C# String Equals (Wie es für Entwickler funktioniert)
Beim Arbeiten mit PDF-Dokumenten in C#-Anwendungen ist das Vergleichen von Zeichenfolgen eine überraschend häufige Aufgabe, sei es beim Überprüfen des extrahierten Textes, beim Verifizieren von Metadaten oder beim bedingten Ändern von Dokumenten. Die string.Equals-Methode in C# bietet eine präzise Möglichkeit zum Vergleichen von Zeichenfolgenobjekten, und in Kombination mit IronPDF wird sie zu einem leistungsstarken Werkzeug in Ihrem PDF-Automatisierungs-Toolkit.
In diesem Artikel werden wir untersuchen, was string.Equals ist, warum es in .NET wichtig ist und wie Sie es effektiv zusammen mit IronPDF, der führenden .NET-PDF-Bibliothek für Erzeugung und Bearbeitung, verwenden können.
Was ist string.Equals in C#?
Die C-Zeichenfolge-Gleich-Methode, in C# als string.Equals bekannt, wird verwendet, um den Inhalt von zwei Parametern zu vergleichen, die entweder Zeichenfolgen oder andere kompatible Objekte darstellen. Sie können entweder einfache Zeichenfolgenwerte oder ein Typobjekt übergeben, das während des Vergleichs in eine Zeichenfolge konvertiert wird. Im Gegensatz zum == Operator, der syntaktischer Zucker für equals string ist, ermöglicht Ihnen die explizite Verwendung von string.Equals Folgendes:
-
Vergleichsregeln anzugeben (wie z.B. groß-/kleinschreibungssensitiven Vergleich oder kulturunsensitiven Vergleich).
-
Verwirrung mit überladenen Operatoren zu vermeiden.
- Lesbarkeit in Bedingungslogik zu verbessern.
Im .NET Framework sieht die Methodensignatur oft so aus:
public bool Equals(string value, StringComparison comparisonType)public bool Equals(string value, StringComparison comparisonType)'INSTANT VB TODO TASK: The following line uses invalid syntax:
'public bool Equals(string value, StringComparison comparisonType)Hier zeigt public bool an, dass der Rückgabewert je nach Vergleichsergebnis immer true oder false sein wird.
Grundlegende Syntax
string.Equals(str1, str2)
string.Equals(str1, str2, StringComparison.OrdinalIgnoreCase)string.Equals(str1, str2)
string.Equals(str1, str2, StringComparison.OrdinalIgnoreCase)'INSTANT VB TODO TASK: The following line uses invalid syntax:
'string.Equals(str1, str2) string.Equals(str1, str2, StringComparison.OrdinalIgnoreCase)Diese Methode nimmt zwei Parameter: die beiden zu vergleichenden Zeichenfolgen oder Zeichenfolgenobjekte und optional den Typ des auszuführenden Vergleichs. Der Rückgabewert ist ein boolescher Wert. Die Methode gibt true zurück, wenn beide Argumente gemäß den Vergleichsregeln gleich sind oder andernfalls false.
Sie können zwei Zeichenfolgen mit verschiedenen StringComparison-Optionen vergleichen wie:
-
Ordinal (binärer Vergleich, groß-/kleinschreibungssensitiver Vergleich)
-
OrdinalIgnoreCase (groß-/kleinschreibungsunsensitiver Vergleich)
-
CurrentCulture
- InvariantCultureIgnoreCase
Wie es mit IronPDF funktioniert
IronPDF ist eine leistungsstarke .NET PDF-Bibliothek, die es Ihnen ermöglicht, innerhalb von PDF-Dokumenten zu suchen, Text zu extrahieren und zu bearbeiten. Durch die Verwendung von string.Equals können Sie:
-
Den extrahierten Zeichenfolgenwert mit einem bekannten Wert vergleichen.
-
Metadatenfelder wie Titel, Autor und Schlüsselwörter überprüfen.
- Bedingt Ihre PDF-Dokumente bearbeiten, was Ihnen ermöglicht, Anmerkungen, Hervorhebungen oder Wasserzeichen basierend auf den Ergebnissen des Zeichenfolgenvergleichs hinzuzufügen.
