
C# Directory.GetFiles (Jak to działa: Przewodnik dla deweloperów)
Łącząc tę funkcjonalność z IronPDF, deweloperzy mogą automatyzować przepływy PDF na dużą skalę. Na przykład można użyć Directory.GetFiles do zlokalizowania wszystkich plików PDF w folderze, a następnie przetworzyć je masowo z IronPDF w celu scalania, dodawania adnotacji lub generowania raportów. To połączenie pozwala na sprawniejsze działania, szczególnie przy pracy z wieloma plikami w systemie plików.
Czym jest IronPDF?
IronPDF to solidna biblioteka .NET, która zapewnia deweloperom narzędzia do bezproblemowej pracy z plikami PDF. Z IronPDF można tworzyć, edytować, scalać, dzielić i manipulować plikami PDF, używając prostych, intuicyjnych metod. Zawiera zaawansowane funkcje, takie jak konwersja HTML na PDF, zaawansowane stylowanie i zarządzanie metadanymi. Dla deweloperów .NET pracujących nad aplikacjami wymagającymi przetwarzania PDF, IronPDF jest nieocenionym narzędziem, które usprawnia przepływy pracy i zwiększa wydajność.
Pierwsze kroki
Instalacja IronPDF
Instalacja pakietu NuGet
Aby rozpoczac, dodaj IronPDF do swojego projektu poprzez NuGet:
- Otwórz swój projekt w Visual Studio.
- Przejdź do menu Narzędzia i wybierz Menedżer pakietów NuGet > Zarządzaj pakietami NuGet dla rozwiązania.
- Wyszukaj IronPDF w menedżerze pakietów NuGet.
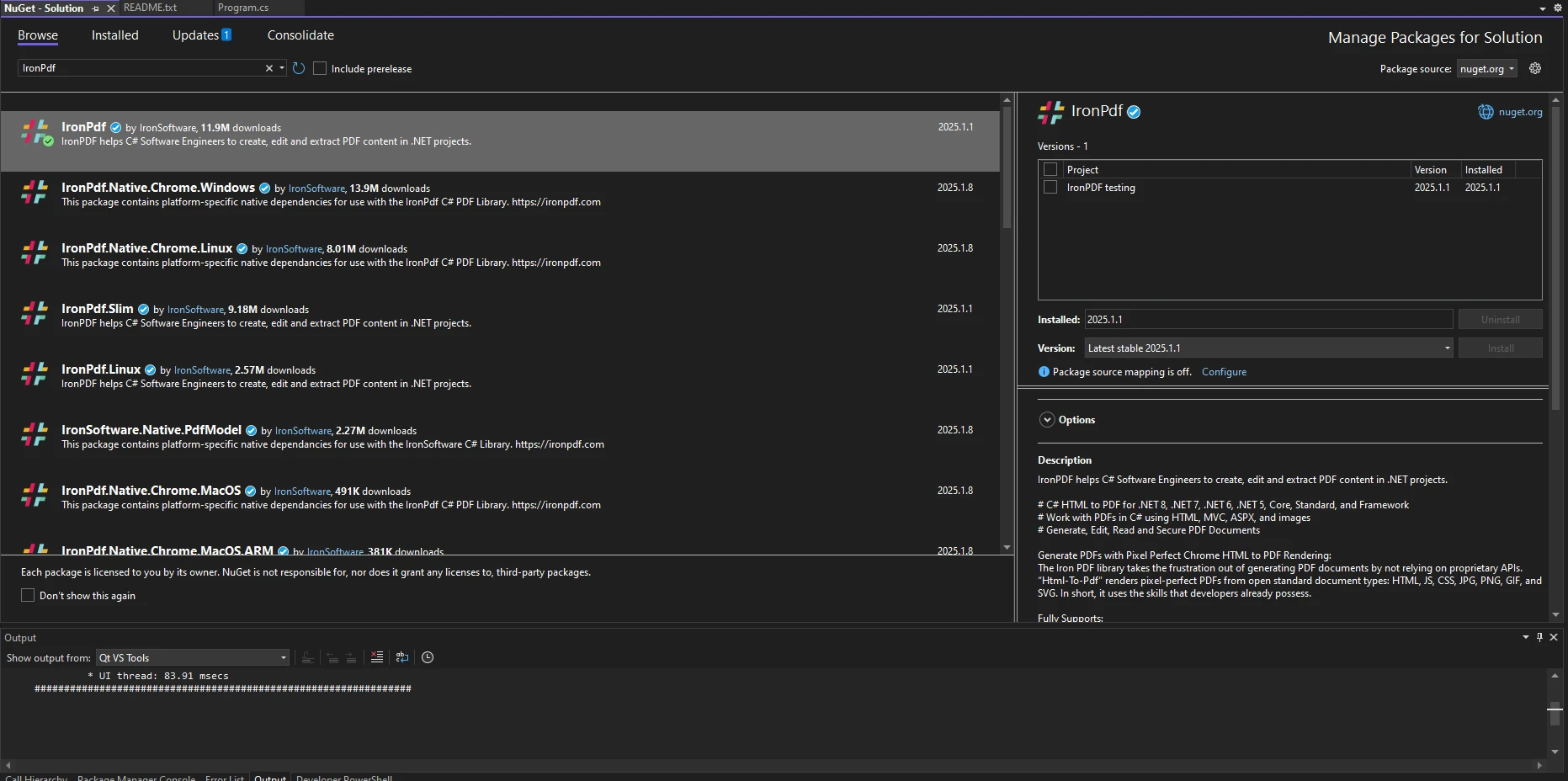
- Zainstaluj najnowszą wersję IronPDF.
Alternatywnie, użyj konsoli Menedżera pakietów NuGet:
