
Jak wyodrębnić strony z plików PDF — przewodnik krok po kroku
Jeśli pracujesz z plikami PDF, prawdopodobnie często będziesz musiał wyodrębniać strony. Na szczęście istnieje szeroki wybór narzędzi, które mogą pomóc w realizacji tego zadania. Użytkownicy wyodrębniają strony PDF z różnych powodów. Oto trzy najpopularniejsze z nich:
Potrzebujesz tylko wybranych stron — jeśli masz duży dokument, a potrzebujesz tylko określonych stron do prezentacji, przesłania lub z jakiegokolwiek innego powodu, będziesz chciał wyodrębnić strony z pliku PDF.
Zmiana kolejności stron w pliku PDF — Możesz odłączyć strony i zmienić ich położenie w dokumencie, jeśli chcesz zmienić numery stron i przenieść niektóre części do nowej sekcji.
Konwersja stron PDF — zamiast konwertować cały plik, możesz wyodrębnić strony PDF, aby oddzielić i przekonwertować konkretną część dokumentu.
Ekstrakcja to proces kopiowania i wklejania wybranych stron z jednego pliku PDF do innego. Treść wyodrębnionych stron obejmuje wszystkie pola formularzy, komentarze i linki do oryginalnej treści strony.
Możesz pozostawić wyodrębnione strony w oryginalnym dokumencie lub usunąć je podczas procesu wyodrębniania, co przypomina wycinanie i wklejanie lub kopiowanie i wklejanie, ale tym razem w skali całych stron.
Jak wyodrębnić strony z plików PDF w programie Adobe Acrobat
Funkcja "Wyodrębnij strony" w programie Adobe Acrobat™ ułatwia podzielenie pliku PDF na dwa lub więcej oddzielnych plików PDF. Strony z istniejącego dokumentu PDF można wyodrębnić i wykorzystać jako podstawę dla jednego nowego dokumentu PDF lub wielu wersji. Podczas wyodrębniania stron masz możliwość zachowania oryginalnych wersji w dokumencie lub ich usunięcia.
Make sure you have the authorization to edit the PDF before manipulating its pages. To determine this, go to File > Properties, then to the Security tab. Permissions are listed in the "Summary of Document Restrictions".
With Adobe Acrobat DC, extracting a single or numerous pages from a PDF file is a breeze (if you use another product, chances are the steps are similar). The methods are basic, but they can be a little confusing for first-time users. Here's everything you need to know:
Step 1
Choose Tools > Organize Pages or Organize Pages from the right pane after opening the PDF in Acrobat DC.
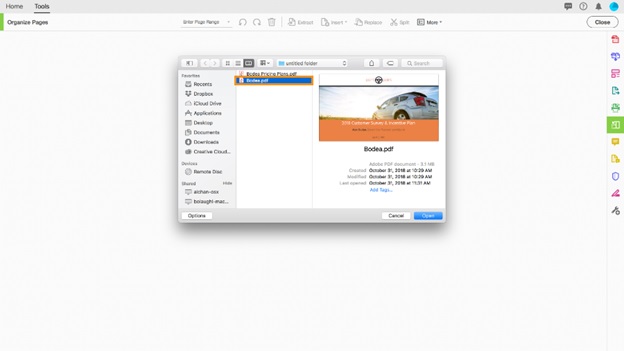
Extract pages from a PDF file step 3, open a PDF
In the secondary toolbar, you'll find the "Organize Pages" toolset.
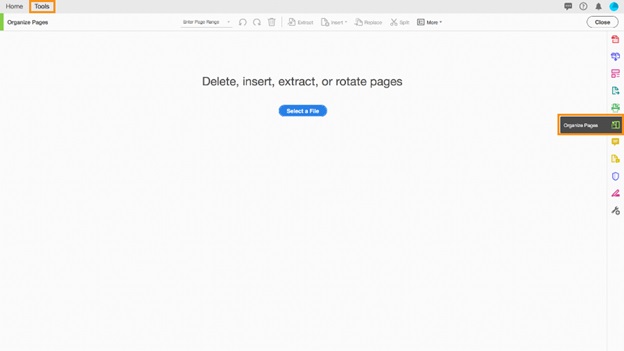
Extract pages from a PDF file step 1, open the Organize Pages tool
Krok 2
Click "Extract" on the secondary toolbar.