Lassen Sie uns die folgenden Beispiele durchgehen, in denen sich string.Equals in IronPDF-Workflows als nützlich erweist.
Beispiel 1: Extrahierten Text mit string.Equals vergleichen
Stellen Sie sich vor, Sie scannen eine PDF-Rechnung und möchten überprüfen, ob sie einen bestimmten Firmennamen enthält. Hier ist ein Beispiel, das zeigt, wie Sie häufige Fallstricke wie Nullreferenz-Ausnahmen vermeiden und wie die Methode gleich robust prüft.
Das folgende Beispiel wird dieses PDF verwenden:

using IronPdf;
using IronPdf.Editing;
class Program
{
public static void Main(string[] args)
{
var pdf = new IronPdf.PdfDocument("invoice.pdf");
string extractedText = pdf.ExtractAllText();
var lines = extractedText.Split(new[] { '\r', '\n' }, StringSplitOptions.RemoveEmptyEntries);
foreach (var line in lines)
{
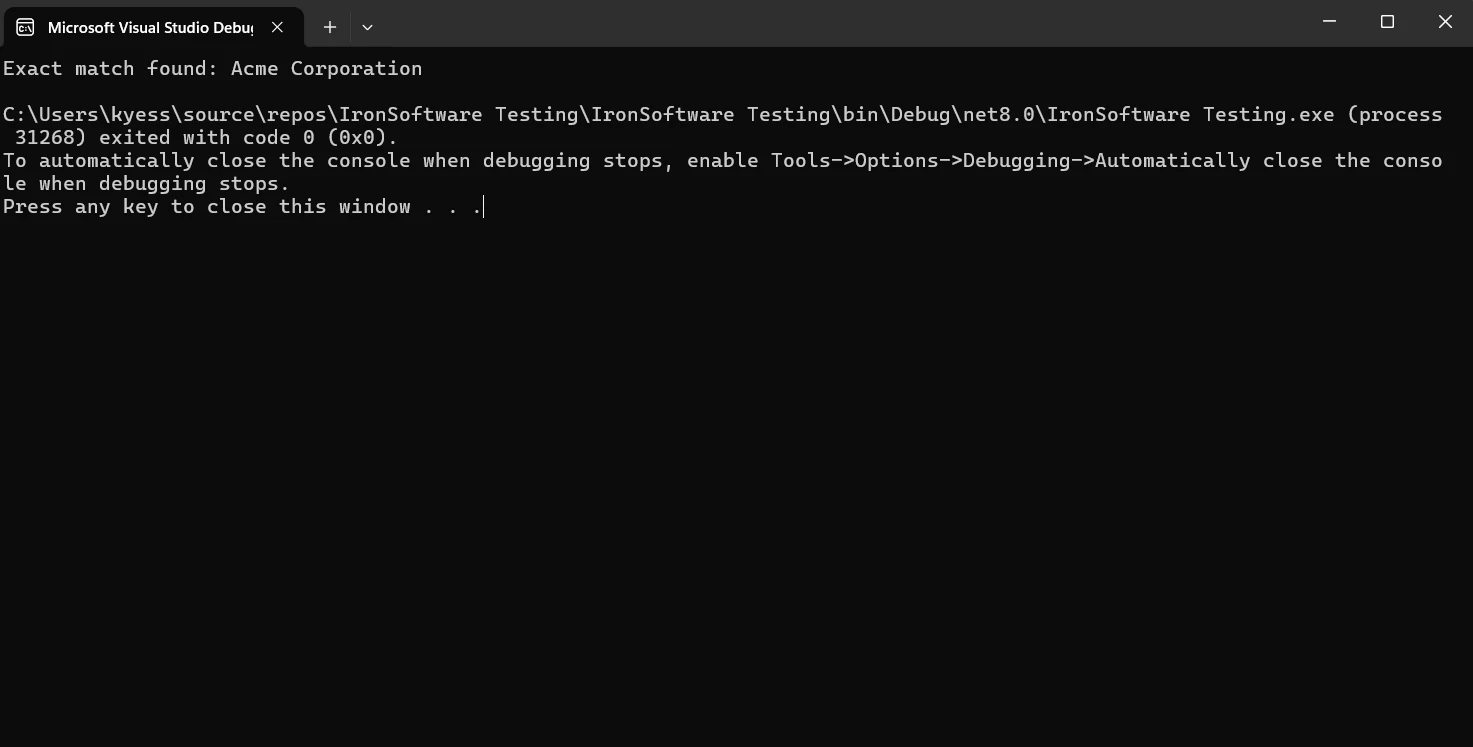
if (string.Equals(line.Trim(), "Acme Corporation", StringComparison.OrdinalIgnoreCase))
{
Console.WriteLine("Exact match found: Acme Corporation");
}
}
}
}using IronPdf;
using IronPdf.Editing;
class Program
{
public static void Main(string[] args)
{
var pdf = new IronPdf.PdfDocument("invoice.pdf");
string extractedText = pdf.ExtractAllText();
var lines = extractedText.Split(new[] { '\r', '\n' }, StringSplitOptions.RemoveEmptyEntries);
foreach (var line in lines)
{
if (string.Equals(line.Trim(), "Acme Corporation", StringComparison.OrdinalIgnoreCase))
