
C# Data Structures(開発者向けの動作方法)
データ構造 は、ソフトウェア開発において、アプリケーション内部でデータをきちんと効果的に格納・操作するための鍵です。 データ構造は、データを効率的に整理・管理する上で重要な役割を果たします。
C#をはじめ多くのプログラミング言語では、データ構造の利用方法を理解することが、効率的でスケーラブルかつ保守可能なソフトウェアを作成するうえで基本となります。 このガイドでは、C#におけるデータ構造の基本と初心者向けの例を紹介します。 また記事の後半では、IronPDF.com の IronPDF ドキュメントとその潜在的な使用例についても学びます。
基本的なデータ構造とその用途
どのアプリケーションにおいても基本的に、データ構造は、さまざまな操作ニーズに応じた構造化されたデータの保存を提供します。 適切なデータ構造を選ぶと、アプリケーションのパフォーマンスとメモリー効率に大きく影響を与えます。
配列: データ組織の基礎
配列は、C#において最も基本的で広く使われているデータ構造のひとつです。 一続きのメモリ領域に同じデータ型の要素を格納し、インデックスを介して効率的に要素にアクセスすることができます。 配列は、要素数があらかじめ知られていて変更されない状況に最適です。
int[] numbers = new int[5] {1, 2, 3, 4, 5};int[] numbers = new int[5] {1, 2, 3, 4, 5};Dim numbers() As Integer = {1, 2, 3, 4, 5}インデックスを通じて要素にアクセスすることで、配列はデータの取り出しを容易にし、初めの項目はインデックス0に位置しています。例えば、numbers[0] は、配列 numbers の最初の要素である1 にアクセスします。
リスト: 動的なデータコレクション
配列とは異なり、C#のリストは動的なサイズ変更を提供し、要素数が時間とともに変化する可能性があるシナリオに適しています。C#はさまざまなデータ型をサポートし、リストのようなデータ構造を通じて型安全な保存が可能です。
List<int> numbers = new List<int> {1, 2, 3, 4, 5};
numbers.Add(6); // Adds a new element to the listList<int> numbers = new List<int> {1, 2, 3, 4, 5};
numbers.Add(6); // Adds a new element to the listDim numbers As New List(Of Integer) From {1, 2, 3, 4, 5}
numbers.Add(6) ' Adds a new element to the listリストは多用途で、データのサイズに関係なく、自由に要素を追加し、削除し、アクセスできます。
ディクショナリ: キーと値の関連付け
ディクショナリは、キーと値のペアの形で関連付けを保存しており、一意のキーに基づいて値にアクセスする必要がある状況に最適です。 これにより、ユーザーセッションや設定の管理、またはキーでの検索が必要なシナリオで特に有効です。
Dictionary<string, int> ages = new Dictionary<string, int>();
ages.Add("Alice", 30);
ages.Add("Bob", 25);Dictionary<string, int> ages = new Dictionary<string, int>();
ages.Add("Alice", 30);
ages.Add("Bob", 25);Dim ages As New Dictionary(Of String, Integer)()
ages.Add("Alice", 30)
ages.Add("Bob", 25)この例では、各人の名前が年齢と関連付けられており、名前に基づいて個人の年齢に素早くアクセスできます。
スタックとキュー: コレクションの管理
スタックは、ラストインファーストアウト(LIFO)の原則で動作し、アンドゥ機能やタスクスケジューリングシステムのように、最近追加された要素に最初にアクセスする必要があるコレクションの管理に最適です。
Stack<string> books = new Stack<string>();
books.Push("Book 1");
books.Push("Book 2");
string lastAddedBook = books.Pop(); // Removes and returns "Book 2"Stack<string> books = new Stack<string>();
books.Push("Book 1");
books.Push("Book 2");
string lastAddedBook = books.Pop(); // Removes and returns "Book 2"Dim books As New Stack(Of String)()
books.Push("Book 1")
books.Push("Book 2")
Dim lastAddedBook As String = books.Pop() ' Removes and returns "Book 2"一方、キューは、ファーストインファーストアウト(FIFO)に基づいて動作します。 プリンタのタスクスケジューリングやカスタマーサービスのリクエスト処理などのシナリオで役立ちます。
Queue<string> customers = new Queue<string>();
customers.Enqueue("Customer 1");
customers.Enqueue("Customer 2");
string firstCustomer = customers.Dequeue(); // Removes and returns "Customer 1"Queue<string> customers = new Queue<string>();