Below the secondary toolbar, a new toolbar opens with commands relevant to the Extract operation.
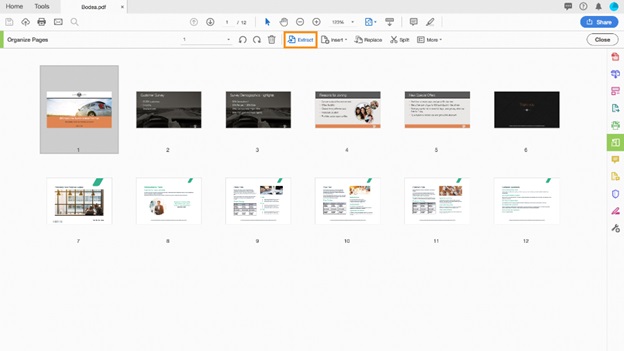
Extract pages from a PDF file step 4, select Extract in the top menu
Krok 3
You can choose a single page or a group of pages to extract:
- Click on the first page you want to extract, then hold the Shift key (Windows and Mac) and click on the last page you want to extract to highlight the set.
- Click a page to extract, then hold the Ctrl key (Windows) or the Cmd key (Mac) while clicking each additional page you want to extract into a new PDF document.
If you want to remove the pages from the original PDF after extraction, click the "Delete Pages after Extracting" checkbox. To extract each highlighted page as a distinct PDF file, tick the "Extract pages as independent files" checkbox.
Extract pages from a PDF file step 5, highlight pages
Step 4
Perform one or more of the following actions in the new toolbar before clicking "Extract":
- Select "Delete Pages" After extracting to remove the extracted pages from the source document.
- Select "Extract Pages As Separate Files" to create a single-page PDF for each extracted page.
- Leave both checkboxes deselected to keep the original pages in the document and create a single PDF with all of the extracted pages.
The pages that were extracted are pasted into a new document.
Step 5
Choose File > Save or File > Save As when the PDF of the extracted pages opens in a new tab, and then specify a file name and location for the new PDF file.
Using Websites and Online Tools to Extract Pages from PDF Files and Create New PDF Files
There are numerous methods for extracting PDF pages. You can use online website services to extract or split PDF files.
These websites are cross-platform online services that you can use anywhere if you have a laptop, desktop, or mobile device such as an iPad, tablet, or smartphone. The websites are browser-based, and thus they work well on all devices and in a variety of browsers, including Chrome, Firefox, Safari, Opera, and others. The best three platforms are shown below.
On a Windows laptop, desktop, or smartphone, open your chosen browser and visit any PDF extraction website to start extracting, converting, merging, and splitting PDF files. All Windows devices with internet connectivity can visit the site.
Mac — Mac desktops and laptops, like Windows, are fully compatible with these websites. Simply open your browser, go to any of the split PDF websites, choose a tool, upload your file, finish the extraction, and save your new PDF file.
Online PDF converters and other PDF tools for Android and iOS smartphones, tablets, and iPads are tailored for use on Android and iOS devices. You may also use the browser on your Blackberry or any other smartphone with an internet connection.
Most of these websites come with free tools that allow you to create your own file.
Here is a quick guide on how to use online PDF platforms.
Step 1
Go to your browser and type "online PDF extraction tool".
Krok 2
Select any of the PDF platforms.
Krok 3
Launch the "Extraction Tool" on the website. You can choose the PDF extract option from the All Tools menu or from the homepage list. You will be taken to a new page where you can finish extracting pages from your PDF file.
Step 4
Upload a PDF File — on the new screen that appears, click "Choose File" and select a PDF file from your computer or mobile device. You may also directly drag & drop files onto the upload area.
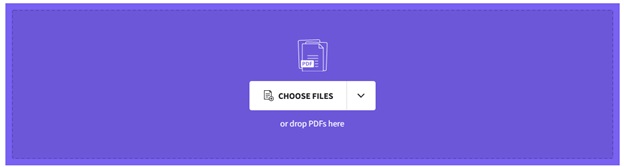
Step 5
The website will then create PDF thumbnails of the document. Next, select the pages that you wish to extract from the PDF, then click "extract pdf pages". It will only take a few seconds for the procedure to complete.