{
Console.WriteLine("Exact match found: Acme Corporation");
}
}
}
}Imports Microsoft.VisualBasic
Imports IronPdf
Imports IronPdf.Editing
Friend Class Program
Public Shared Sub Main(ByVal args() As String)
Dim pdf = New IronPdf.PdfDocument("invoice.pdf")
Dim extractedText As String = pdf.ExtractAllText()
Dim lines = extractedText.Split( { ControlChars.Cr, ControlChars.Lf }, StringSplitOptions.RemoveEmptyEntries)
For Each line In lines
If String.Equals(line.Trim(), "Acme Corporation", StringComparison.OrdinalIgnoreCase) Then
Console.WriteLine("Exact match found: Acme Corporation")
End If
Next line
End Sub
End ClassHinweis: Die Methode gibt einen booleschen Wert zurück, der angibt, ob die beiden Zeichenfolgenobjekte denselben Wert enthalten.
Warum dies wichtig ist:
Wie wir im folgenden Output sehen, stellt die Verwendung von string.Equals mit StringComparison.OrdinalIgnoreCase sicher, dass "ACME CORPORATION" und "Acme Corporation" als gleich behandelt werden - entscheidend in OCR- oder Textextraktions-Szenarien, in denen groß-/kleinschreibungsbedingte Unterschiede zu unterschiedlichem Verhalten führen könnten.
Ausgabe
Beispiel 2: Validieren von PDF-Metadaten mit string.Equals
PDF-Dateien enthalten häufig Metadaten-Felder wie Titel, Autor und Betreff. IronPDF kann verwendet werden, um diese Eigenschaften zu lesen, was es einfach macht, sie zu überprüfen und zu vergleichen.
