C# String Equals(開発者向けの仕組み)
C#アプリケーションでPDFドキュメントを処理する際、抽出されたテキストのチェック、メタデータの確認、条件付きでドキュメントを変更するか否かは意外と一般的なタスクです。 C#のstring.Equalsメソッドは、文字列オブジェクトを比較する正確な方法を提供し、IronPDFと組み合わせることで、PDF自動化ツールキットの強力なツールとなります。
この記事では、string.Equalsが何であるか、.NETでそれが重要である理由、そして.NETのPDFライブラリとしてトップクラスのIronPDFと組み合わせて効果的に使用する方法を探ります。
C#のstring.Equalsとは?
C#でstring.Equalsとして知られるCの文字列等価メソッドは、文字列または他の互換性のあるオブジェクトを表す2つのパラメータの内容を比較するために使用されます。 通常の文字列の値または比較中に文字列に変換される型オブジェクトのいずれを渡すことができます。 文字列に対する等価のシンタックスシュガーである==演算子とは異なり、string.Equalsを明示的に使用することで以下が可能となります。
-
比較ルールを指定(大文字と小文字を区別する比較やカルチャに依存しない比較など)。
-
オーバーロードされた演算子による混乱を避ける。
- 条件ロジックにおける読みやすさを向上させる。
.NET Frameworkでは、メソッドシグネチャはしばしば次のように見えます。
public bool Equals(string value, StringComparison comparisonType)public bool Equals(string value, StringComparison comparisonType)'INSTANT VB TODO TASK: The following line uses invalid syntax:
'public bool Equals(string value, StringComparison comparisonType)ここで、public boolは比較結果に応じて返り値が常にtrueまたはfalseであることを示しています。
基本構文
string.Equals(str1, str2)
string.Equals(str1, str2, StringComparison.OrdinalIgnoreCase)string.Equals(str1, str2)
string.Equals(str1, str2, StringComparison.OrdinalIgnoreCase)'INSTANT VB TODO TASK: The following line uses invalid syntax:
'string.Equals(str1, str2) string.Equals(str1, str2, StringComparison.OrdinalIgnoreCase)このメソッドは2つのパラメータを取ります:比較対象の2つの文字列または文字列オブジェクト、そしてオプションで実行する比較の種類。 返り値はブール値です。 メソッドは、両方の引数が比較ルールに従って等しい場合はtrueを、そうでない場合はfalseを返します。
さまざまなStringComparisonオプションを使用して2つの文字列を比較することができます。
-
Ordinal(バイナリ比較、ケースセンシティブな比較)
-