Install-Package IronPdf
Podstawy Directory.GetFiles w języku C
Metoda Directory.GetFiles jest częścią przestrzeni nazw System.IO i służy do uzyskiwania nazw plików z systemu plików. Ta metoda, publiczny statyczny członek klasy Directory, upraszcza dostęp do ścieżek plików. Na przykład:
string[] pdfFiles = Directory.GetFiles("C:\\Documents\\PDFs", "*.pdf");string[] pdfFiles = Directory.GetFiles("C:\\Documents\\PDFs", "*.pdf");Dim pdfFiles() As String = Directory.GetFiles("C:\Documents\PDFs", "*.pdf")Ten fragment kodu pobiera wszystkie pliki PDF w bieżącym katalogu. Łącząc tę metodę z IronPDF, można tworzyć zautomatyzowane rozwiązania do przetwarzania wielu plików jednocześnie. Można również zastosować określony wzorzec wyszukiwania, zdefiniowany jako wzorzec ciągu, aby filtrować pliki na podstawie ich rozszerzeń lub nazw.
Można bardziej doprecyzować logikę pobierania plików, określając opcje wyszukiwania, takie jak dołączanie podkatalogów wyszukiwania:
string[] pdfFiles = Directory.GetFiles("C:\\Documents\\PDFs", "*.pdf", SearchOption.AllDirectories);string[] pdfFiles = Directory.GetFiles("C:\\Documents\\PDFs", "*.pdf", SearchOption.AllDirectories);Dim pdfFiles() As String = Directory.GetFiles("C:\Documents\PDFs", "*.pdf", SearchOption.AllDirectories)To zapewnia, że pliki w zagnieżdżonych folderach są również uwzględnione, pobierając ścieżkę bezwzględną każdego pliku i czyniąc podejście uniwersalnym dla różnych scenariuszy.
