
PDFファイルからページを抽出する方法—ステップバイステップガイド
PDFファイルを扱う場合、ページを抽出する必要が多くあります。 幸いなことに、この作業を支援するためのさまざまなツールがあります。 人々はさまざまな理由でPDFページを抽出します。 ここに最も人気のある3つの理由があります。
選択したページのみが必要です — 大きなドキュメントがあり、特定のプレゼンテーション、アップロード、または他の理由のために特定のページが必要な場合、PDFからページを抽出したいでしょう。
PDFページの再配置 — ページ番号を変更し、パーツを新しいセクションに移動したい場合は、ページを分離してドキュメント内で再配置できます。
PDFページの変換 — 完全なファイルを変換する代わりに、ドキュメントの特定のセクションを分離して変換するためにPDFページを抽出することを希望するかもしれません。
抽出は、選択したページを1つのPDFから別のPDFにコピーして貼り付けるプロセスです。 抽出したページの内容には、すべてのフォームフィールド、コメント、および元のページ内容へのリンクが含まれます。
抽出したページを元のドキュメントに残すか、抽出プロセス中に削除するかを選択できますが、これは切り取りと貼り付け、またはコピーと貼り付けに似ていますが、今回はページ全体のスケールで行います。
Adobe AcrobatでPDFからページを抽出する方法
Adobe Acrobat™の"ページを抽出"機能を使用すると、PDFファイルを2つ以上の別個のPDFファイルに分割するのが簡単です。 既存のPDFドキュメントからページを抽出して、新しいPDFドキュメントの基礎として使用することができます。 ページを抽出するときに、元のバージョンをドキュメントに残すか削除するかを選択できます。
PDFのページを操作する前に、編集できる権限があることを確認してください。 そのためには、ファイル > プロパティに行き、セキュリティタブに移動します。 許可は"ドキュメント制限の要約"に記載されています。
Adobe Acrobat DCを使用すると、PDFファイルから1ページまたは多くのページを抽出するのは簡単です(別の製品を使用している場合、手順は似ている可能性があります)。 方法は基本ですが、初めてのユーザーには少し混乱しやすいかもしれません。 以下は知っておくべき情報です。
ステップ1
PDFをAcrobat DCで開いたら、右側のペインからツール > ページを整理、またはページを整理を選択します。
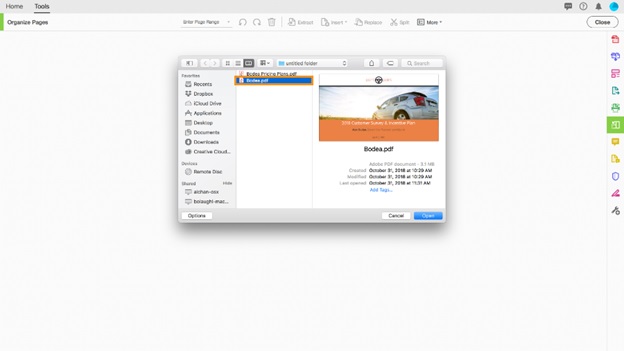
PDFファイルからページを抽出する ステップ3、PDFを開く
セカンダリツールバーに"ページを整理"ツールセットがあります。
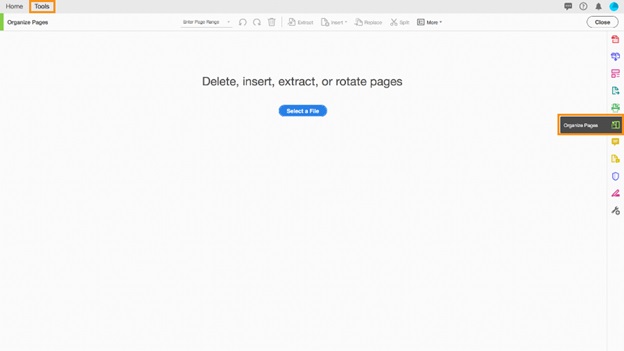
PDFファイルからページを抽出する ステップ1、Organize Pagesツールを開く
ステップ2
セカンダリツールバーの"抽出"をクリックします。
セカンダリツールバーの下に、新しいツールバーが開き、抽出操作に関連するコマンドが表示されます。
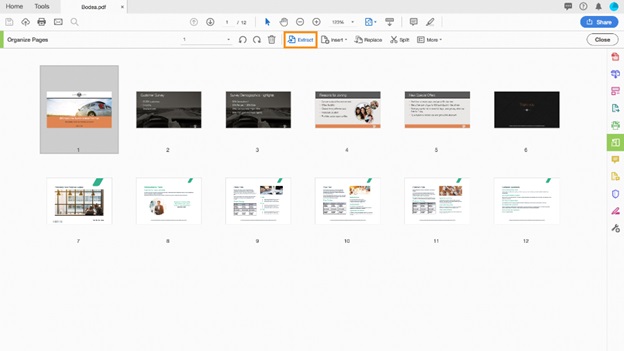
PDFファイルからページを抽出する ステップ4、上部メニューで"抽出"を選択します。
ステップ3
抽出する単一ページまたはグループのページを選択できます。
- 抽出したい最初のページをクリックした後、Shiftキーを押しながら(WindowsとMac)抽出したい最後のページをクリックしてセットをハイライトします。
- 抽出したいページをクリックし、その後Ctrlキー(Windows)またはCmdキー(Mac)を押しながら、新しいPDFドキュメントに抽出する各追加ページをクリックします。
抽出後に元のPDFからページを削除したい場合は、"抽出後にページを削除"のチェックボックスをクリックします。 ハイライトした各ページを別個のPDFファイルとして抽出するには、"ページを独立したファイルとして抽出"のチェックボックスにチェックを入れます。
PDFファイルからページを抽出する ステップ5、ページをハイライトする
ステップ4
"抽出"をクリックする前に、新しいツールバーで次の1つまたは複数の操作を行います。
- 抽出後に"ページを削除"を選択し、ソースドキュメントから抽出したページを削除します。
- "ページを別々のファイルとして抽出"を選択し、各抽出したページのシングルページPDFを作成します。