using IronPdf;
var pdf = new IronPdf.PdfDocument("invoice.pdf");
string author = pdf.MetaData.Author;
if (string.Equals(author, "Iron Software", StringComparison.InvariantCulture))
{
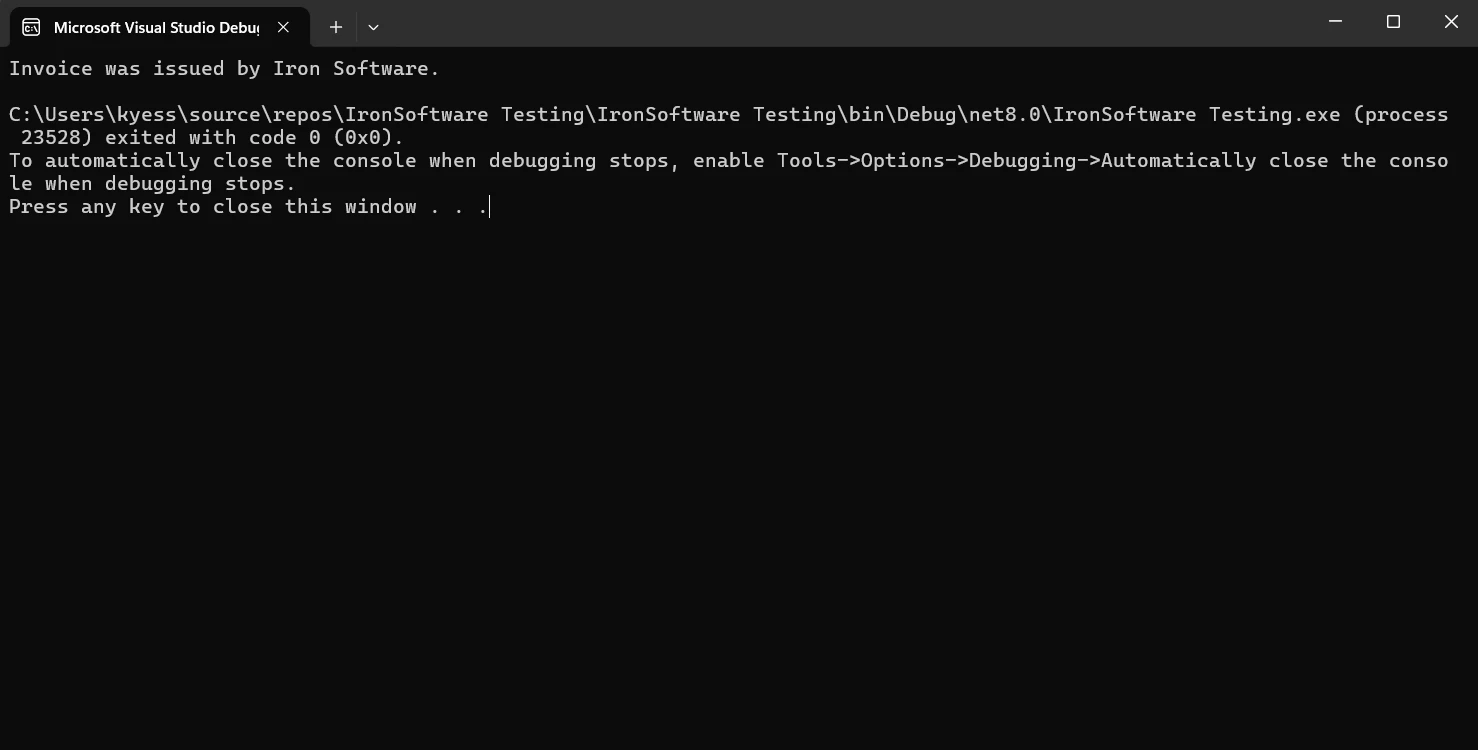
Console.WriteLine("Invoice was issued by Iron Software.");
}using IronPdf;
var pdf = new IronPdf.PdfDocument("invoice.pdf");
string author = pdf.MetaData.Author;
if (string.Equals(author, "Iron Software", StringComparison.InvariantCulture))
{
Console.WriteLine("Invoice was issued by Iron Software.");
}Imports IronPdf
Private pdf = New IronPdf.PdfDocument("invoice.pdf")
Private author As String = pdf.MetaData.Author
If String.Equals(author, "Iron Software", StringComparison.InvariantCulture) Then
Console.WriteLine("Invoice was issued by Iron Software.")
End IfDiese Methode ist besonders nützlich in Systemen, in denen die Validierung basierend auf Metadaten die Verarbeitung von Nicht-Zeichenfolgen- oder ungültigen Dateien verhindert.
