

Porównanie IronPDF for Java i Apache PDFBox
This article will cover the following two of the most popular libraries used in Java to work with PDF files:
- IronPDF
- Apache PDFBox
Now which library should we use? In this article, I'll compare both libraries' core functionality to allow you to make a decision about which one is best for your production environment.
How to Convert HTML to PDF in Apache PDFBOX
- Install Java library to convert HTML to PDF
- Create new document and page instance with Apache PDFBox
- Create a new
PDPageContentStreamwith the document and page as input - Use the
PDPageContentStreaminstance to configure and add content - Export the PDF document with
savemethod
IronPDF
The IronPDF library supports HTML to PDF Conversion for Java 8+, Kotlin, and Scala. This creator provides cross-platform support, i.e., Windows, Linux, or Cloud platforms. It is designed especially for Java, prioritizing accuracy, ease of use, and speed.
IronPDF is developed to help software developers create, edit, and extract content from PDF documents. It is based on the success and popularity of IronPDF for .NET.
Standout features of IronPDF include:
Use HTML Assets
- HTML (5 and below), CSS (Screen & Print), images (JPG, PNG, GIF, TIFF, SVG, BMP), JavaScript (+ Render Delays)
- Fonts (Web & Icon)
HTML to PDF
- HTML file/string to PDF document creation and manipulation
- URL to PDF
Convert Images
- Image to new PDF documents
- PDF to Image
Custom Paper Settings
- Custom Paper Size, Orientation & Rotation
- Margins (mm, inch & zero)
- Color & Grayscale, Resolution & JPEG Quality
Additional Features
- Website & System Logins
- Custom User Agents and Proxies
- HTTP Headers
Apache PDFBox library
Apache PDFBox is an open-source Java library for working with PDF files. It allows one to generate, edit, and manipulate existing documents. It can also extract content from files. The library provides several utilities that are used to perform various operations on documents.
Here are the standout features of Apache PDFBox.
Extract Text
- Extract Unicode text from files.
Split & Merge
- Split a single PDF into many files
- Merge multiple documents.
Fill Forms
- Extract data from forms
- Fill a PDF form.
Preflight
- Validate files against the PDF/A-1b standard.
- Print a PDF using the standard printing API.
Save as Image
- Save PDFs as PNG, JPEG, or other image types.
Create PDFs
- Develop a PDF from scratch with embedded fonts and images.
Signing
- Digitally sign files.
Overview
The rest of the article goes as follows:
- IronPDF Installation
- Apache PDFBox Installation
- Create PDF Document
- Images to Document
- Encrypting Documents
- Licensing
- Conclusion
Now, we will download and install the libraries to compare them and their powerful features.
1. IronPDF Installation
Installing IronPDF for Java is simple. There are different ways of doing it. This section will demonstrate two of the most popular ways.
1.1. Download JAR and add the Library
To download the IronPDF JAR file, visit the Maven website for IronPDF and download the latest version of IronPDF.
- Click the Downloads option and download the JAR.
Download IronPDF JAR
Once the JAR is downloaded, it's now time to install the library into our Maven project. You can use any IDE, but we will be using NetBeans. In the Projects section:
- Right-Click the Libraries folder and select the Add JAR/Folder option.
Add IronPDF Library in Netbeans
- Move to the folder where you downloaded the JAR.
- Select the IronPDF JAR and click the Open button.
Open IronPDF JAR
1.2. Install via Maven as a Dependency
Another way of downloading and installing IronPDF is using Maven. You can simply add the dependency in the pom.xml or use NetBeans's Dependency tool to include it in your project.
Add the Library Dependency in pom.xml
Add the following dependency in your pom.xml:
<dependencies>
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>YOUR_VERSION_HERE</version>
</dependency>
</dependencies><dependencies>
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>YOUR_VERSION_HERE</version>
</dependency>
</dependencies>Add The Library using the Dependencies Feature
- Right-Click on dependencies
- Select Add Dependency and fill in the following details with the updated version
Dodaj zależność IronPDF
Now let's install Apache PDFBox.
2. Apache PDFBox Installation
We can download and install PDFBox using the same methods as IronPDF.
2.1. Download JAR and Add the Library Manually
To install PDFBox JAR, visit the official website and download the PDFBox library the latest version.
After creating a project, in the project section:
- Right-Click the Libraries folder and select Add JAR/Folder option.
