAsPdf biblioteki IronPDF do konwersji ciągów HTML na pliki PDF. Możesz również konwertować pliki HTML na pliki PDF za pomocą metody RenderHtmlFileAsPdf.
Jakie są podstawowe struktury danych dostępne w języku C#?
Język C# oferuje kilka podstawowych struktur danych, w tym tablice, listy, stosy, kolejki, słowniki, listy połączone, drzewa i grafy. Każda z nich służy do innych celów w zarządzaniu danymi i tworzeniu aplikacji.
Czym różnią się tablice i listy pod względem zmiany rozmiaru w języku C#?
Tablice mają stały rozmiar, co oznacza, że ich długość jest ustalana w momencie utworzenia i nie może ulec zmianie. Listy są natomiast dynamiczne i mogą automatycznie zmieniać rozmiar w miarę dodawania lub usuwania elementów.
Jak wygenerować plik PDF na podstawie listy danych w języku C#?
Za pomocą IronPDF można przekonwertować listę danych, takich jak nazwy klientów i adresy e-mail, na dokument PDF. Wymaga to renderowania treści HTML z listy oraz użycia IronPDF do utworzenia i zapisania pliku PDF.
Jakie znaczenie ma używanie słowników w języku C#?
Słowniki mają duże znaczenie dla przechowywania danych w postaci par klucz-wartość, umożliwiając szybkie wyszukiwanie danych na podstawie unikalnych kluczy. Są one szczególnie przydatne do zarządzania konfiguracjami lub danymi sesji.
Jakie są zasady działania stosów i kolejek w języku C#?
Stosy działają na zasadzie „ostatni na wejściu, pierwszy na wyjściu” (LIFO), gdzie element dodany jako ostatni jest usuwany jako pierwszy. Kolejki działają na zasadzie „pierwszy na wejściu, pierwszy na wyjściu” (FIFO), gdzie elementy są przetwarzane w kolejności ich pojawienia się.
Jak wybrać odpowiednią strukturę danych dla mojej aplikacji w języku C#?
Wybór odpowiedniej struktury danych wymaga uwzględnienia złożoności operacji, efektywności wykorzystania pamięci, łatwości implementacji oraz tego, czy rozmiar danych jest stały, czy dynamiczny. Czynniki te pomagają określić strukturę danych najlepiej odpowiadającą Twoim potrzebom.
Jaką rolę odgrywają drzewa i grafy w programowaniu w języku C#?
Drzewa i wykresy służą odpowiednio do przedstawiania danych hierarchicznych i sieciowych. Są one niezbędne do rozwiązywania problemów związanych z relacjami między danymi lub złożoną nawigacją po danych.
Czy istnieje biblioteka C# do tworzenia i edycji plików PDF?
Tak, IronPDF to potężna biblioteka C# umożliwiająca tworzenie, edycję i wyodrębnianie zawartości z dokumentów PDF w aplikacjach .NET.
Dlaczego zrozumienie struktur danych jest kluczowe dla programistów C#?
Zrozumienie struktur danych jest kluczowe dla programistów C#, ponieważ umożliwia efektywne zarządzanie danymi, skalowalność i utrzymanie aplikacji. Pomaga również w optymalizacji wydajności i wykorzystania zasobów.














