PDF 파일에서 페이지를 추출하는 방법 — 단계별 가이드
PDF 파일을 작업하면 페이지 추출이 자주 필요할 때가 있을 것입니다. 다행히 이 작업을 지원하는 다양한 도구가 있습니다. 사람들은 다양한 이유로 PDF 페이지를 추출합니다. 다음은 가장 인기 있는 세 가지입니다:
선택된 페이지만 필요할 때 — 대형 문서가 있고 프레젠테이션, 업로드, 기타 이유로 특정 페이지만 필요한 경우, PDF에서 페이지를 추출하고 싶을 것입니다.
PDF 페이지 재배치 — 페이지를 분리하고 문서 내에서 위치를 조정하여 페이지 번호를 변경하거나 일부 부분을 새 섹션으로 이동할 수 있습니다.
PDF 페이지 변환 — 전체 파일을 변환하는 대신, 문서의 특정 섹션을 분리하고 변환하기 위해 PDF 페이지를 추출할 수 있습니다.
추출은 한 PDF에서 선택된 페이지를 다른 PDF로 복사하여 붙여넣는 과정입니다. 추출된 페이지의 콘텐츠에는 모든 폼 필드, 댓글, 원본 페이지 콘텐츠에 대한 링크가 포함됩니다.
추출한 페이지를 원본 문서에 남겨 두거나 제거할 수 있으며, 이는 페이지 전체를 대상으로 하는 잘라내기 및 붙여넣기 또는 복사 및 붙여넣기와 유사합니다.
Adobe Acrobat에서 PDF에서 페이지를 추출하는 방법