Ausgabe
Beispiel 3: Wasserzeichen auf der Grundlage eines Textmatches hinzufügen
Möglicherweise möchten Sie PDF-Dokumente automatisch mit einem Wasserzeichen versehen, die bestimmte Schlüsselwörter enthalten. Hier erfahren Sie, wie das geht:
using IronPdf;
using IronPdf.Editing;
License.LicenseKey = "IRONSUITE.WRITERS.21046-907F5E67CC-AHYQW6L-RCHLPMRJMU4G-SET72XAF2JNY-LQK45E5JPLGW-XOLPVBEBLHV7-2LHKZRWUZWMO-5LNIZSPF4BM6-UHUH4R-T4MMJ4MEIYSQEA-DEPLOYMENT.TRIAL-LDG2MK.TRIAL.EXPIRES.16.NOV.2025";
var pdf = new IronPdf.PdfDocument("invoice.pdf");
string content = pdf.ExtractAllText();
var lines = content.Split(new[] { '\r', '\n' }, StringSplitOptions.RemoveEmptyEntries);
foreach (var line in lines)
{
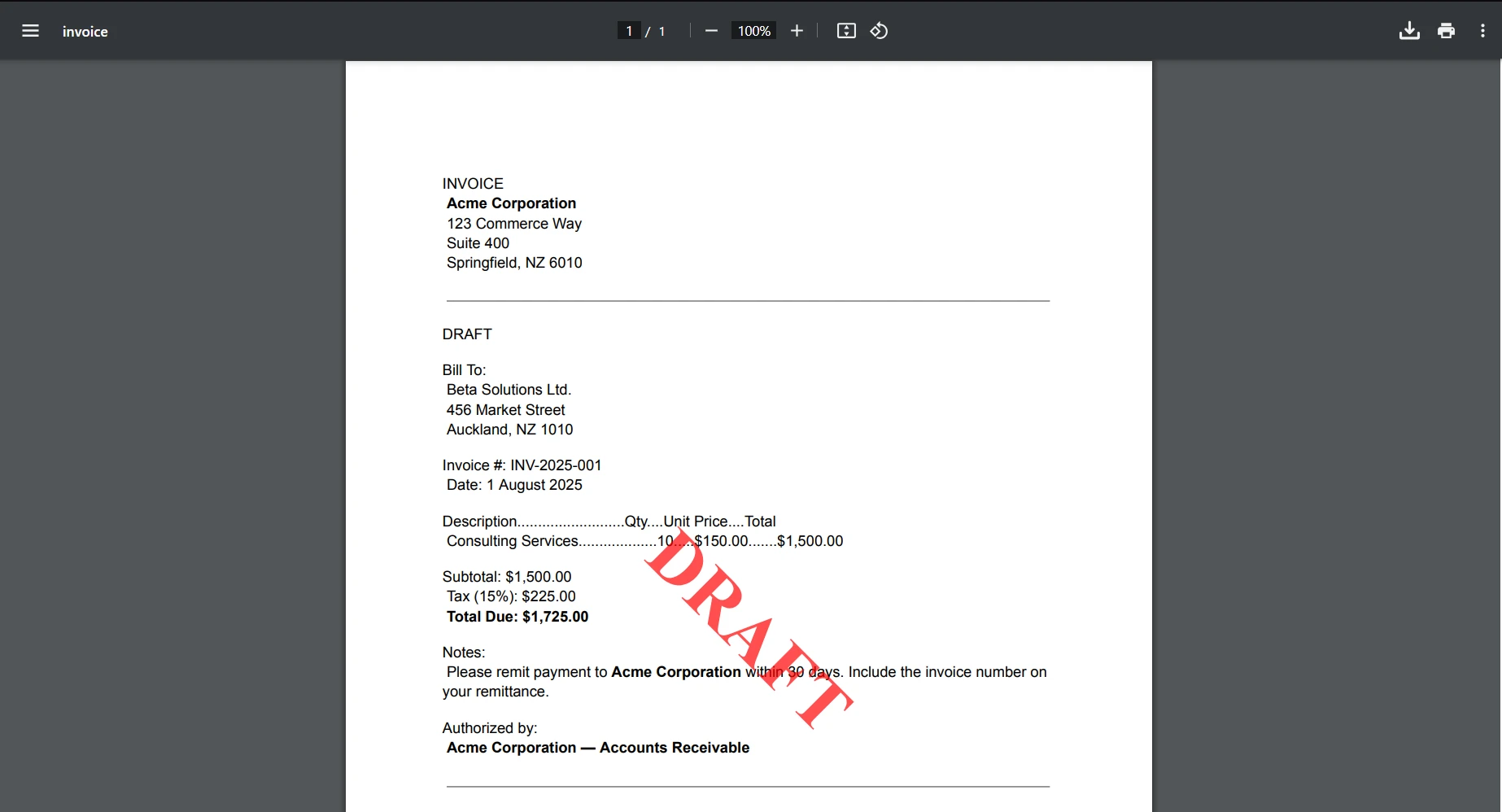
if (string.Equals(line.Trim(), "DRAFT", StringComparison.OrdinalIgnoreCase))
{
Console.WriteLine("The document is a draft.");
// Corrected HTML and CSS
string watermark = @"<div style='color:red; font-size:72px; font-weight:bold;'>DRAFT</div>";
pdf.ApplyWatermark(watermark, rotation: 45, opacity: 70,
verticalAlignment: VerticalAlignment.Middle,
horizontalAlignment: HorizontalAlignment.Center);
pdf.SaveAs("watermarked_invoice.pdf");
}
}using IronPdf;
using IronPdf.Editing;
License.LicenseKey = "IRONSUITE.WRITERS.21046-907F5E67CC-AHYQW6L-RCHLPMRJMU4G-SET72XAF2JNY-LQK45E5JPLGW-XOLPVBEBLHV7-2LHKZRWUZWMO-5LNIZSPF4BM6-UHUH4R-T4MMJ4MEIYSQEA-DEPLOYMENT.TRIAL-LDG2MK.TRIAL.EXPIRES.16.NOV.2025";
var pdf = new IronPdf.PdfDocument("invoice.pdf");
string content = pdf.ExtractAllText();
var lines = content.Split(new[] { '\r', '\n' }, StringSplitOptions.RemoveEmptyEntries);
foreach (var line in lines)
{