- どちらのチェックボックスも選択しない状態にして、元のページをドキュメントに保持し、抽出したすべてのページを1つのPDFにします。
抽出されたページは新しいドキュメントに貼り付けられます。
ステップ5
新しいタブで抽出したページのPDFが開いたら、ファイル > 名前を付けて保存を選択し、新しいPDFファイルのファイル名と保存場所を指定します。
ウェブサイトとオンラインツールを使用してPDFファイルからページを抽出し、新しいPDFファイルを作成します
PDFページを抽出する方法は多数あります。 オンラインのウェブサイトサービスを使用してPDFファイルを抽出または分割できます。
これらのウェブサイトはクロスプラットフォームのオンラインサービスであり、ノートパソコン、デスクトップ、またはiPad、タブレット、スマートフォンなどのモバイルデバイスを所有している限り、どこからでも使用できます。 これらのウェブサイトはブラウザベースであるため、すべてのデバイスと、Chrome、Firefox、Safari、Operaなどのさまざまなブラウザでうまく動作します。 以下に最も優れた3つのプラットフォームを示します。
Windowsのノートパソコン、デスクトップ、またはスマートフォンで選択したブラウザを開き、任意のPDF抽出ウェブサイトにアクセスして抽出、変換、結合、PDFファイルの分割を始めます。 インターネット接続があるすべてのWindowsデバイスはサイトを訪れることができます。
Mac — MacデスクトップとノートパソコンもWindowsと同様にこれらのウェブサイトに完全に対応しています。 単にブラウザを開き、任意の分割PDFウェブサイトにアクセスし、ツールを選択、ファイルをアップロード、抽出を終了し、新しいPDFファイルを保存します。
オンラインPDFコンバーターと、AndroidおよびiOSのスマートフォン、タブレット、iPad向けの他のPDFツールは、AndroidおよびiOSデバイスで使用するように調整されています。 また、インターネット接続があるBlackberryまたは他のスマートフォンのブラウザを使用することもできます。
ほとんどのこれらのウェブサイトには、独自のファイルを作成できる無料のツールが付属しています。
オンラインPDFプラットフォームの使い方について簡単なガイドを紹介します。
ステップ1
ブラウザに"オンラインPDF抽出ツール"と入力します。
ステップ2
任意のPDFプラットフォームを選択します。
ステップ3
ウェブサイトで"抽出ツール"を起動します。すべてのツールメニューまたはホームページのリストからPDF抽出オプションを選択できます。新しいページに移動し、PDFファイルからページを抽出することができます。
ステップ4
PDFファイルをアップロード — 表示される新しい画面で"ファイルを選択"をクリックし、コンピュータまたはモバイルデバイスからPDFファイルを選択します。また、アップロード領域にファイルを直接ドラッグ&ドロップすることもできます。
ステップ5
ウェブサイトはドキュメントのPDFサムネイルを作成します。 次に、PDFから抽出したいページを選択し、"PDFページを抽出"をクリックします。 手続きが完了するまでに数秒しかかかりません。
ステップ6
選択したPDFのページが新しいPDFファイルに追加され、ダウンロードできます。 抽出されたページはページ番号の順序で整理され、歪みはありません。
IronPDF C#ライブラリを使用してPDFドキュメントからページを抽出する方法
Iron SoftwareのIronPDFは、C#におけるあらゆるPDF関連の問題を解決するための最も効果的で革新的な方法です。PDFファイルからのページ抽出を含む多くのPDF関連機能を提供します。 このタスクを最も簡単に実行する手段を探しているなら、IronPDFが最適です。 ほんの数行のコードで、複数ページのPDFドキュメントを一つのPDFに変換することができます。 自分のプロジェクトでどのように使用するか、例を見てみましょう。
IronPDFライセンスキーを使用すると、透かしなしで製品を公開できます。
ライセンスの価格は$999からで、1年間の無料サポートとアップグレードが含まれています。
トライアルライセンスキーでIronPDFを無料で試すことも可能です。
IronPDFを使用すると、1つのPDFドキュメントを複数のドキュメントに分割するのが簡単です。 各ドキュメントは単一ページのみです。
IronPDFを使用すると、単一ページまたはページ範囲を新しい IronPdf.PdfDocument オブジェクトに抽出することで、PDF ドキュメントを分割できます。