Adobe Acrobat™의 페이지 추출 기능은 PDF 파일을 두 개 이상의 개별 PDF 파일로 나누는 것을 쉽게 해줍니다. 기존 PDF 문서의 페이지를 추출하여 단일 새 PDF 문서 또는 여러 버전의 기반으로 사용할 수 있습니다. 페이지를 추출할 때, 문서에서 원본 버전을 유지하거나 삭제할 수 있는 옵션이 있습니다.
PDF를 편집하기 전에 페이지를 조작하기 위한 권한이 있는지 확인하십시오. 이를 확인하려면 파일 > 속성으로 이동한 다음 보안 탭으로 이동하십시오. "문서 제한 요약"에 권한이 나열됩니다.
Adobe Acrobat DC를 사용하면 PDF 파일에서 한 개 또는 여러 페이지를 추출하는 것이 매우 쉽습니다(다른 제품을 사용하는 경우, 절차는 비슷할 가능성이 있습니다). 방법은 기본적이지만 처음 사용하는 사용자에게는 약간 혼란스러울 수 있습니다. 다음은 알아야 할 모든 것입니다:
1단계
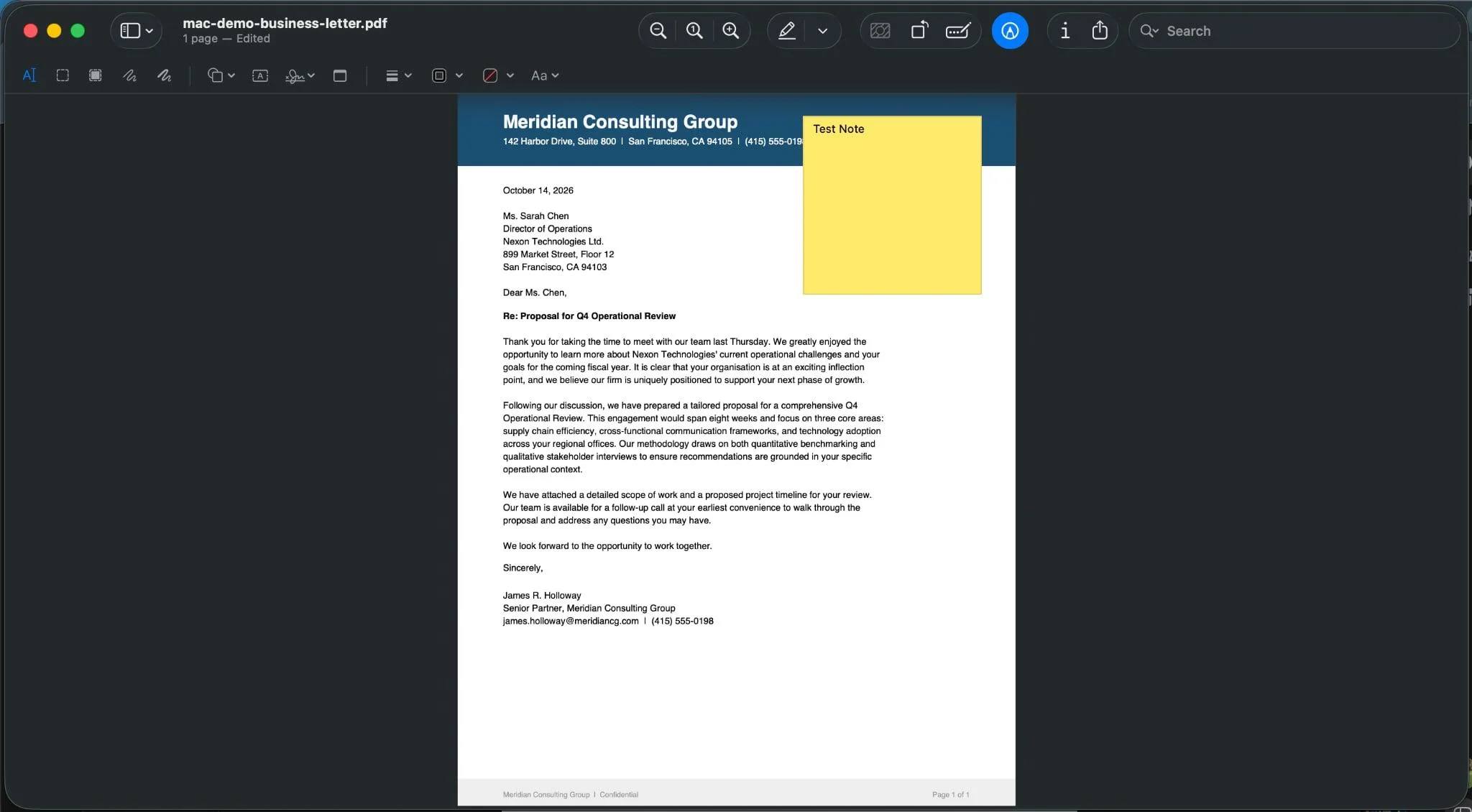
도구 > 페이지 정리 또는 Acrobat DC에서 PDF를 연 후 오른쪽 창에서 페이지 정리를 선택하십시오.
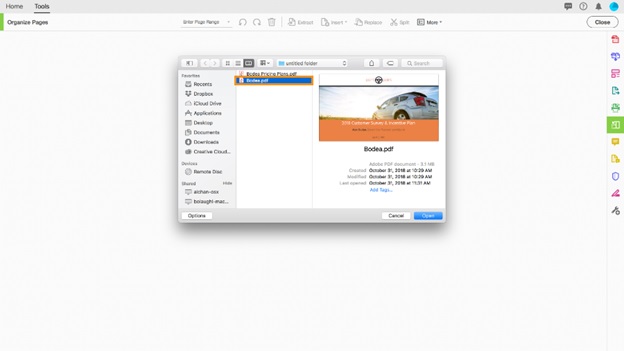
단계 3에서 PDF 파일에서 페이지를 추출하고, PDF를 엽니다
보조 도구 모음에서 "페이지 정리" 툴셋을 찾을 수 있습니다.
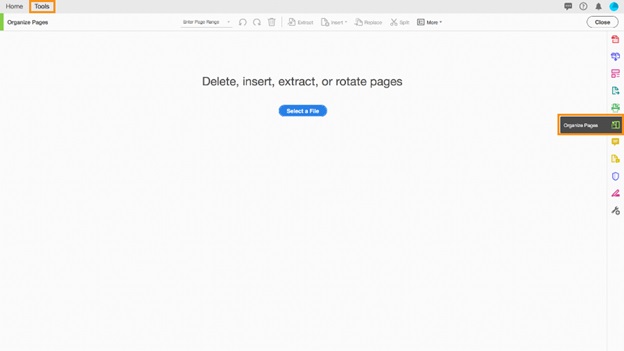
PDF 파일에서 페이지 추출 1단계, 페이지 정리 도구 열기
2단계
보조 도구 모음에서 "추출"을 클릭하십시오.