if (string.Equals(line.Trim(), "DRAFT", StringComparison.OrdinalIgnoreCase))
{
Console.WriteLine("The document is a draft.");
// Corrected HTML and CSS
string watermark = @"<div style='color:red; font-size:72px; font-weight:bold;'>DRAFT</div>";
pdf.ApplyWatermark(watermark, rotation: 45, opacity: 70,
verticalAlignment: VerticalAlignment.Middle,
horizontalAlignment: HorizontalAlignment.Center);
pdf.SaveAs("watermarked_invoice.pdf");
}
}Imports Microsoft.VisualBasic
Imports IronPdf
Imports IronPdf.Editing
License.LicenseKey = "IRONSUITE.WRITERS.21046-907F5E67CC-AHYQW6L-RCHLPMRJMU4G-SET72XAF2JNY-LQK45E5JPLGW-XOLPVBEBLHV7-2LHKZRWUZWMO-5LNIZSPF4BM6-UHUH4R-T4MMJ4MEIYSQEA-DEPLOYMENT.TRIAL-LDG2MK.TRIAL.EXPIRES.16.NOV.2025"
Dim pdf = New IronPdf.PdfDocument("invoice.pdf")
Dim content As String = pdf.ExtractAllText()
Dim lines = content.Split( { ControlChars.Cr, ControlChars.Lf }, StringSplitOptions.RemoveEmptyEntries)
For Each line In lines
If String.Equals(line.Trim(), "DRAFT", StringComparison.OrdinalIgnoreCase) Then
Console.WriteLine("The document is a draft.")
' Corrected HTML and CSS
Dim watermark As String = "<div style='color:red; font-size:72px; font-weight:bold;'>DRAFT</div>"
pdf.ApplyWatermark(watermark, rotation:= 45, opacity:= 70, verticalAlignment:= VerticalAlignment.Middle, horizontalAlignment:= HorizontalAlignment.Center)
pdf.SaveAs("watermarked_invoice.pdf")
End If
Next lineDurch die Verwendung von string.Equals sind wir in der Lage zu prüfen, ob das Eingabe-PDF-Dokument den Text enthält, der es als Entwurf kennzeichnet, und wenn ja, wird das Programm unser "DRAFT"-Wasserzeichen auf das Dokument anwenden und es speichern.