customers.Enqueue("Customer 1");
customers.Enqueue("Customer 2");
string firstCustomer = customers.Dequeue(); // Removes and returns "Customer 1"Dim customers As New Queue(Of String)()
customers.Enqueue("Customer 1")
customers.Enqueue("Customer 2")
Dim firstCustomer As String = customers.Dequeue() ' Removes and returns "Customer 1"リンクされたリスト: カスタムデータ構造
リンクされたリストは、データと順序内の次のノードの参照を含むノードで構成されており、要素の効率的な挿入と削除を可能にします。 個々の要素の操作が頻繁に行われるアプリケーション、例えばソーシャルメディアアプリケーションの連絡先リストなどで特に役立ちます。
public class Node
{
public int data;
public Node next;
public Node(int d) { data = d; next = null; }
}
public class LinkedList
{
public Node head;
// Adds a new node with the given data at the head of the list
public void Add(int data)
{
Node newNode = new Node(data);
newNode.next = head;
head = newNode;
}
// Displays the data for each node in the list
public void Display()
{
Node current = head;
while (current != null)
{
Console.WriteLine(current.data);
current = current.next;
}
}
}public class Node
{
public int data;
public Node next;
public Node(int d) { data = d; next = null; }
}
public class LinkedList
{
public Node head;
// Adds a new node with the given data at the head of the list
public void Add(int data)
{
Node newNode = new Node(data);
newNode.next = head;
head = newNode;
}
// Displays the data for each node in the list
public void Display()
{
Node current = head;
while (current != null)
{
Console.WriteLine(current.data);
current = current.next;
}
}
}Public Class Node
Public data As Integer
Public [next] As Node
Public Sub New(ByVal d As Integer)
data = d
[next] = Nothing
End Sub
End Class
Public Class LinkedList
Public head As Node
' Adds a new node with the given data at the head of the list
Public Sub Add(ByVal data As Integer)
Dim newNode As New Node(data)
newNode.next = head
head = newNode
End Sub
' Displays the data for each node in the list
Public Sub Display()
Dim current As Node = head
Do While current IsNot Nothing
Console.WriteLine(current.data)
current = current.next
Loop
End Sub
End Classツリーとグラフ: 複雑なデータ構造
ツリー、特に二分木は、データを階層的に組織し、検索、挿入、削除のような操作を効率的に実行できるようにします。 例えば、バイナリツリーは、二分探索や幅優先探索のようなアルゴリズムの実装において基本となります。
ノード(頂点)とエッジ(接続)で構成されるグラフは、ソーシャルグラフや交通図のようにネットワークを表現するために使用されます。 ツリーとグラフの両方が、階層データやネットワーク関係を含む複雑な問題を解く際に重要です。
適切なデータ構造の選択
データ構造の選択は、アプリケーションの効率性とパフォーマンスに大きな影響を与えます。 ただ任意のデータ構造を選ぶのではなく、 タスクやアルゴリズムの具体的なニーズに合った正しいものを特定することが求められます。
この選択は、最も頻繁に行う必要がある操作のタイプ(例えばデータの検索、挿入、削除)、これらの操作の速度、メモリの使用量など、いくつかの要因によって影響されます。
データ構造選択の基準