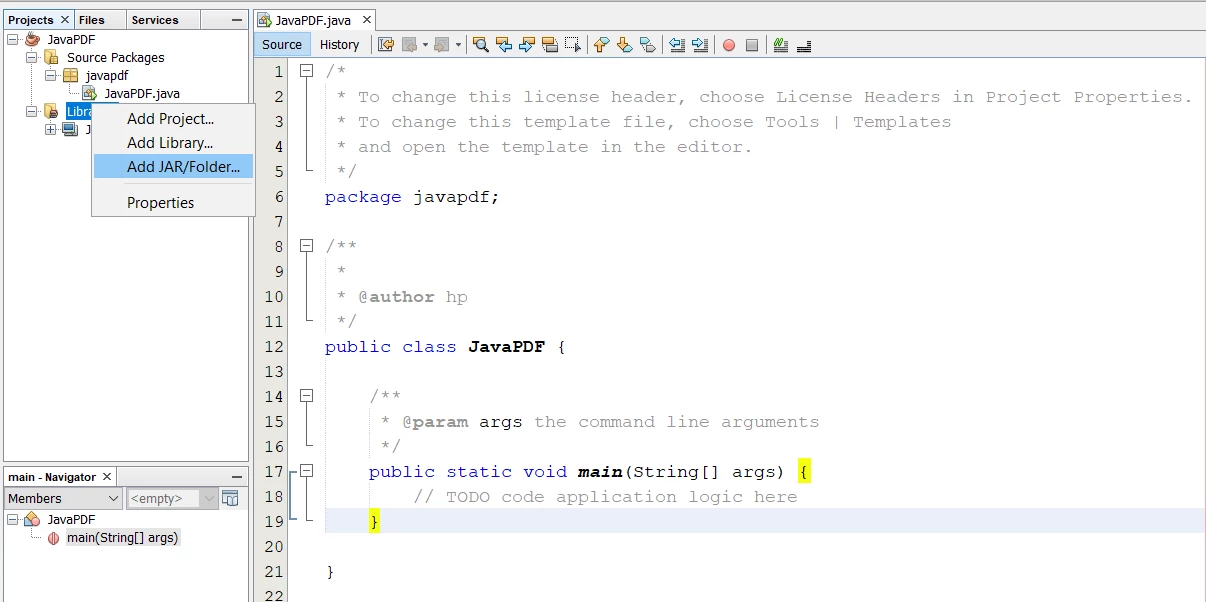
Add Library
- Move to the folder where you downloaded the JAR.
- Select the PDFBox JAR and click the Open button.
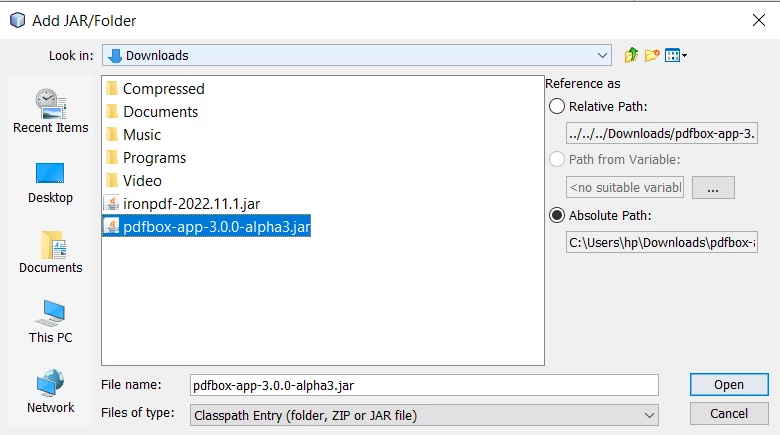
Open PDFBox JAR
2.2. Install via Maven as a Dependency
Add Dependency in the pom.xml
Copy the following code and paste it in the pom.xml.
<dependencies>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox-app</artifactId>
<version>3.0.0-alpha3</version>
</dependency>
</dependencies><dependencies>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox-app</artifactId>
<version>3.0.0-alpha3</version>
</dependency>
</dependencies>This will automatically download the PDFBox dependency and install it in the repository folder. It will now be ready to use.
Add Dependency using the Dependencies Feature
- Right-Click on dependencies in the project section
- Select Add Dependency and fill in the following details with the updated version
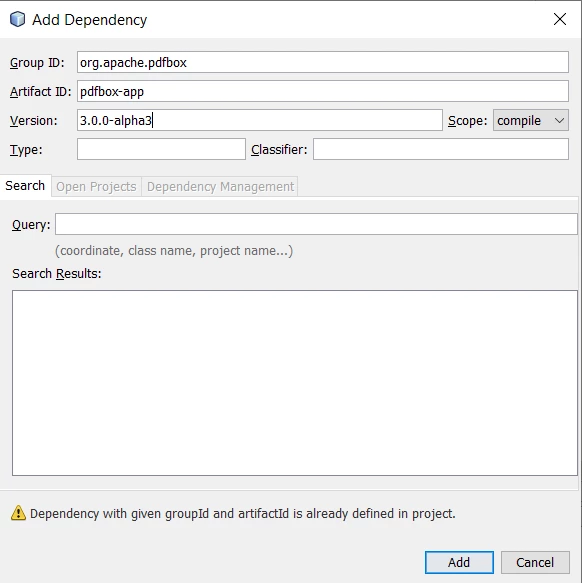
Add PDFBox Dependency
3. Create PDF Document
3.1. Using IronPDF
IronPDF provides different methods for creating files. Let's have a look at two of the most important methods.