OrdinalIgnoreCase(ケースインセンシティブな比較)
-
CurrentCulture
- InvariantCultureIgnoreCase
IronPDFとの連携方法
IronPDFは、PDFドキュメント内のテキストを検索、抽出、操作することを可能にする強力な.NET PDFライブラリです。 string.Equalsを使用することで可能になること:
-
抽出した文字列値を既知の値と比較する。
-
タイトル、著者、キーワードなどのメタデータフィールドを確認してください。
- 文字列比較結果に基づいて注釈、ハイライト、透かしを追加することなど、条件付きでPDFドキュメントを編集する。
string.EqualsがIronPDFワークフローで役立つ例を見てみましょう。
例 1: 抽出されたテキストをstring.Equalsで比較
PDF請求書をスキャンして特定の会社名が含まれているかどうかを検証したいと想像してみてください。 ここでは、ヌル参照例外のような一般的な落とし穴を避ける方法と、メソッドが堅牢に等価性をチェックする方法を示す例があります。
次の例では、以下のPDFを使用します。

using IronPdf;
using IronPdf.Editing;
class Program
{
public static void Main(string[] args)
{
var pdf = new IronPdf.PdfDocument("invoice.pdf");
string extractedText = pdf.ExtractAllText();
var lines = extractedText.Split(new[] { '\r', '\n' }, StringSplitOptions.RemoveEmptyEntries);
foreach (var line in lines)
{
if (string.Equals(line.Trim(), "Acme Corporation", StringComparison.OrdinalIgnoreCase))
{
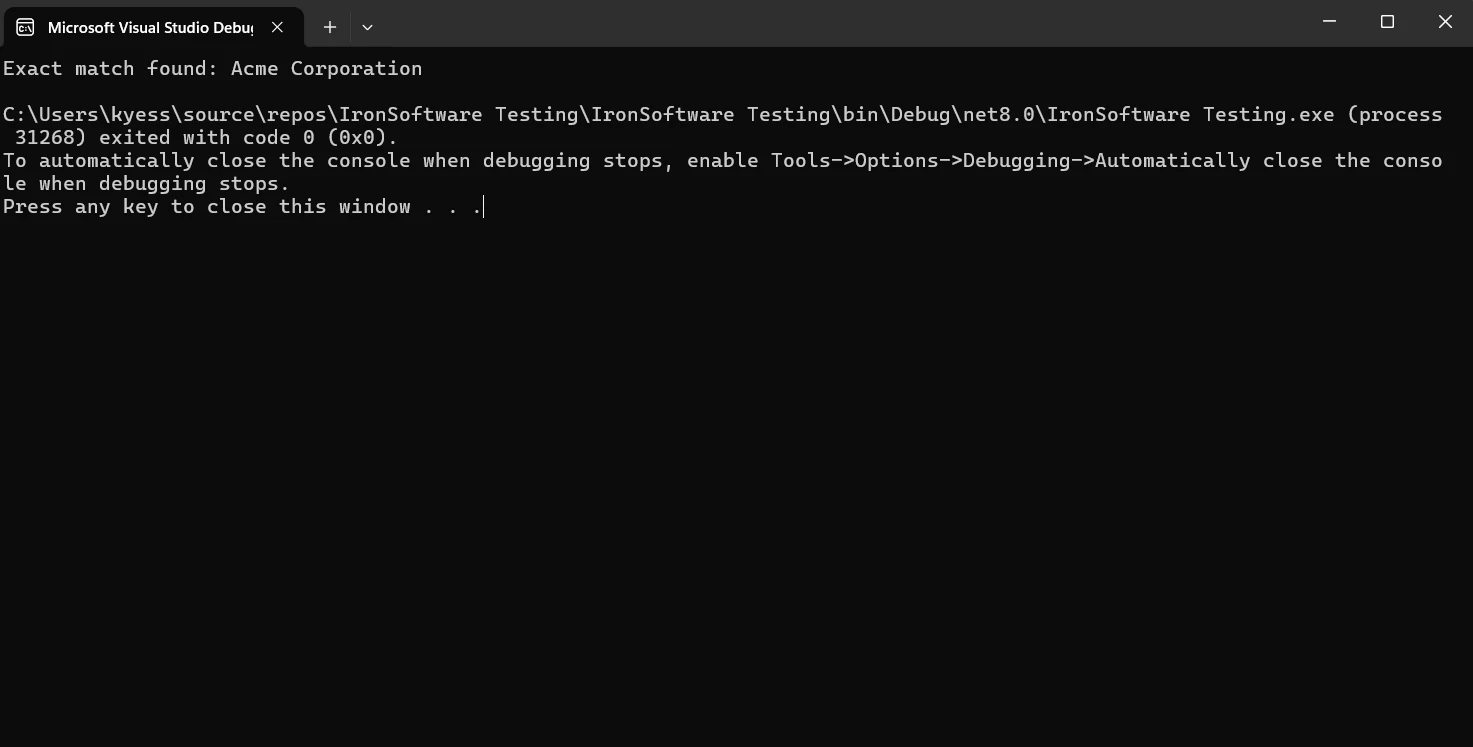
Console.WriteLine("Exact match found: Acme Corporation");
}
}
}
}using IronPdf;
using IronPdf.Editing;
class Program
{
public static void Main(string[] args)
{
var pdf = new IronPdf.PdfDocument("invoice.pdf");
string extractedText = pdf.ExtractAllText();
var lines = extractedText.Split(new[] { '\r', '\n' }, StringSplitOptions.RemoveEmptyEntries);
foreach (var line in lines)
{
if (string.Equals(line.Trim(), "Acme Corporation", StringComparison.OrdinalIgnoreCase))
{
Console.WriteLine("Exact match found: Acme Corporation");
}
}
}
}Imports Microsoft.VisualBasic
Imports IronPdf
Imports IronPdf.Editing