// Import the necessary namespaces
using IronPdf;
class Program
{
static void Main()
{
// Load the PDF document from a file
var pdfDocument = PdfDocument.FromFile("example.pdf");
// Extract a specific page (for example, page 1)
var extractedPage = pdfDocument.ExtractPage(1);
// Save the extracted page as a new PDF file
extractedPage.SaveAs("extractedPage.pdf");
// To extract a range of pages, use ExtractPages(start, end)
var extractedPages = pdfDocument.ExtractPages(1, 3);
// Save the extracted pages as a new PDF file
extractedPages.SaveAs("extractedPages.pdf");
}
}// Import the necessary namespaces
using IronPdf;
class Program
{
static void Main()
{
// Load the PDF document from a file
var pdfDocument = PdfDocument.FromFile("example.pdf");
// Extract a specific page (for example, page 1)
var extractedPage = pdfDocument.ExtractPage(1);
// Save the extracted page as a new PDF file
extractedPage.SaveAs("extractedPage.pdf");
// To extract a range of pages, use ExtractPages(start, end)
var extractedPages = pdfDocument.ExtractPages(1, 3);
// Save the extracted pages as a new PDF file
extractedPages.SaveAs("extractedPages.pdf");
}
}' Import the necessary namespaces
Imports IronPdf
Friend Class Program
Shared Sub Main()
' Load the PDF document from a file
Dim pdfDocument = PdfDocument.FromFile("example.pdf")
' Extract a specific page (for example, page 1)
Dim extractedPage = pdfDocument.ExtractPage(1)
' Save the extracted page as a new PDF file
extractedPage.SaveAs("extractedPage.pdf")
' To extract a range of pages, use ExtractPages(start, end)
Dim extractedPages = pdfDocument.ExtractPages(1, 3)
' Save the extracted pages as a new PDF file
extractedPages.SaveAs("extractedPages.pdf")
End Sub
End ClassこのC#コードは、IronPDFを使用して既存のPDFドキュメントから単一または複数のページを抽出する方法を示しています。 ExtractPage メソッドは特定のページを取得するために使用され、ExtractPages メソッドはページの範囲を処理できます。 抽出後、ページを新しいPDFファイルに保存することができます。
IronPdf.PdfDocumentはC#.NET APIです。
CopyPage は、1つまたは複数のPDFファイルからページを抽出し、新しいドキュメントに貼り付けるプログラムです。