Existing URL to PDF
IronPDF makes it very simple to generate documents from HTML. The following code sample converts a web page's URL to a PDF.
import com.ironsoftware.ironpdf.*;
import java.nio.file.Paths;
// Set the license key and log path
License.setLicenseKey("YOUR-LICENSE-KEY");
Settings.setLogPath(Paths.get("C:/tmp/IronPdfEngine.log"));
// Convert a URL to a PDF
PdfDocument myPdf = PdfDocument.renderUrlAsPdf("https://ironpdf.com");
// Save the PDF document to a file
myPdf.saveAs(Paths.get("url.pdf"));import com.ironsoftware.ironpdf.*;
import java.nio.file.Paths;
// Set the license key and log path
License.setLicenseKey("YOUR-LICENSE-KEY");
Settings.setLogPath(Paths.get("C:/tmp/IronPdfEngine.log"));
// Convert a URL to a PDF
PdfDocument myPdf = PdfDocument.renderUrlAsPdf("https://ironpdf.com");
// Save the PDF document to a file
myPdf.saveAs(Paths.get("url.pdf"));The output is the below URL that is well formatted and saved as follows:
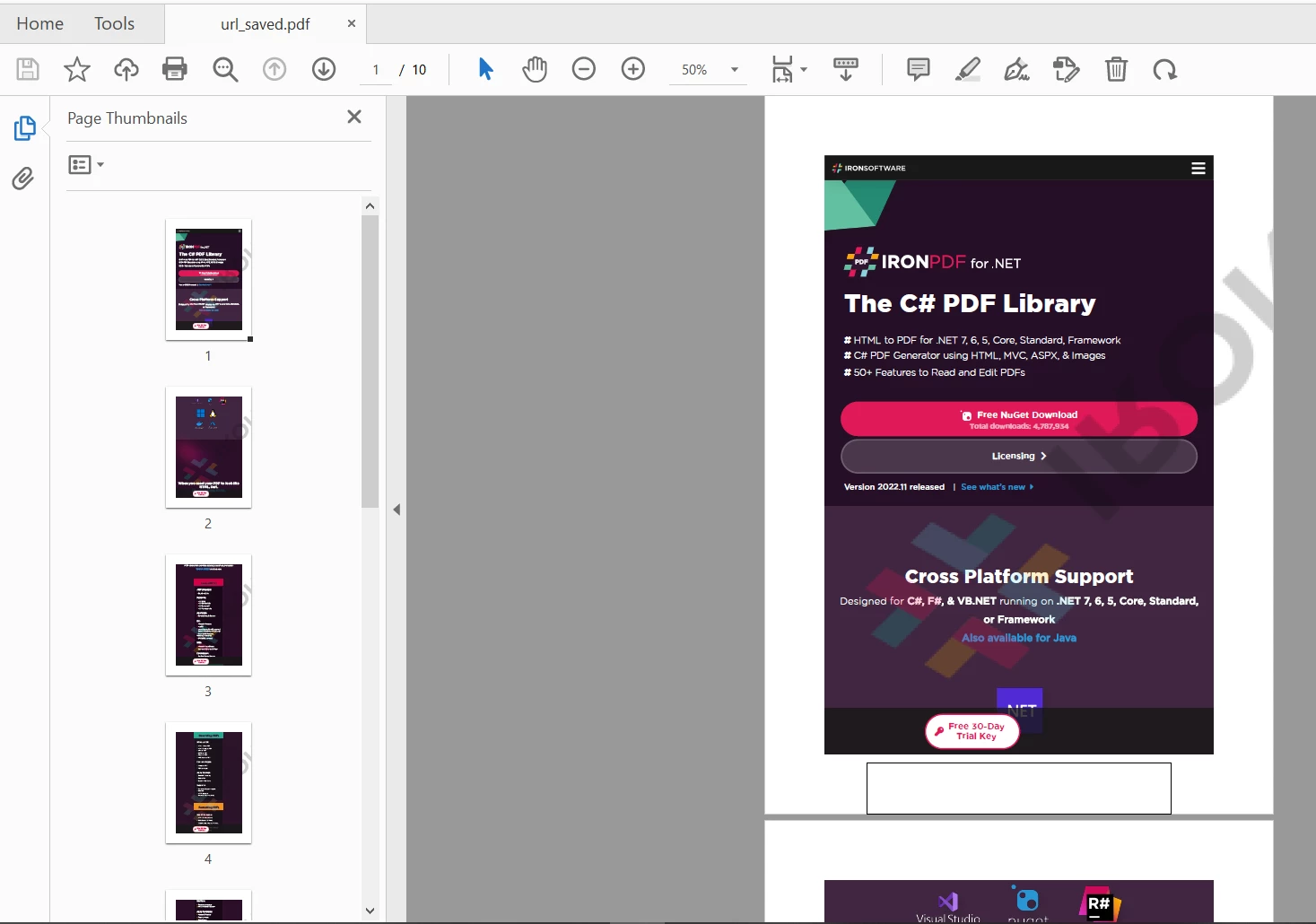
IronPDF URL Output
HTML Input String to PDF
The following sample code shows how an HTML string can be used to render a PDF in Java. You simply use an HTML string or document to convert it to new documents.