1.操作の複雑さ:一般的な操作をどのくらいの速さで実行する必要があるかを検討します。 例えば、キーに基づいて要素への頻繁なアクセスが必要な場合、ハッシュテーブル(C#では Dictionary として実装)を選ぶことが最も効率的かもしれません。 2.メモリ効率:特に大量のデータを扱う場合は、データ構造が消費するメモリの量を評価します。 リンクリストのような構造体は、不要な要素にメモリを割り当てないため、特定の操作において配列よりもメモリ効率が良い場合があります。 3.実装の容易さ:一部のデータ構造では、特定のユースケースに対してより簡単な実装が提供される場合があります。 たとえば、一端での要素の追加と削除を頻繁に行う必要がある場合、Stack や Queue を使用することは、LinkedList よりも理解と使用が簡単です。 4.データ サイズとスケーラビリティ:データ サイズが固定か動的かを検討します。 配列は固定サイズのデータコレクションに理想的ですが、リストやリンクリストは、動的にサイズを増減する必要があるデータコレクションに最適です。
イントロダクション: IronPDF - C# PDF ライブラリ
高度な IronPDF 機能 は、開発者が.NETアプリケーションでPDFコンテンツを作成、編集、および抽出するために設計された包括的なライブラリです。 IronPDF を使用して HTML から PDF に変換する 簡単なアプローチが、ピクセル単位で完璧な PDF を作成するのに役立ちます。
多様な機能セットを備え、開発者は簡単に複雑なPDF機能を実装できます。 IronPDF は PDF の操作プロセスを簡素化し、C# プロジェクト内で効率的なドキュメント管理を追加します。
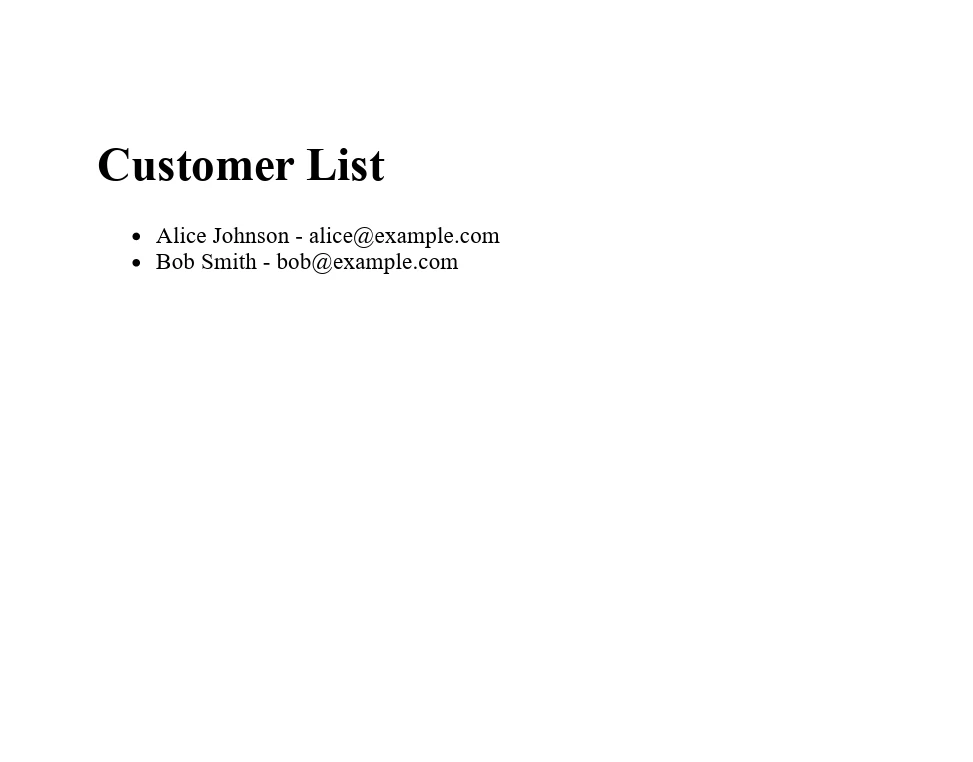
例: データリストからPDFを生成する
顧客の名前とメールアドレスのリストから報告書を生成する必要があるシナリオを考えます。 まず、データをカスタムクラスのCustomerのListに構造化してから、このリストから IronPDF を使用して PDF ドキュメントを作成します。
using IronPdf;
using System.Collections.Generic;
// Define a customer class with properties for name and email
public class Customer
{
public string Name { get; set; }
public string Email { get; set; }
}
class Program
{
static void Main(string[] args)
{
// Set your IronPDF license key here. Replace "License-Key" with your actual key
License.LicenseKey = "License-Key";
// Create a list of customers
List<Customer> customers = new List<Customer>
{
new Customer { Name = "Alice Johnson", Email = "alice@example.com" },
new Customer { Name = "Bob Smith", Email = "bob@example.com" }
};
// Initialize the HTML to PDF converter
var renderer = new ChromePdfRenderer();
// Generate HTML content from the list of customers
var htmlContent = "<h1>Customer List</h1><ul>";
foreach (var customer in customers)
{
htmlContent += $"<li>{customer.Name} - {customer.Email}</li>";
}
htmlContent += "</ul>";
// Convert HTML to PDF
var pdf = renderer.RenderHtmlAsPdf(htmlContent);
// Save the PDF document
pdf.SaveAs("CustomerList.pdf");
}
}using IronPdf;
using System.Collections.Generic;
// Define a customer class with properties for name and email
public class Customer
{
public string Name { get; set; }
public string Email { get; set; }
}
class Program
{
static void Main(string[] args)
{
// Set your IronPDF license key here. Replace "License-Key" with your actual key
License.LicenseKey = "License-Key";
// Create a list of customers
List<Customer> customers = new List<Customer>
{
new Customer { Name = "Alice Johnson", Email = "alice@example.com" },
new Customer { Name = "Bob Smith", Email = "bob@example.com" }
};
// Initialize the HTML to PDF converter
var renderer = new ChromePdfRenderer();
// Generate HTML content from the list of customers
var htmlContent = "<h1>Customer List</h1><ul>";
foreach (var customer in customers)
{
htmlContent += $"<li>{customer.Name} - {customer.Email}</li>";
}
htmlContent += "</ul>";
// Convert HTML to PDF