Friend Class Program
Public Shared Sub Main(ByVal args() As String)
Dim pdf = New IronPdf.PdfDocument("invoice.pdf")
Dim extractedText As String = pdf.ExtractAllText()
Dim lines = extractedText.Split( { ControlChars.Cr, ControlChars.Lf }, StringSplitOptions.RemoveEmptyEntries)
For Each line In lines
If String.Equals(line.Trim(), "Acme Corporation", StringComparison.OrdinalIgnoreCase) Then
Console.WriteLine("Exact match found: Acme Corporation")
End If
Next line
End Sub
End Class注:このメソッドは、2つの文字列オブジェクトが同じ値を含んでいるかどうかを示すブール値を返します。
これが重要な理由:
以下の出力で見るように、StringComparison.OrdinalIgnoreCaseを使用したstring.Equalsは、"ACME CORPORATION"および"Acme Corporation"を同等とみなします—これはOCRやテキスト抽出のシナリオで、ケースセンシティブな違いが異なる挙動を引き起こす可能性がある場合に重要です。
出力
例 2: string.Equalsを使用してPDFメタデータを検証
PDFファイルはしばしばメタデータフィールドを含んでいます。例えば、タイトル、著者、件名などです。 IronPDFはこれらのプロパティを読み取ることができ、検査および比較が容易です。
using IronPdf;
var pdf = new IronPdf.PdfDocument("invoice.pdf");
string author = pdf.MetaData.Author;
if (string.Equals(author, "Iron Software", StringComparison.InvariantCulture))
{
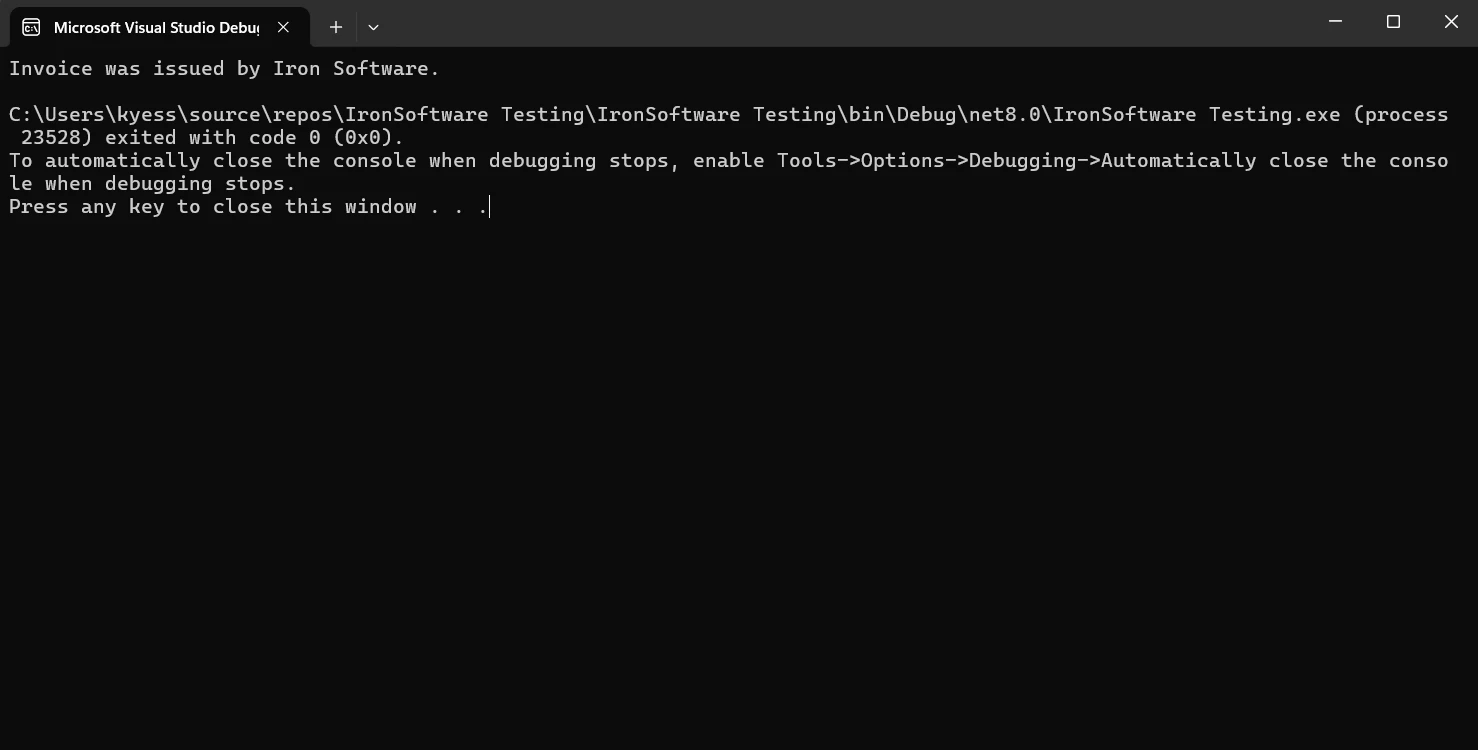
Console.WriteLine("Invoice was issued by Iron Software.");
}using IronPdf;
var pdf = new IronPdf.PdfDocument("invoice.pdf");
string author = pdf.MetaData.Author;
if (string.Equals(author, "Iron Software", StringComparison.InvariantCulture))
{
Console.WriteLine("Invoice was issued by Iron Software.");
}Imports IronPdf
Private pdf = New IronPdf.PdfDocument("invoice.pdf")
Private author As String = pdf.MetaData.Author