import com.ironsoftware.ironpdf.*;
import java.nio.file.Paths;
// Set the license key and log path
License.setLicenseKey("YOUR-LICENSE-KEY");
Settings.setLogPath(Paths.get("C:/tmp/IronPdfEngine.log"));
// Convert an HTML string to a PDF
PdfDocument myPdf = PdfDocument.renderHtmlAsPdf("<h1> ~Hello World~ </h1> Made with IronPDF!");
// Save the PDF document to a file
myPdf.saveAs(Paths.get("html_saved.pdf"));import com.ironsoftware.ironpdf.*;
import java.nio.file.Paths;
// Set the license key and log path
License.setLicenseKey("YOUR-LICENSE-KEY");
Settings.setLogPath(Paths.get("C:/tmp/IronPdfEngine.log"));
// Convert an HTML string to a PDF
PdfDocument myPdf = PdfDocument.renderHtmlAsPdf("<h1> ~Hello World~ </h1> Made with IronPDF!");
// Save the PDF document to a file
myPdf.saveAs(Paths.get("html_saved.pdf"));Oto wynik:

IronPDF HTML Output
3.2. Using Apache PDFBox
PDFBox can also generate new PDF documents from different formats, but it cannot convert directly from URL or HTML string.
Poniższy przykład kodu tworzy dokument zawierający tekst:
import org.apache.pdfbox.pdmodel.*;
import org.apache.pdfbox.pdmodel.common.*;
import org.apache.pdfbox.pdmodel.font.*;
import org.apache.pdfbox.pdmodel.graphics.image.*;
import org.apache.pdfbox.pdmodel.interactive.annotation.*;
import org.apache.pdfbox.pdmodel.interactive.form.*;
import java.io.IOException;
public class PDFBoxExample {
public static void main(String[] args) throws IOException {
// Create a document object
PDDocument document = new PDDocument();
// Add a blank page to the document
PDPage blankPage = new PDPage();
document.addPage(blankPage);
// Retrieve the page of the document
PDPage paper = document.getPage(0);
try (PDPageContentStream contentStream = new PDPageContentStream(document, paper)) {
// Begin the content stream
contentStream.beginText();
// Set the font to the content stream
contentStream.setFont(PDType1Font.TIMES_ROMAN, 12);
// Set the position for the line
contentStream.newLineAtOffset(25, 700);
String text = "This is the sample document and we are adding content to it.";
// Add text in the form of a string
contentStream.showText(text);
// End the content stream
contentStream.endText();
System.out.println("Content added");
// Save the document
document.save("C:/PdfBox_Examples/my_doc.pdf");
System.out.println("PDF created");
}
// Closing the document
document.close();
}
}import org.apache.pdfbox.pdmodel.*;
import org.apache.pdfbox.pdmodel.common.*;
import org.apache.pdfbox.pdmodel.font.*;
import org.apache.pdfbox.pdmodel.graphics.image.*;
import org.apache.pdfbox.pdmodel.interactive.annotation.*;
import org.apache.pdfbox.pdmodel.interactive.form.*;
import java.io.IOException;
public class PDFBoxExample {
public static void main(String[] args) throws IOException {
// Create a document object
PDDocument document = new PDDocument();
// Add a blank page to the document
PDPage blankPage = new PDPage();
document.addPage(blankPage);
// Retrieve the page of the document
PDPage paper = document.getPage(0);
try (PDPageContentStream contentStream = new PDPageContentStream(document, paper)) {
// Begin the content stream
contentStream.beginText();
// Set the font to the content stream
contentStream.setFont(PDType1Font.TIMES_ROMAN, 12);
// Set the position for the line
contentStream.newLineAtOffset(25, 700);
String text = "This is the sample document and we are adding content to it.";
// Add text in the form of a string
contentStream.showText(text);
// End the content stream
contentStream.endText();
System.out.println("Content added");
// Save the document
document.save("C:/PdfBox_Examples/my_doc.pdf");
System.out.println("PDF created");
}
// Closing the document
document.close();
}
}
PDFBox Pozycjonowane dane wyjściowe
However, if we remove contentStream.newLineAtOffset(25, 700); from the above code example and then run the project, it produces a PDF with output at the bottom of the page. Dla niektórych programistów może to być dość irytujące, ponieważ muszą dostosowywać tekst za pomocą współrzędnych (x, y). y = 0 means that the text will appear at the bottom.