보조 도구 모음 아래에 추출 작업에 관련된 명령이 있는 새로운 도구 모음이 열립니다.
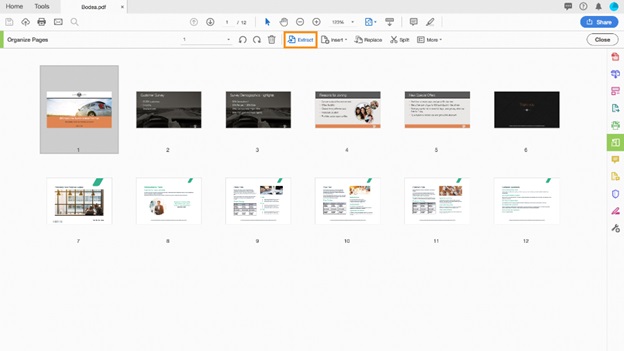
PDF 파일에서 페이지 추출 4단계, 상단 메뉴에서 추출 선택
3단계
단일 페이지 또는 그룹의 페이지를 선택하여 추출할 수 있습니다:
- 추출하려는 첫 번째 페이지를 클릭한 다음, Shift 키(Windows 및 Mac)를 누르고 마우스를 클릭하여 선택한 세트를 강조 표시하려는 마지막 페이지를 클릭하십시오.
- 추출하려는 페이지를 클릭한 다음, Windows에서는 Ctrl 키를, Mac에서는 Cmd 키를 누르고 추가로 추출하려는 각 페이지를 클릭하여 새로운 PDF 문서로 만드십시오.
추출 뒤 원본 PDF에서 페이지를 제거하고 싶다면 "추출 후 페이지 삭제" 체크박스를 클릭하십시오. 각 강조 표시된 페이지를 개별적인 PDF 파일로 추출하려면 "파일을 독립적인 파일로 추출" 체크박스를 선택하십시오.
PDF 파일에서 페이지 추출 5단계, 페이지 강조
4단계
"추출"을 클릭하기 전에 새로운 도구 모음에서 다음 작업 중 하나 또는 그 이상을 수행하십시오:
- 추출한 후 소스 문서에서 추출된 페이지를 제거하려면 "페이지 삭제"를 선택하십시오.
- 추출한 각 페이지를 하나의 단일 페이지 PDF로 생성하려면 "페이지를 독립적인 파일로 추출"을 선택하십시오.
- 두 개의 체크박스를 모두 선택 해제하여 문서에 원본 페이지를 그대로 두고 추출된 모든 페이지로 단일 PDF를 생성하십시오.
추출된 페이지가 새로운 문서에 붙여넣어집니다.
5단계
새 탭에서 추출된 페이지의 PDF가 열리면 파일을 선택하고 저장 또는 저장 옵션을 선택한 다음 새 PDF 파일의 파일 이름과 위치를 지정하십시오.
웹사이트 및 온라인 도구를 사용하여 PDF 파일에서 페이지를 추출하고 새로운 PDF 파일 생성
PDF 페이지를 추출하는 방법은 다양합니다. 온라인 웹사이트 서비스를 사용하여 PDF 파일을 추출하거나 나눌 수 있습니다.
이 웹사이트는 크로스 플랫폼 온라인 서비스로, 랩톱, 데스크탑, iPad, 태블릿, 스마트폰 같은 모바일 장치가 있다면 어디서나 사용할 수 있습니다. 웹사이트는 브라우저 기반이므로 Chrome, Firefox, Safari, Opera 등 다양한 브라우저와 장치에서 잘 작동합니다. 다음은 최고의 세 플랫폼입니다.