If String.Equals(author, "Iron Software", StringComparison.InvariantCulture) Then
Console.WriteLine("Invoice was issued by Iron Software.")
End Ifメタデータに基づく検証が非文字列または無効なファイルの処理を防ぐシステムでは、この方法が特に便利です。
出力
例 3: テキスト一致に基づいて透かしを追加
特定のキーワードを含むPDFドキュメントに自動的に透かしを入れたいことがあるでしょう。 その方法は次のとおりです。
using IronPdf;
using IronPdf.Editing;
License.LicenseKey = "IRONSUITE.WRITERS.21046-907F5E67CC-AHYQW6L-RCHLPMRJMU4G-SET72XAF2JNY-LQK45E5JPLGW-XOLPVBEBLHV7-2LHKZRWUZWMO-5LNIZSPF4BM6-UHUH4R-T4MMJ4MEIYSQEA-DEPLOYMENT.TRIAL-LDG2MK.TRIAL.EXPIRES.16.NOV.2025";
var pdf = new IronPdf.PdfDocument("invoice.pdf");
string content = pdf.ExtractAllText();
var lines = content.Split(new[] { '\r', '\n' }, StringSplitOptions.RemoveEmptyEntries);
foreach (var line in lines)
{
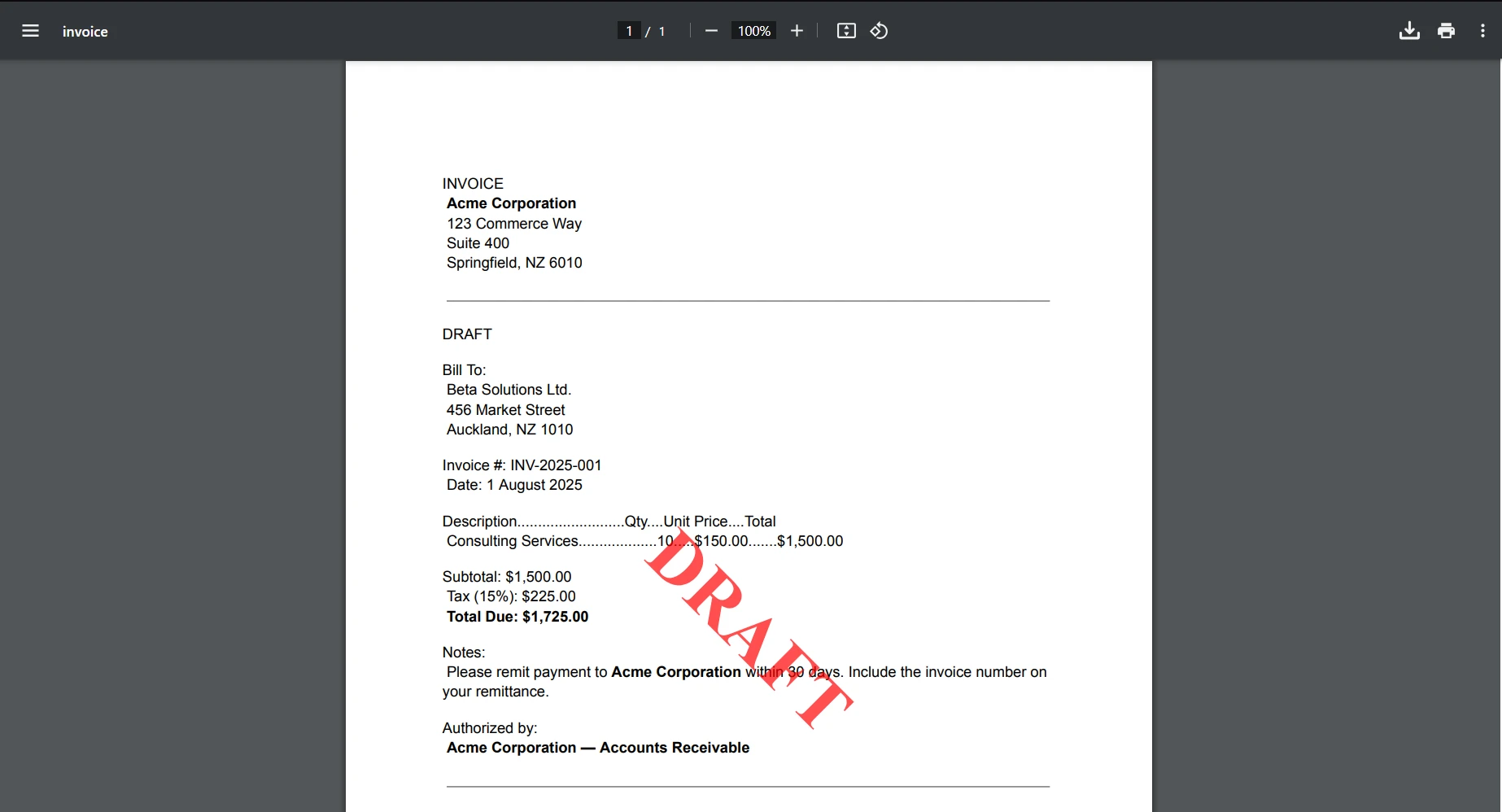
if (string.Equals(line.Trim(), "DRAFT", StringComparison.OrdinalIgnoreCase))
{
Console.WriteLine("The document is a draft.");
// Corrected HTML and CSS
string watermark = @"<div style='color:red; font-size:72px; font-weight:bold;'>DRAFT</div>";
pdf.ApplyWatermark(watermark, rotation: 45, opacity: 70,
verticalAlignment: VerticalAlignment.Middle,
horizontalAlignment: HorizontalAlignment.Center);
pdf.SaveAs("watermarked_invoice.pdf");
}
}using IronPdf;
using IronPdf.Editing;
License.LicenseKey = "IRONSUITE.WRITERS.21046-907F5E67CC-AHYQW6L-RCHLPMRJMU4G-SET72XAF2JNY-LQK45E5JPLGW-XOLPVBEBLHV7-2LHKZRWUZWMO-5LNIZSPF4BM6-UHUH4R-T4MMJ4MEIYSQEA-DEPLOYMENT.TRIAL-LDG2MK.TRIAL.EXPIRES.16.NOV.2025";
var pdf = new IronPdf.PdfDocument("invoice.pdf");
string content = pdf.ExtractAllText();