var pdf = renderer.RenderHtmlAsPdf(htmlContent);
// Save the PDF document
pdf.SaveAs("CustomerList.pdf");
}
}Imports IronPdf
Imports System.Collections.Generic
' Define a customer class with properties for name and email
Public Class Customer
Public Property Name() As String
Public Property Email() As String
End Class
Friend Class Program
Shared Sub Main(ByVal args() As String)
' Set your IronPDF license key here. Replace "License-Key" with your actual key
License.LicenseKey = "License-Key"
' Create a list of customers
Dim customers As New List(Of Customer) From {
New Customer With {
.Name = "Alice Johnson",
.Email = "alice@example.com"
},
New Customer With {
.Name = "Bob Smith",
.Email = "bob@example.com"
}
}
' Initialize the HTML to PDF converter
Dim renderer = New ChromePdfRenderer()
' Generate HTML content from the list of customers
Dim htmlContent = "<h1>Customer List</h1><ul>"
For Each customer In customers
htmlContent &= $"<li>{customer.Name} - {customer.Email}</li>"
Next customer
htmlContent &= "</ul>"
' Convert HTML to PDF
Dim pdf = renderer.RenderHtmlAsPdf(htmlContent)
' Save the PDF document
pdf.SaveAs("CustomerList.pdf")
End Sub
End Classこの例では、IronPDF は List
結論
結論として、最適なデータ構造を選択することはソフトウェア開発において重要なステップです。 開発者にとって、これらの構造とその実際の応用を理解することは非常に重要です。 さらに、 .NETプロジェクトで PDF の生成と操作を検討している方のために、 IronPDF は、$999 から開始できるIronPDFの無料試用版による強力なソリューションを提供しており、さまざまな開発ニーズに適したさまざまな機能を提供しています。
よくある質問
C# で HTML を PDF に変換するにはどうすればいいですか?
IronPDF の RenderHtmlAsPdf メソッドを使用して、HTML 文字列を PDF に変換できます。RenderHtmlFileAsPdf を使用して HTML ファイルを PDF に変換することもできます。
C#で利用可能な基本的なデータ構造は何ですか?
C# には、配列、リスト、スタック、キュー、辞書、リンクリスト、ツリー、グラフなど、いくつかの基本的なデータ構造があります。それぞれがデータ管理とアプリケーション開発において異なる目的を果たします。
C#での配列とリストのサイズ変更に関する違いは何ですか?
配列は固定サイズであり、作成時にその長さが設定され、変更できません。しかし、リストは動的であり、要素が追加または削除されると自動的にサイズを変更できます。
C#でデータのリストからPDFを生成するにはどうすればよいですか?
IronPDFを使用すると、顧客名やメールアドレスなどのデータのリストをPDFドキュメントに変換できます。これは、リストからHTMLコンテンツをレンダリングし、IronPDFを使用してPDFを作成して保存することを含みます。
C#で辞書を使用することの重要性は何ですか?
辞書はキーと値のペアとしてデータを保存するため、ユニークなキーに基づいた迅速なデータ検索が可能です。特に、設定やセッションデータを管理する際に役立ちます。
C#でのスタックとキューの原則は何ですか?
スタックは、最後に入った要素が最初に削除される(LIFO: Last In, First Out)原則を使用し、キューは最初に入った要素が順番に処理される(FIFO: First In, First Out)原則に基づいて動作します。
C#アプリケーションに適したデータ構造を選ぶ方法は?
適切なデータ構造を選択するには、操作の複雑さ、メモリエフィシェンシー、実装の容易さ、データサイズが固定または動的であるかどうかを考慮する必要があります。これらの要因は、ニーズに最も適したデータ構造を判断するのに役立ちます。
C#プログラミングにおけるツリーとグラフの役割は何ですか?
ツリーとグラフは、それぞれ階層データとネットワークデータを表現するために使用されます。データの関係や複雑なデータのナビゲーションを含む問題を解決するのに欠かせません。
C#でPDFを作成および編集するライブラリはありますか?
はい、IronPDFは強力なC#ライブラリであり、.NETアプリケーション内でPDFドキュメントを作成、編集、およびコンテンツを抽出することができます。
C#開発者にとってデータ構造を理解することがなぜ重要ですか?
データ構造を理解することは、効率的なデータ管理、スケーラビリティ、アプリケーションの保守性に寄与するため、C#開発者にとって非常に重要です。また、パフォーマンスの最適化やリソースの効率的な使用にも役立ちます。