PDFBox bez pozycjonowania wyjścia
4. Obrazy do dokumentu
4.1. Korzystanie z IronPDF
IronPDF może z łatwością konwertować wiele obrazów do jednego pliku PDF. Kod służący do dodawania wielu obrazów do jednego dokumentu wygląda następująco:
import com.ironsoftware.ironpdf.*;
import java.nio.file.*;
import java.util.ArrayList;
import java.util.List;
// Reference to the directory containing the images that we desire to convert
List<Path> images = new ArrayList<>();
images.add(Paths.get("imageA.png"));
images.add(Paths.get("imageB.png"));
images.add(Paths.get("imageC.png"));
images.add(Paths.get("imageD.png"));
images.add(Paths.get("imageE.png"));
// Render all targeted images as PDF content and save them together in one document.
PdfDocument merged = PdfDocument.fromImage(images);
merged.saveAs(Paths.get("output.pdf"));import com.ironsoftware.ironpdf.*;
import java.nio.file.*;
import java.util.ArrayList;
import java.util.List;
// Reference to the directory containing the images that we desire to convert
List<Path> images = new ArrayList<>();
images.add(Paths.get("imageA.png"));
images.add(Paths.get("imageB.png"));
images.add(Paths.get("imageC.png"));
images.add(Paths.get("imageD.png"));
images.add(Paths.get("imageE.png"));
// Render all targeted images as PDF content and save them together in one document.
PdfDocument merged = PdfDocument.fromImage(images);
merged.saveAs(Paths.get("output.pdf"));
Obrazy IronPDF do wygenerowania
4.2. Korzystanie z Apache PDFBox
import org.apache.pdfbox.pdmodel.*;
import org.apache.pdfbox.pdmodel.graphics.image.*;
import java.io.IOException;
import java.nio.file.*;
import java.util.ArrayList;
import java.util.List;
public class ImageToPdf {
public static void main(String[] args) {
// Reference to the directory containing the images that we desire to convert
Path imageDirectory = Paths.get("assets/images");
// Create an empty list to contain Paths to images from the directory.
List<Path> imageFiles = new ArrayList<>();
PDDocument doc = new PDDocument();
// Use a DirectoryStream to populate the list with paths for each image in the directory that we want to convert
try (DirectoryStream<Path> stream = Files.newDirectoryStream(imageDirectory, "*.{png,jpg}")) {
for (Path entry : stream) {
imageFiles.add(entry);
}
for (int i = 0; i < imageFiles.size(); i++) {
// Add a Page
PDPage blankPage = new PDPage();
doc.addPage(blankPage);
PDPage page = doc.getPage(i);
// Create PDImageXObject object
PDImageXObject pdImage = PDImageXObject.createFromFile(imageFiles.get(i).toString(), doc);
// Create the PDPageContentStream object
PDPageContentStream contents = new PDPageContentStream(doc, page);
// Drawing the image in the document
contents.drawImage(pdImage, 0, 0);
System.out.println("Image inserted");
// Closing the PDPageContentStream object
contents.close();
}
// Saving the document
doc.save("C:/PdfBox_Examples/sample.pdf");
// Closing the document
doc.close();
} catch (IOException exception) {
throw new RuntimeException(String.format("Error converting images to PDF from directory: %s: %s",
imageDirectory, exception.getMessage()), exception);
}
}
}import org.apache.pdfbox.pdmodel.*;
import org.apache.pdfbox.pdmodel.graphics.image.*;
import java.io.IOException;
import java.nio.file.*;
import java.util.ArrayList;
import java.util.List;
public class ImageToPdf {
public static void main(String[] args) {
// Reference to the directory containing the images that we desire to convert
Path imageDirectory = Paths.get("assets/images");
// Create an empty list to contain Paths to images from the directory.