var lines = content.Split(new[] { '\r', '\n' }, StringSplitOptions.RemoveEmptyEntries);
foreach (var line in lines)
{
if (string.Equals(line.Trim(), "DRAFT", StringComparison.OrdinalIgnoreCase))
{
Console.WriteLine("The document is a draft.");
// Corrected HTML and CSS
string watermark = @"<div style='color:red; font-size:72px; font-weight:bold;'>DRAFT</div>";
pdf.ApplyWatermark(watermark, rotation: 45, opacity: 70,
verticalAlignment: VerticalAlignment.Middle,
horizontalAlignment: HorizontalAlignment.Center);
pdf.SaveAs("watermarked_invoice.pdf");
}
}Imports Microsoft.VisualBasic
Imports IronPdf
Imports IronPdf.Editing
License.LicenseKey = "IRONSUITE.WRITERS.21046-907F5E67CC-AHYQW6L-RCHLPMRJMU4G-SET72XAF2JNY-LQK45E5JPLGW-XOLPVBEBLHV7-2LHKZRWUZWMO-5LNIZSPF4BM6-UHUH4R-T4MMJ4MEIYSQEA-DEPLOYMENT.TRIAL-LDG2MK.TRIAL.EXPIRES.16.NOV.2025"
Dim pdf = New IronPdf.PdfDocument("invoice.pdf")
Dim content As String = pdf.ExtractAllText()
Dim lines = content.Split( { ControlChars.Cr, ControlChars.Lf }, StringSplitOptions.RemoveEmptyEntries)
For Each line In lines
If String.Equals(line.Trim(), "DRAFT", StringComparison.OrdinalIgnoreCase) Then
Console.WriteLine("The document is a draft.")
' Corrected HTML and CSS
Dim watermark As String = "<div style='color:red; font-size:72px; font-weight:bold;'>DRAFT</div>"
pdf.ApplyWatermark(watermark, rotation:= 45, opacity:= 70, verticalAlignment:= VerticalAlignment.Middle, horizontalAlignment:= HorizontalAlignment.Center)
pdf.SaveAs("watermarked_invoice.pdf")
End If