Praktyczne przypadki użycia
Pobieranie i przetwarzanie plików PDF z katalogu
Przykład: Ładowanie wszystkich plików PDF do przetwarzania
Dzięki Directory.GetFiles można iterować po wszystkich plikach PDF w katalogu i przetwarzać je z IronPDF:
string[] pdfFiles = Directory.GetFiles("C:\\Documents\\PDFs", "*.pdf");
foreach (string file in pdfFiles)
{
// Load the PDF with IronPDF
var pdf = PdfDocument.FromFile(file);
Console.WriteLine($"Processing file: {Path.GetFileName(file)}");
}string[] pdfFiles = Directory.GetFiles("C:\\Documents\\PDFs", "*.pdf");
foreach (string file in pdfFiles)
{
// Load the PDF with IronPDF
var pdf = PdfDocument.FromFile(file);
Console.WriteLine($"Processing file: {Path.GetFileName(file)}");
}Dim pdfFiles() As String = Directory.GetFiles("C:\Documents\PDFs", "*.pdf")
For Each file As String In pdfFiles
' Load the PDF with IronPDF
Dim pdf = PdfDocument.FromFile(file)
Console.WriteLine($"Processing file: {Path.GetFileName(file)}")
Next file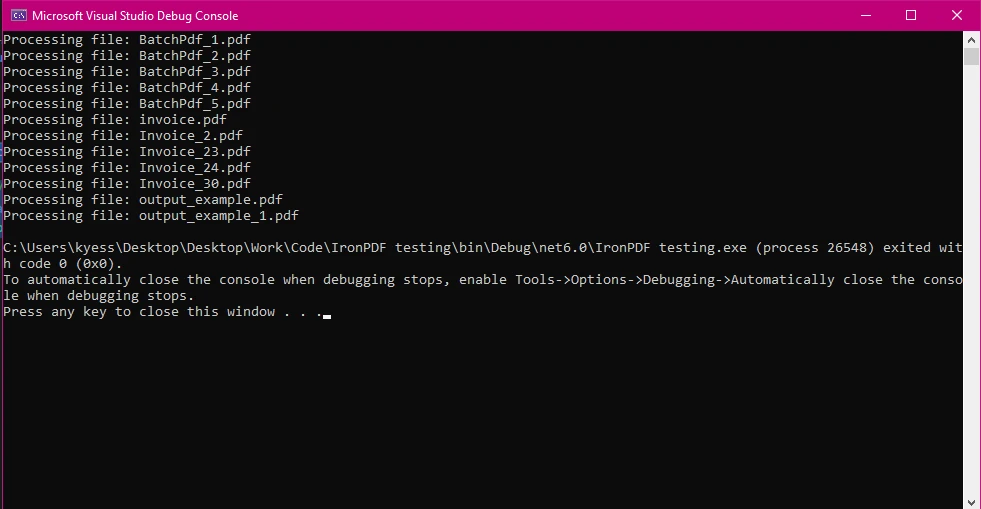
Ten przykład pokazuje, jak załadować wiele plików PDF z katalogu do przetwarzania. Po załadowaniu można wykonywać różne operacje, takie jak ekstrakcja tekstu, dodawanie adnotacji lub generowanie nowych plików PDF na podstawie ich zawartości.
Filtrowanie plików za pomocą wzorców wyszukiwania
Przykład: Wybór plików PDF według nazwy lub daty
Można łączyć Directory.GetFiles z LINQ, aby filtrować pliki na podstawie takich kryteriów jak data utworzenia lub modyfikacji:
string[] pdfFiles = Directory.GetFiles("C:\\Documents\\PDFs", "*.pdf");
var recentFiles = pdfFiles.Where(file => File.GetLastWriteTime(file) > DateTime.Now.AddDays(-7));
foreach (string file in recentFiles)
{
Console.WriteLine($"Recent file: {Path.GetFileName(file)}");
}string[] pdfFiles = Directory.GetFiles("C:\\Documents\\PDFs", "*.pdf");
var recentFiles = pdfFiles.Where(file => File.GetLastWriteTime(file) > DateTime.Now.AddDays(-7));
foreach (string file in recentFiles)
{
Console.WriteLine($"Recent file: {Path.GetFileName(file)}");
}Dim pdfFiles() As String = Directory.GetFiles("C:\Documents\PDFs", "*.pdf")
Dim recentFiles = pdfFiles.Where(Function(file) File.GetLastWriteTime(file) > DateTime.Now.AddDays(-7))
For Each file As String In recentFiles
Console.WriteLine($"Recent file: {Path.GetFileName(file)}")
Next file
To podejście zapewnia, że przetwarzane są tylko odpowiednie pliki, co oszczędza czas i zasoby obliczeniowe. Na przykład można użyć tej metody, aby przetworzyć tylko najnowsze faktury lub raporty wygenerowane w ciągu ostatniego tygodnia.