Windows 노트북, 데스크탑 또는 스마트폰에서 선택한 브라우저를 열고 선택한 PDF 추출 웹사이트에 방문하여 PDF 파일을 추출, 변환, 병합 및 분할하십시오. 인터넷 연결이 있는 모든 Windows 장치는 사이트에 방문할 수 있습니다.
Mac — Windows처럼 Mac 데스크탑과 노트북도 이 웹사이트와 완전히 호환됩니다. 간단히 브라우저를 열고, PDF 분할 웹사이트에 가서 도구를 선택하고, 파일을 업로드하여 추출을 마친 후 새 PDF 파일을 저장하십시오.
Android 및 iOS 스마트폰, 태블릿, iPad용 온라인 PDF 변환기와 기타 PDF 도구는 Android 및 iOS 장치에서 사용하도록 최적화되어 있습니다. 또한 브라우저를 사용하여 Blackberry 또는 인터넷 연결이 되는 다른 스마트폰에서 사용할 수 있습니다.
대부분의 이러한 웹사이트는 자체 파일을 만들 수 있는 무료 도구를 제공합니다.
다음은 온라인 PDF 플랫폼 사용 방법에 대한 간단한 가이드입니다.
1단계
브라우저로 이동하여 "온라인 PDF 추출 도구"를 입력하세요.
2단계
PDF 플랫폼 중 하나를 선택하십시오.
3단계
웹사이트에서 "추출 도구"를 실행하십시오. 모든 도구 메뉴 또는 홈페이지 목록에서 PDF 추출 옵션을 선택할 수 있습니다. PDF 파일에서 페이지 추출을 완료할 수 있는 새 페이지로 이동합니다.
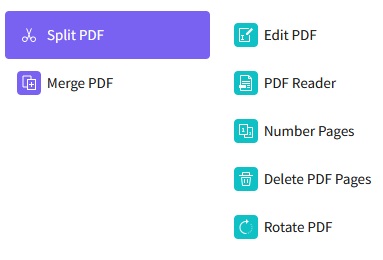
4단계
새로 나타난 화면에서 PDF 파일 업로드 — "파일 선택"을 클릭하여 컴퓨터나 모바일 장치에서 PDF 파일을 선택하십시오. 또는 업로드 영역으로 파일을 직접 끌어다가 놓을 수도 있습니다.
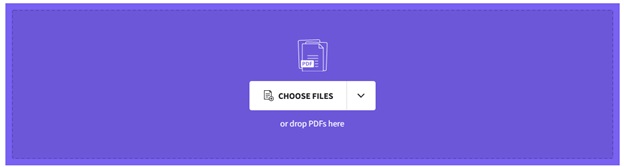
5단계
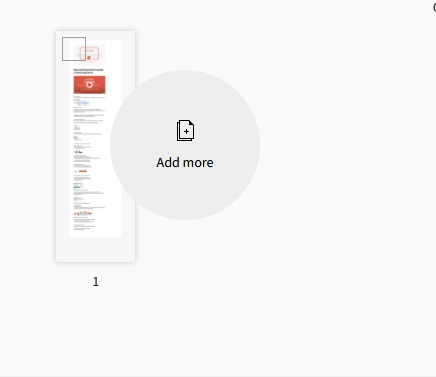
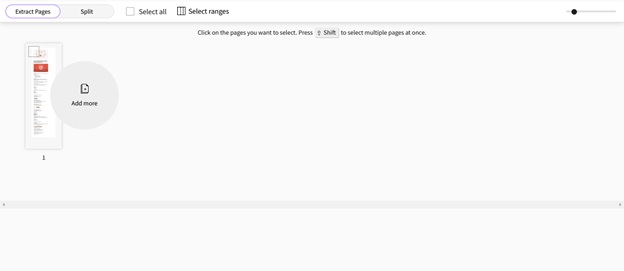
웹사이트는 그런 다음 문서의 PDF 썸네일을 생성합니다. 다음으로, PDF에서 추출할 페이지를 선택한 다음 "PDF 페이지 추출"을 클릭합니다. 절차는 몇 초 만에 완료됩니다.