Next linestring.Equalsを使用することで、入力PDFドキュメントがドラフトとしての印を含むかどうかを確認でき、そうであれば、プログラムはそのドキュメントに"DRAFT"という透かしを適用して保存します。
出力
IronPDFとstring.Equalsのベストプラクティス
-
常にStringComparisonを指定してください。これにより、カルチュアや大文字小文字の違いによるバグを回避できます。
-
ユーザー入力または抽出されたテキストを比較する際にTrim()やNormalize()を使用してください。
-
大きなドキュメントの場合、オーバーヘッドを減らすために必要なページやセグメントのみを抽出してください。
- string.EqualsをRegexやContainsと組み合わせてハイブリッド文字列マッチング戦略を実行します。
IronPDFが簡単にしている理由
IronPDFは開発者がPDFとやり取りする方法を簡素化します。 C#のstring.Equalsと組み合わせることで、定型文やサードパーティツールなしで動的でインテリジェントなPDFワークフローを構築できます。
IronPDFの主な利点:
-
フルテキストの抽出とパース。
-
メタデータへの簡単なアクセス。
-
ネイティブC#ロジックを使用した条件付き操作。
- AdobeやMS Officeのような外部依存関係が不要。
StringComparisonオプションの詳細
C#で文字列を比較する際、StringComparisonオプションの選択は比較の動作とパフォーマンスに大きく影響を与えることがあります。 最も一般的なオプションの概要を簡単に紹介します。
-
Ordinal: 大文字小文字を区別しカルチュアに依存しない高速なバイト単位の比較を行います。カルチャが問題にならない厳密な一致に最適です。
-
OrdinalIgnoreCase: 上記と同様ですが大文字小文字の違いを無視します。 ケースの不一致が発生する可能性があるPDFテキスト抽出のシナリオに最適です。
-
CurrentCulture: コード実行環境の文化的ルールを考慮します。 ローカル言語の規範を尊重すべきユーザー向けテキストを比較する際に便利です。 現在のカルチャを考慮し、ローカライズされた文字列比較に役立ちます。
-
CurrentCultureIgnoreCase: 上記と同様ですが大文字小文字を無視します。
- InvariantCultureおよびInvariantCultureIgnoreCase: カルチャを超えた一貫性のある比較を提供し、グローバル化したアプリ内での文字列の等価性に重要です。
正しいオプションを選択することで、文字列の比較が予測通りに動作することを保証します。 IronPDFを介して抽出されたPDFテキストには、OrdinalIgnoreCaseがしばしば最適な選択で、パフォーマンスと使いやすさのバランスを取ります。
大規模なPDFドキュメントのパフォーマンスを考慮
大きなPDFを効率的に処理することは、アプリケーションの応答性を維持する鍵です。 次に、いくつかのヒントをご紹介します。
-
ファイル全体ではなく特定のページからテキストを抽出します。
-
同じドキュメントを複数回処理する際は、抽出したテキストをキャッシュします。
-
正確な等価性チェックにはstring.Equalsを使用し、部分一致にはContainsを使用し、必要でない限り高価な正規表現操作を避けます。
-
複数のPDFを同時に処理するために非同期処理や並列化を活用します。