Operacje grupowe z IronPDF i Directory.GetFiles
Przykład: Dołączanie wielu plików PDF
Można dołączać wiele plików PDF z katalogu do pojedynczego pliku:
string[] pdfFiles = Directory.GetFiles("C:\\Documents\\PDFs", "*.pdf");
var pdfAppend = new PdfDocument(200, 200);
foreach (string file in pdfFiles)
{
var pdf = PdfDocument.FromFile(file);
pdfAppend.AppendPdf(pdf);
}
pdfAppend.SaveAs("LargePdf.pdf");
Console.WriteLine("PDFs Appended successfully!");string[] pdfFiles = Directory.GetFiles("C:\\Documents\\PDFs", "*.pdf");
var pdfAppend = new PdfDocument(200, 200);
foreach (string file in pdfFiles)
{
var pdf = PdfDocument.FromFile(file);
pdfAppend.AppendPdf(pdf);
}
pdfAppend.SaveAs("LargePdf.pdf");
Console.WriteLine("PDFs Appended successfully!");Dim pdfFiles() As String = Directory.GetFiles("C:\Documents\PDFs", "*.pdf")
Dim pdfAppend = New PdfDocument(200, 200)
For Each file As String In pdfFiles
Dim pdf = PdfDocument.FromFile(file)
pdfAppend.AppendPdf(pdf)
Next file
pdfAppend.SaveAs("LargePdf.pdf")
Console.WriteLine("PDFs Appended successfully!")
To podejście jest szczególnie przydatne do tworzenia skonsolidowanych raportów, archiwizacji wielu dokumentów lub przygotowania prezentacji. Automatyzując ten proces, można łatwo zarządzać dużą liczbą plików.
Wdrożenie krok po kroku
Konfiguracja projektu
Fragment kodu: Inicjowanie IronPDF i praca z plikami PDF
Poniższy kod pokazuje, jak IronPDF może być używany razem z Directory.GetFiles do ładowania i pracy z dokumentami PDF.
using IronPdf;
using System;
using System.IO;
class Program
{
static void Main()
{
// Retrieve all PDF file paths from the specified directory
string[] pdfFiles = Directory.GetFiles("C:\\Users\\kyess\\Documents\\PDFs", "*.pdf");
// Initialize a PdfDocument
var pdfAppend = new PdfDocument(200, 200);
// Create a text annotation to add to each PDF
TextAnnotation annotation = new TextAnnotation(0)
{
Contents = "Processed by IronPDF",
X = 50,
Y = 50,
};
// Iterate over each file path, load, annotate, and save
foreach (string file in pdfFiles)
{
var pdf = PdfDocument.FromFile(file);
pdf.Annotations.Add(annotation);
pdf.SaveAs(file);
}
}
}using IronPdf;
using System;
using System.IO;
class Program
{
static void Main()
{
// Retrieve all PDF file paths from the specified directory
string[] pdfFiles = Directory.GetFiles("C:\\Users\\kyess\\Documents\\PDFs", "*.pdf");
// Initialize a PdfDocument
var pdfAppend = new PdfDocument(200, 200);
// Create a text annotation to add to each PDF
TextAnnotation annotation = new TextAnnotation(0)
{
Contents = "Processed by IronPDF",
X = 50,
Y = 50,
};
// Iterate over each file path, load, annotate, and save
foreach (string file in pdfFiles)
{
var pdf = PdfDocument.FromFile(file);
pdf.Annotations.Add(annotation);
pdf.SaveAs(file);
}
}
}Imports IronPdf
Imports System
Imports System.IO
Friend Class Program
Shared Sub Main()
' Retrieve all PDF file paths from the specified directory
Dim pdfFiles() As String = Directory.GetFiles("C:\Users\kyess\Documents\PDFs", "*.pdf")
' Initialize a PdfDocument
Dim pdfAppend = New PdfDocument(200, 200)
' Create a text annotation to add to each PDF
Dim annotation As New TextAnnotation(0) With {
.Contents = "Processed by IronPDF",
.X = 50,
.Y = 50
}
' Iterate over each file path, load, annotate, and save
For Each file As String In pdfFiles
Dim pdf = PdfDocument.FromFile(file)
pdf.Annotations.Add(annotation)
pdf.SaveAs(file)
Next file
End Sub
End ClassWynik konsoli
Wyjaśnienie
Ten kod pokazuje, jak dodać adnotację tekstową do wszystkich plików PDF w określonym katalogu za pomocą IronPDF w C#. Program zaczyna od pobrania wszystkich ścieżek plików PDF z podanego folderu za pomocą metody Directory.GetFiles, która opiera się na łańcuchu znaków do określenia katalogu i wspiera filtrowanie po rozszerzeniu pliku, zwracając tablicę nazw plików zawierającą ścieżki wszystkich plików PDF z rozszerzeniem ".pdf".