6단계
선택한 페이지가 새 PDF 파일에 추가되어 다운로드할 수 있습니다. 추출된 페이지는 페이지 번호 순서대로 왜곡 없이 정리됩니다.
IronPDF C# 라이브러리를 사용하여 PDF 문서에서 페이지 추출하는 방법
Iron Software의 IronPDF는 C#에서 모든 PDF 관련 문제를 처리하는 가장 효과적이고 혁신적인 방법입니다. PDF 파일에서 페이지 추출을 포함하여 많은 PDF 관련 기능을 제공합니다. 이 작업을 수행하는 가장 간단한 방법을 찾고 있다면 IronPDF가 최고의 옵션입니다. 몇 줄의 코드만으로 다중 페이지 PDF 문서를 단일 PDF로 변환할 수 있습니다. 자신의 프로젝트에서 어떻게 사용할 수 있는지 저희 예제를 확인해 보십시오.
IronPDF 라이센스 키를 사용하여 제품을 워터마크 없이 게시할 수 있습니다.
라이선스 가격은 $999부터 시작하며, 1년간 무료 지원 및 업그레이드가 포함됩니다.
체험판 라이센스 키로 IronPDF를 무료로 체험할 수도 있습니다.
IronPDF로 단일 PDF 문서를 여러 문서로 분할하는 것은 아주 간단합니다. 각 문서는 단순히 한 페이지로 되어 있습니다.
우리는 IronPDF를 사용하여 단일 페이지 또는 페이지 범위를 새 IronPdf.PdfDocument 개체로 추출하여 PDF 문서를 분할할 수 있습니다.
// Import the necessary namespaces
using IronPdf;
class Program
{
static void Main()
{
// Load the PDF document from a file
var pdfDocument = PdfDocument.FromFile("example.pdf");
// Extract a specific page (for example, page 1)
var extractedPage = pdfDocument.ExtractPage(1);
// Save the extracted page as a new PDF file
extractedPage.SaveAs("extractedPage.pdf");
// To extract a range of pages, use ExtractPages(start, end)
var extractedPages = pdfDocument.ExtractPages(1, 3);
// Save the extracted pages as a new PDF file
extractedPages.SaveAs("extractedPages.pdf");
}
}// Import the necessary namespaces
using IronPdf;
class Program
{
static void Main()
{
// Load the PDF document from a file
var pdfDocument = PdfDocument.FromFile("example.pdf");
// Extract a specific page (for example, page 1)
var extractedPage = pdfDocument.ExtractPage(1);
// Save the extracted page as a new PDF file
extractedPage.SaveAs("extractedPage.pdf");
// To extract a range of pages, use ExtractPages(start, end)
var extractedPages = pdfDocument.ExtractPages(1, 3);
// Save the extracted pages as a new PDF file
extractedPages.SaveAs("extractedPages.pdf");
}
}' Import the necessary namespaces
Imports IronPdf
Friend Class Program
Shared Sub Main()
' Load the PDF document from a file
Dim pdfDocument = PdfDocument.FromFile("example.pdf")
' Extract a specific page (for example, page 1)
Dim extractedPage = pdfDocument.ExtractPage(1)
' Save the extracted page as a new PDF file
extractedPage.SaveAs("extractedPage.pdf")
' To extract a range of pages, use ExtractPages(start, end)
Dim extractedPages = pdfDocument.ExtractPages(1, 3)
' Save the extracted pages as a new PDF file
extractedPages.SaveAs("extractedPages.pdf")
End Sub
End Class이 C# 코드는 기존 PDF 문서에서 IronPDF를 사용하여 단일 또는 여러 페이지를 추출하는 방법을 설명합니다. ExtractPage 메소드는 특정 페이지를 가져오는 데 사용되며, ExtractPages 메소드는 페이지 범위를 처리할 수 있습니다. 추출 후, 새 PDF 파일로 페이지를 저장할 수 있습니다.
IronPdf.PdfDocument는 C#.NET API입니다.
CopyPage은 하나 이상의 PDF 파일에서 페이지를 추출하여 새 문서에 붙여넣는 프로그램입니다.