List<Path> imageFiles = new ArrayList<>();
PDDocument doc = new PDDocument();
// Use a DirectoryStream to populate the list with paths for each image in the directory that we want to convert
try (DirectoryStream<Path> stream = Files.newDirectoryStream(imageDirectory, "*.{png,jpg}")) {
for (Path entry : stream) {
imageFiles.add(entry);
}
for (int i = 0; i < imageFiles.size(); i++) {
// Add a Page
PDPage blankPage = new PDPage();
doc.addPage(blankPage);
PDPage page = doc.getPage(i);
// Create PDImageXObject object
PDImageXObject pdImage = PDImageXObject.createFromFile(imageFiles.get(i).toString(), doc);
// Create the PDPageContentStream object
PDPageContentStream contents = new PDPageContentStream(doc, page);
// Drawing the image in the document
contents.drawImage(pdImage, 0, 0);
System.out.println("Image inserted");
// Closing the PDPageContentStream object
contents.close();
}
// Saving the document
doc.save("C:/PdfBox_Examples/sample.pdf");
// Closing the document
doc.close();
} catch (IOException exception) {
throw new RuntimeException(String.format("Error converting images to PDF from directory: %s: %s",
imageDirectory, exception.getMessage()), exception);
}
}
}
Obrazy PDFBox do wygenerowania
5. Szyfrowanie dokumentów
5.1. Korzystanie z IronPDF
Poniżej znajduje się kod służący do szyfrowania plików PDF hasłem w IronPDF:
import com.ironsoftware.ironpdf.*;
import java.nio.file.Paths;
// Open a document (or create a new one from HTML)
PdfDocument pdf = PdfDocument.fromFile(Paths.get("assets/composite.pdf"));
// Edit security settings
SecurityOptions securityOptions = new SecurityOptions();
securityOptions.setOwnerPassword("top-secret");
securityOptions.setUserPassword("sharable");
// Change or set the document encryption password
SecurityManager securityManager = pdf.getSecurity();
securityManager.setSecurityOptions(securityOptions);
pdf.saveAs(Paths.get("assets/secured.pdf"));import com.ironsoftware.ironpdf.*;
import java.nio.file.Paths;
// Open a document (or create a new one from HTML)
PdfDocument pdf = PdfDocument.fromFile(Paths.get("assets/composite.pdf"));
// Edit security settings
SecurityOptions securityOptions = new SecurityOptions();
securityOptions.setOwnerPassword("top-secret");
securityOptions.setUserPassword("sharable");
// Change or set the document encryption password
SecurityManager securityManager = pdf.getSecurity();
securityManager.setSecurityOptions(securityOptions);
pdf.saveAs(Paths.get("assets/secured.pdf"));5.2. Korzystanie z Apache PDFBox
Apache PDFBox zapewnia również szyfrowanie dokumentów, aby zwiększyć bezpieczeństwo plików. Można również dodać dodatkowe informacje, takie jak metadane. Kod wygląda następująco:
import org.apache.pdfbox.pdmodel.*;
import org.apache.pdfbox.pdmodel.encryption.*;
import java.io.File;
import java.io.IOException;
public class PDFEncryption {
public static void main(String[] args) throws IOException {
// Load an existing document
File file = new File("C:/PdfBox_Examples/sample.pdf");
PDDocument document = PDDocument.load(file);
// Create access permission object
AccessPermission ap = new AccessPermission();
// Create StandardProtectionPolicy object
StandardProtectionPolicy spp = new StandardProtectionPolicy("1234", "1234", ap);
// Setting the length of the encryption key
spp.setEncryptionKeyLength(128);
// Set the access permissions
spp.setPermissions(ap);
// Protect the document
document.protect(spp);
System.out.println("Document encrypted");
// Save the document
document.save("C:/PdfBox_Examples/encrypted.pdf");
// Close the document
document.close();
}
}import org.apache.pdfbox.pdmodel.*;
import org.apache.pdfbox.pdmodel.encryption.*;
import java.io.File;
import java.io.IOException;
public class PDFEncryption {
public static void main(String[] args) throws IOException {
// Load an existing document
File file = new File("C:/PdfBox_Examples/sample.pdf");
PDDocument document = PDDocument.load(file);
// Create access permission object
AccessPermission ap = new AccessPermission();
// Create StandardProtectionPolicy object
StandardProtectionPolicy spp = new StandardProtectionPolicy("1234", "1234", ap);
// Setting the length of the encryption key
spp.setEncryptionKeyLength(128);
// Set the access permissions
spp.setPermissions(ap);
// Protect the document
document.protect(spp);
System.out.println("Document encrypted");
// Save the document
document.save("C:/PdfBox_Examples/encrypted.pdf");
// Close the document
document.close();
}
}6. Ceny i licencje
Ceny i licencje IronPDF
IronPDF jest bezpłatny do tworzenia prostych aplikacji PDF, a licencję na użycie komercyjne można kupić w dowolnym momencie. IronPDF oferuje licencje na pojedyncze projekty, licencje dla pojedynczych programistów, licencje dla agencji i międzynarodowych organizacji, a także licencje na redystrybucję SaaS i OEM oraz wsparcie techniczne. All licenses are available with a free trial, a 30-day money-back guarantee, and one year of software support and upgrades.