- 比較の前に文字列(string str1, string str2)を正常化し、不可視文字や形式の違いによる偽の不一致を避けます。
これらの技術を実装することで、PDFワークフローが優美にスケールし、比較が正確であることを維持できます。
エラーハンドリングとデバッグのヒント
ランタイムの問題を避け、信頼性を確保するために以下を確認してください。
-
null参照例外を防ぐために、オブジェクトobjや文字列が比較の前にnullであるかどうかをチェックします。
-
ランタイム中にメソッドが返す内容を検証するために抽出した内容を記録します。
-
不要な空白や特殊なUnicode文字を処理するためにTrim()や正規化を使用します。
-
PDFの読み込みとテキストの抽出の周りに例外処理を含めます。
- ケースセンシティブおよびケースインセンシティブな比較を含むさまざまな入力シナリオをカバーする単体テストを作成します。
最終的な考え
C# string.Equalsは単純でありながら強力なメソッドであり、IronPDFの堅牢なPDF機能と一緒に使用するとさらに効果的です。 メタデータの確認、抽出したテキストの検証、条件付きロジックの適用を行うかどうかにかかわらず、この組み合わせは.NETでのPDF自動化ワークフロー全体を制御する力を与えます。
🔗 IronPDFで今日から始めましょう
C#を使ったインテリジェントなPDFワークフローの構築を始めたいですか? IronPDF NuGetパッケージをダウンロードして、.NETのPDF生成、編集、抽出のフルパワーを探ってみましょう。
よくある質問
C# における string.Equals メソッドの目的は何ですか?
C# の string.Equals メソッドは、文字列オブジェクトを等価性で比較するために使用されます。このメソッドにより、2つの文字列が同じ値を持っているかどうかを正確に判断することができ、PDF ドキュメントでメタデータや抽出したテキストの検証などに欠かせません。
IronPDF は C# アプリケーションでの string.Equals の使用をどのように強化できますか?
IronPDF は、PDF ドキュメントからテキストを抽出する機能を含む、強力な PDF 操作能力を提供することで、string.Equals の使用を強化できます。これにより、開発者は string.Equals を活用して、PDF 自動化タスクの一環として抽出したテキストを比較および検証することができます。
PDF ドキュメントの処理において、なぜ文字列比較が重要なのですか?
文字列比較は、抽出したテキストの確認、メタデータの検証、および特定の文字列値に基づいてドキュメントを条件に応じて修正するために重要です。これにより、データの正確性と期待される内容への準拠が保証されます。
IronPDF は PDF のメタデータ検証を行えますか?
はい、IronPDF は PDF のメタデータ検証を可能にします。開発者がメタデータを抽出し、string.Equals などのメソッドを使用してメタデータが指定された基準を満たしているかを比較および検証することができます。
string.EqualsがIronPDFと一緒に使われる一般的なタスクにはどのようなものがありますか?
IronPDF と 함께 string.Equals が使用される一般的なタスクには、抽出したテキストが基準に適合しているかの確認、PDF ドキュメントのメタデータの検証、および特定の文字列がドキュメントに出現することを確保してからさらに処理することが含まれます。