Ausgabe
Best Practices für die Verwendung von string.Equals mit IronPDF
-
Geben Sie immer eine StringComparison an, um Fehler aufgrund von Kultur- oder Groß-/Kleinschreibungsunterschieden zu vermeiden.
-
Verwenden Sie Trim() oder Normalize(), wenn Sie benutzerdefinierten oder extrahierten Text vergleichen.
-
Bei großen Dokumenten extrahieren Sie nur die notwendigen Seiten oder Segmente, um den Overhead zu reduzieren.
- Kombinieren Sie string.Equals mit Regex oder Contains für hybride Strategien zur Zeichenfolgenübereinstimmung.
Warum IronPDF es einfach macht
IronPDF vereinfacht die Art und Weise, wie Entwickler mit PDFs arbeiten. In Kombination mit string.Equals in C# ermöglicht es Ihnen, dynamische, intelligente PDF-Workflows ohne Boilerplate oder Drittanbieter-Tools zu erstellen.
Wichtige Vorteile von IronPDF:
-
Vollständige Textextraktion und -analyse.
-
Einfacher Zugriff auf Metadaten.
-
Bedingte Bearbeitung mit nativer C#-Logik.
- Keine Notwendigkeit für externe Abhängigkeiten wie Adobe oder MS Office.
Tiefes Eintauchen in die StringComparison Optionen
Beim Vergleich von Zeichenfolgen in C# kann die Wahl der StringComparison-Option das Verhalten und die Leistung Ihrer Vergleiche erheblich beeinflussen. Hier ist ein kurzer Überblick über die am häufigsten verwendeten Optionen:
-
Ordinal: Führt einen schnellen, byteweisen Vergleich durch, der groß-/kleinschreibungssensitiv und kulturunsensitiv ist. Ideal für exakte Übereinstimmungen, bei denen Kultur nicht relevant ist.
-
OrdinalIgnoreCase: Gleich wie oben, aber ignoriert Groß-/Kleinschreibungsunterschiede. Ideal für Szenarien wie PDF-Textextraktion, bei denen Inkonsistenzen in der Groß-/Kleinschreibung auftreten können.
-
CurrentCulture: Berücksichtigt kulturelle Regeln der Umgebung, in der der Code ausgeführt wird. Nützlich beim Vergleich benutzerbezogener Texte, die lokale Sprachregeln respektieren sollten. Berücksichtigen Sie die aktuelle Kultur, nützlich für lokalen Zeichenfolgenvergleich.
-
CurrentCultureIgnoreCase: Gleich wie oben, aber ignoriert Groß-/Kleinschreibung.
- InvariantCulture und InvariantCultureIgnoreCase: Bieten einen konsistenten Vergleich über Kulturen hinweg, was entscheidend für die Zeichenfolgenvergleich in globalisierten Apps ist.
Die Wahl der richtigen Option stellt sicher, dass Ihre Zeichenfolgenvergleiche vorhersehbar funktionieren. Für von IronPDF extrahierten PDF-Text ist OrdinalIgnoreCase oft die beste Wahl, da es Leistung und Benutzerfreundlichkeit ausbalanciert.
Performance-Überlegungen für große PDF-Dokumente
Die effiziente Handhabung großer PDFs ist entscheidend für die Aufrechterhaltung ansprechbarer Anwendungen. Hier einige Tipps:
-
Extrahieren Sie Text von bestimmten Seiten anstatt der gesamten Datei.
-
Cachen Sie extrahierten Text, wenn dasselbe Dokument mehrmals verarbeitet wird.
-
Verwenden Sie string.Equals für exakte Gleichheitsprüfungen und Contains für Teilzeichenfolgenvergleich, vermeiden Sie teure Regex-Operationen wenn möglich.
-
Nutzen Sie asynchrone Verarbeitung oder Parallelisierung, um mehrere PDFs gleichzeitig zu bearbeiten.
- Bereinigen und normalisieren Sie Zeichenfolgen (string str1, string str2) vor dem Vergleich, um falsche Nichtübereinstimmungen aufgrund unsichtbarer Zeichen oder Formatierungen zu vermeiden.