The Lite package is available for $799. W przypadku produktów IronPDF nie ma absolutnie żadnych opłat cyklicznych. Bardziej szczegółowe informacje na temat licencjonowania oprogramowania są dostępne na stronie licencyjnej produktu IronPDF.
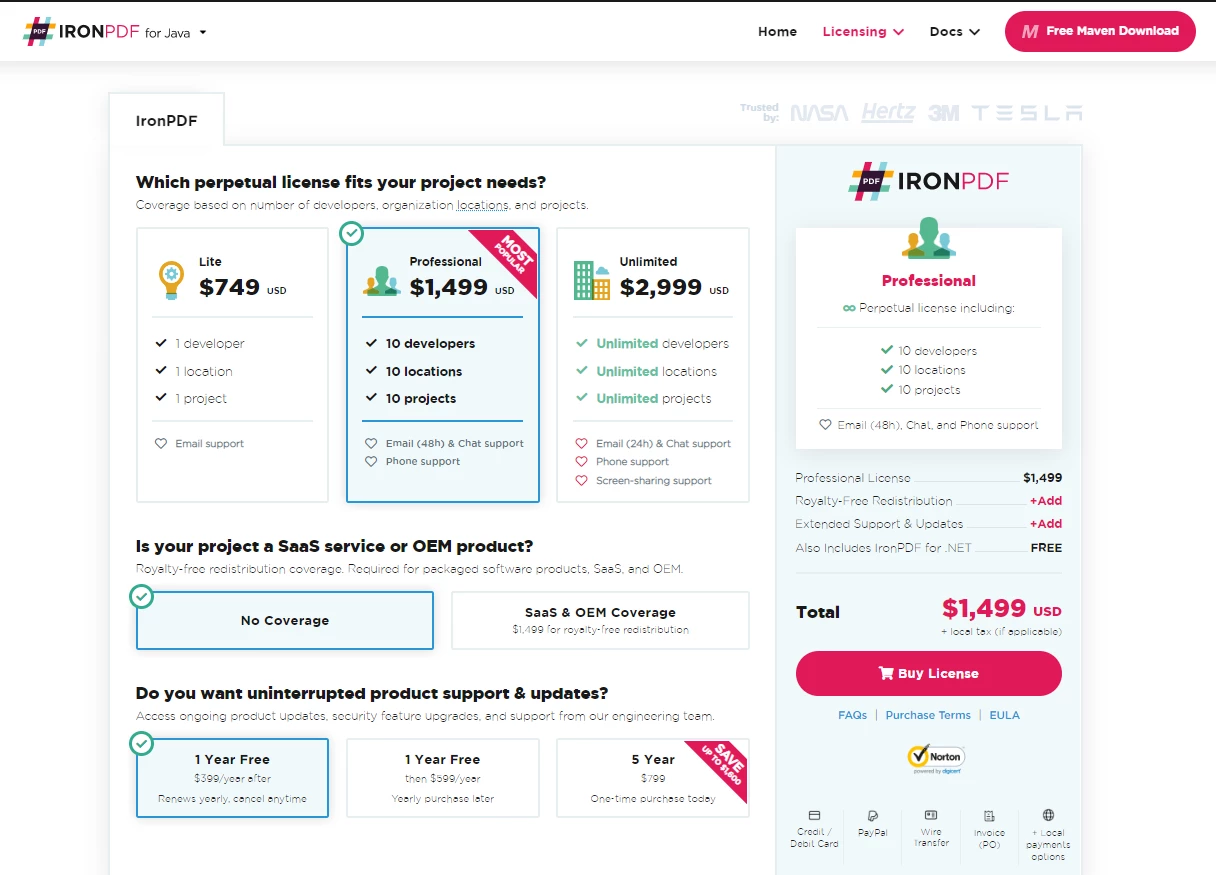
Licencjonowanie IronPDF
Ceny i licencje Apache PDFBox
Apache PDFBox jest dostępny bezpłatnie. Jest bezpłatny niezależnie od sposobu wykorzystania, czy to do celów osobistych, wewnętrznych, czy komercyjnych.