Następnie kod inicjuje obiekt PdfDocument (pdfAppend) o wymiarach 200x200, choć konkretny egzemplarz nie jest używany bezpośrednio w pętli. Następnie tworzy TextAnnotation z tekstem "Przetworzone przez IronPDF" umieszczonym na współrzędnych (50, 50). Ta adnotacja zostanie dodana do każdego pliku PDF.
W pętli foreach program przechodzi przez każdą ścieżkę pliku w tablicy pdfFiles. Dla każdego pliku ładujemy PDF za pomocą PdfDocument.FromFile(file), dodajemy poprzednio utworzoną adnotację do kolekcji adnotacji pliku PDF, po czym zapisujemy zaktualizowany PDF z powrotem do jego ścieżki bezwzględnej za pomocą pdf.SaveAs(file).
Ten proces zapewnia, że każdy PDF w określonym katalogu otrzymuje tę samą adnotację i jest zapisany z tą adnotacją.
Wskazówki dotyczące wydajności i najlepsze praktyki
Optymalizacja pobierania plików za pomocą Directory.GetFiles
Używaj metod asynchronicznych, takich jak Directory.EnumerateFiles, aby uzyskać lepszą wydajność dla dużych katalogów.
Skuteczne zarządzanie dużą liczbą plików
Przetwarzaj pliki w mniejszych partiach, aby zmniejszyć zużycie pamięci:
foreach (var batch in pdfFiles.Batch(10))
{
foreach (string file in batch)
{
var pdf = PdfDocument.FromFile(file);
// Process PDF
}
}foreach (var batch in pdfFiles.Batch(10))
{
foreach (string file in batch)
{
var pdf = PdfDocument.FromFile(file);
// Process PDF
}
}For Each batch In pdfFiles.Batch(10)
For Each file As String In batch
Dim pdf = PdfDocument.FromFile(file)
' Process PDF
Next file
Next batchObsługa błędów w przetwarzaniu plików i generowaniu PDF
Umieść przetwarzanie plików w bloku try-catch, aby obsługiwać wyjątki:
try
{
var pdf = PdfDocument.FromFile(file);
// Process PDF
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {file}: {ex.Message}");
}try
{
var pdf = PdfDocument.FromFile(file);
// Process PDF
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {file}: {ex.Message}");
}Try
Dim pdf = PdfDocument.FromFile(file)
' Process PDF
Catch ex As Exception
Console.WriteLine($"Error processing {file}: {ex.Message}")
End TryWnioski
Łączenie mocy Directory.GetFiles z IronPDF pozwala deweloperom na skuteczne zarządzanie i przetwarzanie plików PDF na dużą skalę. Dzięki temu podejściu takie zadania jak przetwarzanie grupowe, scalanie, filtrowanie i przekształcanie plików PDF stają się bezproblemowe, znacząco zmniejszając wysiłek manualny i poprawiając wydajność. Dzięki zaawansowanym możliwościom IronPDF, w tym dodawaniu nagłówków, metadanych i stylizacji, deweloperzy mogą tworzyć wysokiej jakości, profesjonalne dokumenty PDF dostosowane do swoich wymagań.
W całym tym przewodniku zbadaliśmy, jak używać Directory.GetFiles do pobierania i manipulacji PDF przy pomocy IronPDF. Od konfigurowania projektu po implementację praktycznych przypadków użycia, omówiliśmy kluczowe techniki, które można zastosować w rzeczywistych scenariuszach. Niezależnie od tego, czy pracujesz nad automatyzacją przepływów dokumentów, czy ulepszaniem funkcji swoich aplikacji .NET, to połączenie zapewnia solidne i skalowalne rozwiązanie.
Jeśli jesteś gotowy, aby zagłębić się w IronPDF i odkryć zaawansowane funkcje, rozważ odwiedzenie oficjalnej dokumentacji, co pozwoli Ci przetestować bibliotekę w swoich własnych projektach.