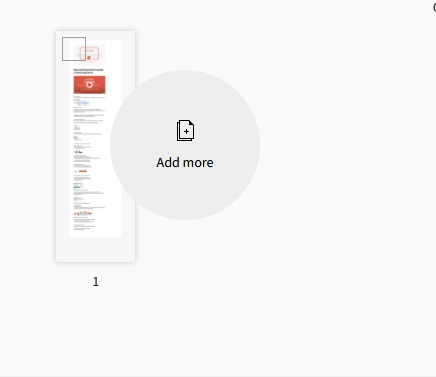
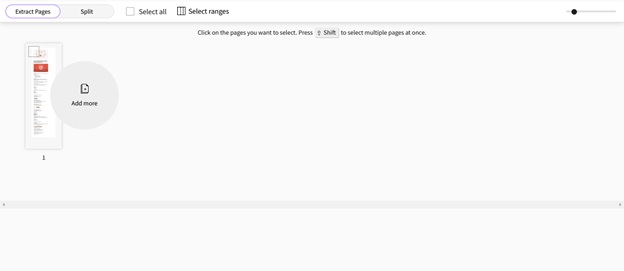
Step 6
The selected pages from the PDF will then be added to a new PDF file which you can download. The extracted pages are organized in order of their page numbers, without any distortion.
How to Extract Pages from a PDF Document Using the IronPDF C# Library
IronPDF by Iron Software is the most effective and innovative way to deal with all PDF-related problems in C#. It provides many PDF-related functions, including page extraction from PDF files. IronPDF is your go-to option if you are looking for the simplest means of performing this task. With just a few lines of code, you can convert a multi-page PDF document into a single PDF. Take a look at our example to see how you may use it in your own project.
IronPDF licensing keys enable you to publish your product without the need for a watermark.
The price of a license starts at $799 and includes one year of free support and upgrades.
With a trial license key, you may also try IronPDF for free.
Splitting a single PDF document into numerous documents is a breeze with IronPDF. Each document is simply one page long.
We can split PDF documents with IronPDF by extracting single pages or page ranges into the new IronPdf.PdfDocument objects.
// Import the necessary namespaces
using IronPdf;
class Program
{
static void Main()
{
// Load the PDF document from a file
var pdfDocument = PdfDocument.FromFile("example.pdf");
// Extract a specific page (for example, page 1)
var extractedPage = pdfDocument.ExtractPage(1);
// Save the extracted page as a new PDF file
extractedPage.SaveAs("extractedPage.pdf");
// To extract a range of pages, use ExtractPages(start, end)
var extractedPages = pdfDocument.ExtractPages(1, 3);
// Save the extracted pages as a new PDF file
extractedPages.SaveAs("extractedPages.pdf");
}
}// Import the necessary namespaces
using IronPdf;
class Program
{
static void Main()
{
// Load the PDF document from a file
var pdfDocument = PdfDocument.FromFile("example.pdf");
// Extract a specific page (for example, page 1)
var extractedPage = pdfDocument.ExtractPage(1);
// Save the extracted page as a new PDF file
extractedPage.SaveAs("extractedPage.pdf");
// To extract a range of pages, use ExtractPages(start, end)
var extractedPages = pdfDocument.ExtractPages(1, 3);
// Save the extracted pages as a new PDF file
extractedPages.SaveAs("extractedPages.pdf");
}
}' Import the necessary namespaces
Imports IronPdf
Friend Class Program
Shared Sub Main()
' Load the PDF document from a file
Dim pdfDocument = PdfDocument.FromFile("example.pdf")
' Extract a specific page (for example, page 1)
Dim extractedPage = pdfDocument.ExtractPage(1)
' Save the extracted page as a new PDF file
extractedPage.SaveAs("extractedPage.pdf")
' To extract a range of pages, use ExtractPages(start, end)
Dim extractedPages = pdfDocument.ExtractPages(1, 3)
' Save the extracted pages as a new PDF file
extractedPages.SaveAs("extractedPages.pdf")
End Sub
End ClassThis C# code illustrates how to use IronPDF to extract single or multiple pages from an existing PDF document. The ExtractPage method is used to get a particular page, while ExtractPages can handle a range of pages. After extraction, you can save the pages into new PDF files.
IronPdf.PdfDocument is the C#.NET API.
CopyPage is a program that extracts pages from one or more PDF files and pastes them into a new document.