Die Implementierung dieser Techniken hilft, dass Ihre PDF-Workflows reibungslos skalieren und gleichzeitig die Vergleiche genau bleiben.
Tipps zur Fehlerbehandlung und Fehlersuche
Um Laufzeitprobleme zu vermeiden und Zuverlässigkeit sicherzustellen:
-
Schützen Sie sich vor Nullwerten, um eine Nullreferenz-Ausnahme zu verhindern, indem Sie prüfen, ob das Objekt obj oder die Zeichenfolgen null sind, bevor Sie vergleichen.
-
Protokollieren Sie den extrahierten Inhalt, um zu überprüfen, was die Methode zur Laufzeit zurückgibt.
-
Verwenden Sie Trim() und Normalisierung, um Leerzeichen am Ende und spezielle Unicode-Zeichen zu behandeln.
-
Schließen Sie die Behandlung von Ausnahmen beim Laden und Extrahieren von Text in PDFs ein.
- Schreiben Sie Unit-Tests, die verschiedene Eingabeszenarien abdecken, einschließlich groß-/kleinschreibungssensitiven und -unsensitiven Vergleichen.
Abschließende Gedanken
C# string.Equals ist eine einfache, aber leistungsstarke Methode, die noch effektiver wird, wenn sie mit den robusten PDF-Funktionen von IronPDF's verwendet wird. Egal, ob Sie Metadaten überprüfen, extrahierten Text validieren oder bedingte Logik anwenden, diese Kombination gibt Ihnen die volle Kontrolle über Ihre PDF-Automatisierungs-Workflows in .NET.
🔗 Legen Sie noch heute mit IronPDF los
Bereit, intelligente PDF-Workflows mit C# zu erstellen? Laden Sie das IronPDF NuGet-Paket herunter und entdecken Sie die volle Leistung der .NET PDF-Erstellung, -Bearbeitung und -Extraktion.
Häufig gestellte Fragen
Was ist der Zweck der string.Equals-Methode in C#?
Die string.Equals-Methode in C# wird verwendet, um String-Objekte auf Gleichheit zu vergleichen. Sie bietet eine präzise Möglichkeit, festzustellen, ob zwei Strings denselben Wert haben, was für Aufgaben wie die Überprüfung von Metadaten oder extrahiertem Text in PDF-Dokumenten unerlässlich ist.
Wie kann IronPDF die Verwendung von string.Equals in C#-Anwendungen verbessern?
IronPDF kann die Verwendung von string.Equals verbessern, indem es umfangreiche PDF-Manipulationsmöglichkeiten bietet, die das Extrahieren von Texten aus PDF-Dokumenten einschließen. Dies ermöglicht es Entwicklern, string.Equals für den Vergleich und die Überprüfung extrahierter Texte im Rahmen ihrer PDF-Automatisierungsaufgaben zu nutzen.
Warum ist der String-Vergleich wichtig bei der Handhabung von PDF-Dokumenten?
Der String-Vergleich ist bei der Handhabung von PDF-Dokumenten wichtig, da er es Entwicklern ermöglicht, extrahierten Text zu überprüfen, Metadaten zu verifizieren und Dokumente basierend auf bestimmten String-Werten bedingt zu ändern, um die Genauigkeit der Daten und die Einhaltung der erwarteten Inhalte sicherzustellen.
Kann IronPDF die Metadaten-Überprüfung in PDFs bewältigen?
Ja, IronPDF kann die Metadaten-Überprüfung in PDFs bewältigen, indem es Entwicklern ermöglicht, Metadaten zu extrahieren und Methoden wie string.Equals zum Vergleich und zur Verifizierung einzusetzen, dass die Metadaten festgelegten Kriterien entsprechen.
Welche gängigen Aufgaben gibt es, bei denen string.Equals mit IronPDF verwendet werden könnte?
Gängige Aufgaben, bei denen string.Equals mit IronPDF verwendet werden könnte, umfassen die Überprüfung, ob extrahierter Text den Kriterien entspricht, die Verifizierung von PDF-Dokumenten-Metadaten und die Gewährleistung, dass bestimmte Strings in einem Dokument vorkommen, bevor weiterverarbeitet wird.