Często Zadawane Pytania
Jak działa metoda Directory.GetFiles w języku C#?
Metoda Directory.GetFiles w języku C# jest częścią przestrzeni nazw System.IO, która pozwala programistom pobierać ścieżki plików z określonego katalogu. Obsługuje wzorce wyszukiwania i opcje uwzględniania podkatalogów, dzięki czemu jest wydajna w przypadku uzyskiwania dostępu do określonych typów lub nazw plików.
Jak mogę użyć języka C# do automatyzacji przetwarzania plików PDF?
Możesz zautomatyzować przetwarzanie plików PDF w języku C#, używając biblioteki IronPDF wraz z metodą Directory.GetFiles. Pozwala to na lokalizowanie plików PDF w katalogu i automatyczne wykonywanie zadań, takich jak scałanie, dodawanie adnotacji lub generowanie raportów.
Jakie są zalety połączenia Directory.GetFiles z biblioteką PDF?
Połączenie funkcji Directory.GetFiles z biblioteką PDF, taką jak IronPDF, pozwala na zautomatyzowane i wydajne zarządzanie dokumentami PDF. Można pobierać i przetwarzać pliki PDF zbiorczo, wprowadzać modyfikacje oraz konsolidować pliki, zwiększając produktywność i ograniczając pracę ręczną.
Jak dołączyć wiele plików PDF do jednego dokumentu za pomocą języka C#?
Aby dołączyć wiele plików PDF do jednego dokumentu, użyj metody Directory.GetFiles, aby pobrać wszystkie pliki PDF z katalogu. Następnie załaduj każdy plik PDF za pomocą IronPDF i dołącz je do jednego obiektu PdfDocument, który można zapisać jako skonsolidowany plik PDF.
Jak w języku C# filtrować pliki w katalogu według daty utworzenia?
Możesz filtrować pliki w katalogu według daty utworzenia, używając LINQ z Directory.GetFiles. Na przykład, aby wybrać pliki utworzone w ciągu ostatniego tygodnia, użyj: var recentFiles = pdfFiles.Where(file => File.GetCreationTime(file) > DateTime.Now.AddDays(-7));
Jaka jest najlepsza praktyka przetwarzania dużej liczby plików w języku C#?
W celu przetwarzania dużej liczby plików należy stosować metody asynchroniczne, takie jak Directory.EnumerateFiles, aby poprawić wydajność poprzez skrócenie czasu pobierania. Jest to szczególnie przydatne przy efektywnej obsłudze dużych katalogów.
Jak radzić sobie z błędami podczas przetwarzania plików PDF w języku C#?
Obsługuj błędy podczas przetwarzania plików PDF, otaczając operacje blokiem try-catch. Zapewnia to płynne zarządzanie wyjątkami, umożliwiając aplikacji dalsze działanie bez awarii spowodowanej nieoczekiwanymi błędami.
Jaki jest przykład przetwarzania wsadowego z wykorzystaniem biblioteki PDF w języku C#?
Przykładem przetwarzania wsadowego jest użycie funkcji Directory.GetFiles do pobrania plików PDF, a następnie wykorzystanie biblioteki IronPDF do ich zbiorczego scałania lub dodawania adnotacji. Takie podejście automatyzuje powtarzalne zadania, oszczędzając czas i wysiłek.
Jak mogę dodawać adnotacje tekstowe do plików PDF za pomocą biblioteki .NET?
Aby dodać adnotacje tekstowe do plików PDF za pomocą IronPDF, należy utworzyć obiekt TextAnnotation z określoną treścią i położeniem. Następnie należy załadować każdy plik PDF, dodać adnotację do jego kolekcji Annotations i zapisać zaktualizowany dokument.
Jakie kroki należy wykonać, aby zainstalować bibliotekę PDF za pośrednictwem NuGet w Visual Studio?
Aby zainstalować bibliotekę PDF za pośrednictwem NuGet w Visual Studio, otwórz projekt, przejdź do menu Narzędzia > Menedżer pakietów NuGet > Zarządzaj pakietami NuGet dla rozwiązania, wyszukaj IronPDF i zainstaluj go. Alternatywnie możesz użyć konsoli menedżera pakietów NuGet, wpisując polecenie: Install-Package IronPdf.