Można dołączyć licencję Apache 2.0 (aktualna wersja) z tekstu licencji Apache 2.0. Aby dołączyć kopię licencji, wystarczy umieścić ją w swojej pracy. Możesz również dołączyć poniższą informację jako komentarz na początku kodu źródłowego.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
https://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.Wnioski
W porównaniu z Apache PDFBox, IronPDF ma przewagę zarówno pod względem funkcjonalności, jak i wsparcia technicznego. Zapewnia również obsługę SaaS i OEM, co jest wymagane we współczesnym tworzeniu oprogramowania. Biblioteka ta nie jest jednak darmowa do użytku komercyjnego, tak jak Apache PDFBox.
Firmy posiadające duże aplikacje mogą wymagać ciągłego usuwania błędów i wsparcia ze strony zewnętrznych dostawców w celu rozwiązywania problemów pojawiających się podczas tworzenia oprogramowania. Jest to coś, czego brakuje w wielu rozwiązaniach open source, takich jak Apache PDFBox, które polegają na dobrowolnym wsparciu ze strony społeczności programistów w celu utrzymania ich w dobrym stanie. Krótko mówiąc, IronPDF najlepiej sprawdza się w zastosowaniach biznesowych i rynkowych, podczas gdy Apache PDFBox jest bardziej odpowiedni do zastosowań osobistych i niekomercyjnych.
Dostępna jest również bezpłatna wersja próbna, umożliwiająca przetestowanie funkcjonalności IronPDF. Wypróbuj lub kup IronPDF.
Teraz możesz kupić wszystkie produkty Iron Software w pakiecie Iron Suite w znacznie obniżonej cenie. Odwiedź tę stronę internetową Iron Suite, aby uzyskać więcej informacji na temat tej niesamowitej oferty.
Często Zadawane Pytania
Jak przekonwertować HTML na PDF w Javie?
Możesz użyć biblioteki Java IronPDF do konwersji HTML na PDF. Biblioteka oferuje metody łatwego przekształcania ciągów znaków HTML, plików lub adresów URL na pliki PDF.
Jakie są zalety korzystania z IronPDF for Java?
IronPDF for Java oferuje takie funkcje, jak konwersja HTML do PDF, konwersja obrazów, niestandardowe ustawienia papieru oraz obsługę logowania do stron internetowych i niestandardowych nagłówków HTTP. Jest zaprojektowany z myślą o łatwości użytkowania i oferuje wsparcie techniczne.
Czy IronPDF może konwertować obraz na plik PDF?
Tak, IronPDF może konwertować obrazy do formatu PDF. Ta funkcja pozwala generować dokumenty PDF z różnych formatów obrazów przy minimalnym wysiłku.
Czym różni się funkcjonalność Apache PDFBox od IronPDF?
Chociaż Apache PDFBox nadaje się do wyodrębniania tekstu, obsługi formularzy i podpisywania cyfrowego, nie oferuje bezpośredniej konwersji HTML do PDF. IronPDF oferuje natomiast bezpośrednią konwersję HTML i adresów URL do PDF wraz z zaawansowanymi funkcjami obsługi plików PDF.
Czy IronPDF nadaje się do użytku w Enterprise?
Tak, IronPDF doskonale nadaje się do użytku w przedsiębiorstwach dzięki komercyjnemu wsparciu, rozbudowanym funkcjom i opcjom licencyjnym, co czyni go idealnym rozwiązaniem dla aplikacji biznesowych.
Jakie są typowe problemy związane z konwersją HTML do PDF?
Typowe problemy to nieprawidłowe renderowanie złożonego kodu HTML/CSS, brakujące obrazy i nieprawidłowy układ stron. IronPDF rozwiązuje te problemy dzięki takim funkcjom, jak niestandardowe ustawienia papieru i obsługa obrazów.
Jak mogę zintegrować IronPDF z moim projektem Java?
Możesz zintegrować IronPDF ze swoim projektem Java, pobierając plik JAR z Maven lub dodając go jako zależność w pliku pom.xml projektu.
Do czego służy Apache PDFBox?
Apache PDFBox służy do tworzenia, edycji i manipulowania dokumentami PDF. Obsługuje wyodrębnianie tekstu, dzielenie i łączenie dokumentów, wypełnianie formularzy oraz podpisywanie cyfrowe.
Czy z IronPDF wiążą się koszty licencji?
IronPDF oferuje bezpłatną wersję próbną i jest darmowy do podstawowych zastosowań programistycznych, ale do użytku komercyjnego wymaga licencji. Dostępne są różne opcje licencyjne dostosowane do różnych potrzeb.
Dlaczego ktoś miałby wybrać Apache PDFBox zamiast IronPDF?
Ktoś może wybrać Apache PDFBox zamiast IronPDF, jeśli potrzebuje darmowego rozwiązania open source do użytku osobistego lub niekomercyjnego i nie potrzebuje konwersji HTML do PDF.
















